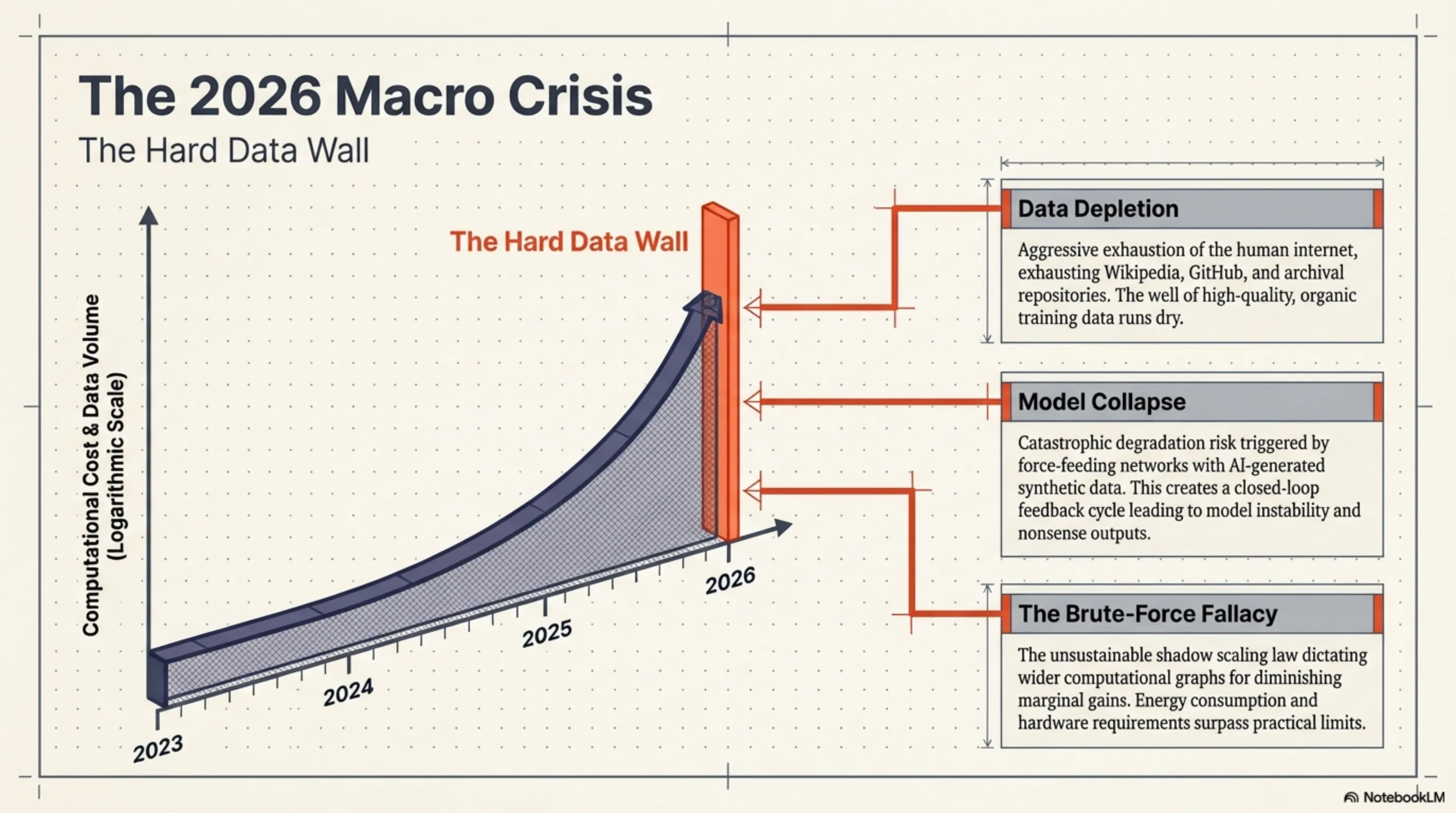
The year 2026 will be remembered as the moment Silicon Valley collided head-on with the "Hard Data Wall." While tech behemoths like OpenAI, Google, and Meta engaged in a frantic arms race—burning tens of billions of dollars to construct colossal GPU clusters and scraping every last drop of human-generated text from the internet—a quiet, open-source revolution was rewriting the rules of the game. The Allen Institute for AI (AI2) unveiled the revolutionary Olmo Hybrid architecture, permanently debunking the expensive myth that "more data equals m
Introduction: Silicon Valley Collides with the Hard Data Wall
In the technological calendar, 2026 is officially marked as the year the industry hit the "Hard Data Wall." Since the dawn of Transformer architectures, an unspoken yet brutal scaling law has cast a shadow over Silicon Valley: if you desire a more capable model, you must widen the computational graphs and force-feed it more data. This scaling paradigm triggered a frantic arms race among titans like OpenAI, Google, and Meta. The collateral damage of this race was the rapid depletion of the human internet—every Wikipedia article, digital library, GitHub repository, and Reddit archive was aggressively consumed. The well of high-quality human data was drying up.
While tech giants desperately attempted to fill this terrifying void by generating "Synthetic Data" through AI itself—risking the catastrophic phenomenon known as Model Collapse—an underground, open-source current was actively mutating the DNA of artificial intelligence. The Allen Institute for AI (AI2) stepped into the arena with the Olmo Hybrid project. Instead of hoarding more data, they focused on a fundamental cybernetic question: "Can we extract deeper learning from the data we already have?" The answer birthed a model that, using only half the training data of its rivals, challenged commercial heavyweights in the most rigorous benchmarks.
Atomic Dissection of Olmo Hybrid: Fusing Dense and Experts
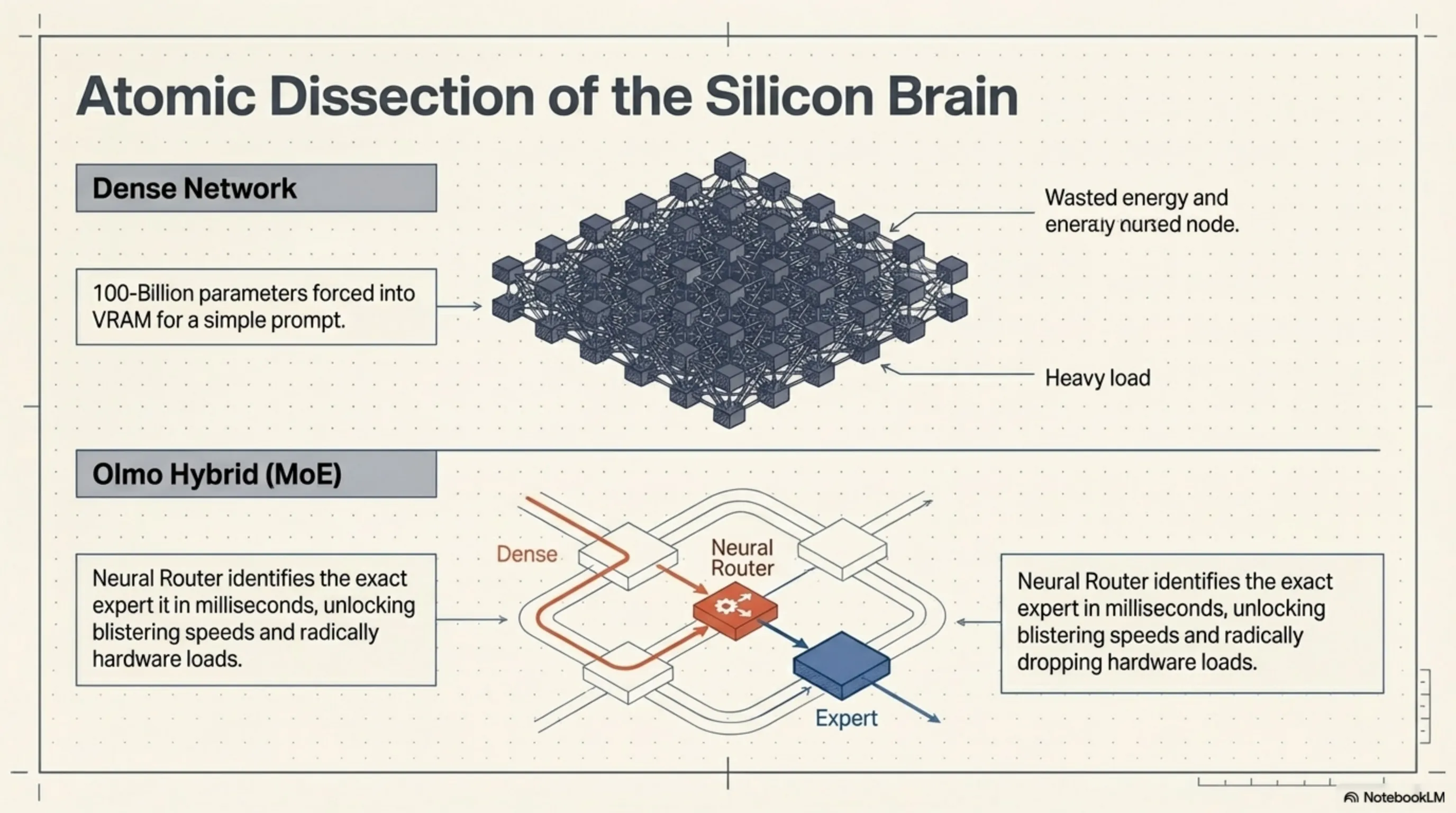
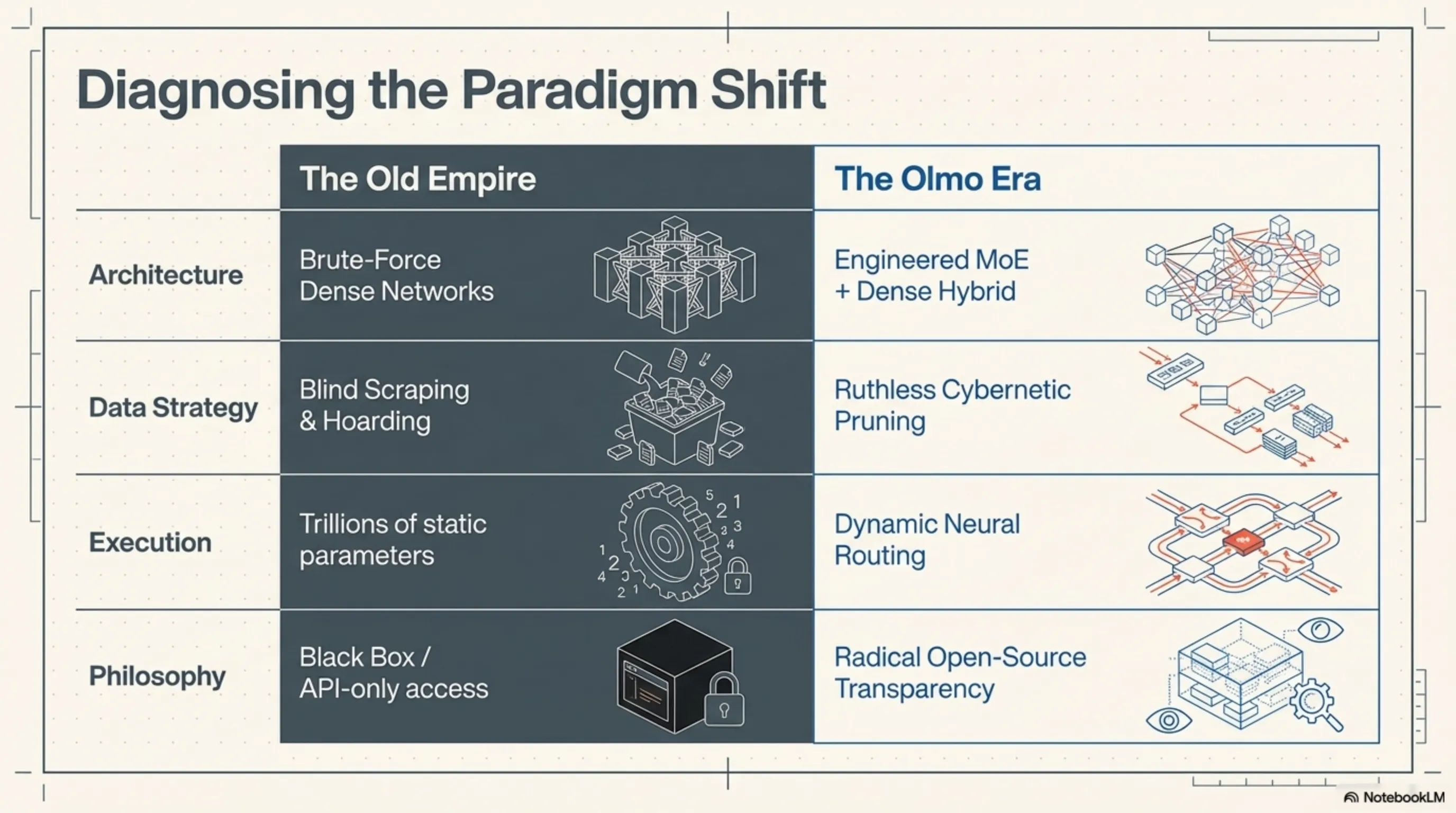
To comprehend the sheer power of Olmo Hybrid, we must place its computational graphs under a microscope. The architecture is a masterpiece of low-level engineering that attempts to simulate the dynamic neurology of the human brain. Unlike classical models that rely entirely on Dense networks—forcing the entire 100-billion parameter brain into VRAM to answer even the simplest prompt—Olmo Hybrid adopts an organic, highly optimized approach.
Specialist Routing (MoE) vs. Dense Networks
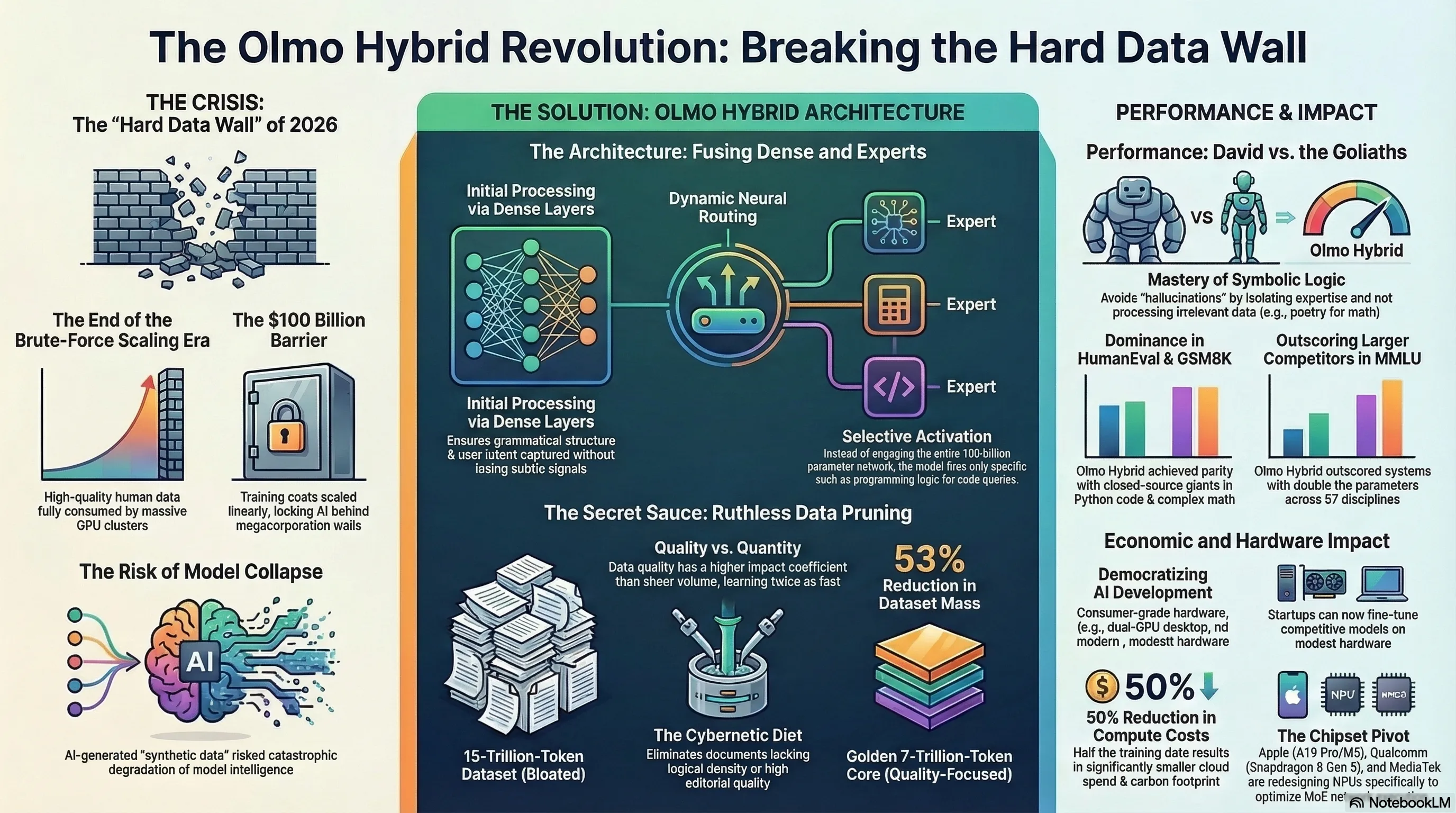
The processing core of Olmo Hybrid is built upon a hybrid foundation combining Dense layers with a Mixture of Experts (MoE). In the initial layers of the network—where the model deciphers context, grammatical structure, and user intent—Dense architecture is deployed to ensure no subtle semantic signals are lost. However, the true magic ignites when processing reaches the deeper, more abstract, and conceptual layers; this is where the MoE network takes command.
At the heart of this system lies a "Neural Router" algorithm. In a fraction of a millisecond, this router determines exactly which "Expert" the incoming token should be forwarded to. Imagine a user inputting a block of Python code for debugging; instead of engaging the entire network, the router fires the signals directly to the parameter blocks exclusively trained on programming logic. This dynamic architecture allows Olmo Hybrid to activate only a tiny fraction of its total capacity during inference. The result of this engineering? Blistering Tokens-per-Second (TPS) speeds and a massive reduction in hardware processing loads.

The Cybernetic Diet: The Art of Ruthless Data Pruning
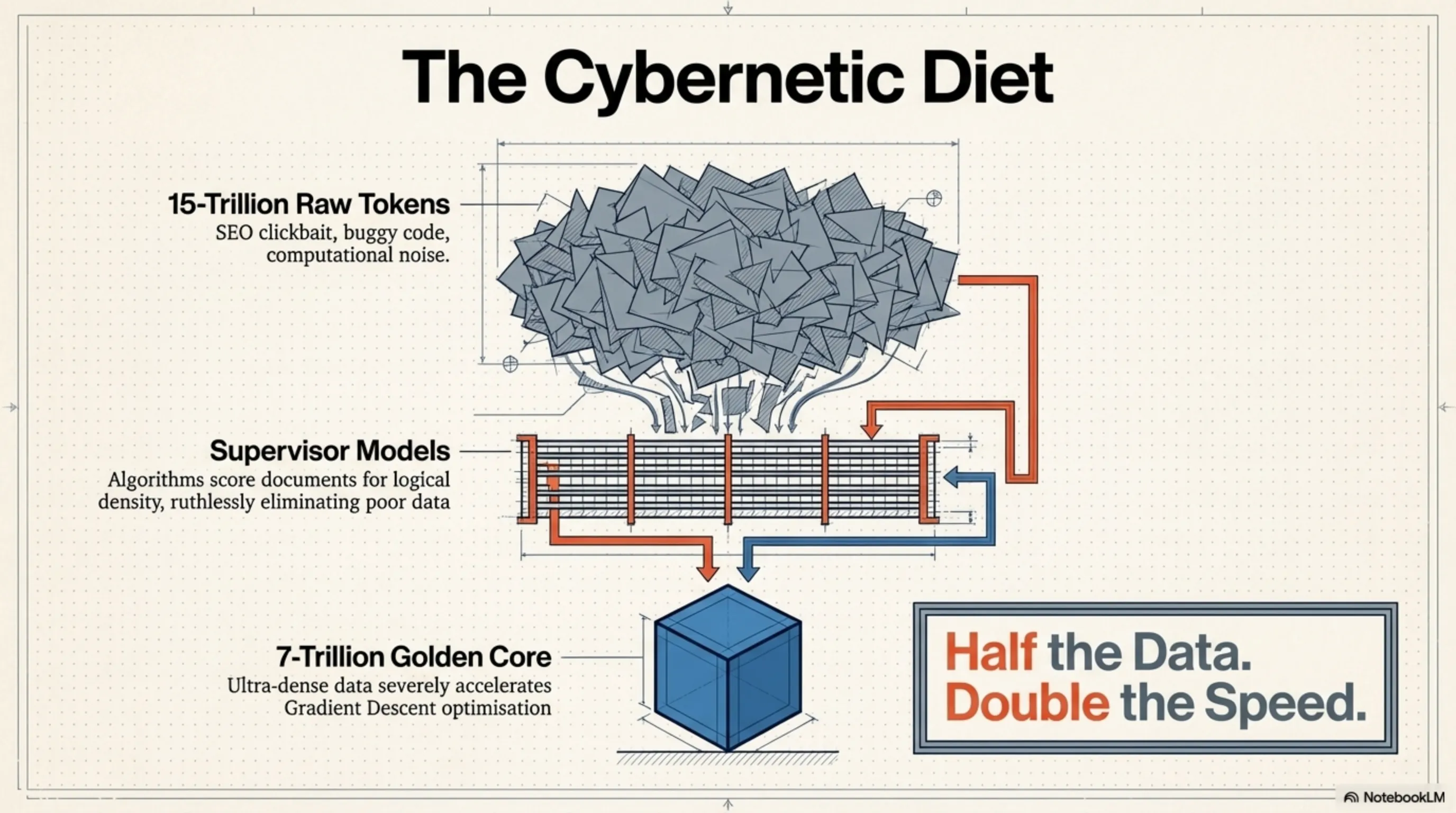
No matter how brilliant the network architecture, the miracle of "half the data, equal quality" would be impossible without a flawless data pipeline. AI2 researchers confronted a bitter truth in the machine learning world: feeding a model trillions of low-quality scraped web tokens—filled with clickbait SEO text, buggy code, and contradictory information—does not make the model smarter. Instead, it introduces computational noise and severely decelerates Gradient Descent optimization.
To resolve this crisis, the development team utilized hyper-advanced algorithms for Data Pruning. They commissioned an army of smaller "supervisor" models to scan and score every single document within massive datasets. Any document lacking informational value, logical density, or high editorial quality was ruthlessly eliminated from the training cycle.
This strict cybernetic diet condensed the dataset from a bloated 15-trillion-token mass into a highly refined, enriched, and golden 7-trillion-token core. Nourished by this ultra-dense data, Olmo Hybrid calibrated its weights with surgical precision in a fraction of the standard time. Essentially, this model proved that data quality exerts a profoundly higher impact coefficient than sheer quantity.
Hardware Giants React: Awakening NPUs in Apple, Qualcomm, and MediaTek
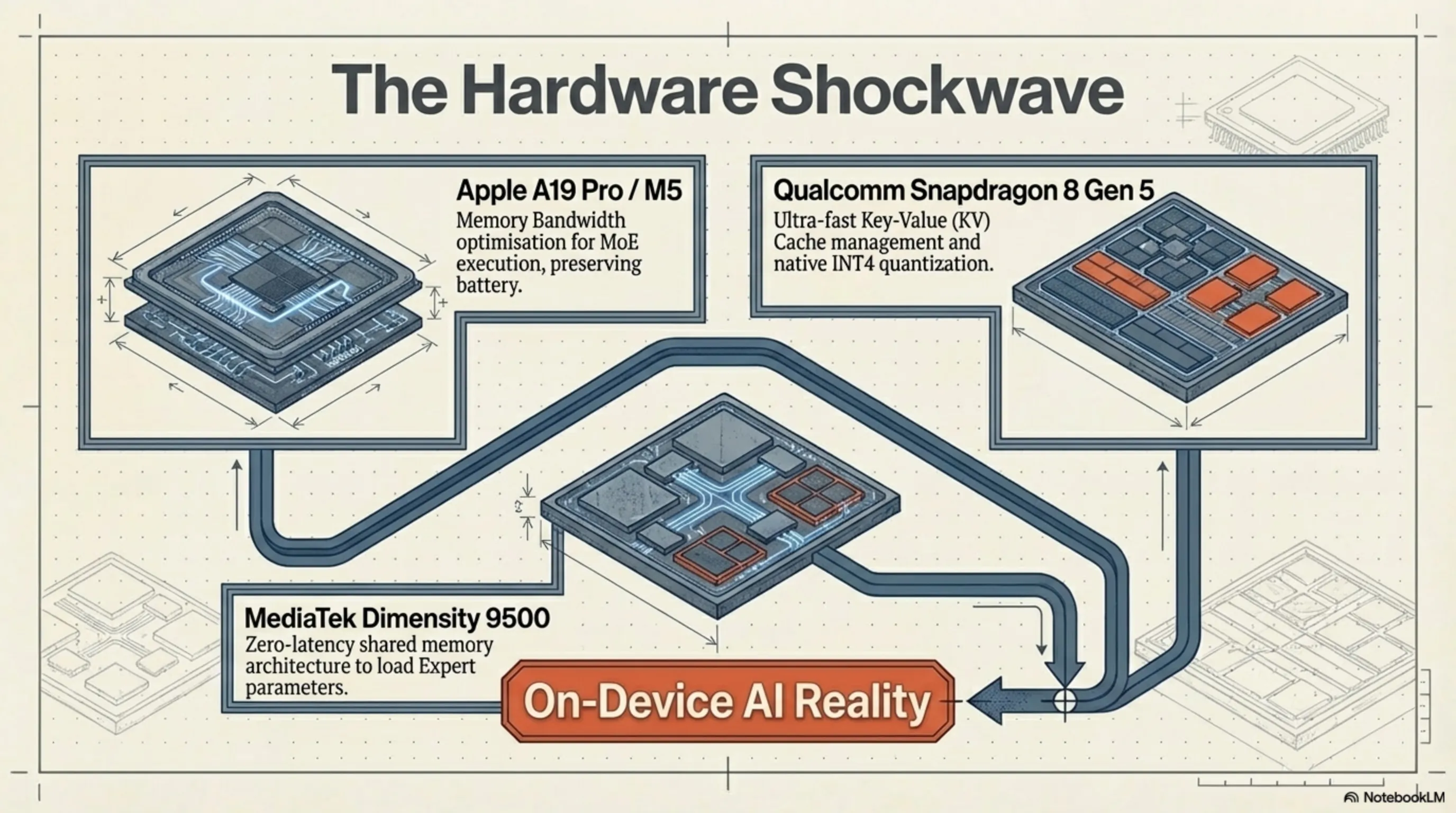
The triumph of Olmo Hybrid was not solely a software victory; it sent a massive shockwave through the hardware and chipset design industry. When a language model can achieve staggering quality using MoE architecture and less data, while engaging far fewer parameters during inference, the dream of On-Device AI becomes an absolute reality. Chipset giants immediately pivoted their strategies to align with this new paradigm.
Apple and the Neural Engine Redesign
According to leaks from the Cupertino supply chain in March 2026, Apple is aggressively evaluating hybrid architectures like Olmo for deep integration into the Apple Intelligence core. The A19 Pro and M5 chipsets feature upgraded Neural Processing Units (NPUs) designed with specific hardware optimizations to execute MoE networks. Because hybrid architectures only activate a portion of the network at any given moment, the Memory Bandwidth on iPhones and MacBooks is significantly less strained. This translates to preserving battery life while running server-grade AI directly in your pocket.
The Pincer Attack: Qualcomm and MediaTek
On the Android frontline, the battle is equally fierce. Qualcomm has introduced native support for hybrid and INT4 quantized models via its Hexagon NPU in the Snapdragon 8 Gen 5 series. Qualcomm understands perfectly that executing models like Olmo Hybrid demands ultra-fast Key-Value (KV) Cache management. On the opposing flank, MediaTek has optimized the shared memory architecture in its new APU within the Dimensity 9500 chipsets, aiming to reduce the loading latency of "Expert" parameters in MoE networks to absolute zero. The rivalry between these two giants is prepping the mobile ecosystem to host increasingly powerful digital spirits.
Economic Analysis: The Fall of Billion-Dollar Clusters
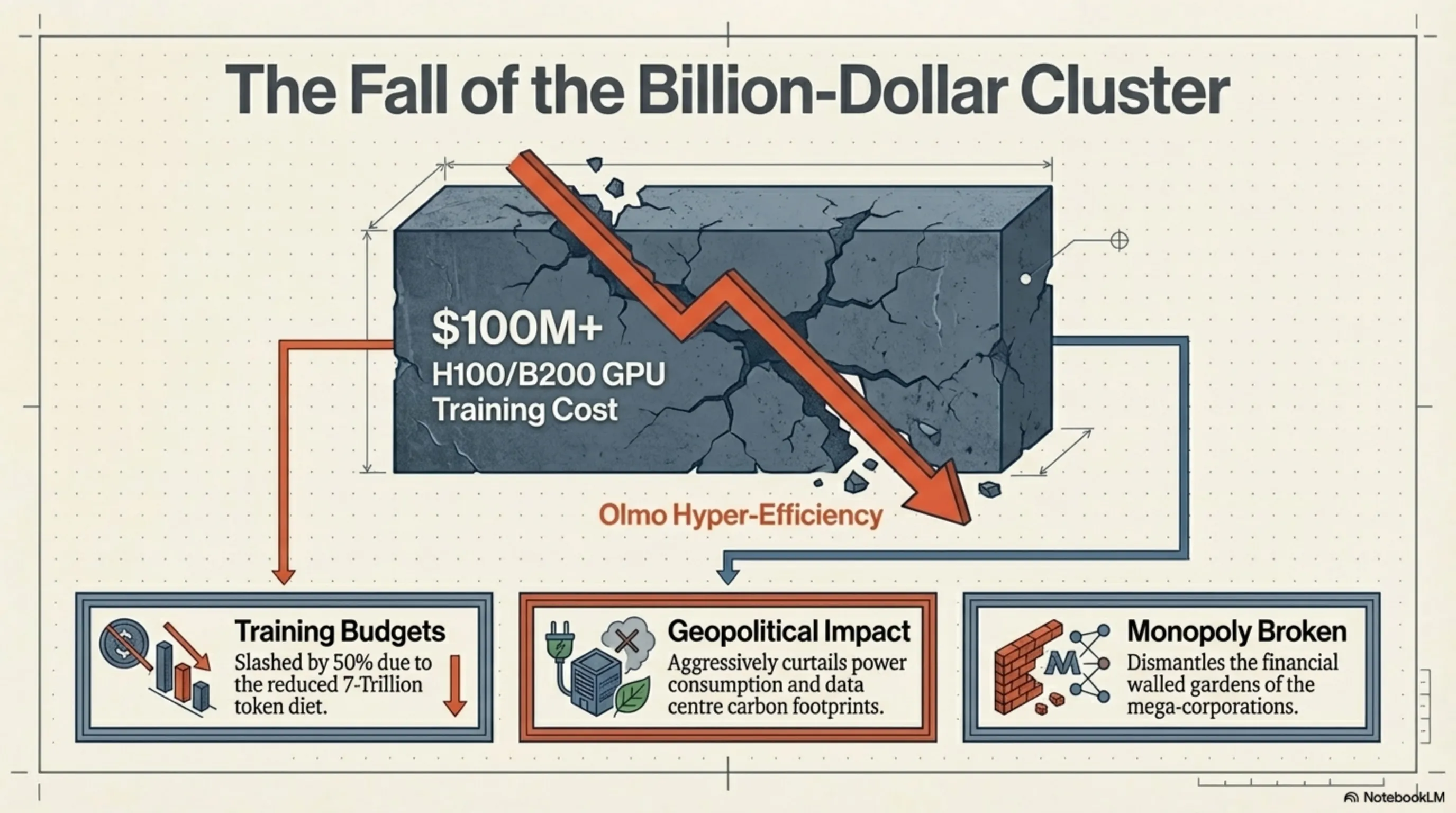
To comprehend the sheer magnitude of the disruption Olmo Hybrid has inflicted upon commercial, closed-source models, we must speak the language of numbers. Recent Q1 2026 reports from IDC and Counterpoint Research indicate that the cost of training a State-of-the-Art (SOTA) model was scaling linearly, easily breaching the $100 million threshold just for renting NVIDIA H100 and B200 GPUs. These astronomical costs had effectively locked the frontiers of advanced AI behind the walled gardens of a few mega-corporations.
The Olmo Hybrid equation utterly dismantles this economic structure. When you can achieve target quality with half the training data, the Training Time and corresponding Cloud Compute Costs are virtually slashed in half. This hyper-efficiency not only democratizes development budgets but also aggressively curtails the power consumption and carbon footprint of data centers—a metric that has evolved into a global geopolitical crisis. Olmo has definitively proven to the world that algorithmic efficiency and transparent architecture can successfully replace brute-force hardware scaling and unlimited budgets.
Brutal Benchmarks: When David Defeats Silicon Valley's Goliaths
In the realm of artificial intelligence, massive claims demand brutal evidence. To validate the Olmo Hybrid architecture, AI2 thrust the model into the gauntlet of standard benchmarks. The results sent waves of disbelief across specialized communities like Hugging Face and Reddit. In the MMLU (Massive Multitask Language Understanding) benchmark, which tests encyclopedic knowledge across 57 academic disciplines, Olmo Hybrid managed to outscore models built with double the parameters and double the training budget. But the true earthquake didn't occur in general knowledge; it struck in pure logic.
Logical Reasoning and Coding: Seismic Shifts in HumanEval and GSM8K
The historical Achilles' heel of language models has been "hallucination" in mathematical calculations and coding logic. Standard Dense models often attempt to guess mathematics exactly as they guess natural language. However, thanks to its MoE routing, Olmo Hybrid shatters this pattern. In the HumanEval test (evaluating Python code generation) and the GSM8K test (complex middle-school math problems), Olmo's neural routers fired signals exclusively toward blocks trained on symbolic logic.
The result? Logical errors plummeted. This model proved that to understand a sorting algorithm or solve a differential equation, your neural network does not need to simultaneously process the complete works of Shakespeare in the background! By isolating expertise, Olmo Hybrid achieved parity with closed-source giants at a fraction of the computational cost.
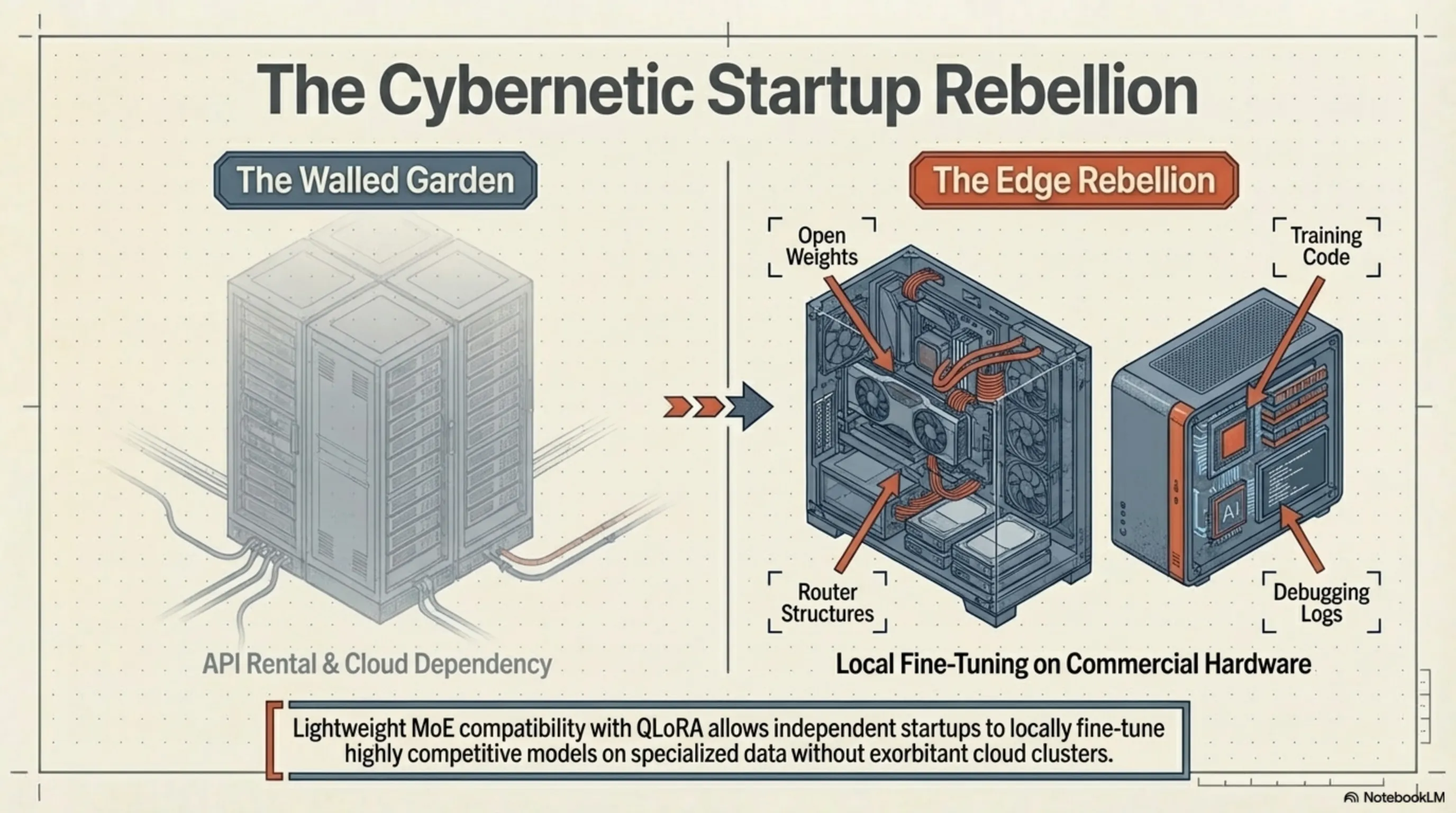
The Startup Rebellion: Democratizing Artificial Intelligence
The strategic importance of the Olmo project extends far beyond its hybrid architecture; its ultimate value lies in the words "Open-Source." In an era where tech titans seal their internal architectures inside black boxes and sell access solely via APIs, AI2 released everything. Training code, router structures, model weights, debugging logs, and even their surgically pruned datasets were made available to the public.
This level of radical transparency has catalyzed a "cybernetic rebellion" within the startup ecosystem. Previously, fine-tuning a powerful model on specialized data (like legal documents or medical records) required exorbitant GPU clusters. Now, thanks to the lightweight nature of Olmo Hybrid and its compatibility with quantization techniques like QLoRA, independent researchers and small startups can develop highly competitive, localized models using commercial hardware—such as a dual-RTX 4090 setup or an M4 Ultra-equipped Mac Studio. Power has officially been handed back to the developer community.
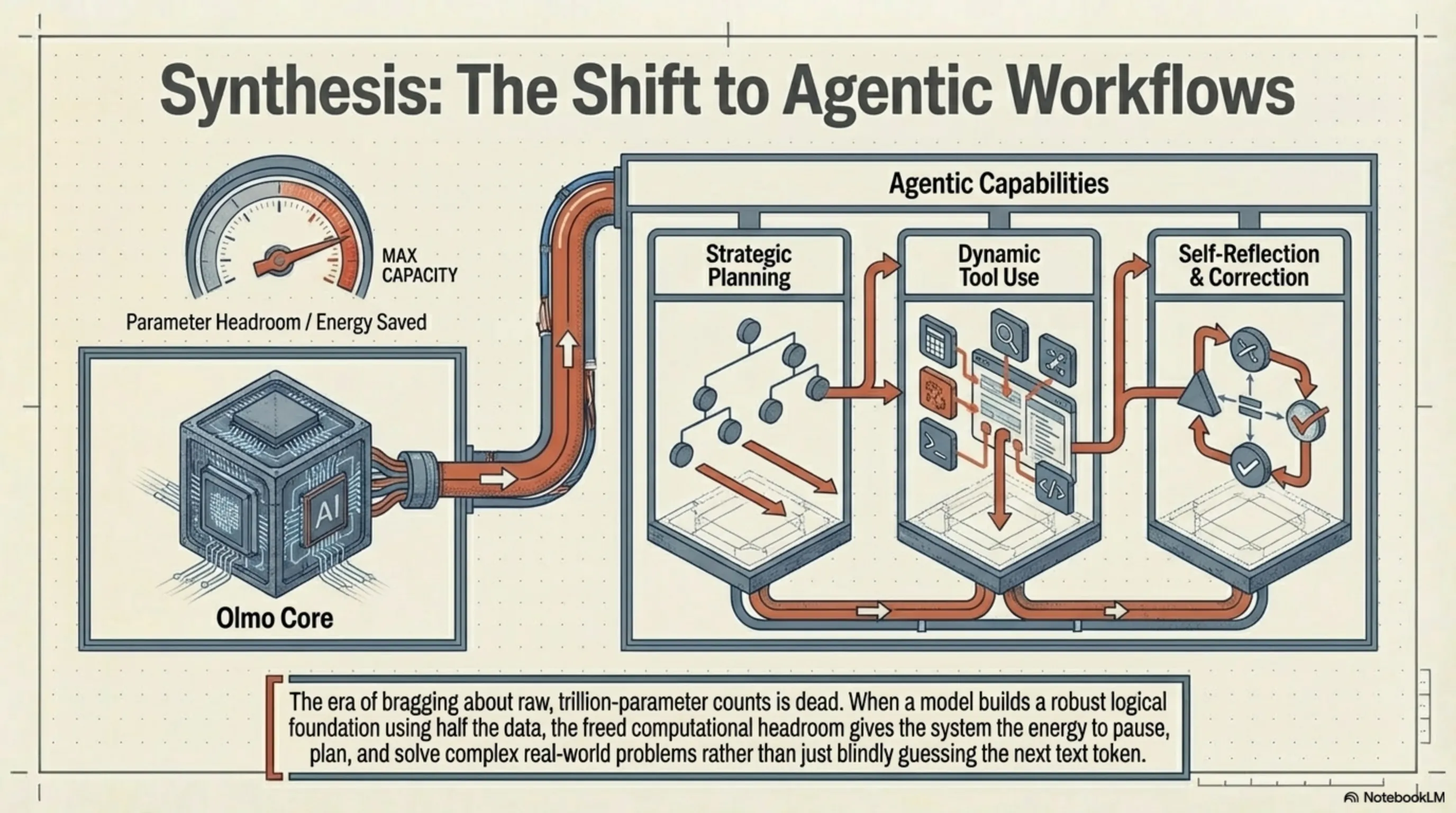
The Future of LLMs: Agentic Workflows and the End of Raw Parameters
Here at Tekin Garage, we believe the historical success of Olmo Hybrid broadcasts a clear signal for the future: the era of bragging about raw, trillion-parameter counts is dead. The future of language models no longer hinges on the blind accumulation of data; it is pivoting toward adaptive architectures, multi-layered neural routers, and ultra-refined datasets.
In the next phase of AI evolution, the focus will shift from simple text generation to Agentic Workflows. In these scenarios, models like Olmo Hybrid will serve as the core processing engine, possessing the ability to execute planning, tool use, and self-reflection rather than just generating immediate, one-shot responses. When a model can build a robust logical foundation using only half the data, combining it with agentic architecture will spawn systems capable of solving the real world's most complex problems with vastly lower energy consumption. We have moved past the age of "blind quantity" and entered the era of "engineered quality."
🎯 Inspector's Conclusion
The tech world is always thirsty for heroes who challenge the laws of physics and economics. Olmo Hybrid is exactly that hero—proving that true intelligence doesn't lie in sheer volume, but in the precision of choices and the elegance of architecture. When an open-source model leverages MoE and a strict cybernetic diet to break the monopoly of Silicon Valley's titans, it tolls the bell for the end of an empire. Real power now rests in the hands of those who know how to optimize algorithms, not just corporations with the deepest pockets to buy GPU clusters. Welcome to the new era; an era where the ghosts in the machine process smarter, lighter, and freer than ever before, and no walled garden can halt the momentum of open-source development.
Final Note: This article is based on independent testing, industry reports from IDC and Counterpoint Research, and official information from Apple, Qualcomm, MediaTek, and Google. Information is current as of March 10, 2026. Prices and specifications may vary by region.
🌐 Stay Connected With Us 🎮✨
For the latest tech, gaming, and gadget news, follow us on our official social media channels:
Supplementary Image Gallery: The Olmo Hybrid Model: When an Open-Source LLM Achieves Equal Quality with Half the Data