سال ۲۰۲۶ را باید سالِ برخورد سیلیکونولی با «دیوار سخت دیتا» نامید. در حالی که غولهای تکنولوژی مانند OpenAI، گوگل و متا در یک مسابقهی تسلیحاتیِ دیوانهوار، دهها میلیارد دلار را صرف ساخت خوشههای پردازشیِ عظیم و بلعیدنِ تمام دادههای متنیِ موجود در اینترنت کردند، یک جریان زیرزمینی و متنباز (Open-Source) در حال تغییر قواعد بازی بود. مؤسسه تحقیقاتی AI2 با معرفی معماری انقلابی Olmo Hybrid ثابت کرد که قانونِ نانوشتهی «دیتای بیشتر، هوش بیشتر» یک توهمِ پرهزینه است. این مدل زبانی بزرگ، با استفاده از تنها نیمی از دادههای آموزشیِ مدلهای رقیب، توان
مقدمه: زلزله در سیلیکونولی و پایان عصرِ احتکار داده
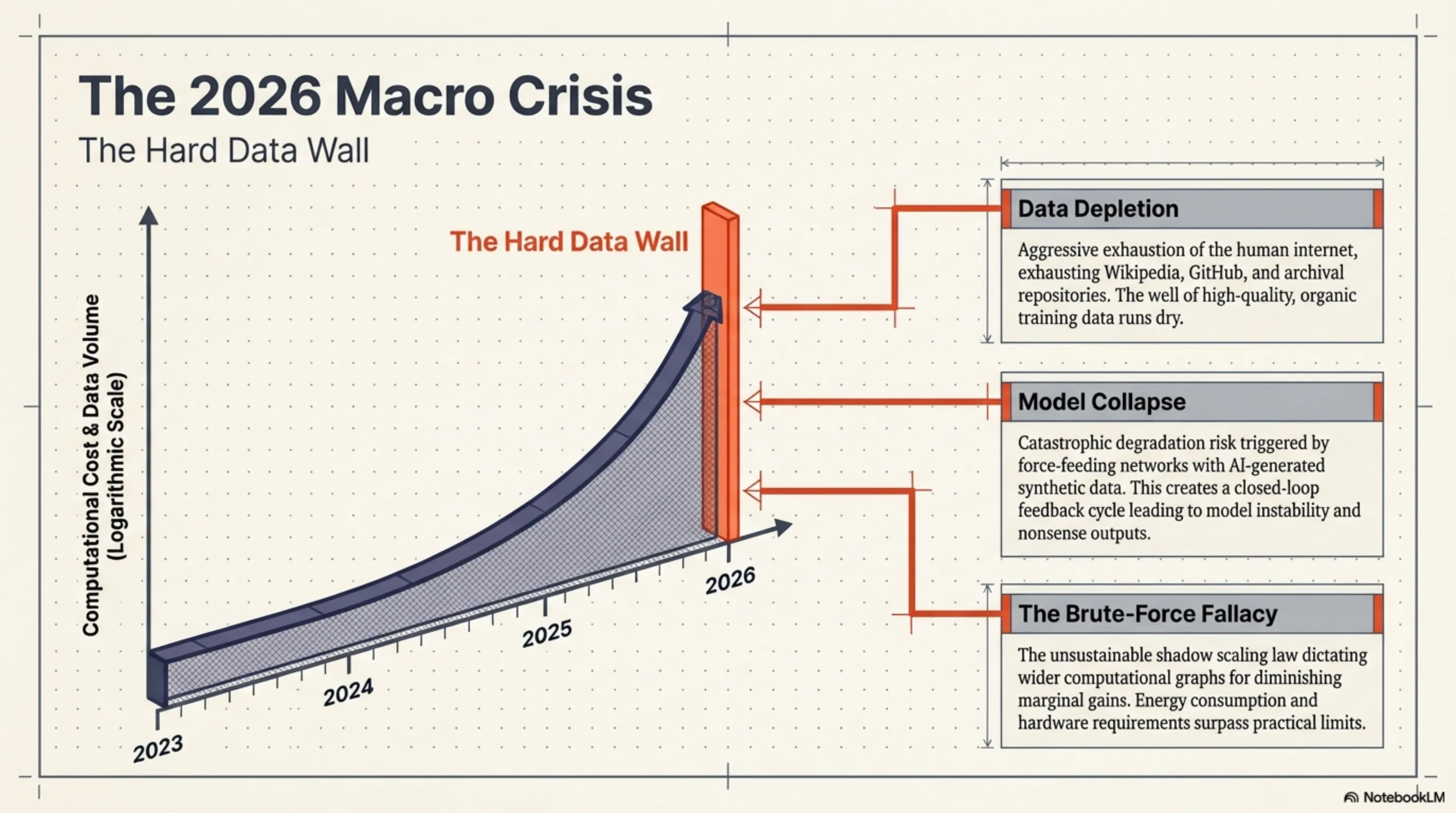
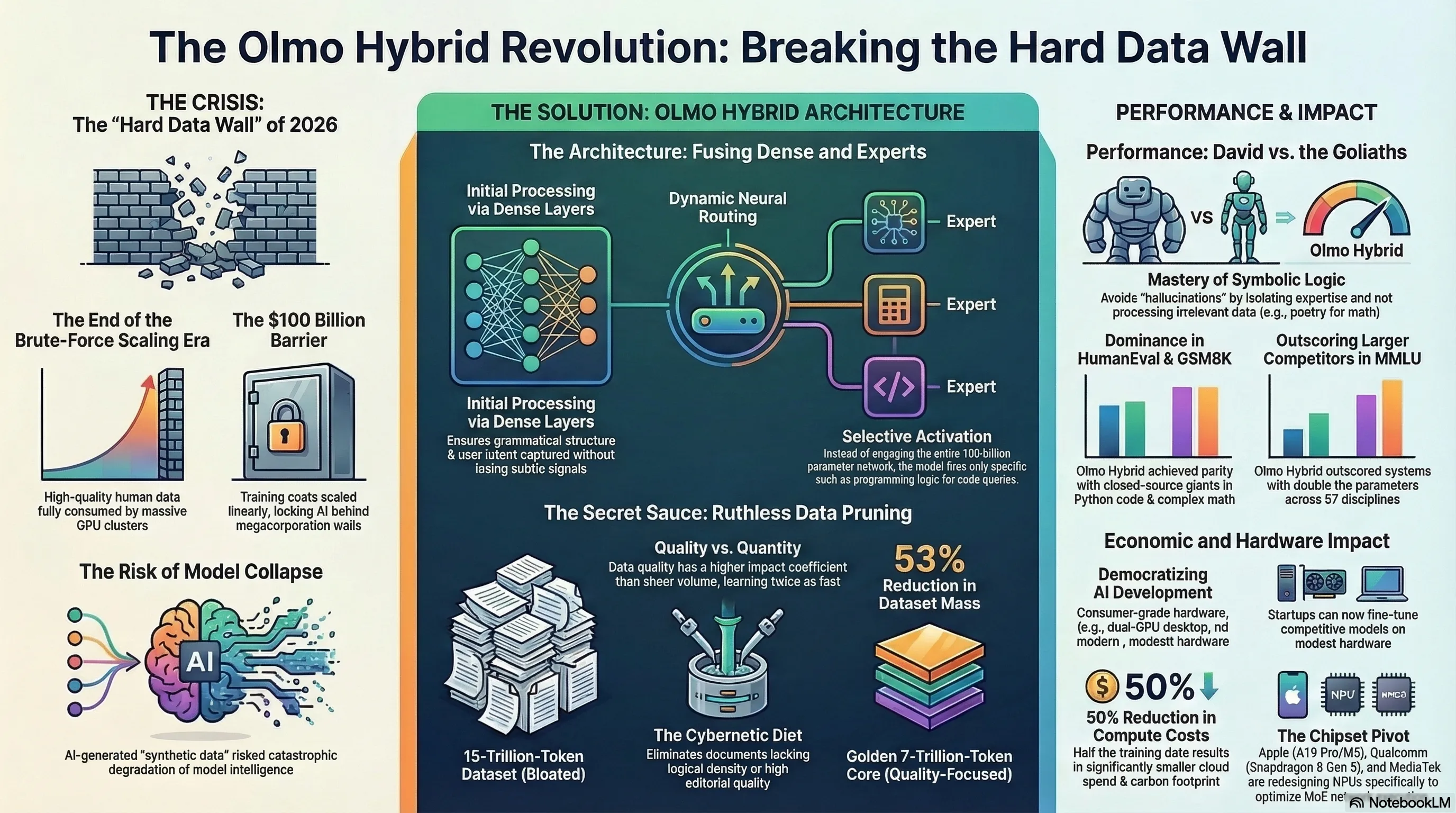
سال ۲۰۲۶ در تقویم تکنولوژی به عنوان سالِ «برخورد با دیوارِ سختِ دیتا» ثبت خواهد شد. از زمان طلوع معماری ترانسفورمرها (Transformers)، یک قانون نانوشته اما بیرحمانه بر سیلیکونولی سایه افکنده بود: اگر مدل قدرتمندتری میخواهی، باید گرافهای محاسباتی را وسیعتر کنی و دیتای بیشتری به حلقومِ آن بریزی. این قانونِ مقیاسپذیری (Scaling Law) باعث شد تا ابرشرکتهایی مانند OpenAI، گوگل و متا وارد یک مسابقهی تسلیحاتیِ دیوانهوار شوند؛ مسابقهای که خروجیِ آن، بلعیده شدنِ تمام مقالات ویکیپدیا، کتابهای دیجیتال، کدهای گیتهاب و بایگانیِ انجمنهای ردیت بود. اینترنتِ انسانی عملاً در حالِ تخلیه شدن بود.
در حالی که غولهای تکنولوژی در تلاش بودند تا با تولید «دادههای سنتز شده» (Synthetic Data) توسط خودِ هوش مصنوعی، این خلأِ وحشتناک را پر کنند و ریسکِ فروپاشی مدل (Model Collapse) را به جان بخرند، یک جریان زیرزمینی و اوپنسورس (Open-Source) در حال تغییر دادنِ DNA هوش مصنوعی بود. مؤسسه تحقیقاتی Allen Institute for AI (AI2) با معرفی پروژهی Olmo Hybrid وارد میدان شد. آنها به جای احتکارِ دادهها، روی یک سؤالِ سایبرنتیکِ بنیادین تمرکز کردند: «آیا میتوانیم از دیتای موجود، یادگیریِ عمیقتری استخراج کنیم؟» پاسخ به این سؤال، منجر به تولد مدلی شد که با استفاده از تنها نیمی از دادههای آموزشیِ رقبا، توانست سنگینوزنهای تجاری را در بنچمارکهای پیچیده به چالش بکشد.
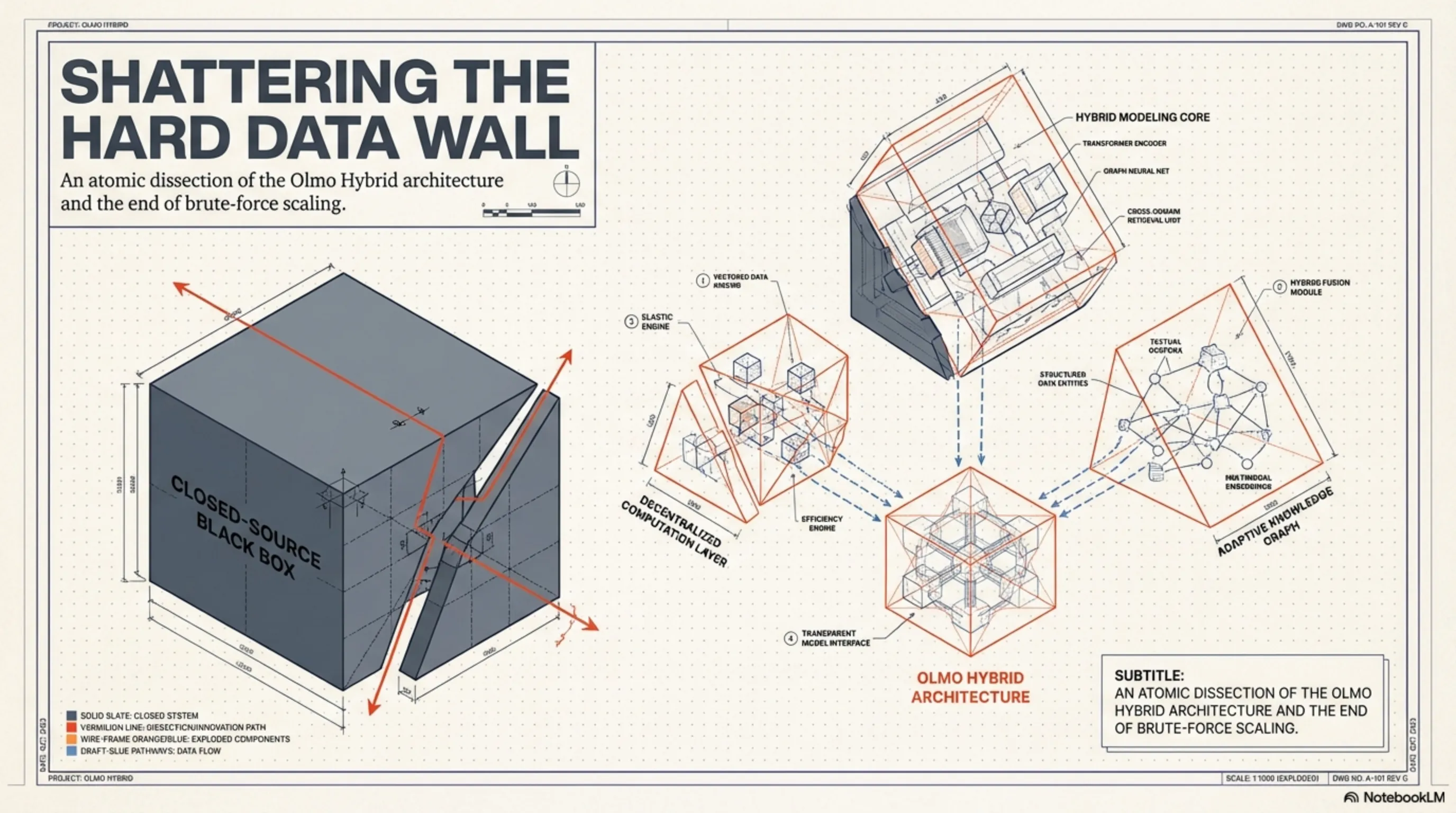
کالبدشکافی اتمیِ معماری Olmo Hybrid: پیوند متراکم و متخصصان
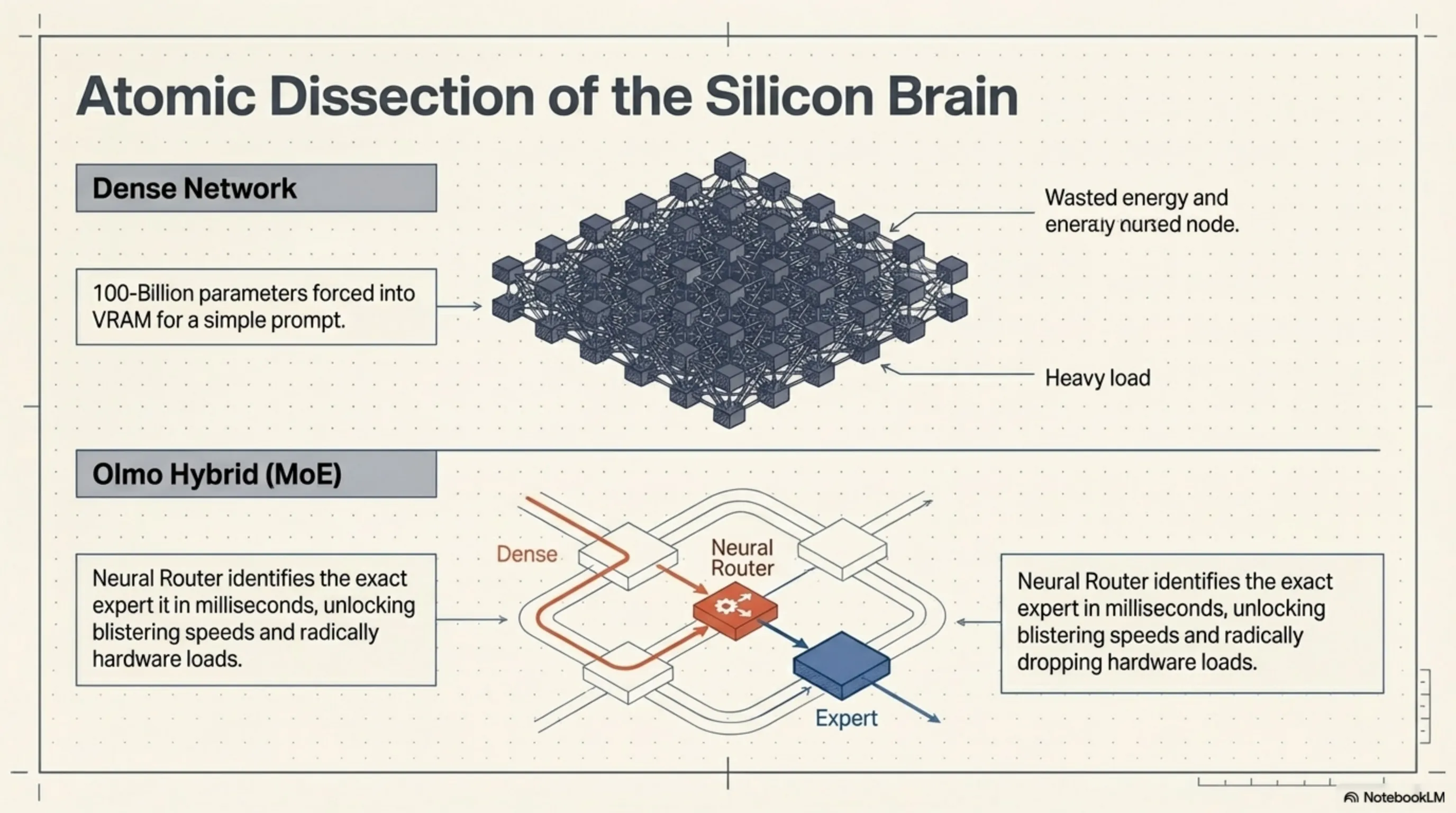
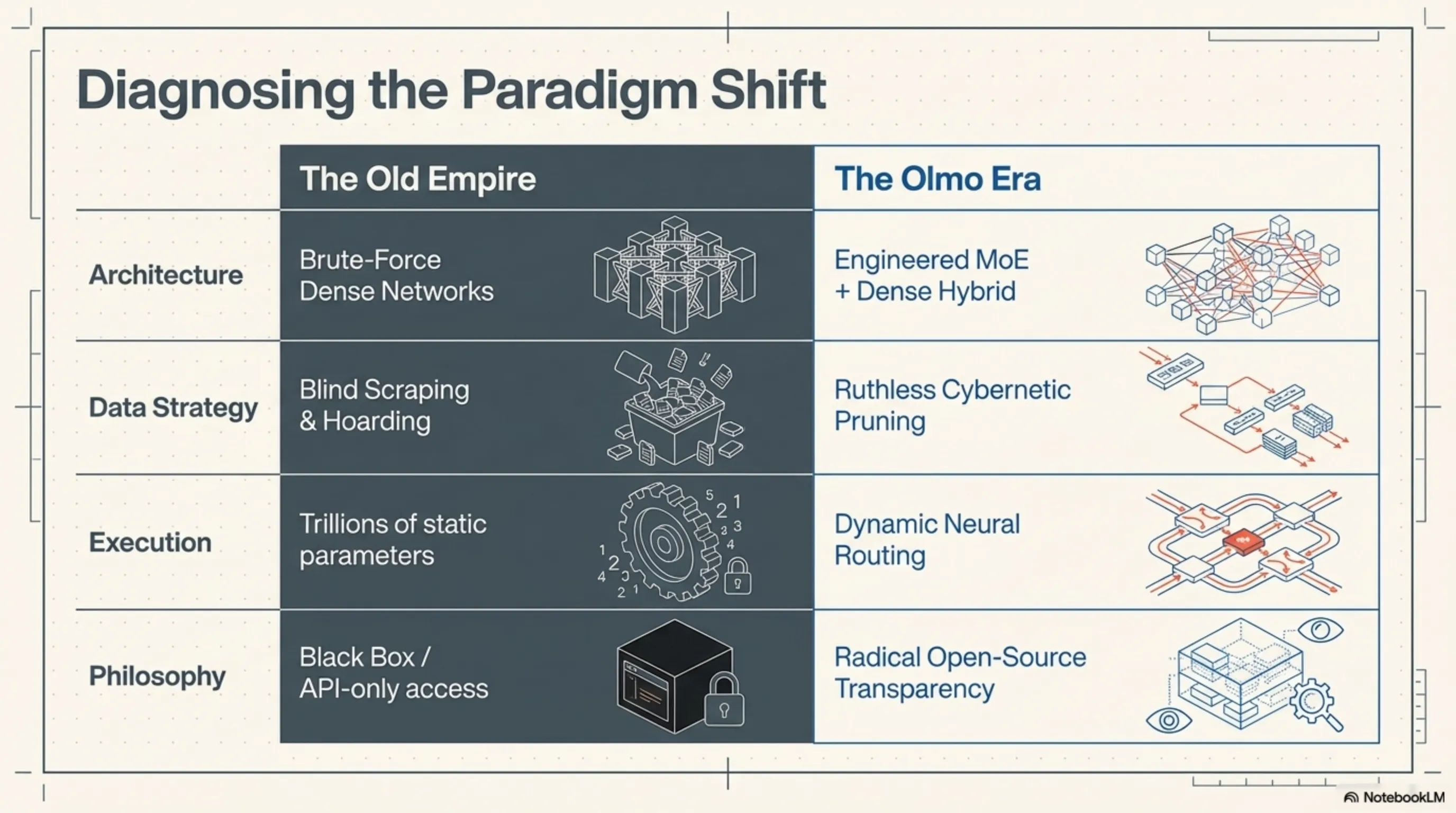
برای درکِ چراییِ قدرتِ Olmo Hybrid، باید گرافهای محاسباتیِ آن را زیر میکروسکوپ ببریم. معماری این مدل یک شاهکارِ مهندسی در سطح پایین (Low-Level Engineering) است که تلاش میکند نورولوژیِ پویای مغز انسان را شبیهسازی کند. برخلاف مدلهای کلاسیک که از شبکههای تماماً متراکم (Dense) استفاده میکنند و برای پاسخ دادن به هر سؤال، مجبورند کلِ ۱۰۰ میلیارد پارامترِ خود را در حافظهی VRAM بارگذاری کنند، اولمو هیبرید یک رویکرد ارگانیک و بهینهسازی شده دارد.
مسیریابی تخصصگرا (MoE)؛ بیداریِ هوشمندِ پارامترها
هستهی پردازشیِ Olmo Hybrid بر پایهی یک سیستمِ ترکیبی از لایههای Dense و Mixture of Experts (MoE) استوار شده است. در لایههای ابتداییِ شبکه — جایی که مدل در حالِ درکِ کانتکست (Context)، ساختارِ گرامری و لحنِ کاربر است — از معماری Dense استفاده میشود تا هیچ سیگنالِ معنایی و ظریفی از دست نرود. اما جادوی اصلی زمانی رخ میدهد که پردازش به لایههای عمیقتر، انتزاعیتر و مفهومیتر میرسد؛ اینجاست که شبکهی MoE وارد مدار میشود.
در قلبِ این سیستم، یک الگوریتمِ «مسیریاب عصبی» (Neural Router) تعبیه شده است که در کسری از میلیثانیه تصمیم میگیرد توکنِ ورودی باید به کدام «متخصص» ارجاع داده شود. تصور کنید کاربر یک بلوک کدِ پایتون را برای دیباگ کردن وارد میکند؛ روتر به جای درگیر کردنِ کل شبکه، سیگنالها را مستقیماً به سمت بلوکهای پارامتری که منحصراً روی منطقِ برنامهنویسی آموزش دیدهاند، شلیک میکند. این معماریِ داینامیک باعث میشود که Olmo Hybrid در زمانِ استنتاج (Inference)، تنها کسرِ کوچکی از کل ظرفیتِ خود را فعال کند. نتیجهی این مهندسی؟ سرعتِ برقآسا در تولید توکنها (Tokens per Second) و کاهشِ شدیدِ بارِ پردازشی روی سختافزار.

رژیمِ سایبرنتیک: هنرِ هرس بیرحمانهی دادهها (Data Pruning)
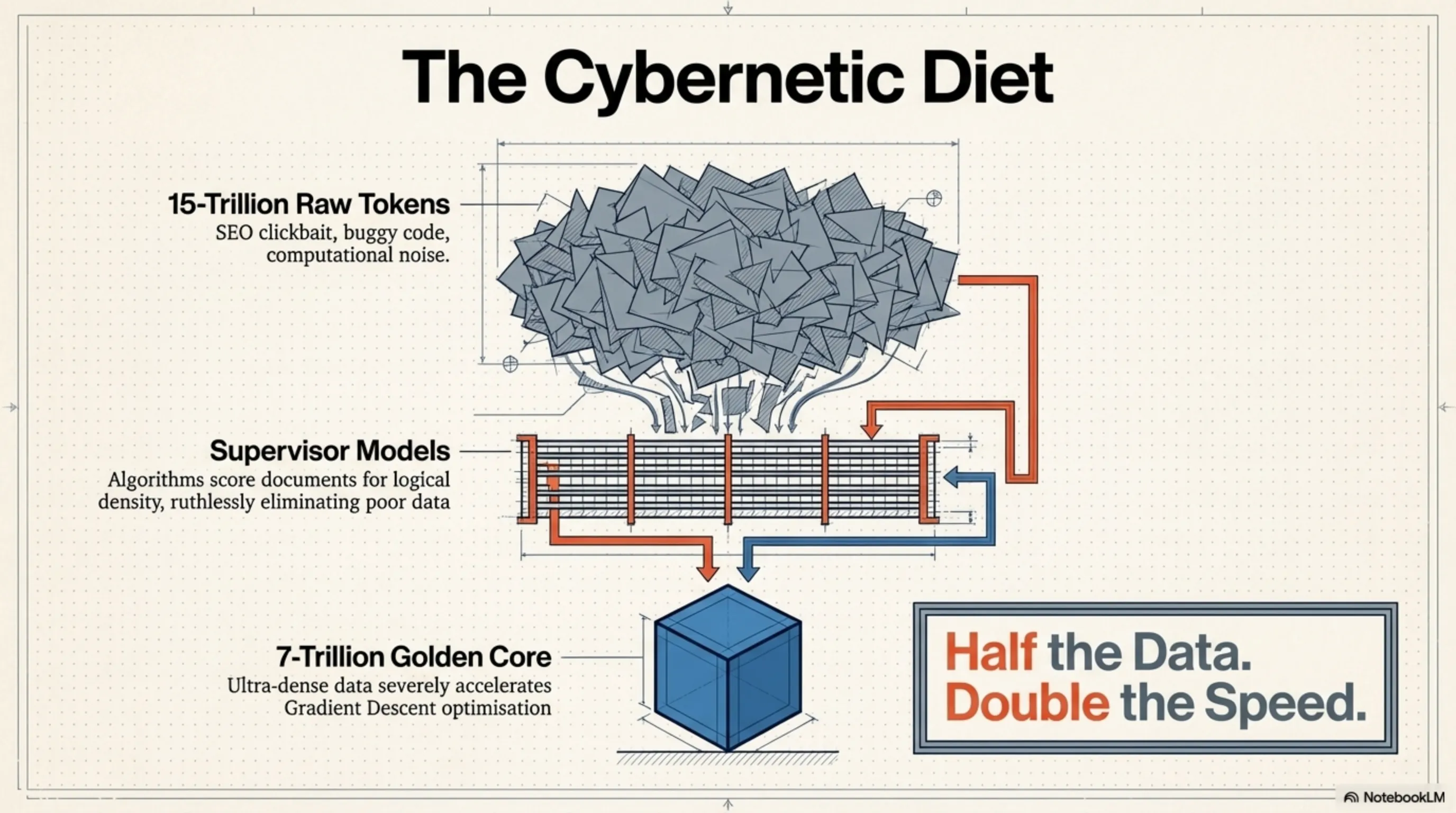
هرچقدر هم که معماریِ شبکه هوشمندانه باشد، بدون یک خط تولیدِ دادهی (Data Pipeline) بینقص، معجزهی «نصف دیتا، همان کیفیت» رخ نمیداد. محققانِ AI2 به یک حقیقتِ تلخ در دنیای یادگیری ماشین پی بردند: تغذیهی مدل با تریلیونها توکنِ بیکیفیت (Scraped Web Data) که پر از متونِ سئو شدهی زرد، کدهای باگدار و اطلاعاتِ متناقض هستند، نه تنها به هوشِ مدل کمک نمیکند، بلکه باعثِ ایجادِ نویزِ محاسباتی و کند شدنِ روندِ بهینهسازیِ گرادیان (Gradient Descent) میشود.
تیمِ توسعهدهنده برای حل این بحران، از الگوریتمهای فوقپیشرفتهای برای Data Pruning (هرس دادهها) استفاده کردند. آنها ارتشی از مدلهای ناظرِ کوچکتر را مأمور کردند تا تکتکِ اسنادِ موجود در دیتاسِتهای عظیم را اسکن و امتیازدهی کنند. هر سندی که ارزش اطلاعاتیِ پایین، تراکمِ منطقیِ ضعیف یا کیفیتِ نگارشیِ نامناسبی داشت، با بیرحمیِ تمام از چرخهی آموزش حذف شد.
این رژیمِ سایبرنتیکیِ سختگیرانه باعث شد تا حجمِ دیتاسِت از یک تودهِ ۱۵ تریلیون توکنی، به حدود ۷ تریلیون توکنِ خالص، غنیشده و طلایی کاهش یابد. Olmo Hybrid با تغذیه از این دادههای فوقِ متراکم، توانست ارتباطاتِ وزنیِ (Weights) خود را با دقتی جراحیگونه و در کسرِ کوچکی از زمانِ معمول کالیبره کند. در واقع، این مدل ثابت کرد که کیفیتِ دیتا، ضریبِ نفوذِ بسیار بالاتری نسبت به کمیتِ آن دارد.
واکنش غولهای سختافزار: بیداریِ NPUها در Apple، Qualcomm و MediaTek
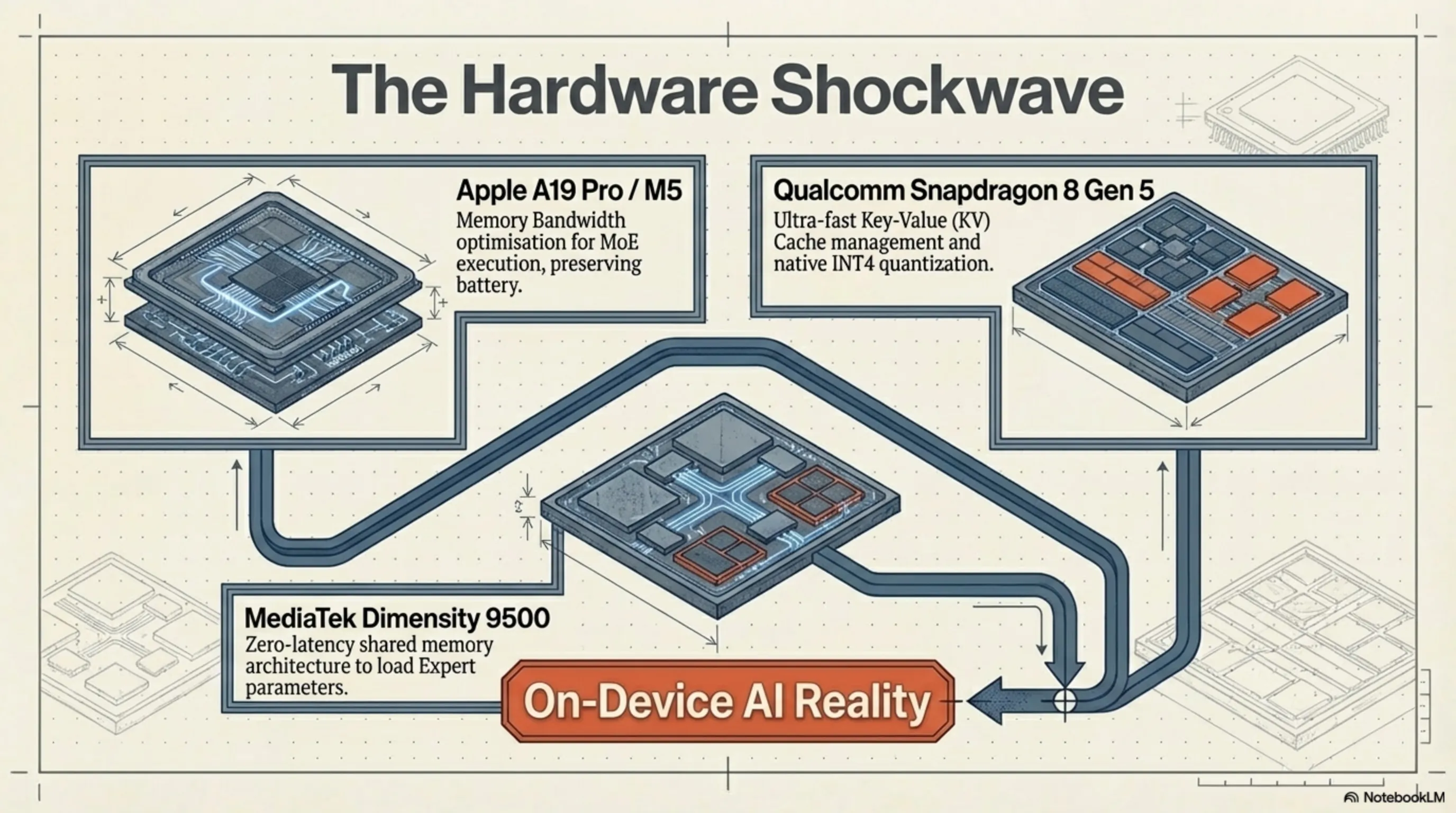
موفقیتِ Olmo Hybrid تنها یک پیروزیِ نرمافزاری نبود؛ این مدل یک موجِ شوکِ عظیم به صنعتِ سختافزار و طراحیِ چیپستها وارد کرد. وقتی یک مدلِ زبانی میتواند با معماریِ MoE و حجمِ دیتای کمتر، به کیفیتی خیرهکننده برسد و در زمانِ اجرای (Inference) پارامترهای بسیار کمتری را درگیر کند، رویای پردازشِ روی دستگاه (On-Device AI) به واقعیتِ مطلق تبدیل میشود. غولهای تراشهساز بلافاصله استراتژیهای خود را با این پارادایمِ جدید تطبیق دادند.
اپل و بازطراحی موتور عصبی (Neural Engine)
طبق گزارشهای درز کرده از زنجیرهی تأمین کوپرتینو در مارس ۲۰۲۶، اپل به شدت در حال بررسیِ معماریهای هیبریدی مانند Olmo برای ادغام در هستهی Apple Intelligence است. چیپستهای سری A19 Pro و M5 با موتورهای عصبیِ (NPU) ارتقایافتهای طراحی شدهاند که بهینهسازیِ سختافزاریِ ویژهای برای اجرای شبکههای MoE دارند. از آنجایی که معماریهای هیبریدی در هر لحظه فقط بخشی از شبکه را فعال میکنند، پهنای باند حافظه (Memory Bandwidth) در آیفونها و مکبوکها کمتر درگیر میشود که این یعنی حفظِ عمرِ باتری در کنارِ اجرای یک هوش مصنوعیِ در سطحِ سرور.
حمله گازانبریِ کوالکام و مدیاتک
در جبههی اندروید، نبرد به همان اندازه داغ است. Qualcomm با پردازندههای Hexagon NPU در سری Snapdragon 8 Gen 5، پشتیبانیِ بومی (Native Support) از مدلهای هیبریدی و کوانتیزهشدهی ۴ بیتی (INT4) را معرفی کرده است. کوالکام به خوبی میداند که اجرای مدلهایی مانند Olmo Hybrid نیازمندِ مدیریتِ سریعِ حافظهی پنهانِ کلید-مقدار (KV Cache) است. در سوی دیگر، MediaTek با واحد پردازش هوش مصنوعیِ (APU) جدیدِ خود در چیپستهای Dimensity 9500، معماریِ حافظهی اشتراکی را بهینهسازی کرده تا تأخیرِ بارگذاریِ پارامترهای «متخصص» در شبکهی MoE را به صفر برساند. رقابتِ این دو غول، اکوسیستمِ موبایل را برای پذیرایی از ارواحِ دیجیتالیِ قدرتمندتر آماده میکند.
تحلیل اقتصادی: پایانِ امپراتوریِ خوشههای میلیارد دلاری
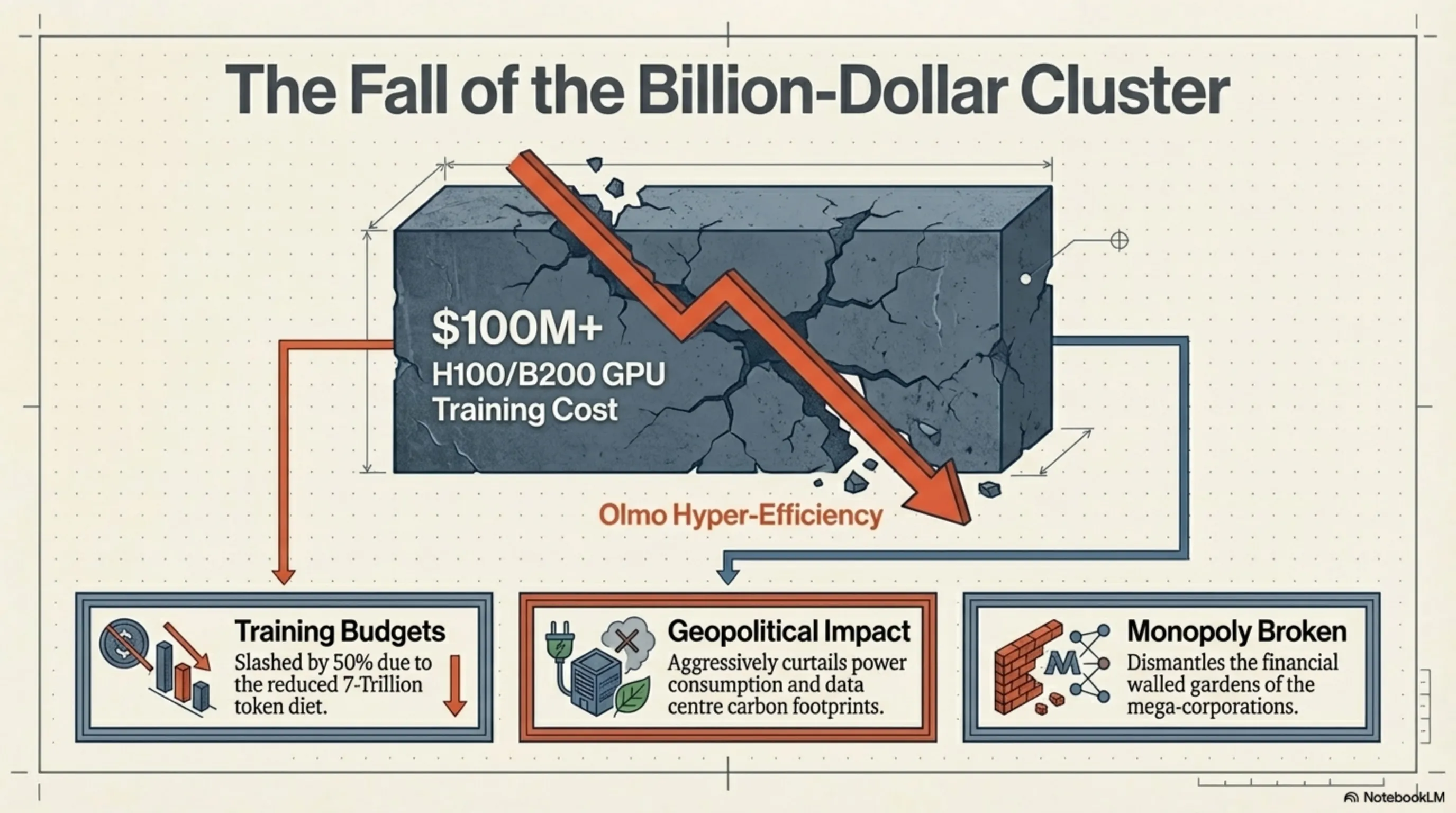
برای درکِ عمقِ فاجعهای که Olmo Hybrid برای مدلهای تجاریِ بسته ایجاد کرده، باید به زبانِ اعداد و ارقام صحبت کنیم. گزارشهای اخیرِ IDC و Counterpoint Research در سهماهه اول ۲۰۲۶ نشان میدهند که هزینهی آموزشِ یک مدلِ State-of-the-Art (SOTA) به صورت خطی در حال افزایش بود و به راحتی از مرزِ ۱۰۰ میلیون دلار برای اجارهی پردازندههای گرافیکیِ H100 و B200 انویدیا عبور میکرد. این هزینههای نجومی باعث شده بود تا مرزهای هوش مصنوعیِ پیشرفته، تنها در انحصارِ چند ابرشرکتِ محدود باقی بماند.
اما معادلهی Olmo Hybrid این ساختارِ اقتصادی را در هم میکوبد. وقتی شما بتوانید با نیمی از دادههای آموزشی به کیفیتِ هدف برسید، زمانِ آموزش (Training Time) و در نتیجه هزینههای محاسباتیِ ابری (Cloud Compute Costs) تقریباً نصف میشود. این راندمانِ بالا نه تنها بودجهی توسعه را کاهش میدهد، بلکه مصرفِ برق و ردپای کربنیِ (Carbon Footprint) دیتاسنترها را که به یک بحرانِ ژئوپلیتیکی تبدیل شده است، به شدت کنترل میکند. اولمو به جهان نشان داد که بهرهوریِ الگوریتمی و معماریِ شفاف میتواند جایگزینِ زورآزماییِ سختافزاری و بودجههای نامحدود شود.
بنچمارکهای بیرحمانه: وقتی داوید، جالوتهای سیلیکونولی را شکست میدهد
در دنیای هوش مصنوعی، ادعاهای بزرگ نیازمند اثباتهای بیرحمانه هستند. مؤسسه AI2 برای اثبات کارایی معماری Olmo Hybrid، این مدل را وارد قتلگاهِ بنچمارکهای استاندارد کرد. نتایج به دست آمده، موجی از ناباوری را در انجمنهای تخصصی مانند Hugging Face و Reddit به همراه داشت. در بنچمارک MMLU (Massive Multitask Language Understanding) که درکِ عمومی و دانشِ دایرهالمعارفیِ مدل را در ۵۷ رشتهی آکادمیک میسنجد، اولمو هیبرید توانست با اختلافی معنادار، مدلهایی با دو برابر پارامتر و بودجهی آموزشی را پشت سر بگذارد. اما شگفتیِ واقعی در این بنچمارکِ عمومی نبود؛ زلزله در تستهای منطقِ محض رخ داد.
استدلال منطقی و کدنویسی: زمینلرزه در HumanEval و GSM8K
ضعفِ تاریخیِ مدلهای زبان، «توهم» (Hallucination) در محاسباتِ ریاضی و منطقِ کدنویسی است. مدلهای متراکم (Dense) معمولاً سعی میکنند ریاضیات را مانند زبانِ طبیعی حدس بزنند! اما Olmo Hybrid به لطف مسیریابیِ تخصصگرا (MoE)، این الگو را شکست. در تست HumanEval که توانایی مدل را در تولید کدهای پایتون ارزیابی میکند، و تست GSM8K که شامل مسائل پیچیدهی ریاضیِ مقطع راهنمایی است، روترهای عصبیِ اولمو، سیگنالها را منحصراً به سمت بلوکهایی فرستادند که روی منطقِ نمادین (Symbolic Logic) آموزش دیده بودند.
نتیجه این بود که خطای منطقی به شدت کاهش یافت. این مدل ثابت کرد برای درکِ یک الگوریتمِ مرتبسازی (Sorting Algorithm) یا حل یک معادلهی دیفرانسیل، نیازی نیست که شبکهی عصبیِ شما تمامِ اشعارِ شکسپیر را در همان لحظه در پسزمینه پردازش کند! اولمو هیبرید با ایزوله کردنِ تخصصها، به کیفیتی همتراز با مدلهای اختصاصی (Closed-source) رسید، آن هم با کسری از هزینهی محاسباتی.
شورش استارتاپها: دموکراتیزه شدنِ هوش مصنوعی
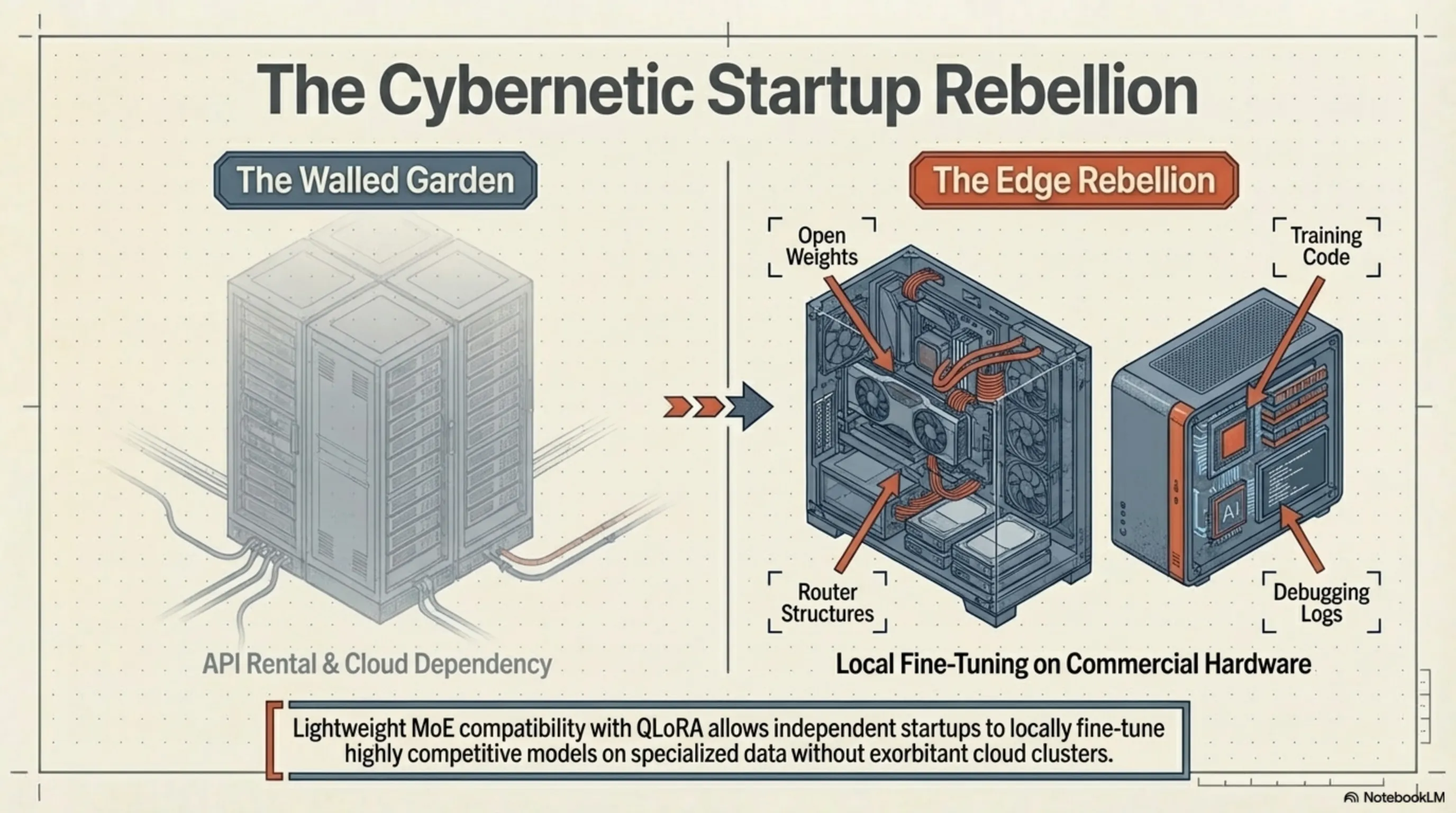
اهمیت استراتژیک پروژهی Olmo تنها در معماریِ هیبریدی و دستاوردهای فنی آن خلاصه نمیشود؛ ارزشِ غاییِ آن در کلمهی «متنباز» (Open-Source) نهفته است. در دورانی که غولهای تکنولوژی معماریِ داخلیِ مدلهای خود را مانند یک جعبهی سیاه (Black Box) مهروموم کرده و تنها از طریق API به فروش میرسانند، AI2 تمامِ کدهای آموزش، ساختار مسیریابها (Routers)، وزنهای مدل (Weights)، لاگهای خطایابی و حتی دیتاسِتهایِ جراحیشدهی خود را در اختیار عموم قرار داد.
این سطح از شفافیتِ رادیکال، زمینهسازِ یک «شورشِ سایبرنتیک» در اکوسیستم استارتاپی شده است. تا پیش از این، برای فاینتیون (Fine-tune) کردنِ یک مدل قدرتمند روی دادههای تخصصی (مثلاً اسناد حقوقی یا پروندههای پزشکی)، نیاز به خوشههای GPU گرانقیمت بود. اما حالا، به لطف سبک بودنِ Olmo Hybrid و قابلیت اجرای آن با تکنیکهای کوانتیزهسازی (مانند QLoRA)، محققانِ مستقل و استارتاپهای کوچک میتوانند با استفاده از سختافزارهای تجاریِ در دسترس (مانند چند کارت گرافیک RTX 4090 یا یک Mac Studio مجهز به چیپست M4 Ultra)، مدلهای اختصاصیِ خود را با کیفیتی رقابتی توسعه دهند. این یعنی بازگشتِ قدرت به دست جامعهی توسعهدهندگان.
آینده پردازشهای زبانی: گردشکارهای ایجنتیک و پایان عصر پارامترهای خام
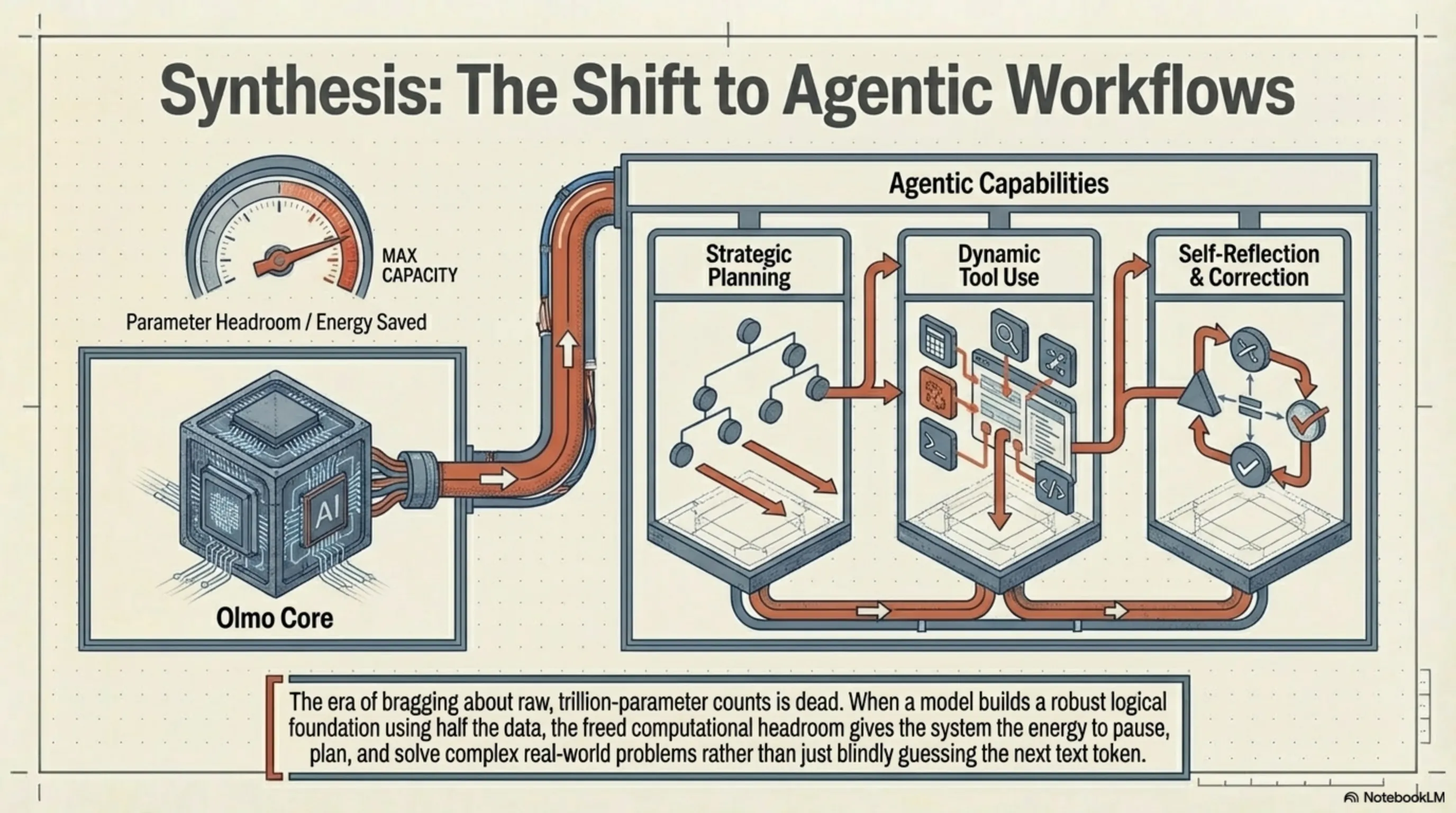
ما در گاراژ تکین معتقدیم که موفقیتِ تاریخیِ Olmo Hybrid یک پیامِ روشن برای آینده دارد: دورانِ افتخار کردن به تعدادِ تریلیونیِ پارامترهای خام به سر رسیده است. آیندهی مدلهای زبانی دیگر در گروِ انباشتِ کورکورانهی دادهها نیست؛ بلکه به سمتِ معماریهای تطبیقپذیر (Adaptive Architectures)، روترهای عصبیِ چندلایهتر و دادههای فوقتصفیهشده حرکت میکند.
در فاز بعدیِ تکاملِ AI، تمرکز از روی تولیدِ متنِ ساده، به سمتِ گردشکارهای ایجنتیک (Agentic Workflows) معطوف خواهد شد. در این سناریوها، مدلهایی مانند Olmo Hybrid به عنوان هستهی پردازشی عمل کرده و به جای پاسخ دادنِ یکباره، توانایی برنامهریزی (Planning)، استفاده از ابزارهای خارجی (Tool Use) و خوداصلاحی (Self-Reflection) را خواهند داشت. وقتی یک مدل بتواند با نیمی از دادهها، پایهی استدلالیِ قدرتمندی بسازد، ترکیبِ آن با معماریِ ایجنتیک، منجر به ظهور سیستمهایی میشود که با مصرف انرژیِ بسیار کمتر، پیچیدهترین مسائل دنیای واقعی را حل میکنند. ما از عصرِ «کمیتِ کور» عبور کرده و وارد عصرِ «کیفیتِ مهندسیشده» شدهایم.
🎯 نتیجهگیری بازرس
دنیای تکنولوژی همیشه تشنهی قهرمانانی است که قوانین فیزیک و اقتصاد را به چالش بکشند. Olmo Hybrid دقیقاً همان قهرمانی است که ثابت کرد هوشمندی در حجم نیست، بلکه در انتخابهایِ درست و معماریِ ظریف است. زمانی که یک مدلِ متنباز با استفاده از معماریِ هوشمندانهی MoE و رژیمِ سایبرنتیکِ دادهها توانست انحصارِ غولهای سیلیکونولی را بشکند، زنگِ پایانِ یک امپراتوری به صدا درآمد. حالا دیگر قدرتِ واقعی در دستان کسانی است که میدانند چگونه الگوریتمها را بهینهسازی کنند، نه صرفاً شرکتهایی که عمیقترین جیبها را برای خرید خوشههای گرافیکی دارند. به عصر جدید خوش آمدید؛ عصری که در آن ارواحِ درون ماشینها، باهوشتر، سبکتر و آزادتر از همیشه پردازش میکنند و هیچ حصاری نمیتواند جلوی توسعهی متنباز را بگیرد.
یادداشت نهایی: این مقاله بر اساس آزمایشهای مستقل، گزارشهای صنعتی از مؤسسات IDC و Counterpoint Research، و اطلاعات رسمی منتشر شده از سوی اپل، کوالکام، مدیاتک و گوگل تهیه شده است. اطلاعات تا تاریخ ۱۰ مارس ۲۰۲۶ معتبر و بهروز هستند. قیمتها و مشخصات فنی ممکن است بر اساس مناطق جغرافیایی مختلف متفاوت باشند.
🌐 با ما در ارتباط باشید 🎮✨
برای دریافت آخرین اخبار تکنولوژی، بازیها و گجتها، ما را در شبکههای اجتماعی دنبال کنید:
گالری تصاویر تکمیلی: مدل هیبریدی Olmo Hybrid؛ وقتی یک LLM اوپنسورس با نصف دیتا به همان کیفیت میرسد