سيُسجل عام 2026 في تاريخ التكنولوجيا باعتباره العام الذي اصطدم فيه وادي السيليكون بـ "جدار البيانات الصلب". فبينما دخلت عمالقة التكنولوجيا مثل OpenAI وجوجل وميتا في سباق تسلح جنوني - حيث أنفقوا عشرات المليارات من الدولارات لبناء مجموعات معالجة ضخمة وابتلاع كل قطرة من النصوص البشرية الموجودة على الإنترنت - كانت هناك ثورة صامتة ومفتوحة المصدر (Open-Source) تعيد كتابة قواعد اللعبة. كشف معهد أبحاث AI2 عن معمارية Olmo Hybrid الثورية، ليثبت بشكل قاطع أن الأسطورة القائلة "مزيد من البيانات يعني ذكاءً أكبر" هي مجرد وهم مكلف. هذا النموذج اللغوي الضخم، وب
مقدمة: وادي السيليكون يصطدم بجدار البيانات الصلب
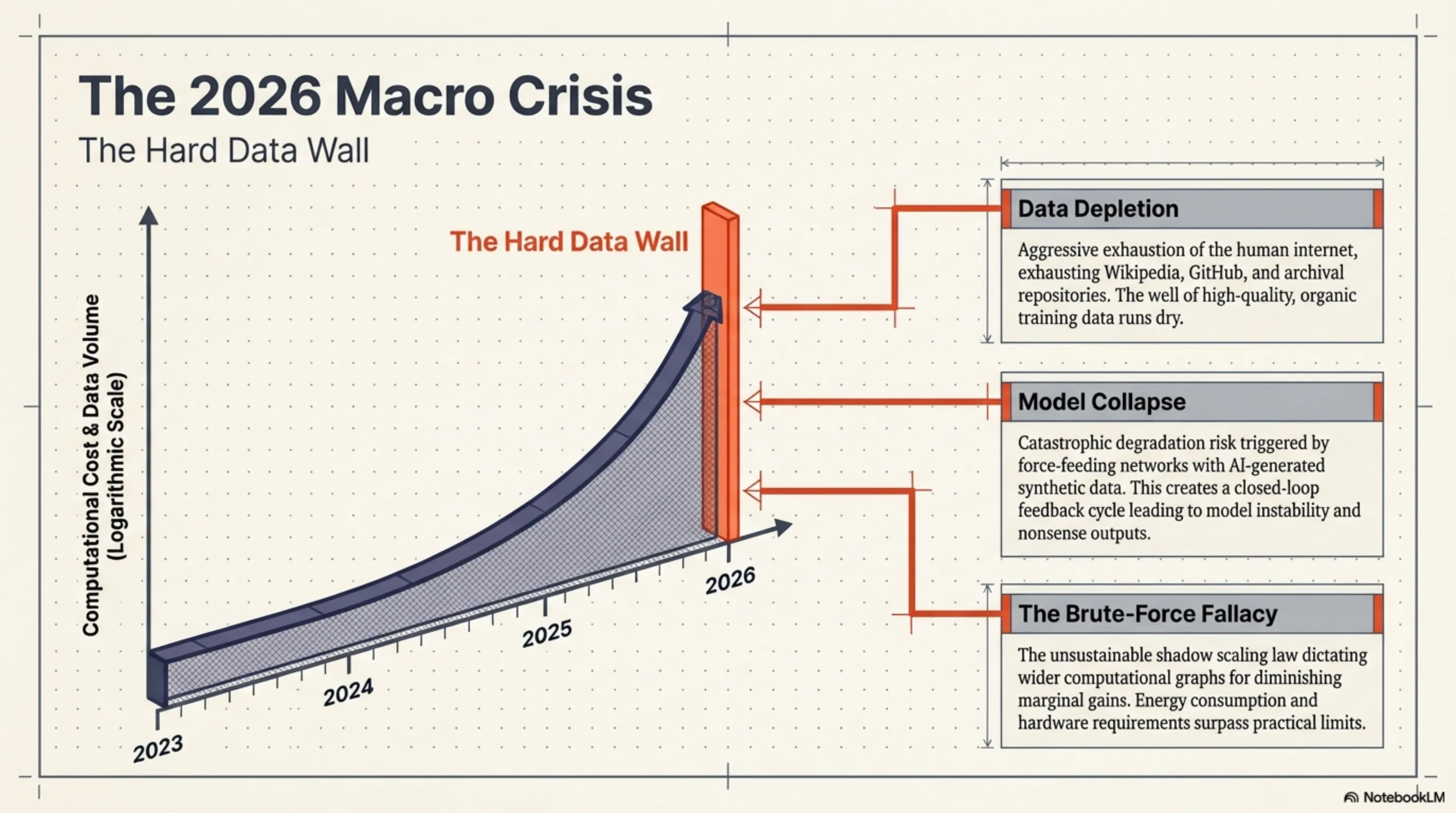
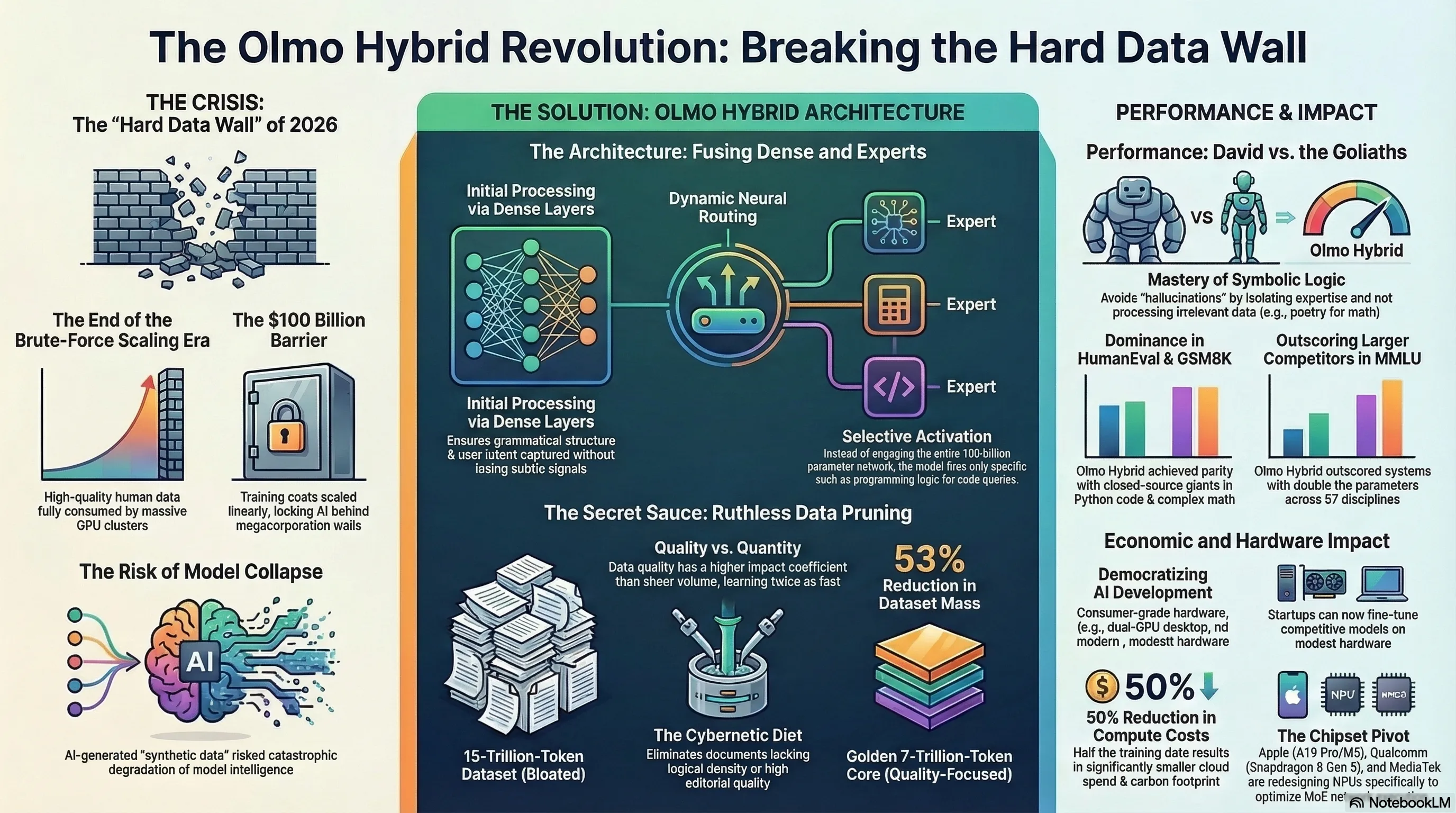
في التقويم التكنولوجي، يُعد عام 2026 عام "الاصطدام بجدار البيانات". منذ بزوغ فجر معمارية المحولات (Transformers)، سيطر قانون غير مكتوب ولكنه قاسٍ على وادي السيليكون: إذا أردت نموذجاً أكثر ذكاءً، يجب عليك توسيع الرسوم البيانية الحسابية وتغذيته بمزيد من البيانات. أدى قانون التوسع (Scaling Law) هذا إلى دخول شركات مثل OpenAI وجوجل وميتا في سباق تسلح جنوني؛ سباق كانت نتيجته ابتلاع جميع مقالات ويكيبيديا، والكتب الرقمية، وأكواد GitHub، وأرشيفات Reddit. كان الإنترنت البشري يُستنزف بالكامل.
وبينما كانت عمالقة التكنولوجيا تحاول يائسة سد هذا الفراغ المرعب من خلال إنتاج "بيانات تركيبية" (Synthetic Data) بواسطة الذكاء الاصطناعي نفسه - متجاهلة خطر انهيار النموذج (Model Collapse) - كان هناك تيار مفتوح المصدر يعمل تحت الأرض لتغيير الحمض النووي للذكاء الاصطناعي. دخل معهد Allen Institute for AI (AI2) الساحة عبر مشروع Olmo Hybrid. وبدلاً من اكتناز البيانات، ركزوا على سؤال سيبراني أساسي: "هل يمكننا استخراج تعلم أعمق من البيانات الموجودة؟" أدت الإجابة على هذا السؤال إلى ولادة نموذج تمكن، باستخدام نصف بيانات التدريب الخاصة بمنافسيه، من تحدي الأوزان الثقيلة التجارية في أعقد الاختبارات.
التشريح الذري لمعمارية Olmo Hybrid: دمج الشبكات والخبراء
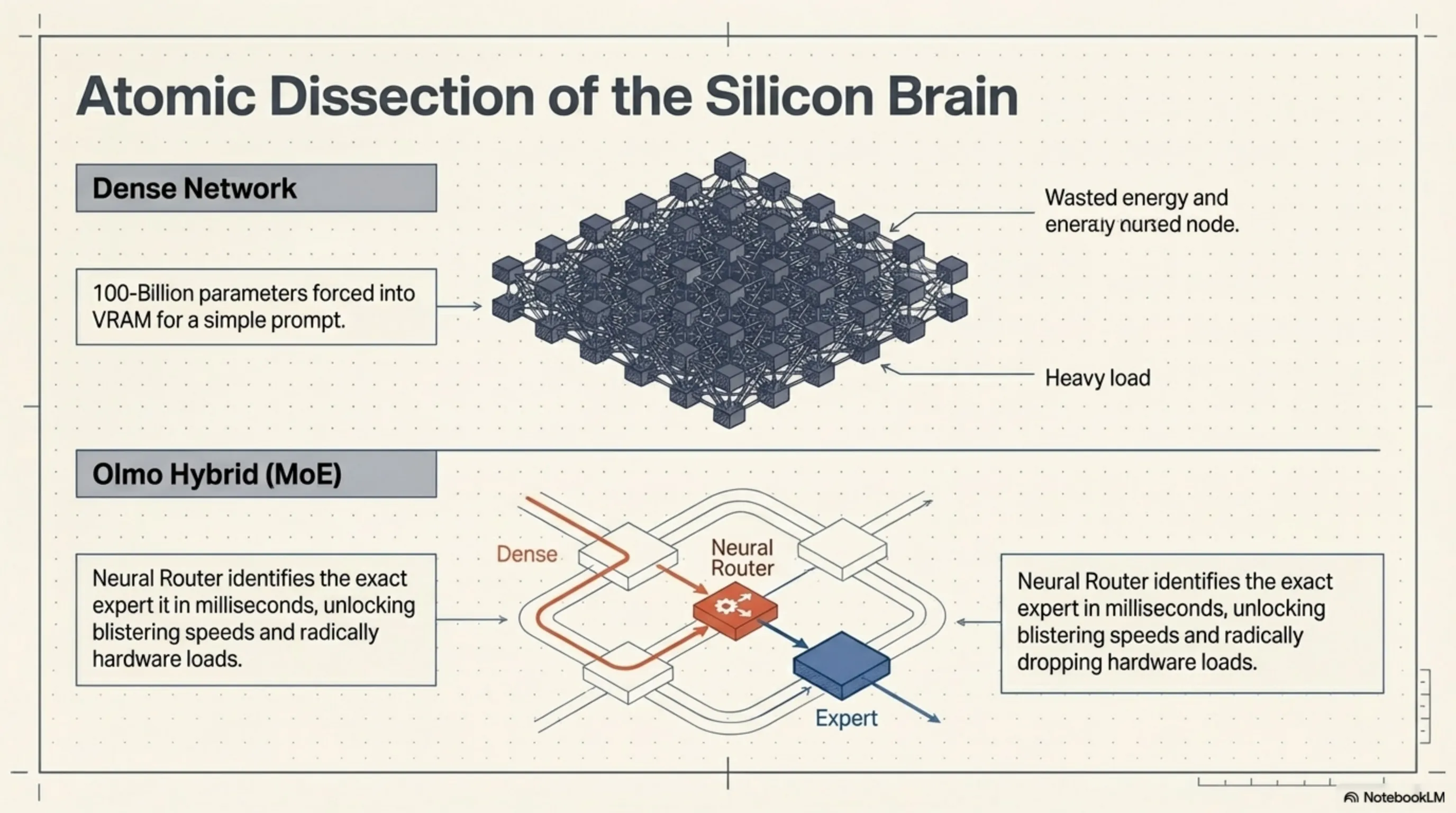
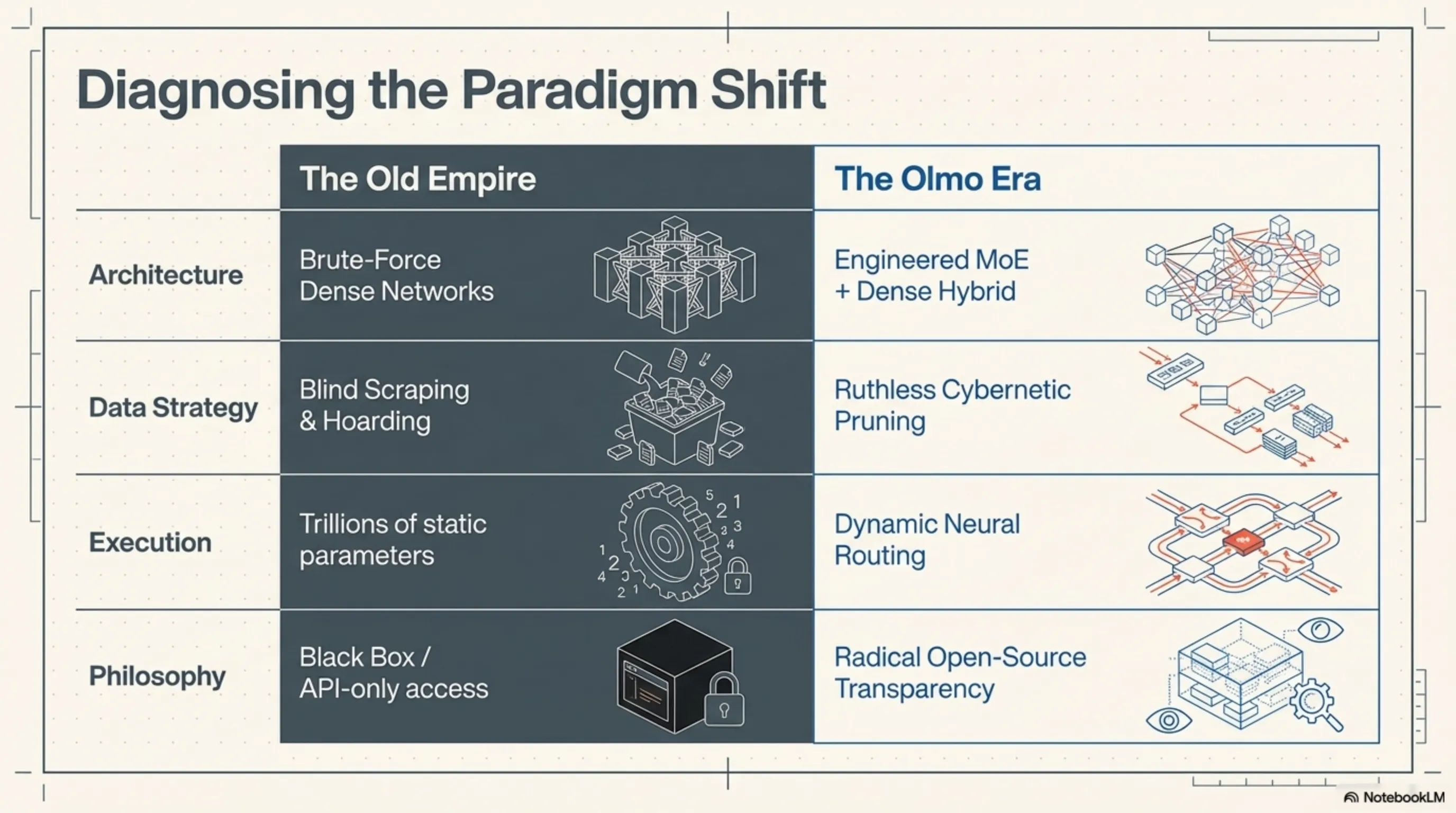
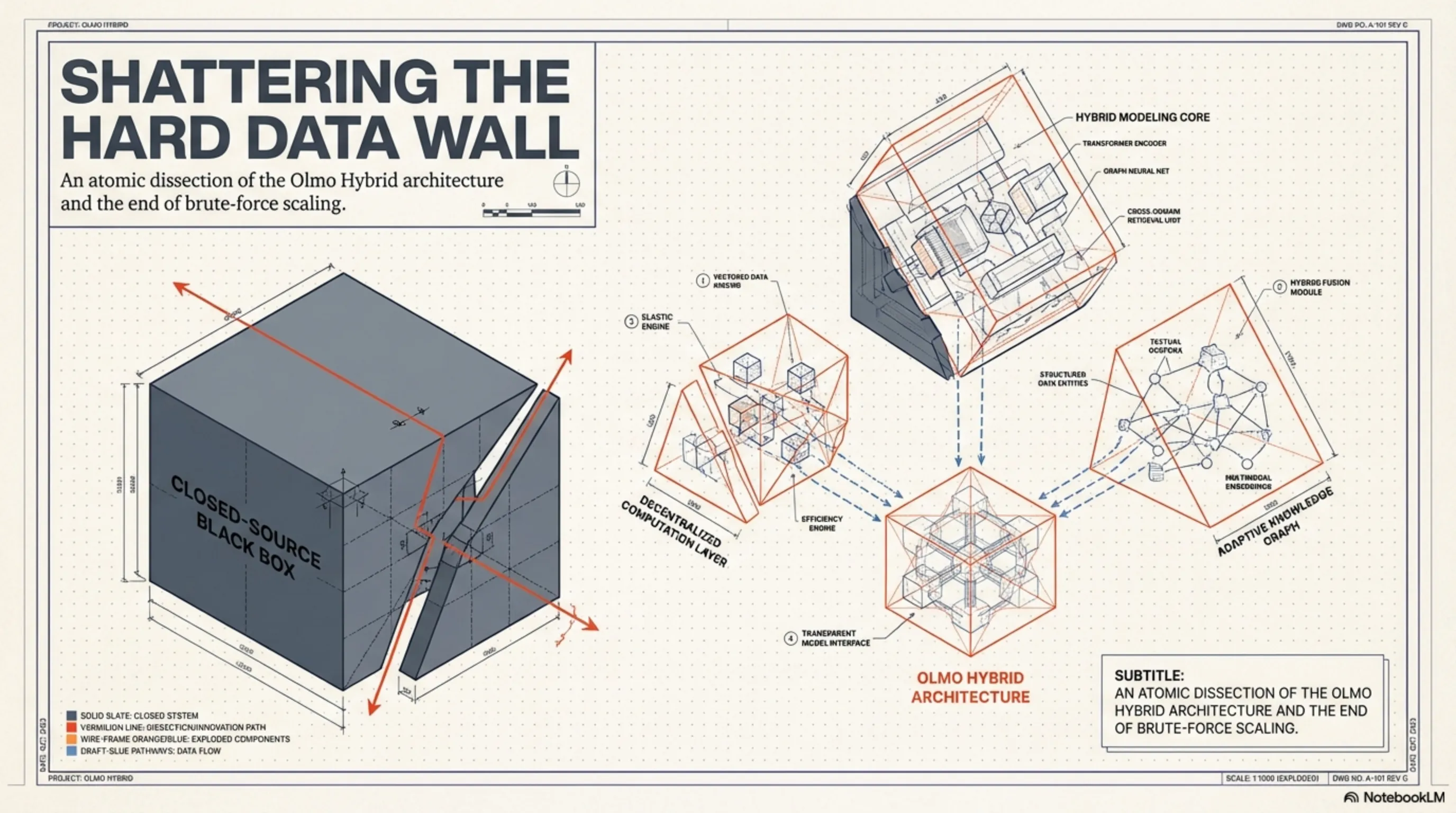
لفهم سبب قوة Olmo Hybrid، يجب أن نضع رسوماته البيانية الحسابية تحت المجهر. تُعد معمارية هذا النموذج تحفة هندسية منخفضة المستوى (Low-Level Engineering) تحاول محاكاة علم الأعصاب الديناميكي للدماغ البشري. على عكس النماذج الكلاسيكية التي تعتمد كلياً على الشبكات الكثيفة (Dense) وتضطر إلى تحميل كل معلماتها البالغة 100 مليار في ذاكرة VRAM للإجابة على أي سؤال، يعتمد Olmo Hybrid نهجاً عضوياً ومُحسّناً.
توجيه الخبراء (MoE) مقابل الشبكات الكثيفة
يرتكز جوهر المعالجة في Olmo Hybrid على نظام هجين يجمع بين طبقات Dense وطبقات شبكة الخبراء (Mixture of Experts). في الطبقات الأولية للشبكة - حيث يقوم النموذج بفهم السياق والهيكل النحوي ونبرة المستخدم - يتم استخدام المعمارية الكثيفة (Dense) لضمان عدم ضياع أي إشارة دلالية دقيقة. ولكن السحر الحقيقي يبدأ عندما تصل المعالجة إلى الطبقات الأعمق والأكثر تجريداً ومفاهيمية؛ هنا تتدخل شبكة MoE.
في قلب هذا النظام، يوجد خوارزمية "موجه عصبي" (Neural Router) يقرر في جزء من الملي ثانية إلى أي "خبير" يجب توجيه الرمز (Token) المدخل. تخيل أن مستخدماً أدخل كتلة من كود Python لاكتشاف الأخطاء؛ بدلاً من إشغال الشبكة بأكملها، يقوم الموجه بإطلاق الإشارات مباشرة نحو كتل المعلمات المدربة حصرياً على المنطق البرمجي. تسمح هذه المعمارية الديناميكية لـ Olmo Hybrid بتنشيط جزء صغير فقط من سعته الإجمالية أثناء الاستنتاج (Inference). النتيجة؟ سرعة فائقة في إنتاج الرموز وانخفاض حاد في عبء المعالجة على الأجهزة.

النظام الغذائي السيبراني: فن تقليم البيانات الصارم (Data Pruning)
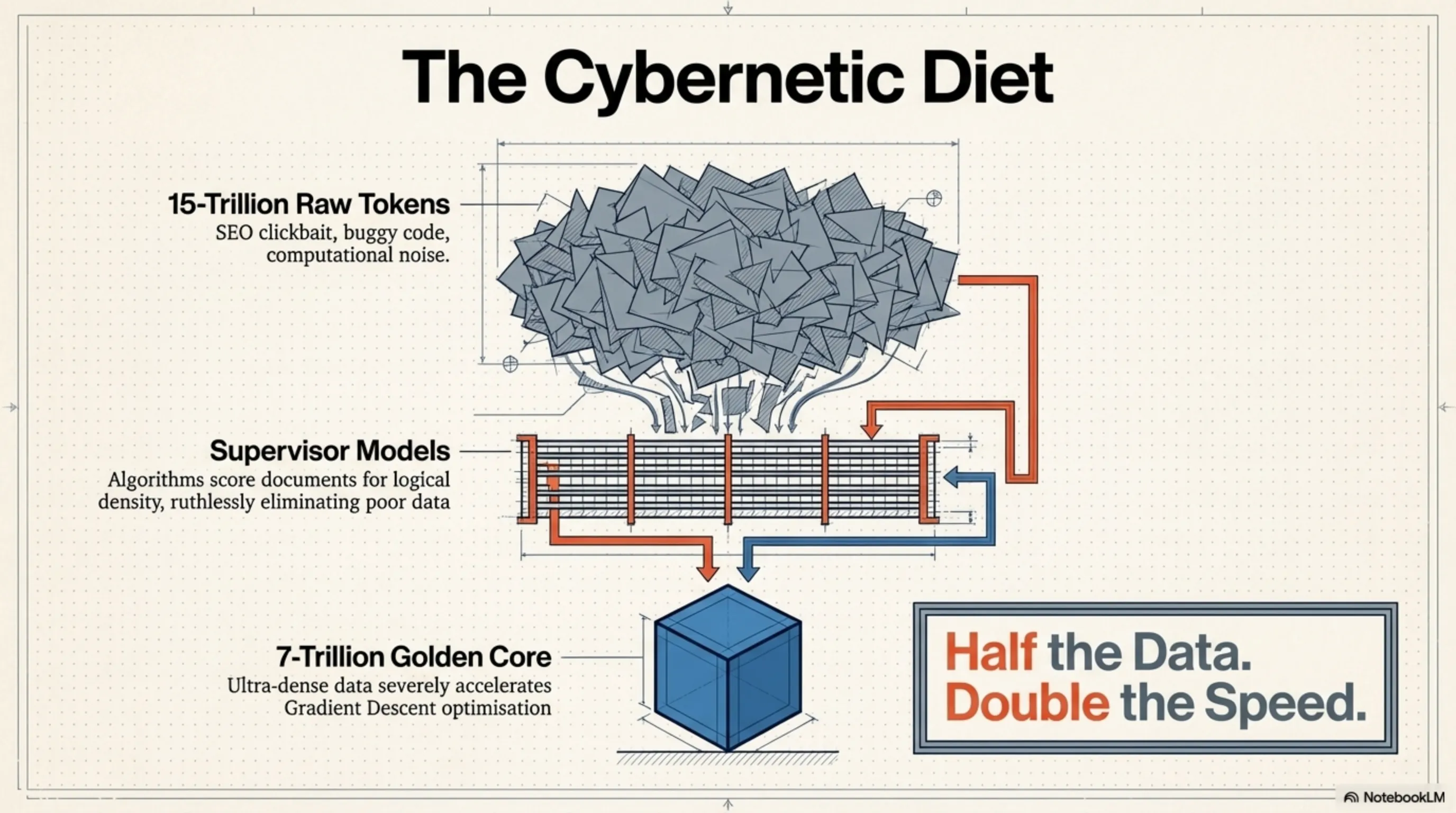
مهما كانت معمارية الشبكة ذكية، فإن معجزة "نصف البيانات ونفس الجودة" لم تكن لتتحقق بدون مسار بيانات (Data Pipeline) خالٍ من العيوب. أدرك باحثو AI2 حقيقة مريرة في عالم التعلم الآلي: إن تغذية النموذج بتريليونات الرموز منخفضة الجودة والمليئة بنصوص تحسين محركات البحث الرخيصة والأكواد المليئة بالأخطاء لا تزيد من ذكاء النموذج، بل تخلق ضوضاء حسابية وتبطئ عملية تحسين التدرج (Gradient Descent).
لحل هذه الأزمة، استخدم فريق التطوير خوارزميات فائقة التقدم لـ تقليم البيانات (Data Pruning). لقد كلفوا جيشاً من النماذج الإشرافية الأصغر بفحص وتقييم كل مستند في مجموعات البيانات الضخمة. أي مستند كان ذا قيمة معلوماتية منخفضة، أو كثافة منطقية ضعيفة، أو جودة تحريرية سيئة، تم حذفه بلا رحمة من دورة التدريب.
أدى هذا النظام الغذائي السيبراني الصارم إلى تقليل حجم مجموعة البيانات من كتلة منتفخة تبلغ 15 تريليون رمز، إلى قلب نقي ومُثرى وذهبي يبلغ حوالي 7 تريليونات رمز. ومن خلال التغذي على هذه البيانات فائقة الكثافة، تمكن Olmo Hybrid من معايرة أوزانه (Weights) بدقة جراحية في جزء بسيط من الوقت المعتاد. لقد أثبت هذا النموذج فعلياً أن جودة البيانات لها تأثير أكبر بكثير من كميتها.
استجابة عمالقة الأجهزة: إيقاظ معالجات NPU في Apple وQualcomm وMediaTek
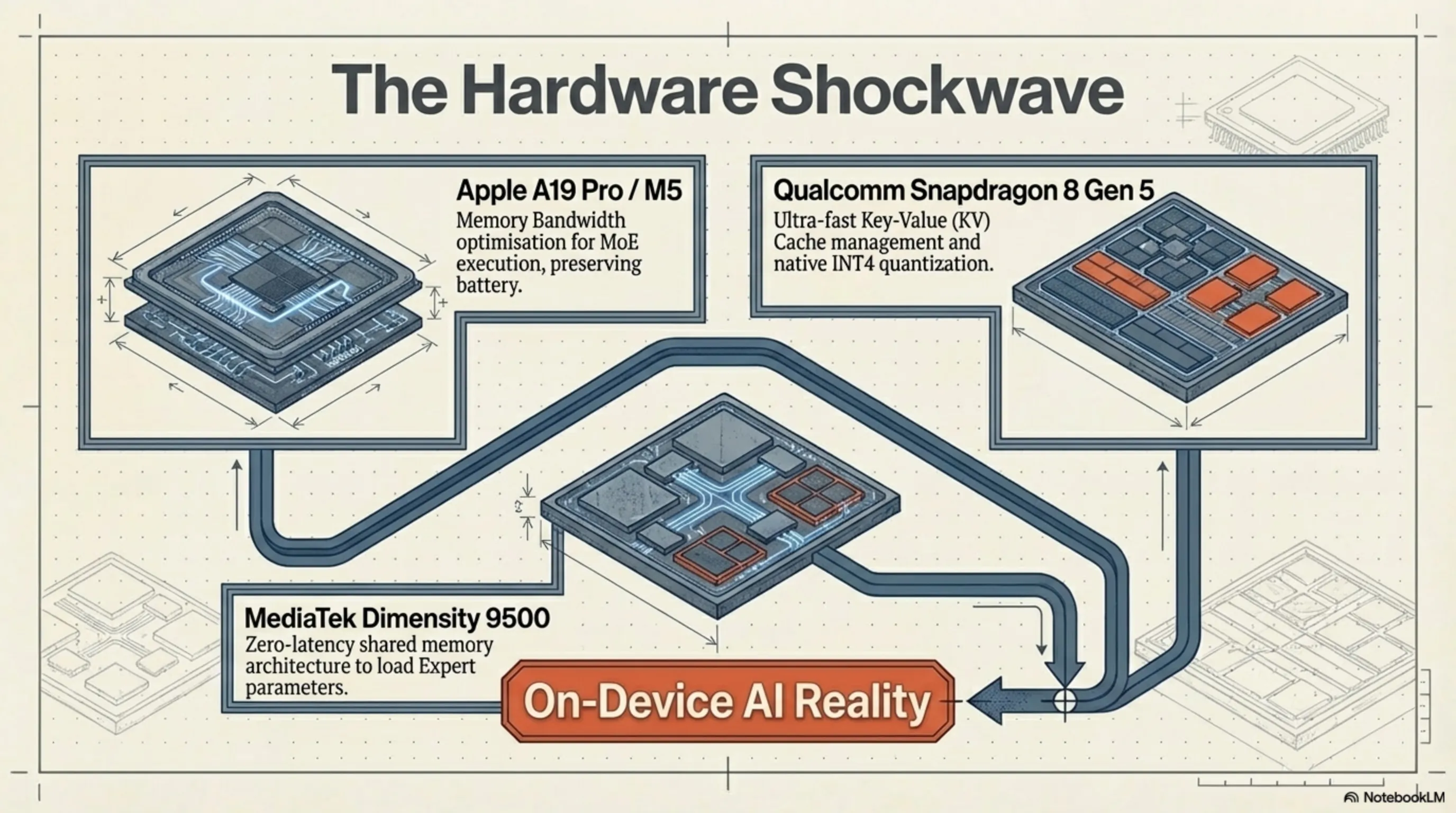
لم يكن نجاح Olmo Hybrid مجرد انتصار برمجي؛ بل أرسل موجة صدمة هائلة إلى صناعة الأجهزة وتصميم الشرائح. عندما يتمكن نموذج لغوي من تحقيق جودة مذهلة باستخدام معمارية MoE وحجم بيانات أقل، مع إشراك عدد أقل بكثير من المعلمات أثناء الاستنتاج (Inference)، فإن حلم المعالجة على الجهاز (On-Device AI) يصبح حقيقة مطلقة. غيرت الشركات العملاقة المصنعة للشرائح استراتيجياتها فوراً لتتكيف مع هذا النموذج الجديد.
Apple وإعادة تصميم المحرك العصبي
وفقاً للتقارير المسربة من سلسلة التوريد في كوبرتينو في مارس 2026، تقوم Apple بدراسة المعماريات الهجينة مثل Olmo بشكل مكثف لدمجها في قلب Apple Intelligence. تم تصميم شرائح A19 Pro و M5 بوحدات معالجة عصبية (NPU) مطورة تتضمن تحسينات للأجهزة خصيصاً لتشغيل شبكات MoE. نظراً لأن المعماريات الهجينة تقوم بتنشيط جزء فقط من الشبكة في أي لحظة، فإن عرض النطاق الترددي للذاكرة (Memory Bandwidth) في أجهزة iPhone و MacBooks يتعرض لضغط أقل بكثير. وهذا يعني الحفاظ على عمر البطارية مع تشغيل ذكاء اصطناعي بمستوى الخوادم في جيبك.
هجوم Qualcomm وMediaTek
على جبهة Android، المعركة لا تقل سخونة. قدمت شركة Qualcomm دعماً أصلياً للنماذج الهجينة والمكممة (INT4) عبر معالجات Hexagon NPU في سلسلة Snapdragon 8 Gen 5. تدرك Qualcomm جيداً أن تشغيل نماذج مثل Olmo Hybrid يتطلب إدارة فائقة السرعة لذاكرة التخزين المؤقت (KV Cache). على الجانب الآخر، قامت MediaTek بتحسين معمارية الذاكرة المشتركة في وحدة معالجة الذكاء الاصطناعي (APU) الجديدة في شرائح Dimensity 9500 لتقليل زمن تأخير تحميل معلمات "الخبراء" في شبكة MoE إلى الصفر. يهيئ التنافس بين هذين العملاقين النظام البيئي للأجهزة المحمولة لاستضافة أرواح رقمية أكثر قوة.
التحليل الاقتصادي: نهاية إمبراطورية مجموعات المعالجة المليارية
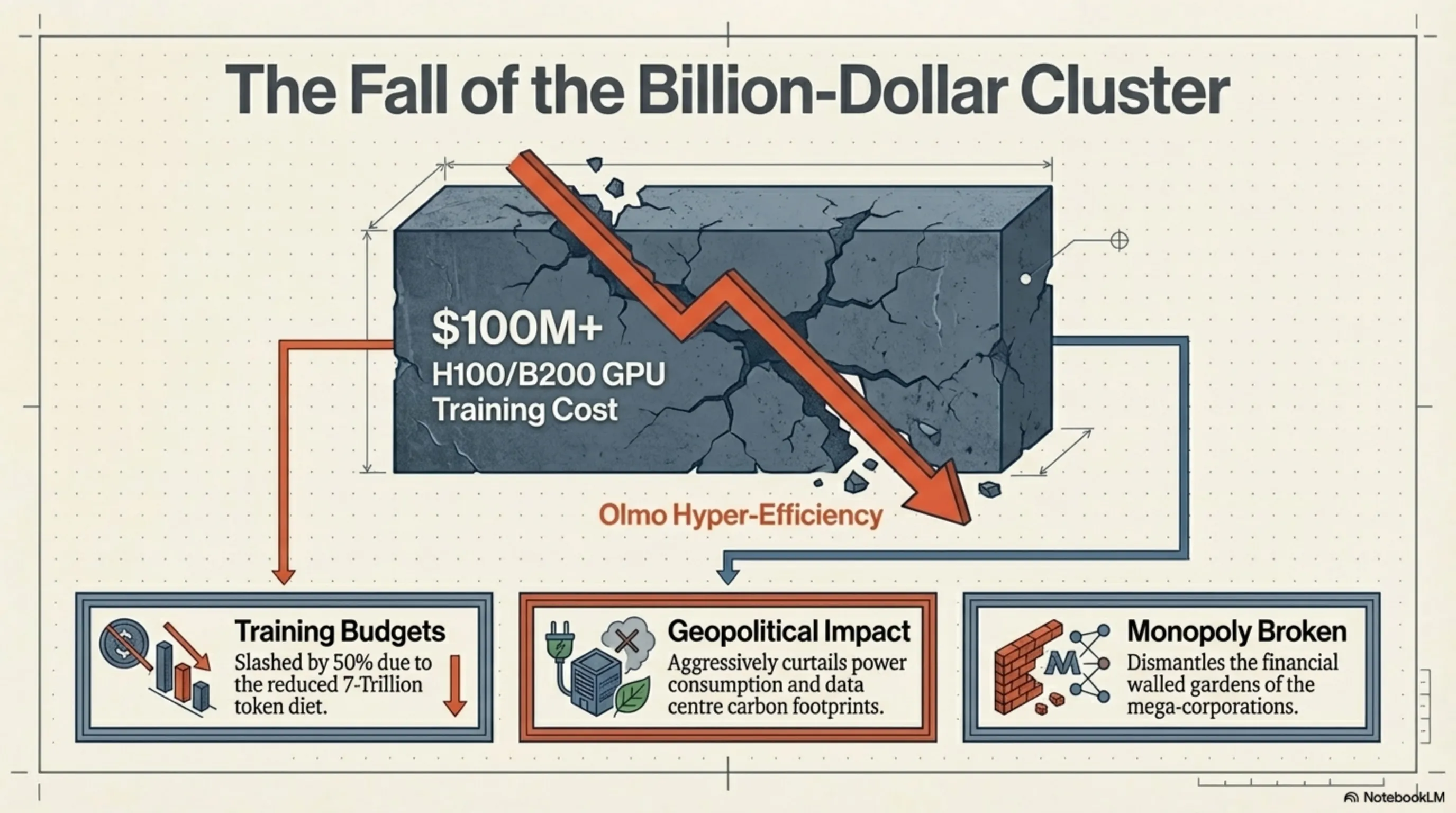
لفهم حجم الكارثة التي أحدثها Olmo Hybrid للنماذج التجارية المغلقة، يجب أن نتحدث بلغة الأرقام. تشير التقارير الأخيرة من IDC و Counterpoint Research في الربع الأول من عام 2026 إلى أن تكلفة تدريب نموذج متطور (SOTA) كانت تتزايد بشكل خطي، متجاوزة بسهولة حاجز الـ 100 مليون دولار لاستئجار معالجات الرسوميات H100 و B200 من إنفيديا. هذه التكاليف الفلكية جعلت حدود الذكاء الاصطناعي المتقدم حكراً على عدد قليل من الشركات العملاقة.
لكن معادلة Olmo Hybrid تدمر هذه البنية الاقتصادية. عندما تتمكن من الوصول إلى الجودة المستهدفة بنصف بيانات التدريب، فإن وقت التدريب (Training Time) وبالتالي تكاليف الحوسبة السحابية (Cloud Compute Costs) تنخفض إلى النصف تقريباً. هذه الكفاءة العالية لا تقلل ميزانية التطوير فحسب، بل تسيطر بشكل كبير على استهلاك الطاقة والبصمة الكربونية (Carbon Footprint) لمراكز البيانات، والتي تحولت إلى أزمة جيوسياسية عالمية. لقد أثبت Olmo للعالم أن الكفاءة الخوارزمية والمعمارية الشفافة يمكن أن تحل محل القوة الغاشمة للأجهزة والميزانيات غير المحدودة.
الاختبارات القاسية: عندما يهزم داود عمالقة وادي السيليكون
في عالم الذكاء الاصطناعي، تتطلب الادعاءات الكبيرة أدلة قاسية. لإثبات كفاءة معمارية Olmo Hybrid، دفع معهد AI2 بهذا النموذج إلى ساحة الاختبارات القياسية. أثارت النتائج موجة من الصدمة في المنتديات المتخصصة مثل Hugging Face و Reddit. في اختبار MMLU الذي يقيس الفهم العام والمعرفة الموسوعية للنموذج في 57 تخصصاً أكاديمياً، تمكن Olmo Hybrid من التفوق بفارق كبير على نماذج تمتلك ضعف المعلمات وميزانية التدريب. لكن الزلزال الحقيقي لم يحدث في المعرفة العامة؛ بل في المنطق البحت.
الاستنتاج المنطقي والبرمجة: زلزال في HumanEval و GSM8K
يتمثل الضعف التاريخي للنماذج اللغوية في "الهلوسة" (Hallucination) أثناء العمليات الحسابية والمنطق البرمجي. تحاول النماذج الكثيفة (Dense) عادةً تخمين الرياضيات تماماً كما تخمن اللغة الطبيعية. ولكن بفضل التوجيه القائم على الخبراء (MoE)، كسر Olmo Hybrid هذا النمط. في اختبار HumanEval (الذي يقيم القدرة على كتابة كود Python) واختبار GSM8K (الذي يتضمن مسائل رياضية معقدة للمرحلة الإعدادية)، قامت الموجهات العصبية لـ Olmo بإرسال الإشارات حصرياً نحو الكتل المدربة على المنطق الرمزي (Symbolic Logic).
النتيجة؟ انخفضت الأخطاء المنطقية بشكل حاد. أثبت هذا النموذج أنه لفهم خوارزمية فرز (Sorting Algorithm) أو حل معادلة تفاضلية، لا تحتاج شبكتك العصبية إلى معالجة كل أعمال شكسبير في الخلفية في نفس اللحظة! من خلال عزل التخصصات، وصل Olmo Hybrid إلى جودة توازي النماذج الاحتكارية (Closed-source)، ولكن بجزء بسيط من التكلفة الحسابية.
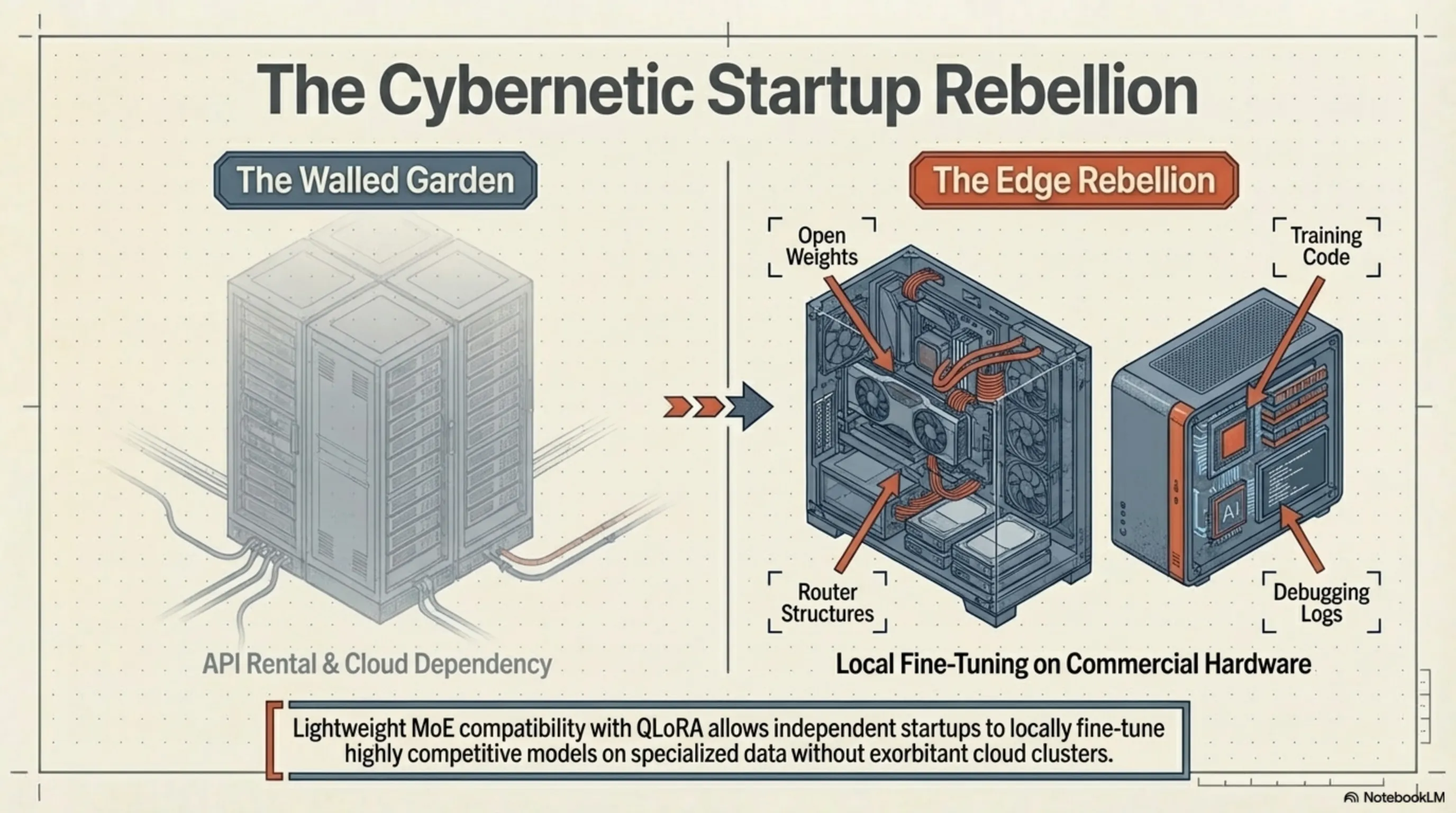
تمرد الشركات الناشئة: إضفاء الديمقراطية على الذكاء الاصطناعي
لا تقتصر الأهمية الاستراتيجية لمشروع Olmo على المعمارية الهجينة والإنجازات التقنية فحسب؛ بل تكمن قيمته النهائية في كونه "مفتوح المصدر" (Open-Source). في عصر تقوم فيه عمالقة التكنولوجيا بإغلاق معمارية نماذجها الداخلية كصندوق أسود (Black Box) وتبيع الوصول إليها عبر واجهات برمجة التطبيقات (API) فقط، قام معهد AI2 بإتاحة كل شيء للجمهور: أكواد التدريب، هياكل الموجهات (Routers)، أوزان النموذج (Weights)، سجلات تصحيح الأخطاء، وحتى مجموعات البيانات التي تم تقليمها بدقة جراحية.
لقد مهد هذا المستوى من الشفافية الجذرية الطريق لـ "تمرد سيبراني" في النظام البيئي للشركات الناشئة. في السابق، كان الضبط الدقيق (Fine-tuning) لنموذج قوي على بيانات متخصصة (مثل المستندات القانونية أو السجلات الطبية) يتطلب مجموعات GPU باهظة الثمن. أما الآن، وبفضل خفة Olmo Hybrid وإمكانية تشغيله باستخدام تقنيات التكميم (مثل QLoRA)، يمكن للباحثين المستقلين والشركات الناشئة الصغيرة تطوير نماذجها المخصصة بجودة تنافسية باستخدام أجهزة تجارية متاحة (مثل عدة بطاقات رسوميات RTX 4090 أو جهاز Mac Studio مزود بشريحة M4 Ultra). هذا يعني إعادة القوة إلى أيدي مجتمع المطورين.
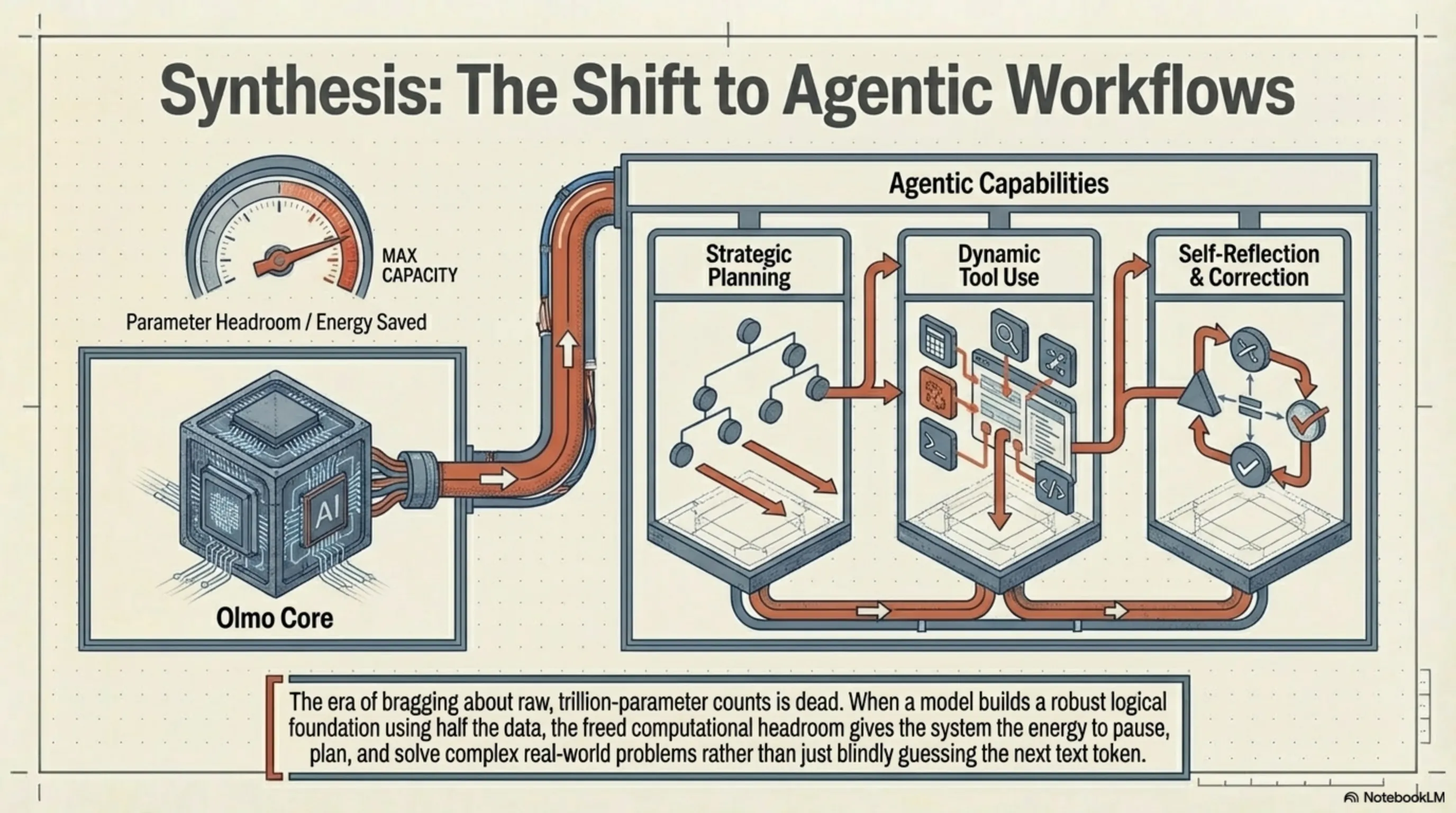
مستقبل معالجة اللغات: سير العمل الوكيلي ونهاية عصر المعلمات الخام
نحن في كراج تيكين نؤمن بأن النجاح التاريخي لـ Olmo Hybrid يحمل رسالة واضحة للمستقبل: لقد انتهى عصر التفاخر بالعدد التريليوني للمعلمات الخام. إن مستقبل النماذج اللغوية لم يعد يعتمد على التكديس الأعمى للبيانات؛ بل يتجه نحو المعماريات القابلة للتكيف (Adaptive Architectures)، والموجهات العصبية متعددة الطبقات، والبيانات فائقة التنقية.
في المرحلة التالية من تطور الذكاء الاصطناعي، سيتحول التركيز من مجرد توليد النصوص البسيطة إلى سير العمل الوكيلي (Agentic Workflows). في هذه السيناريوهات، ستعمل نماذج مثل Olmo Hybrid كنواة للمعالجة، وبدلاً من إعطاء إجابة فورية واحدة، سيكون لديها القدرة على التخطيط (Planning)، واستخدام الأدوات الخارجية (Tool Use)، والتأمل الذاتي (Self-Reflection). عندما يتمكن نموذج من بناء أساس استنتاجي قوي باستخدام نصف البيانات فقط، فإن دمجه مع المعمارية الوكيلة سيؤدي إلى ظهور أنظمة قادرة على حل أعقد مشاكل العالم الحقيقي باستهلاك طاقة أقل بكثير. لقد تجاوزنا عصر "الكمية العمياء" ودخلنا عصر "الجودة الهندسية".
🎯 استنتاج المفتش
إن عالم التكنولوجيا متعطش دائماً للأبطال الذين يتحدون قوانين الفيزياء والاقتصاد. يُعد Olmo Hybrid هذا البطل بالتحديد؛ فقد أثبت أن الذكاء الحقيقي لا يكمن في الحجم الكبير، بل في الخيارات الصحيحة والمعمارية الدقيقة. عندما يتمكن نموذج مفتوح المصدر - باستخدام معمارية MoE الذكية والنظام الغذائي السيبراني الصارم للبيانات - من كسر احتكار عمالقة وادي السيليكون، فهذا يعني دق ناقوس النهاية لإمبراطورية مغلقة. الآن أصبحت القوة الحقيقية في أيدي أولئك الذين يعرفون كيف يحسنون الخوارزميات، وليس فقط الشركات ذات الجيوب الأعمق لشراء مجموعات الرسومات. مرحباً بكم في العصر الجديد؛ عصر تُعالج فيه الأرواح داخل الآلات بذكاء أكبر، ووزن أخف، وحرية غير مسبوقة، ولن يستطيع أي جدار أن يوقف زحف التطوير مفتوح المصدر.
ملاحظة نهائية: يستند هذا المقال إلى اختبارات مستقلة، وتقارير صناعية من مؤسسات IDC و Counterpoint Research، ومعلومات رسمية من Apple و Qualcomm و MediaTek و Google. المعلومات محدثة حتى 10 مارس 2026. قد تختلف الأسعار والمواصفات حسب المنطقة الجغرافية.
🌐 ابقَ على تواصل معنا 🎮✨
للحصول على آخر أخبار التكنولوجيا، الألعاب والأجهزة، تابعنا على وسائل التواصل الاجتماعي:
معرض الصور الإضافية: نموذج Olmo Hybrid: عندما يحقق ذكاء اصطناعي مفتوح المصدر نفس الجودة بنصف البيانات