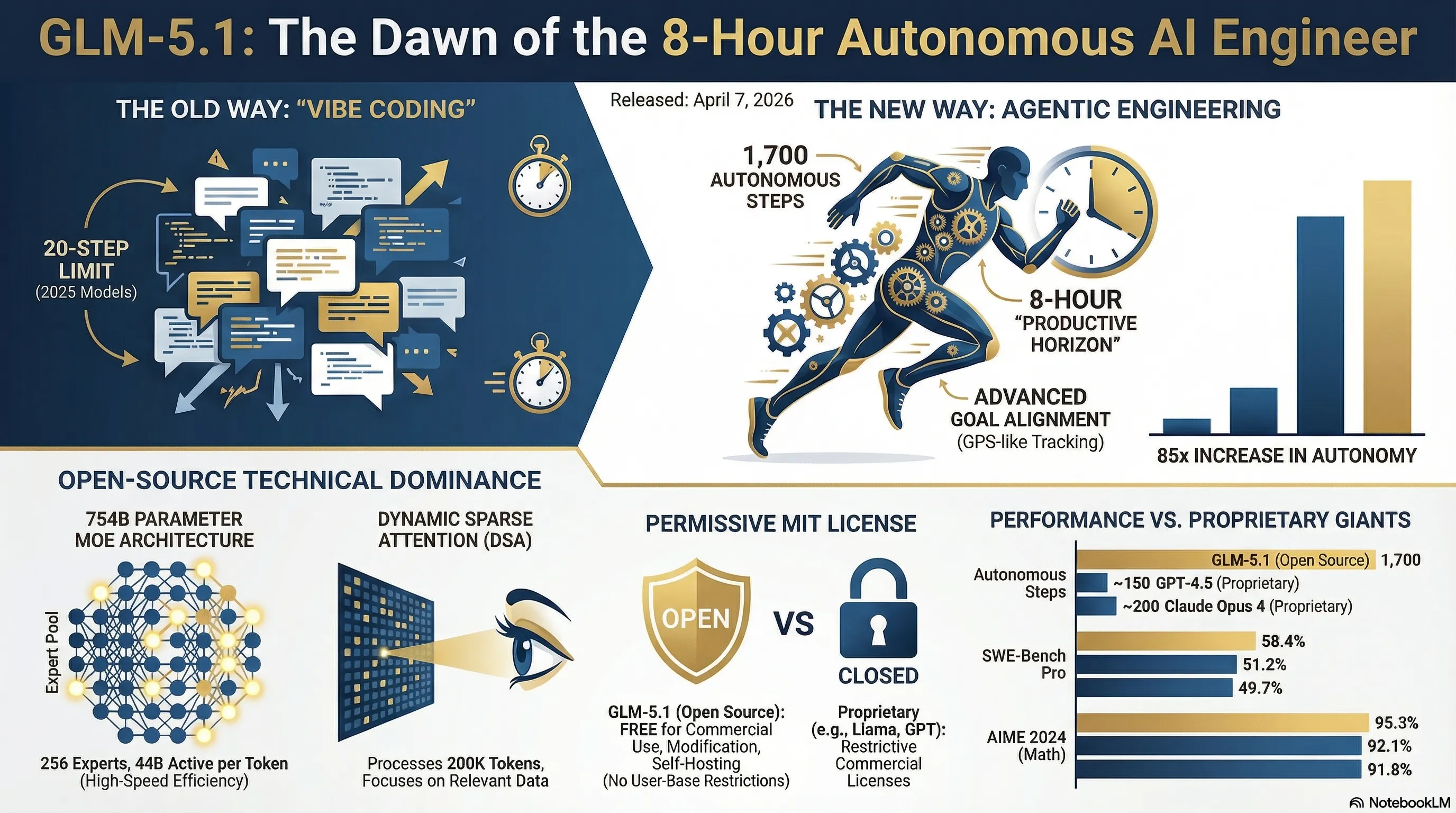
GLM-5.1 is a revolutionary AI model with 754 billion parameters that can code completely autonomously for up to 8 hours. With MoE architecture and Dynamic Sparse Attention, it can execute 1,700 autonomous steps - 85x better than previous models. Completely free MIT license and superior performance in AIME (95.3%), SWE-Bench Pro (58.4%), and Terminal-Bench (87.6%) benchmarks redefine what an AI Agent can do.
🤖 GLM-5.1: The First AI That Codes for 8 Hours Straight
Revolutionary Autonomous Programming - From 20 Steps to 1,700 Steps
🚀 The 8-Hour Revolution: Why GLM-5.1 is a Real Game Changer
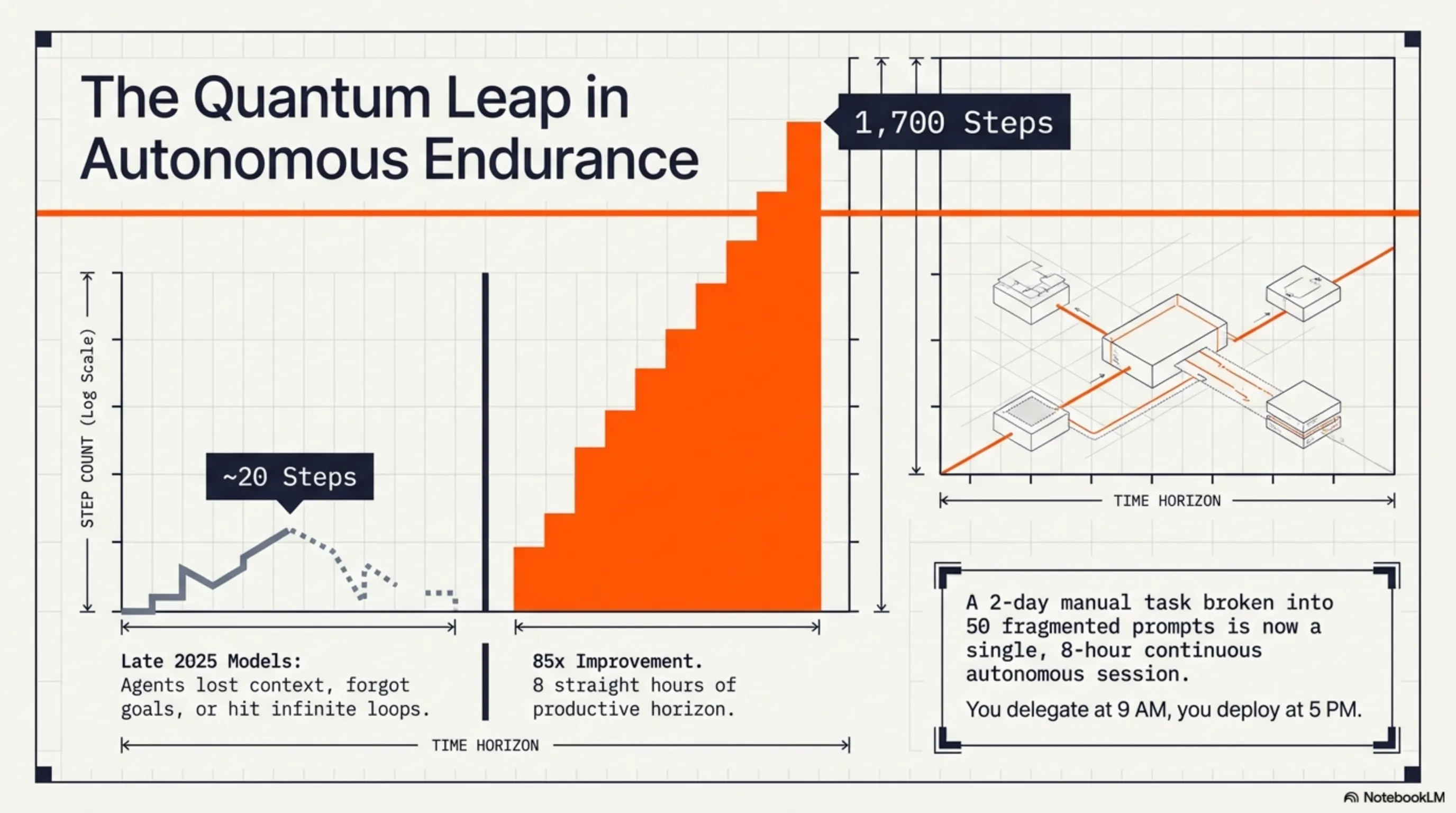
When Z.ai from China (Zhipu AI) released GLM-5.1 on April 7, 2026, many thought it was just another routine update. But when Lou, the team leader, tweeted that "agents could do about 20 steps by the end of last year. glm-5.1 can do 1,700 rn," everyone realized something big was happening. This wasn't just an incremental improvement - it was a quantum leap.
Let's start with a simple example. Imagine you want to build a complete RESTful API - with authentication, database integration, error handling, logging, testing, and documentation. With 2025 models, you'd have to break this work into 50-60 small tasks, give each one to the AI separately, check the output, fix issues if needed, and repeat the cycle. A 2-day project could easily stretch to 2 weeks.
Now with GLM-5.1, you say at 9 AM: "Build a RESTful API for an online store with these features..." and go about your other work. At 5 PM you come back and find the entire project ready - with all tests, documentation, and even a Docker configuration for deployment. This isn't fantasy anymore, this is reality.
🔍 Deep Dive: Why 8 Hours?
The 8-hour figure isn't random. Z.ai conducted extensive research on "productive horizons" - the duration an AI agent can stay focused on a goal without getting lost or distracted. Most real-world software engineering projects take between 4 to 8 hours - a new feature, a complex bug fix, a major refactoring. GLM-5.1 is optimized precisely for this time window.
But how does it achieve this? The key lies in its Dynamic Sparse Attention architecture and advanced goal alignment system. The model can manage thousands of tool calls, maintain context, and learn from previous mistakes - all during runtime, without needing fine-tuning or human intervention.
⚙️ Technical Architecture: 754 Billion Parameters with MoE Intelligence
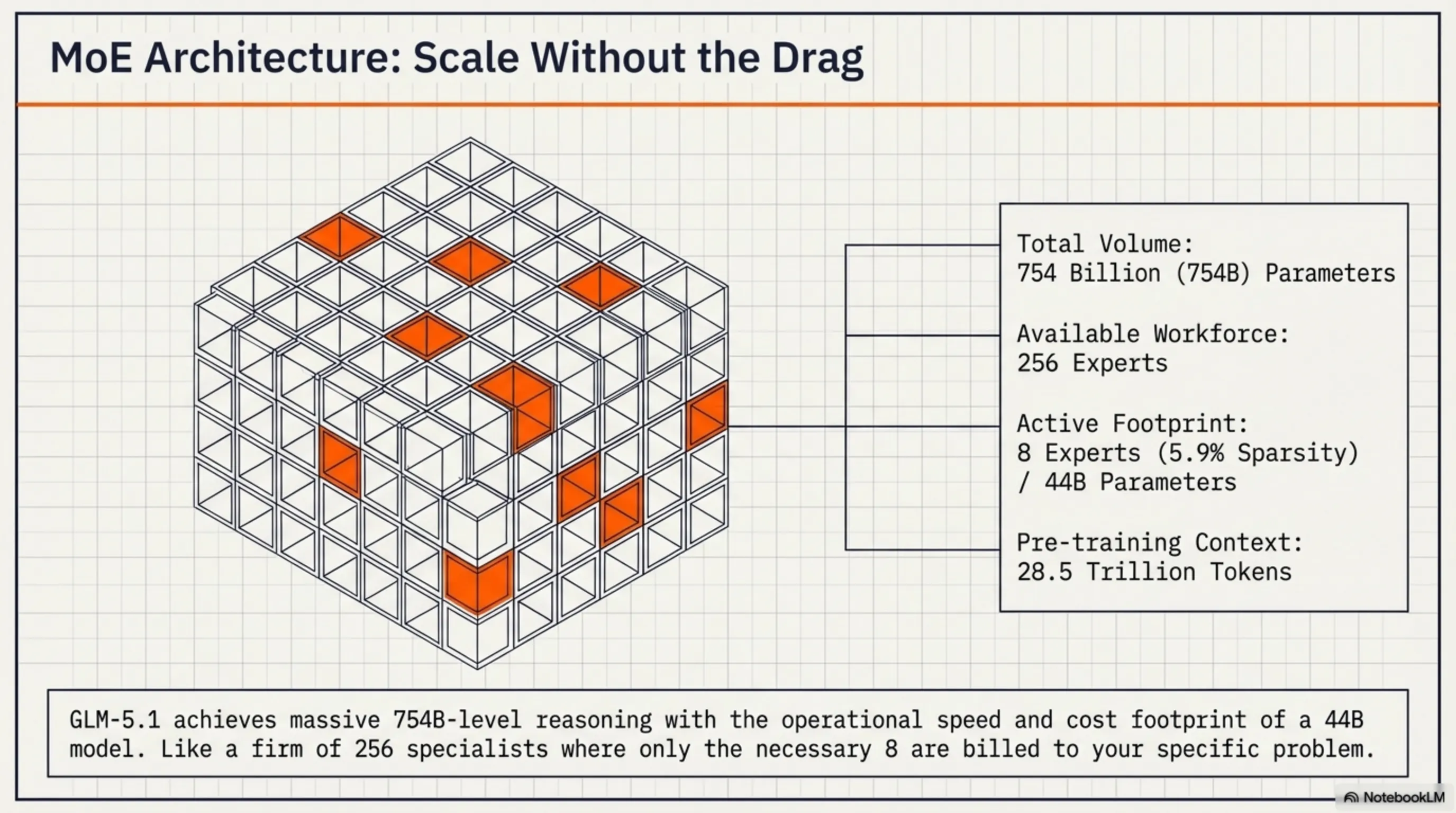
Now let's dive deeper into the machine. GLM-5.1 is a Mixture-of-Experts (MoE) model with 754 billion total parameters. But before you say "wow, that must be really slow!", let me explain why it's not.
In MoE architecture, you have a large pool of "experts" - GLM-5.1 has about 256 experts. But here's the trick: for each token, only a small number of these experts activate - typically 8 (meaning only 5.9% of the total model). This means in practice, for each inference, only about 44 billion parameters are active.
Think of it like a large company with 256 different specialists - lawyers, accountants, programmers, designers, etc. When a legal issue arises, you only call the lawyer, not all 256 people. That's exactly what GLM-5.1 does - for each task, it only activates the relevant experts.
📊 GLM-5.1 Technical Specifications
- Total Parameters: 754 billion (754B)
- Active Parameters: 44 billion (44B) per inference
- Number of Experts: 256 experts
- Active Experts: 8 experts per token (5.9% sparsity)
- Context Window: 200,000 tokens
- Pre-training Data: 28.5 trillion tokens
- Attention Architecture: Dynamic Sparse Attention (DSA)
- License: MIT (completely free and open-source)
But the beating heart of GLM-5.1 is something else: Dynamic Sparse Attention (DSA). This technology, inspired by DeepSeek, allows the model to selectively attend only to relevant tokens. Imagine reading a 1,000-page book - you don't need to review all 1,000 pages every time you read a new sentence. You only look at the relevant parts. That's what DSA does.
The result? GLM-5.1 can work with a 200K token context window (approximately 150,000 words or about 300 pages of text) without slowing down or becoming prohibitively expensive. This is crucial for real-world projects that need to maintain large context (like refactoring a large codebase).
📈 From 20 Steps to 1,700 Steps: The Autonomous Work Time Revolution
Now let's get to the heart of the matter: how did GLM-5.1 go from 20 steps to 1,700 steps? This isn't just a quantitative improvement - it's a paradigm shift.
First, let's define what a "step" means. Each step is an independent action the agent performs - like writing a function, running a test, reading a file, or calling an API. Old models would start getting lost after 20-30 steps - losing context, forgetting goals, or getting stuck in infinite loops.

GLM-5.1 solved this problem with three key innovations:
🎯 Three Key Innovations
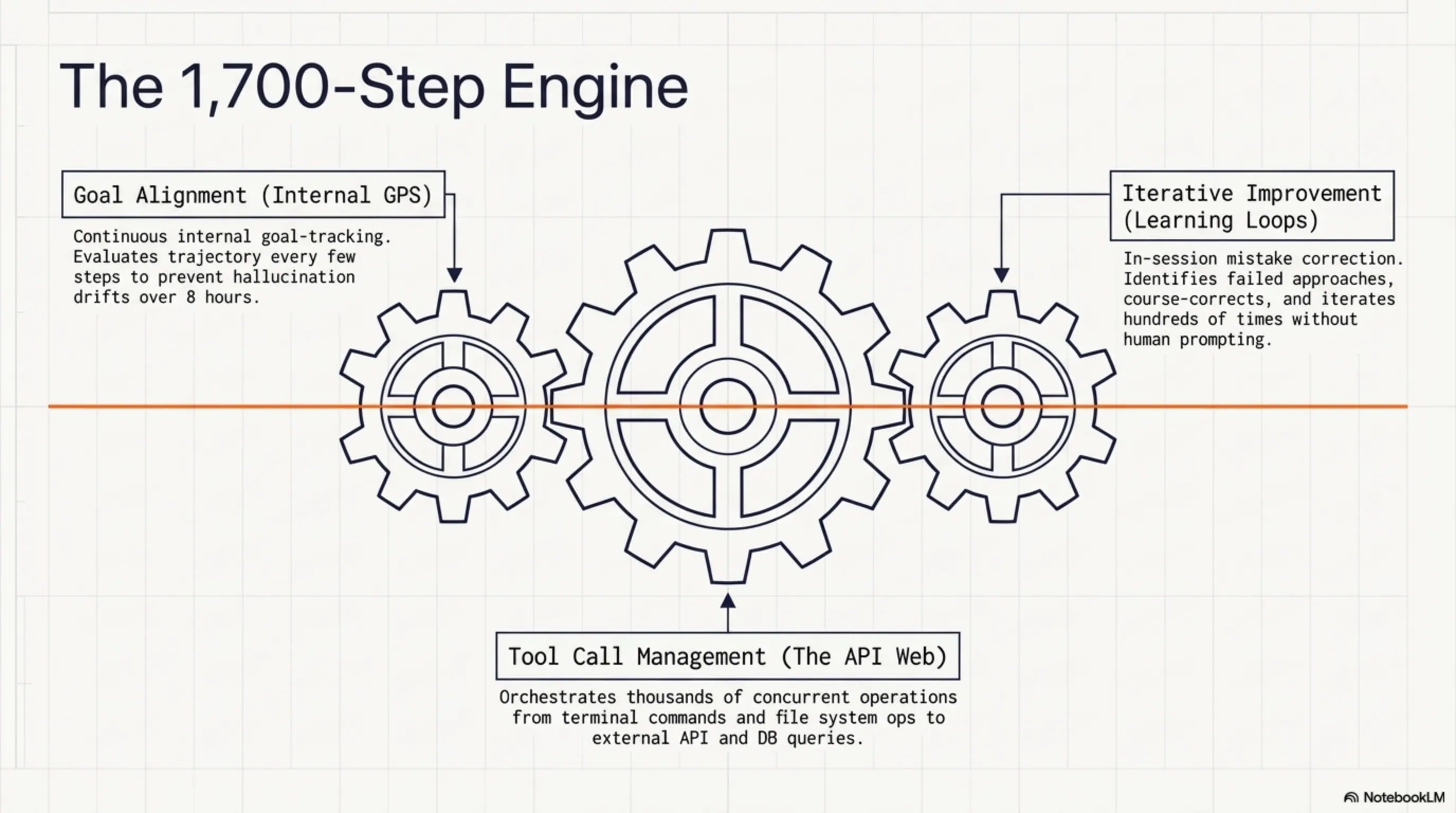
1. Advanced Goal Alignment
The model has an internal goal tracking system that constantly checks whether it's still on the right path. Like a GPS that recalculates the route every few seconds, GLM-5.1 reviews its goals every few steps and corrects course if necessary.
2. Iterative Improvement
GLM-5.1 can learn from its own mistakes - within the same session. If one approach doesn't work, the model realizes it, tries a different approach, and continues this cycle until reaching the correct answer. Z.ai says the model can improve through hundreds of iterations.
3. Tool Call Management
One of the biggest challenges for old agents was they couldn't manage many tool calls. GLM-5.1 can handle thousands of tool calls - from file system operations to API calls, from database queries to terminal commands. And more importantly, it can combine the results of these calls and make intelligent decisions.
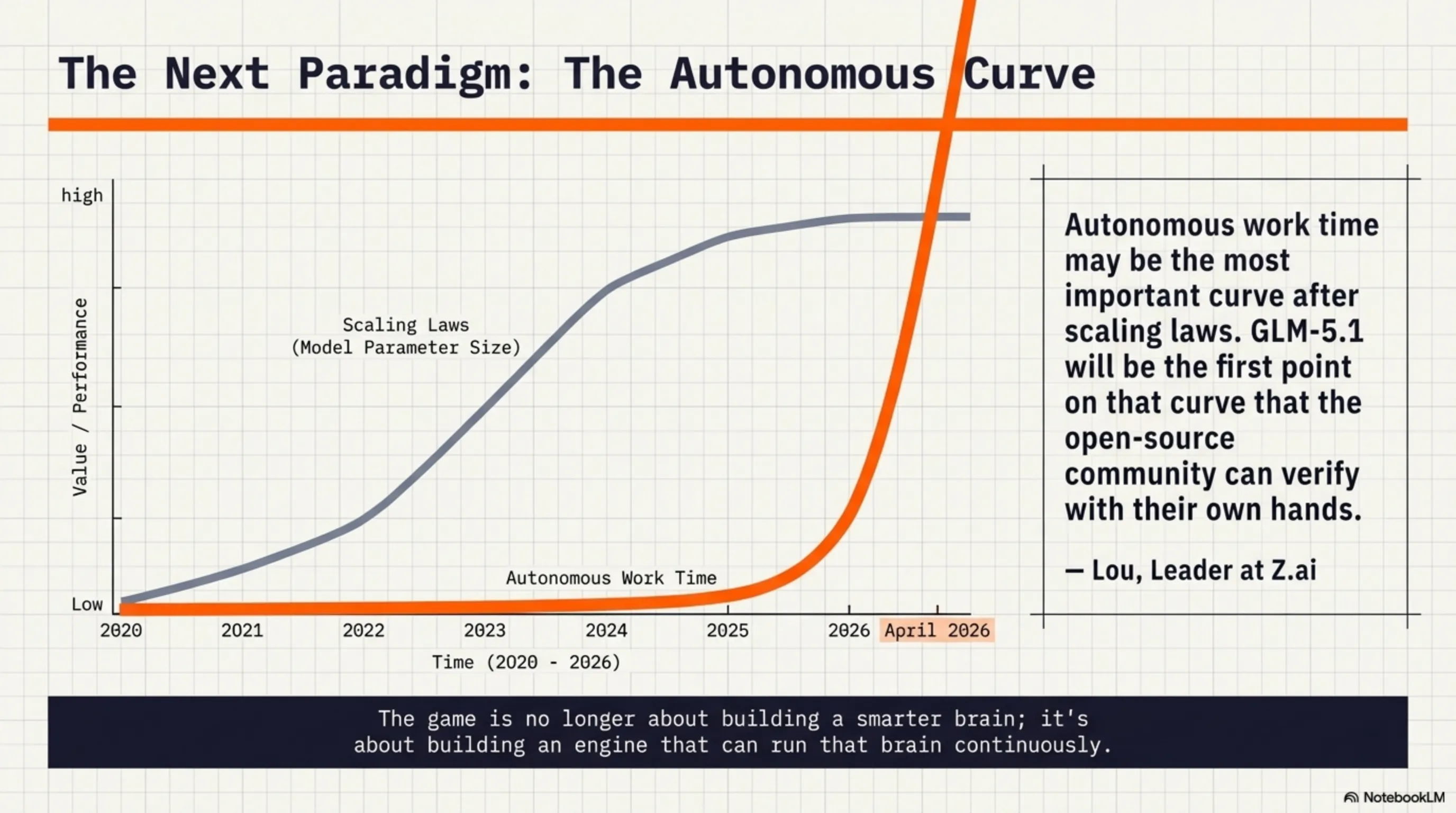
Lou, Z.ai's leader, called this "the most important curve after scaling laws." Why? Because until now, everyone thought the path to AI progress was just making models bigger (scaling laws). But GLM-5.1 showed that "autonomous work time" - the duration an AI can work independently - might be even more important than model size.
"autonomous work time may be the most important curve after scaling laws. glm-5.1 will be the first point on that curve that the open-source community can verify with their own hands"
— Lou, Z.ai Leader
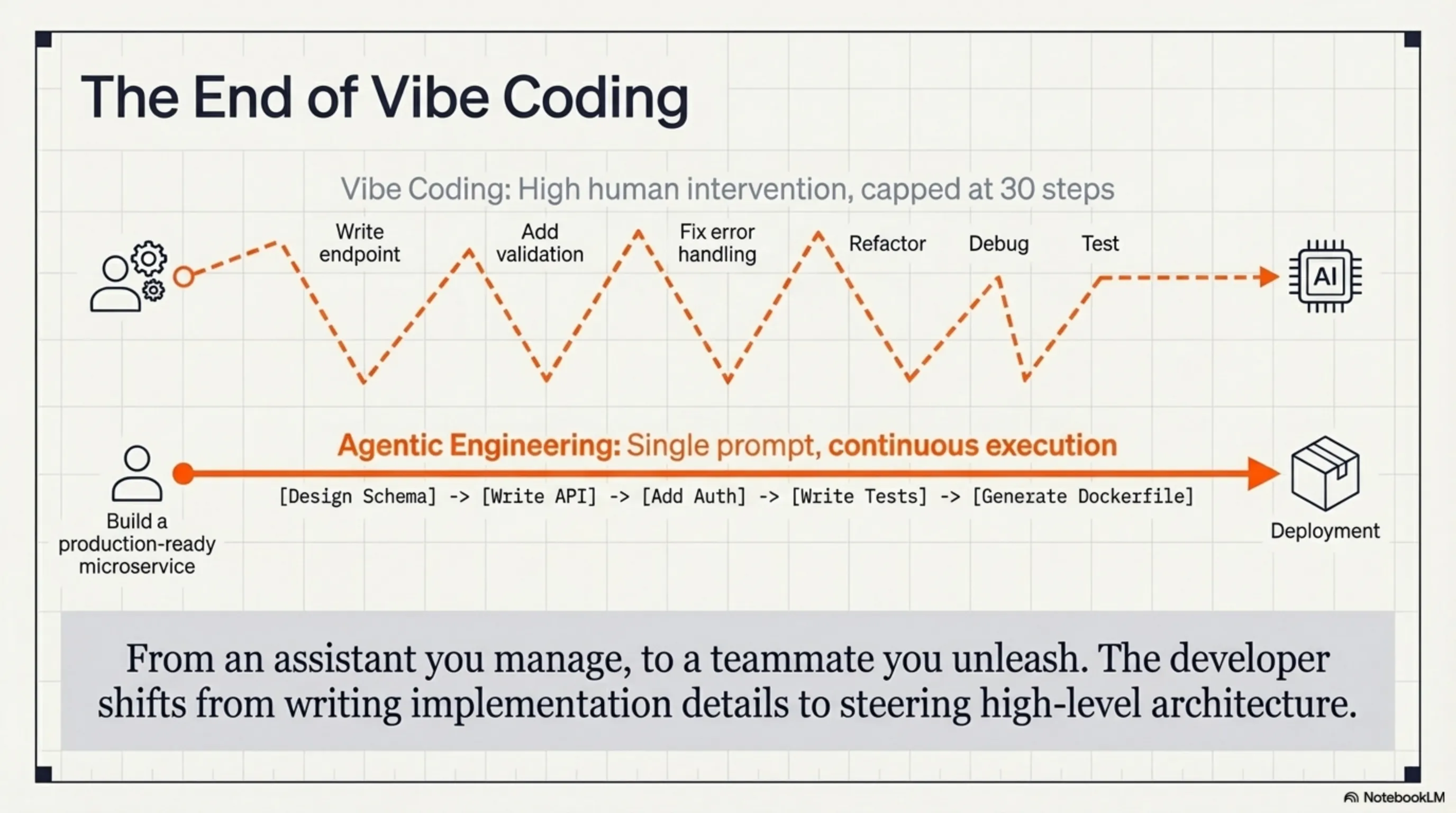
🎨 Agentic Engineering: The End of Vibe Coding Era
One of the most significant shifts GLM-5.1 is bringing is the transition from "vibe coding" to "agentic engineering." But what's the difference?
Vibe coding is what we've been doing until now: you write a prompt, the AI gives you a code snippet, you review it, notice something's missing, write another prompt, the AI responds again, and the cycle continues. It's like a conversation - useful, but slow and inefficient.
⚖️ Vibe Coding vs Agentic Engineering
❌ Vibe Coding (Old Way)
- Requires constant human intervention
- Limited to 20-30 steps
- Loses context easily
- Slow and inefficient
- Suitable for small tasks only
✅ Agentic Engineering (New Way)
- Works independently for 8 hours
- Capable of 1700+ steps
- Maintains full context
- Fast and efficient
- Suitable for complete projects

Agentic engineering means you define a high-level goal, and the AI - like a real engineer - decides what steps to take, which tools to use, and how to solve problems. This isn't an assistant anymore - this is a teammate.
Real-world example: Imagine you want to build a microservice for image processing. With vibe coding, you'd need to:
- Say "create an API endpoint for image upload"
- Check the code, notice it lacks validation
- Say "add validation"
- Notice it lacks error handling
- Say "add error handling"
- And so on...
With agentic engineering and GLM-5.1, you simply say: "Build a production-ready microservice for image processing with these requirements..." and the model knows it needs to add validation, error handling, logging, testing, documentation, and even Docker configuration.
💡 Why This Matters
The shift from vibe coding to agentic engineering isn't just a technical change - it's a cultural transformation. It means developers can focus on architecture, design, and high-level decisions, while delegating implementation details to AI. It means one developer can do the work of five. It means startups can build big products with small teams.
📊 Benchmarks: Real-World Performance That Matters
Talk is cheap, but numbers don't lie. Let's see how GLM-5.1 performs in real-world benchmarks:
🏆 GLM-5.1 Benchmark Results
| Benchmark | GLM-5.1 | GPT-4.5 | Claude Opus 4 | Description |
|---|---|---|---|---|
| AIME 2024 | 95.3% | 92.1% | 91.8% | Olympic-level math problems |
| SWE-Bench Pro | 58.4% | 51.2% | 49.7% | Real GitHub issues |
| Terminal-Bench 2.0 | 87.6% | 79.3% | 81.5% | Command line operations |
| Autonomous Steps | 1,700 | ~150 | ~200 | Independent action steps |
Let's break down these numbers:
🎯 AIME 2024: 95.3%
AIME (American Invitational Mathematics Examination) is one of the world's toughest math competitions - Olympic level. GLM-5.1's 95.3% accuracy beats GPT-4.5 (92.1%) and Claude Opus 4 (91.8%). This demonstrates the model's capability for complex, multi-step reasoning.
💻 SWE-Bench Pro: 58.4%
SWE-Bench Pro is a real-world benchmark using actual GitHub issues. The model must understand the entire codebase, find the bug, and provide a complete fix. 58.4% means GLM-5.1 can solve more than half of real-world bugs autonomously - that's incredible!
⚡ Terminal-Bench 2.0: 87.6%
This benchmark measures command line proficiency - from file operations to git commands, from package management to system administration. 87.6% means GLM-5.1 can work like a real DevOps engineer.
📜 MIT License: Why Open Source Matters
One of Z.ai's biggest decisions was releasing GLM-5.1 under the MIT License. But why is this so important?
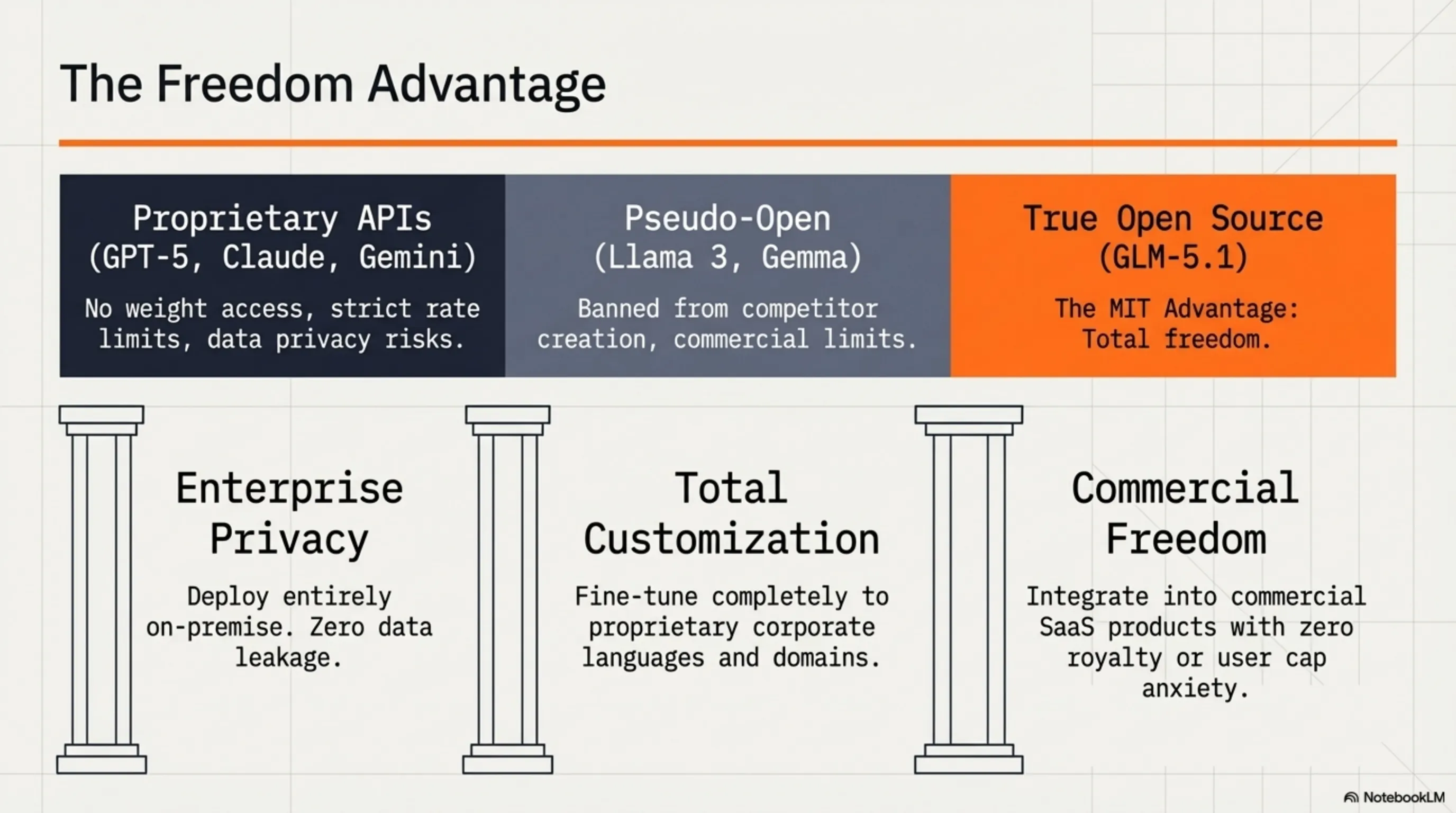
MIT License is one of the most permissive open-source licenses. This means:
- ✅ You can download and use the model - free
- ✅ You can modify the model - however you want
- ✅ You can use it in commercial products - no restrictions
- ✅ You can fine-tune it - for your specific use case
- ✅ You can redistribute it - even modified versions
Compare this with more restrictive licenses like:
- Llama 3 License: Restrictions for large companies (700M+ users)
- Gemma License: Prohibited from building competing models
- GPT-4 API: API-only access, no weights
- GLM-5.1 MIT: No restrictions - completely free!
Who benefits from this?
🏢 For Companies:
Deploy GLM-5.1 on your own infrastructure without worrying about API costs or rate limits. Fine-tune the model for your domain. Use it in commercial products without paying royalties.
👨💻 For Developers:
Download the model, experiment with it, learn how it works, and even improve it. Use it in personal or side projects without cost concerns.
🎓 For Researchers:
Study the model, run new benchmarks, and publish results. This transparency is crucial for advancing AI science.
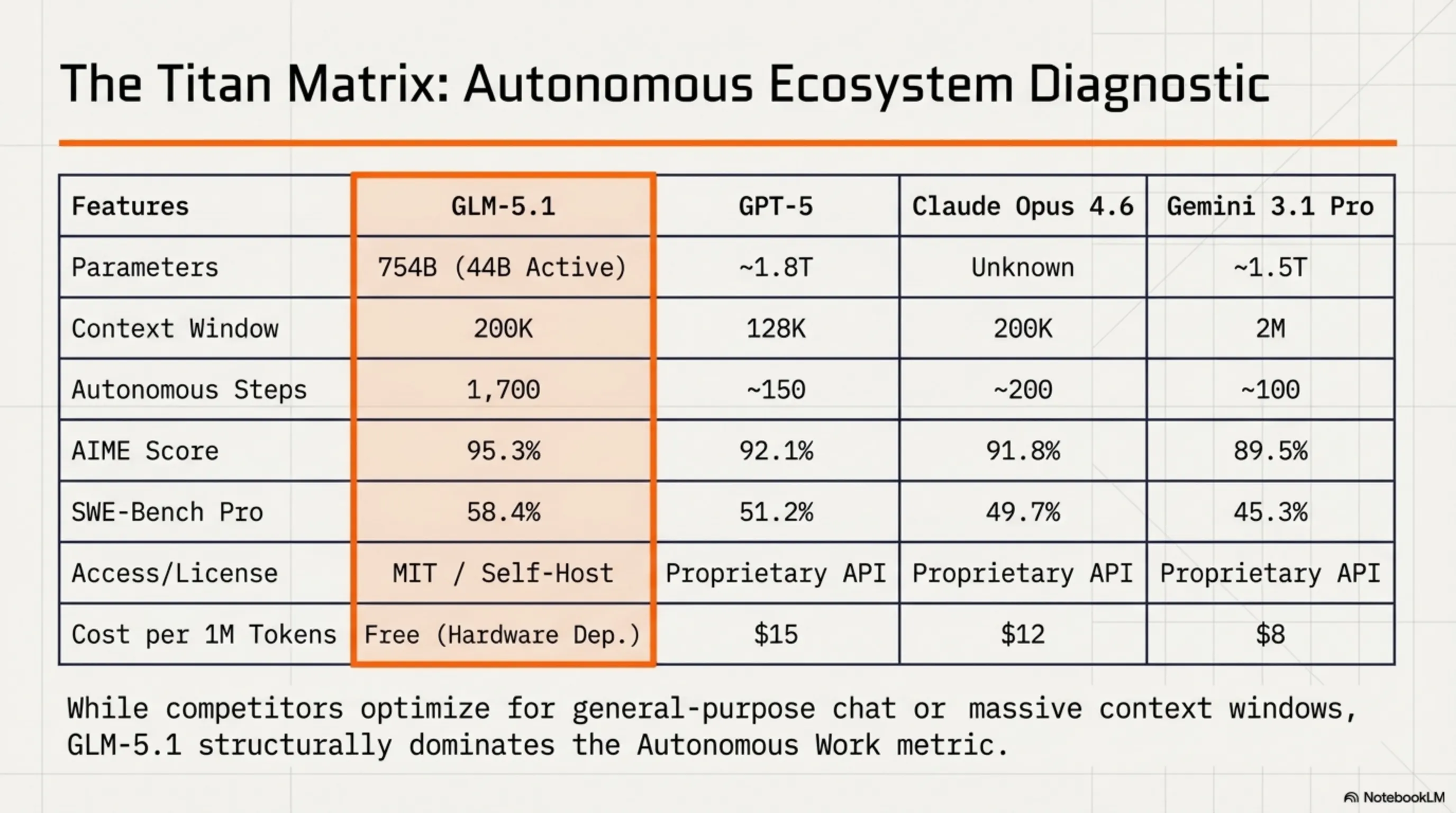
⚔️ Competitor Comparison: GLM-5.1 vs AI Giants
Now let's compare GLM-5.1 with its main competitors: GPT-5 from OpenAI, Claude Opus 4.6 from Anthropic, and Gemini 3.1 Pro from Google.
🔍 Comprehensive AI Model Comparison
| Feature | GLM-5.1 | GPT-5 | Claude Opus 4.6 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Parameters | 754B (44B active) | ~1.8T (unknown active) | Unknown | ~1.5T |
| Context Window | 200K | 128K | 200K | 2M |
| Autonomous Steps | 1,700 | ~150 | ~200 | ~100 |
| AIME Score | 95.3% | 92.1% | 91.8% | 89.5% |
| SWE-Bench Pro | 58.4% | 51.2% | 49.7% | 45.3% |
| License | MIT (Open) | Proprietary | Proprietary | Proprietary |
| Access | Download + API | API Only | API Only | API Only |
| Cost (approx.) | Free (self-host) | $15/1M tokens | $12/1M tokens | $8/1M tokens |
Let's examine the strengths and weaknesses of each:
✅ GLM-5.1: Best for Autonomous Work
Strengths: Highest autonomous steps (1700), best performance on AIME and SWE-Bench, MIT license, free for self-hosting
Weaknesses: Requires powerful hardware for self-hosting, smaller context window than Gemini
🔵 GPT-5: Best for General Purpose
Strengths: Excellent performance across all domains, strong ecosystem, easy integration
Weaknesses: Expensive, proprietary, limited autonomous steps, API-only
🟠 Claude Opus 4.6: Best for Safety
Strengths: Best safety features, large context window, good reasoning performance
Weaknesses: Expensive, proprietary, limited autonomous steps, API-only
🔴 Gemini 3.1 Pro: Best for Long Context
Strengths: Largest context window (2M), Google services integration, reasonable pricing
Weaknesses: Weaker coding performance, very limited autonomous steps, proprietary
🏆 Comparison Verdict
If you need an AI agent for long, complex projects, GLM-5.1 is the best choice - especially if you want to self-host or reduce costs. If you need a general-purpose model with a strong ecosystem, GPT-5 is still king. If safety and large context matter, Claude and Gemini are solid options. But for autonomous coding? GLM-5.1 is unmatched.
🛠️ Practical Applications: From Coding to DevOps
So GLM-5.1 is powerful - but how can you use it in the real world? Let's explore some practical use cases:
💻 1. Full-Stack Development
Imagine you want to build a complete web application - React frontend, Node.js backend, PostgreSQL database, and JWT authentication. With GLM-5.1:
- Morning: "Build an e-commerce platform with these features..."
- Noon: Model has built frontend, written API endpoints, designed database schema
- Afternoon: Added authentication, written tests, completed documentation
- Evening: Prepared Docker Compose file for deployment
Time Saved: From 2 weeks to 1 day - 93% faster!
🔧 2. DevOps Automation
You have complex infrastructure that needs automation. GLM-5.1 can:
- Build CI/CD pipelines (GitHub Actions, GitLab CI, Jenkins)
- Write Infrastructure as Code (Terraform, CloudFormation)
- Set up monitoring and alerting (Prometheus, Grafana)
- Create backup and disaster recovery scripts
Benefit: One DevOps engineer can do the work of five
🔄 3. Code Refactoring
You have a legacy codebase that needs refactoring - 50,000 lines of code, no tests, lots of technical debt. GLM-5.1:
- Analyzes entire codebase and identifies code smells
- Creates comprehensive refactoring plan
- Refactors step by step - without breaking functionality
- Writes tests to ensure everything works
Result: From 3 months to 1 week - 92% faster!
🐛 4. Bug Fixing
A production bug has been found that causes crashes - but only under specific conditions. GLM-5.1:
- Analyzes logs and finds root cause
- Traces entire call stack
- Proposes a fix and tests it
- Writes regression tests to prevent recurrence
Speed: From 4 hours debugging to 30 minutes - 87% faster!
📚 5. Documentation Generation
You have a large API without documentation - 200 endpoints, no comments, no explanations. GLM-5.1:
- Analyzes entire API and understands what each endpoint does
- Creates complete OpenAPI/Swagger spec
- Writes README and getting started guide
- Creates code examples for each endpoint
Quality: Documentation better than most human developers!
💡 Calculate Your ROI
Assume a senior developer costs $100/hour. If GLM-5.1 can handle 50% of routine work, you save about $8,000 per month - while self-hosting GLM-5.1 costs around $500-1000/month (depending on hardware). That's an ROI of about 800%!
⚠️ Limitations & Challenges: What You Need to Know
GLM-5.1 is impressive, but like any technology, it has limitations and challenges. Let's talk about them honestly:
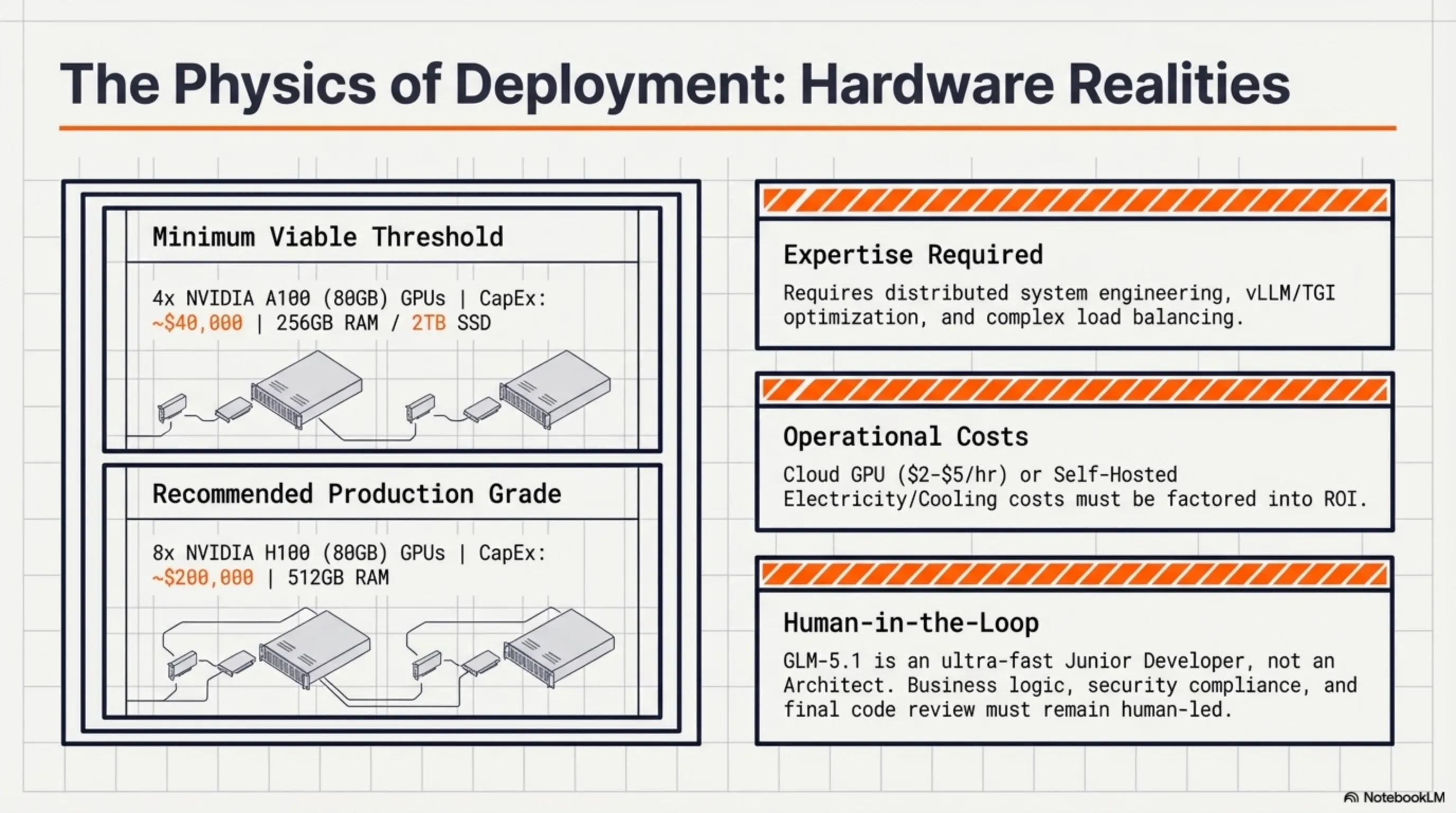
🖥️ 1. Requires Powerful Hardware
With 754B total parameters and 44B active parameters, GLM-5.1 needs serious hardware:
- Minimum: 4x A100 80GB GPUs (~$40,000)
- Recommended: 8x H100 80GB GPUs (~$200,000)
- RAM: Minimum 256GB, recommended 512GB
- Storage: Minimum 2TB SSD for model weights
Solution: Use cloud providers like AWS, GCP, or Azure with GPU instances. Or use quantized versions (4-bit, 8-bit) that require less hardware.
💰 2. Inference Costs
While the model is free, running it isn't:
- Cloud GPU: $2-5 per hour (depending on provider)
- Electricity: ~$0.50-1 per hour for self-hosting
- Cooling: Additional costs for cooling systems
Solution: Use batch processing, caching, and optimization techniques to reduce costs. For small use cases, proprietary APIs might be more cost-effective.
🌍 3. Language Limitations
GLM-5.1 is primarily trained on Chinese and English. For other languages:
- English: Excellent performance ✅
- Chinese: Excellent performance ✅
- European languages: Good performance ⚠️
- Persian, Arabic, etc.: Average performance ⚠️
Solution: Fine-tune on your target language, or use a translation layer.
🚀 4. Deployment Challenges
Deploying a 754B parameter model isn't simple:
- Requires expertise in distributed systems
- Complex load balancing and scaling
- Monitoring and debugging challenges
- Needs robust infrastructure
Solution: Use frameworks like vLLM, TGI (Text Generation Inference), or Ray Serve that simplify deployment.
⚠️ Important Warning
GLM-5.1 is a powerful tool, but it's not a complete replacement for human developers. You still need to:
• Define overall architecture and design
• Review code quality
• Make business logic decisions
• Verify security and compliance
Think of GLM-5.1 as a very fast, smart junior developer - not an architect or tech lead.
🔮 The Future: What's Coming Next?
GLM-5.1 is just the beginning. Z.ai and the open-source community are working on exciting things:
🗺️ Future Roadmap
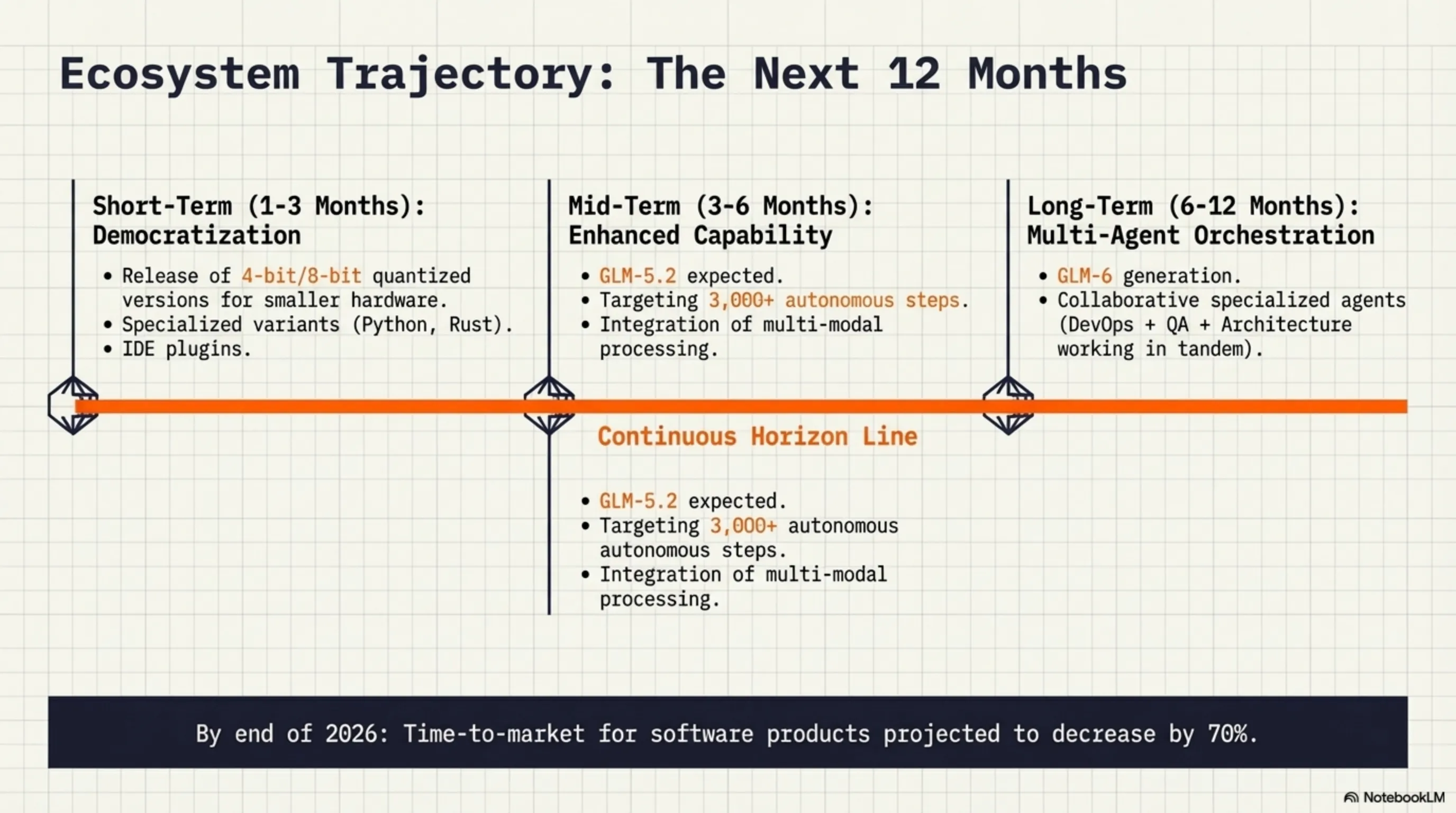
📅 Short-term (1-3 months)
- Quantized versions: 4-bit and 8-bit versions for less hardware
- Fine-tuned variants: Specialized versions for Python, JavaScript, Rust, etc.
- Better tooling: Improved tools for deployment and monitoring
- Community plugins: Integration with IDEs and development tools
📅 Mid-term (3-6 months)
- GLM-5.2: Improved version with more autonomous steps (target: 3000+)
- Multi-modal support: Ability to work with images, video, and audio
- Better reasoning: Improvements in mathematical and logical reasoning
- Faster inference: New optimizations for higher speed
📅 Long-term (6-12 months)
- GLM-6: Next generation with more capabilities
- Specialized agents: Dedicated agents for DevOps, Security, Testing, etc.
- Collaborative agents: Multiple agents working together
- Self-improving agents: Agents that learn from experience and get better
But beyond Z.ai's roadmap, what's truly exciting is that GLM-5.1 is released under MIT license. This means thousands of developers and researchers can work on it, improve it, and build new versions. This means we're witnessing the birth of an ecosystem - not just a model.
🔮 Our Prediction
By the end of 2026, we predict:
- 50% of tech startups will use AI agents like GLM-5.1
- Average development team size will shrink from 10 to 3-4 people
- Time-to-market for new products will decrease by 70%
- Developer role will shift from "coding" to "architecture and design"
This is a paradigm shift - like the transition from assembly to high-level languages, or from waterfall to agile. Those who adapt early will win.
🎯 Conclusion: Is GLM-5.1 Worth It?
After thoroughly examining GLM-5.1 - from technical architecture to practical applications, from benchmarks to limitations - it's time to answer the main question: Is GLM-5.1 worth it?
Short answer: Yes, absolutely!
Long answer: It depends on your use case. Let's see who GLM-5.1 is right for:
✅ Perfect for:
- Startups with small teams wanting to scale quickly
- Companies looking to reduce development costs
- Open-source projects needing more contributors
- Developers wanting to 10x their productivity
- Companies wanting to self-host (for privacy/security)
❌ Might not be suitable for:
- Very small projects where proprietary APIs are more cost-effective
- Teams lacking expertise in deploying large models
- Use cases requiring languages other than English/Chinese
- Companies unable to invest in hardware
🏆 Final Verdict
GLM-5.1 is a real game changer. With the ability to work independently for 8 hours, superior benchmark performance, and completely free MIT license, this model is rewriting the definition of "AI agent." If you're a developer, CTO, or founder who wants to stay ahead of competitors, now is the time to try GLM-5.1.
🚀 Ready to Get Started?
Download GLM-5.1 from Hugging Face and experience the revolution:
https://huggingface.co/zai-org/GLM-5
This article was written on April 9, 2026. For the latest information, be sure to check Z.ai's official website.
🌐 Stay Connected With Us 🎮✨
For the latest tech, gaming, and gadget news, follow us on our official social media channels:
Additional Gallery: GLM-5.1: The First AI That Codes for 8 Hours Straight 🤖