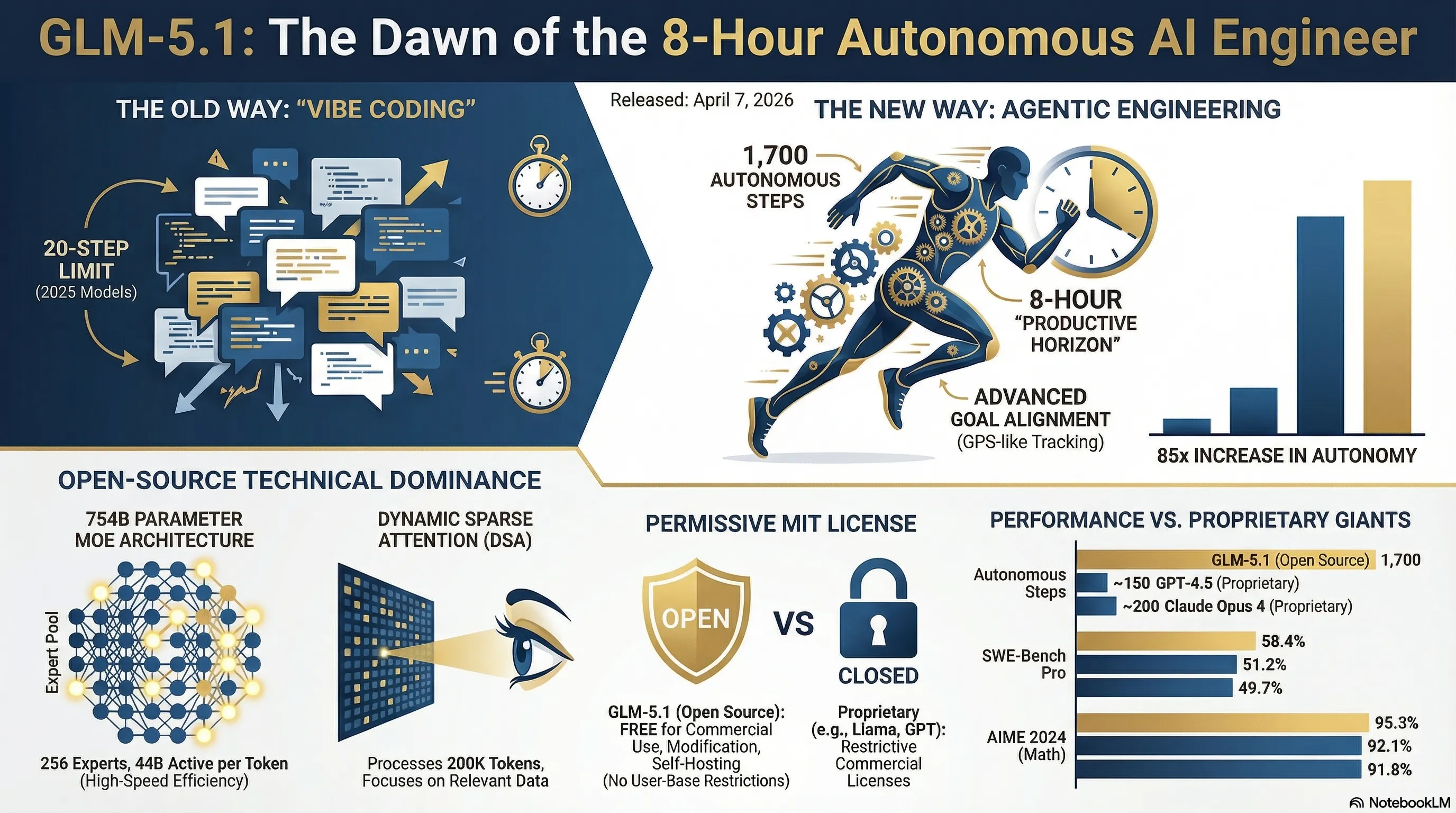
GLM-5.1 هو نموذج ذكاء اصطناعي ثوري بـ 754 مليار معامل يمكنه البرمجة بشكل مستقل تماماً لمدة تصل إلى 8 ساعات. مع معمارية MoE وDynamic Sparse Attention، يمكنه تنفيذ 1700 خطوة مستقلة - أفضل بـ 85 مرة من النماذج السابقة. رخصة MIT مجانية تماماً وأداء متفوق في معايير AIME (95.3%)، وSWE-Bench Pro (58.4%)، وTerminal-Bench (87.6%) يعيد تعريف ما يمكن لوكيل الذكاء الاصطناعي القيام به.
🤖 GLM-5.1: أول ذكاء اصطناعي يبرمج لمدة 8 ساعات متواصلة
البرمجة المستقلة الثورية - من 20 خطوة إلى 1700 خطوة
🚀 ثورة الـ 8 ساعات: لماذا GLM-5.1 يغير قواعد اللعبة حقاً
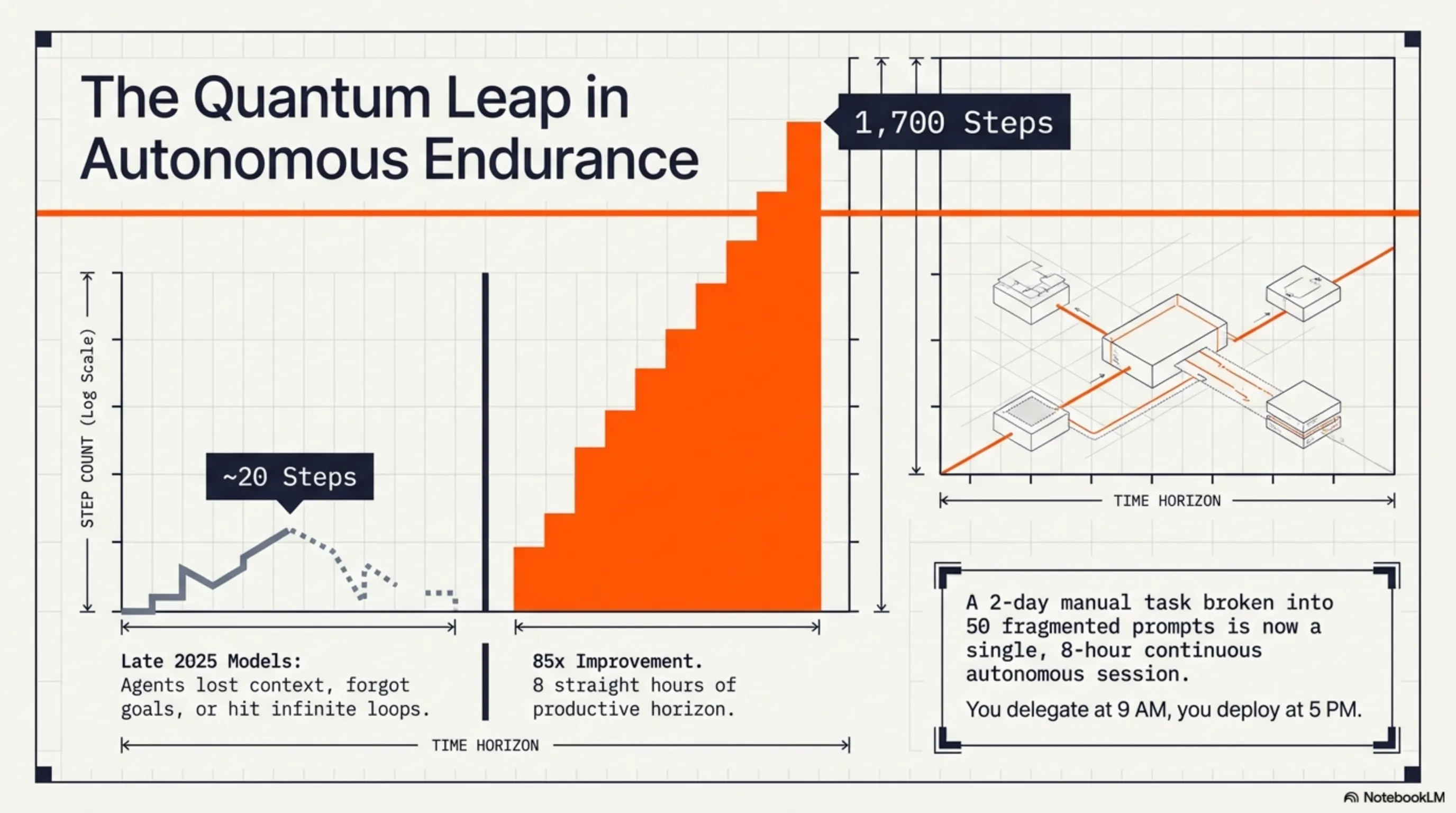
عندما أطلقت Z.ai من الصين (Zhipu AI) نموذج GLM-5.1 في 7 أبريل 2026، ظن الكثيرون أنه مجرد تحديث روتيني آخر. لكن عندما غرد لو، قائد الفريق، قائلاً "كانت الوكلاء قادرة على حوالي 20 خطوة بنهاية العام الماضي. glm-5.1 يمكنه 1700 الآن"، أدرك الجميع أن شيئاً كبيراً يحدث. لم يكن هذا مجرد تحسين تدريجي - كان قفزة كمومية.
لنبدأ بمثال بسيط. تخيل أنك تريد بناء RESTful API كامل - مع المصادقة، تكامل قاعدة البيانات، معالجة الأخطاء، التسجيل، الاختبارات، والتوثيق. مع نماذج 2025، كان عليك تقسيم هذا العمل إلى 50-60 مهمة صغيرة، إعطاء كل واحدة للذكاء الاصطناعي بشكل منفصل، فحص المخرجات، إصلاح المشاكل إذا لزم الأمر، وتكرار الدورة. مشروع يومين يمكن أن يمتد بسهولة إلى أسبوعين.
الآن مع GLM-5.1، تقول في الساعة 9 صباحاً: "ابنِ RESTful API لمتجر إلكتروني بهذه الميزات..." وتذهب لأعمالك الأخرى. في الساعة 5 مساءً تعود لتجد المشروع بأكمله جاهزاً - مع جميع الاختبارات، التوثيق، وحتى إعدادات Docker للنشر. هذا لم يعد خيالاً، هذا واقع.
🔍 غوص عميق: لماذا 8 ساعات؟
رقم الـ 8 ساعات ليس عشوائياً. أجرت Z.ai أبحاثاً مكثفة حول "آفاق الإنتاجية" - المدة التي يمكن لوكيل الذكاء الاصطناعي أن يبقى مركزاً على هدف دون أن يضيع أو يتشتت. معظم مشاريع هندسة البرمجيات في العالم الواقعي تستغرق بين 4 إلى 8 ساعات - ميزة جديدة، إصلاح خطأ معقد، إعادة هيكلة كبيرة. GLM-5.1 محسّن بدقة لهذه النافذة الزمنية.
لكن كيف يحقق ذلك؟ المفتاح يكمن في معمارية Dynamic Sparse Attention ونظام محاذاة الأهداف المتقدم. يمكن للنموذج إدارة آلاف استدعاءات الأدوات، الحفاظ على السياق، والتعلم من الأخطاء السابقة - كل ذلك أثناء التشغيل، دون الحاجة إلى ضبط دقيق أو تدخل بشري.
⚙️ المعمارية التقنية: 754 مليار معامل مع ذكاء MoE
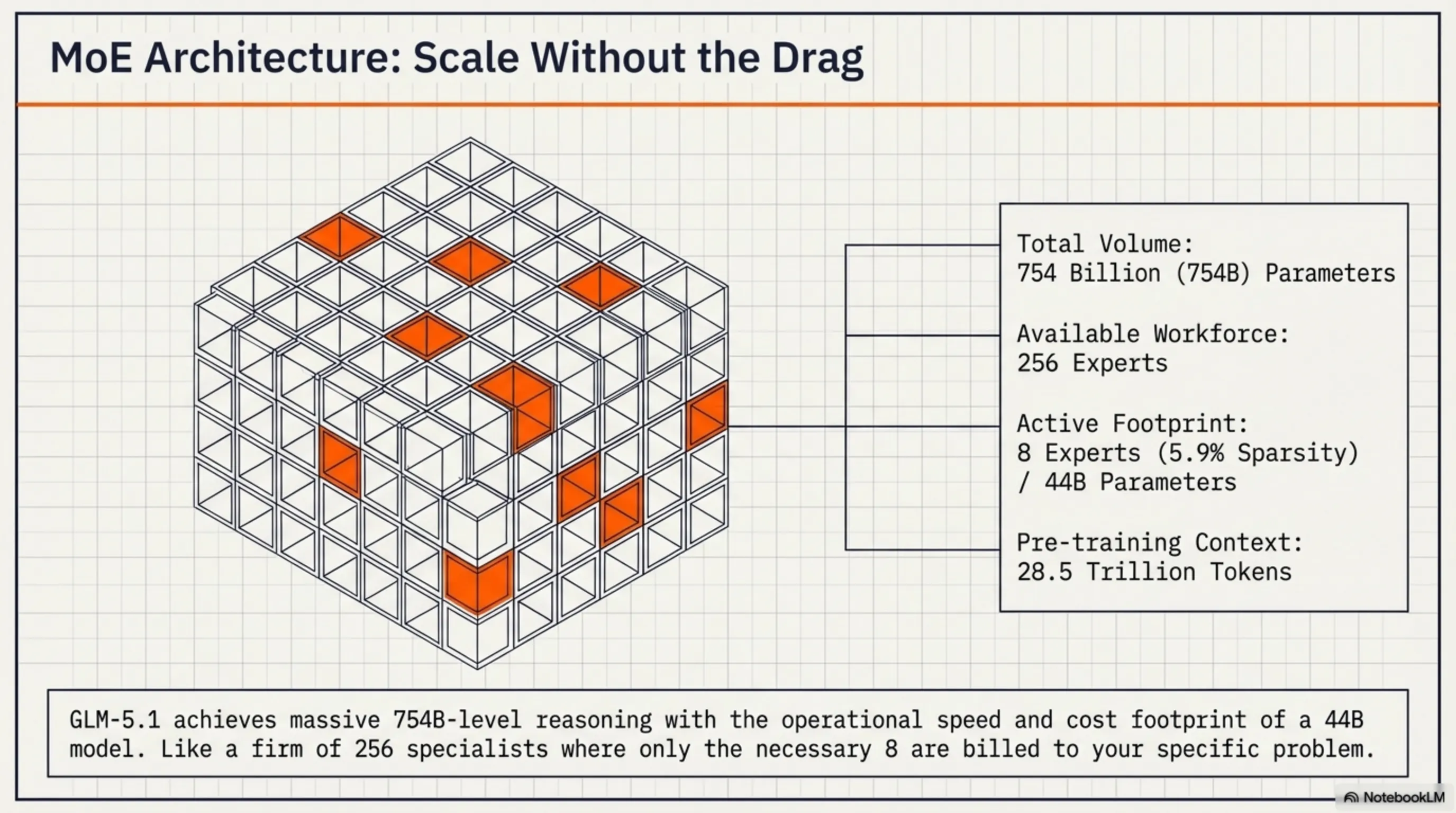
الآن لنغوص أعمق في الآلة. GLM-5.1 هو نموذج Mixture-of-Experts (MoE) بإجمالي 754 مليار معامل. لكن قبل أن تقول "واو، هذا يجب أن يكون بطيئاً جداً!"، دعني أشرح لماذا ليس كذلك.
في معمارية MoE، لديك مجموعة كبيرة من "الخبراء" - GLM-5.1 لديه حوالي 256 خبيراً. لكن إليك الحيلة: لكل رمز، يتم تنشيط عدد صغير فقط من هؤلاء الخبراء - عادة 8 (أي فقط 5.9% من النموذج الكلي). هذا يعني عملياً، لكل استنتاج، حوالي 44 مليار معامل فقط نشطة.
فكر في الأمر كشركة كبيرة بها 256 متخصصاً مختلفاً - محامون، محاسبون، مبرمجون، مصممون، إلخ. عندما تنشأ مسألة قانونية، تستدعي المحامي فقط، وليس جميع الـ 256 شخصاً. هذا بالضبط ما يفعله GLM-5.1 - لكل مهمة، ينشط فقط الخبراء ذوي الصلة.
📊 المواصفات التقنية لـ GLM-5.1
- إجمالي المعاملات: 754 مليار (754B)
- المعاملات النشطة: 44 مليار (44B) لكل استنتاج
- عدد الخبراء: 256 خبيراً
- الخبراء النشطون: 8 خبراء لكل رمز (تفرق 5.9%)
- نافذة السياق: 200,000 رمز
- بيانات التدريب المسبق: 28.5 تريليون رمز
- معمارية الانتباه: Dynamic Sparse Attention (DSA)
- الرخصة: MIT (مجاني تماماً ومفتوح المصدر)
لكن القلب النابض لـ GLM-5.1 هو شيء آخر: Dynamic Sparse Attention (DSA). هذه التقنية، المستوحاة من DeepSeek، تسمح للنموذج بالانتباه بشكل انتقائي فقط للرموز ذات الصلة. تخيل قراءة كتاب من 1000 صفحة - لا تحتاج لمراجعة جميع الـ 1000 صفحة في كل مرة تقرأ جملة جديدة. تنظر فقط إلى الأجزاء ذات الصلة. هذا ما يفعله DSA.
النتيجة؟ يمكن لـ GLM-5.1 العمل مع نافذة سياق 200K رمز (حوالي 150,000 كلمة أو حوالي 300 صفحة من النص) دون التباطؤ أو أن يصبح باهظ التكلفة. هذا أمر حاسم للمشاريع الواقعية التي تحتاج للحفاظ على سياق كبير (مثل إعادة هيكلة قاعدة أكواد كبيرة).
📈 من 20 خطوة إلى 1700 خطوة: ثورة وقت العمل المستقل
الآن لنصل إلى جوهر الموضوع: كيف انتقل GLM-5.1 من 20 خطوة إلى 1700 خطوة؟ هذا ليس مجرد تحسين كمي - إنه تحول نموذجي.
أولاً، لنحدد ما تعنيه "خطوة". كل خطوة هي إجراء مستقل يقوم به الوكيل - مثل كتابة دالة، تشغيل اختبار، قراءة ملف، أو استدعاء API. كانت النماذج القديمة تبدأ في الضياع بعد 20-30 خطوة - تفقد السياق، تنسى الأهداف، أو تعلق في حلقات لا نهائية.

حل GLM-5.1 هذه المشكلة بثلاث ابتكارات رئيسية:
🎯 ثلاثة ابتكارات رئيسية
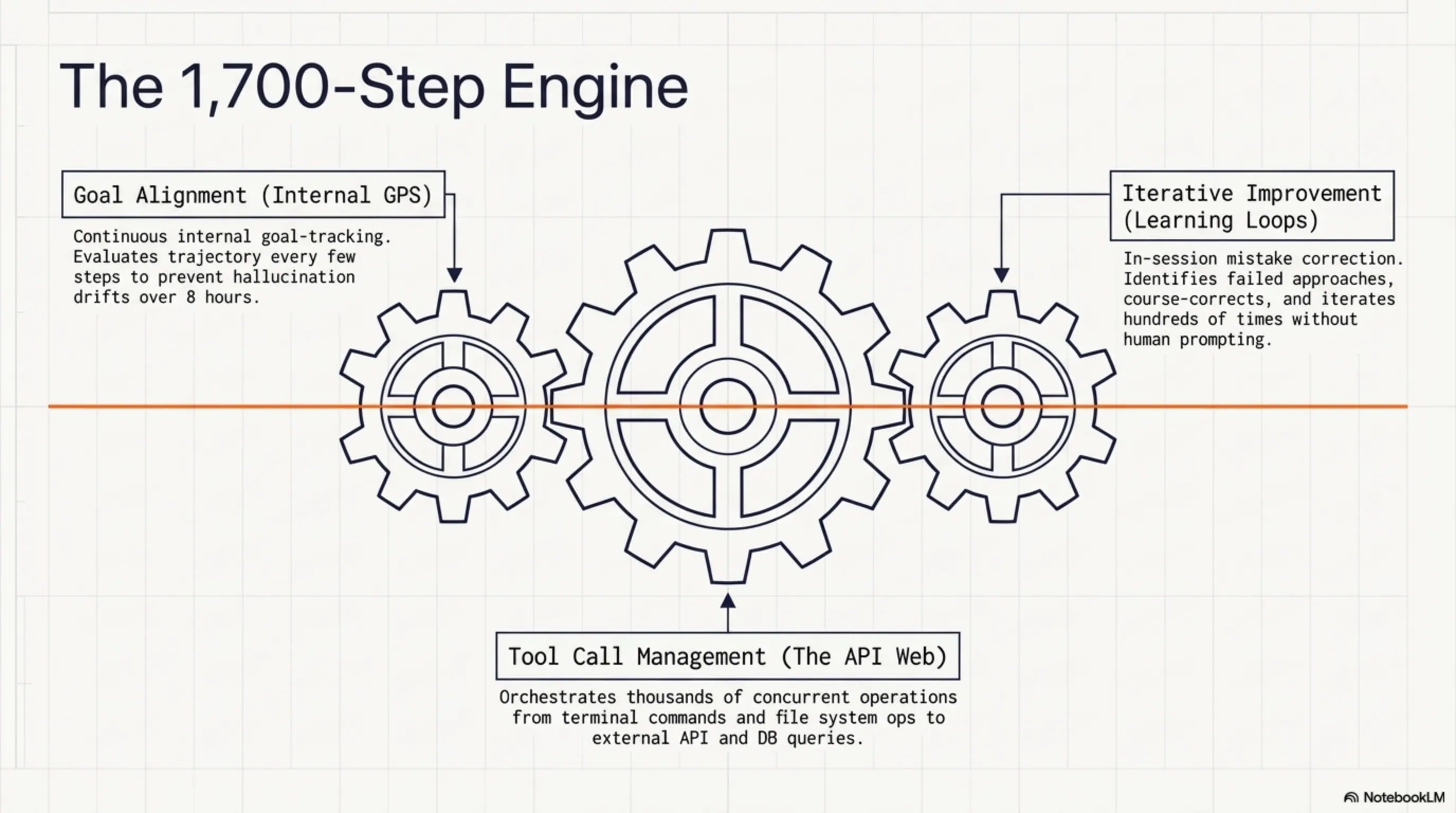
1. محاذاة الأهداف المتقدمة
لدى النموذج نظام تتبع أهداف داخلي يتحقق باستمرار مما إذا كان لا يزال على المسار الصحيح. مثل GPS يعيد حساب المسار كل بضع ثوانٍ، يراجع GLM-5.1 أهدافه كل بضع خطوات ويصحح المسار إذا لزم الأمر.
2. التحسين التكراري
يمكن لـ GLM-5.1 التعلم من أخطائه - داخل نفس الجلسة. إذا لم ينجح نهج ما، يدرك النموذج ذلك، يجرب نهجاً مختلفاً، ويستمر في هذه الدورة حتى الوصول إلى الإجابة الصحيحة. تقول Z.ai أن النموذج يمكنه التحسن من خلال مئات التكرارات.
3. إدارة استدعاءات الأدوات
كان أحد أكبر التحديات للوكلاء القدامى هو عدم قدرتهم على إدارة العديد من استدعاءات الأدوات. يمكن لـ GLM-5.1 التعامل مع آلاف استدعاءات الأدوات - من عمليات نظام الملفات إلى استدعاءات API، من استعلامات قاعدة البيانات إلى أوامر الطرفية. والأهم من ذلك، يمكنه دمج نتائج هذه الاستدعاءات واتخاذ قرارات ذكية.
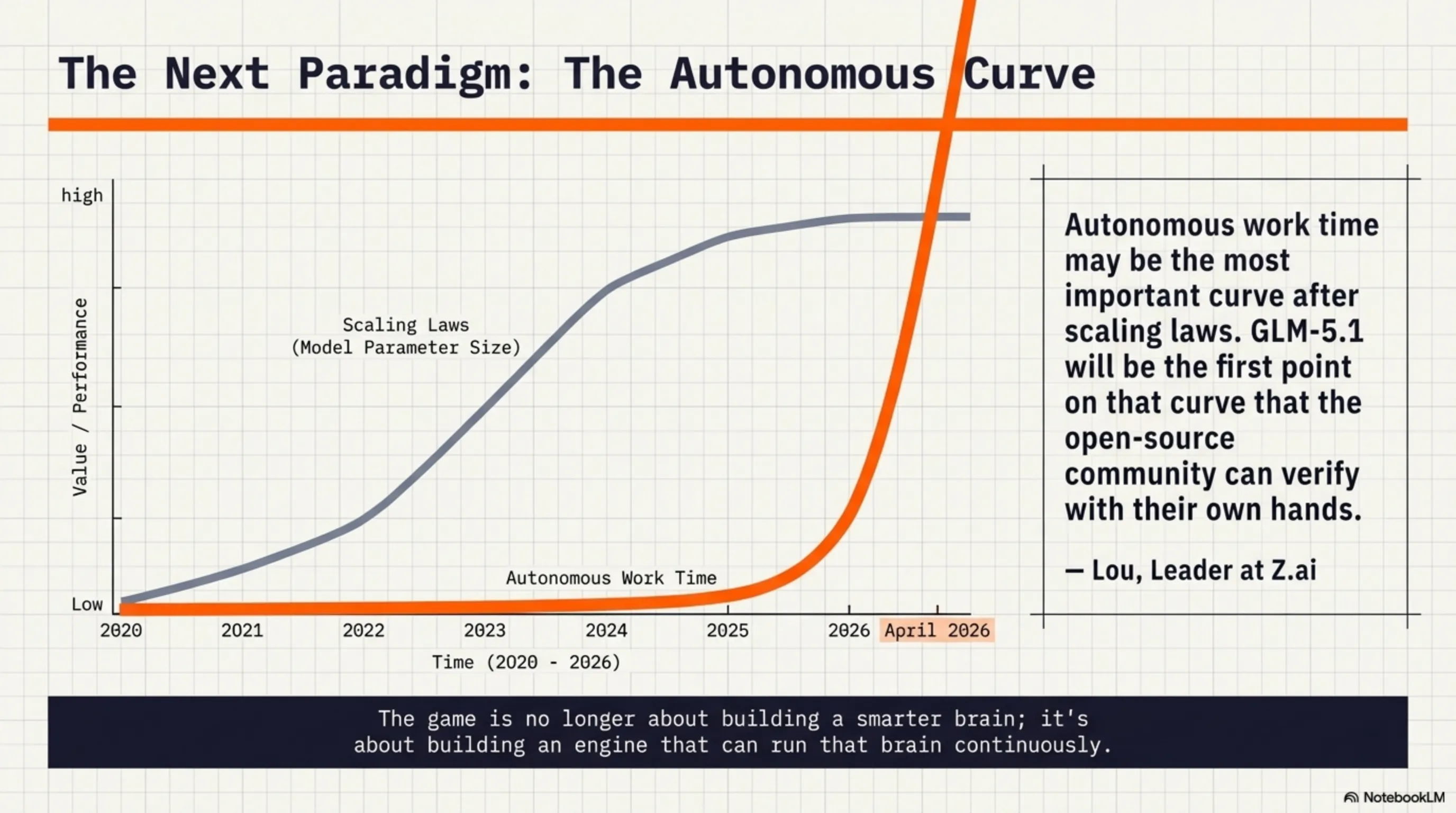
وصف لو، قائد Z.ai، هذا بأنه "المنحنى الأهم بعد قوانين التوسع". لماذا؟ لأنه حتى الآن، كان الجميع يعتقد أن طريق تقدم الذكاء الاصطناعي هو فقط جعل النماذج أكبر (قوانين التوسع). لكن GLM-5.1 أظهر أن "وقت العمل المستقل" - المدة التي يمكن للذكاء الاصطناعي العمل فيها بشكل مستقل - قد يكون أكثر أهمية من حجم النموذج.
"قد يكون وقت العمل المستقل هو المنحنى الأهم بعد قوانين التوسع. سيكون glm-5.1 النقطة الأولى على هذا المنحنى التي يمكن لمجتمع المصدر المفتوح التحقق منها بأيديهم"
— لو، قائد Z.ai
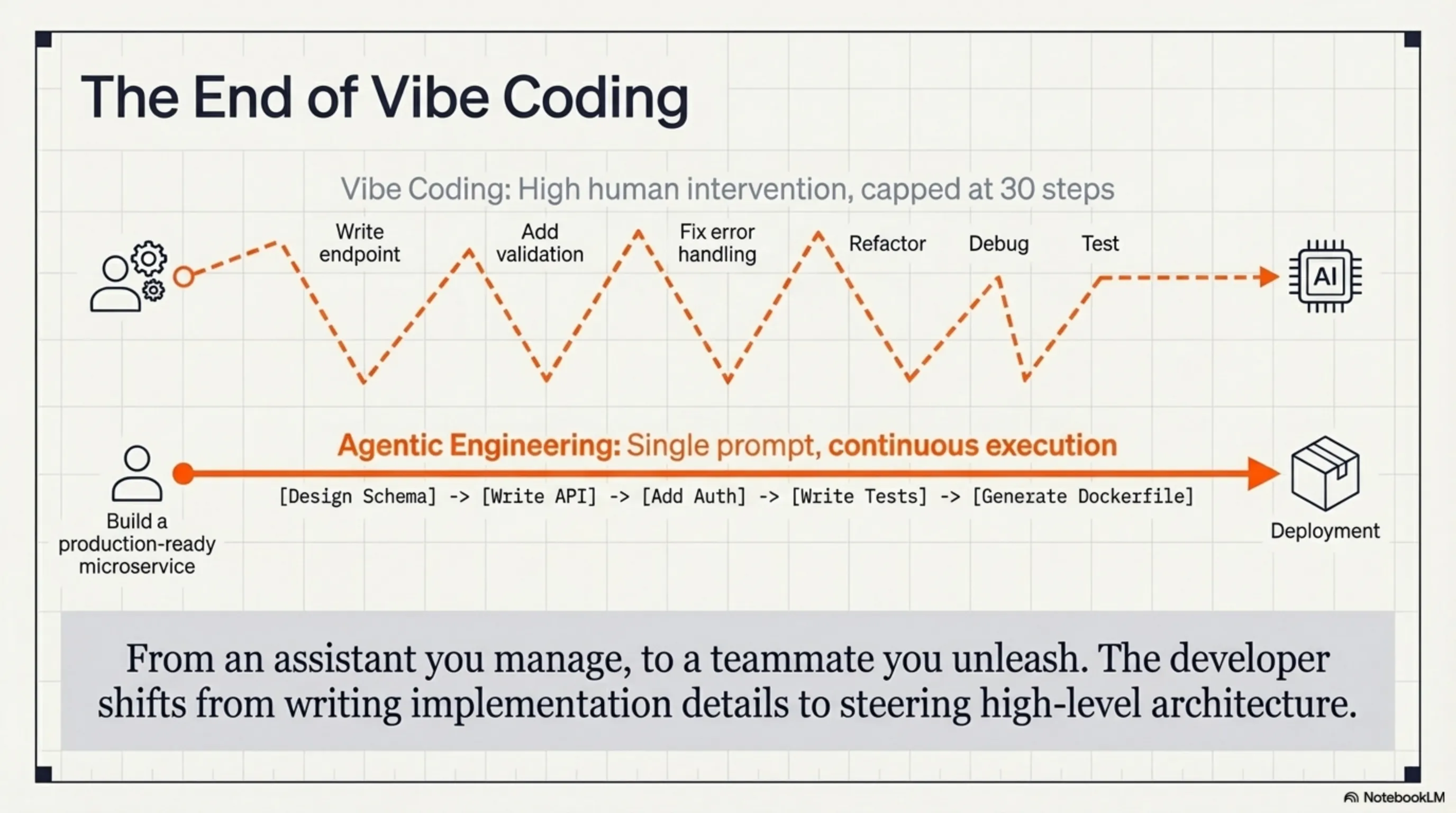
🎨 الهندسة بالوكلاء: نهاية عصر البرمجة العاطفية
أحد أهم التحولات التي يجلبها GLM-5.1 هو الانتقال من "البرمجة العاطفية" (vibe coding) إلى "الهندسة بالوكلاء" (agentic engineering). لكن ما الفرق؟
البرمجة العاطفية هي ما كنا نفعله حتى الآن: تكتب موجهاً، يعطيك الذكاء الاصطناعي مقتطف كود، تراجعه، تلاحظ شيئاً ناقصاً، تكتب موجهاً آخر، يستجيب الذكاء الاصطناعي مرة أخرى، وتستمر الدورة. إنها مثل محادثة - مفيدة، لكنها بطيئة وغير فعالة.
⚖️ البرمجة العاطفية مقابل الهندسة بالوكلاء
❌ البرمجة العاطفية (الطريقة القديمة)
- تتطلب تدخلاً بشرياً مستمراً
- محدودة بـ 20-30 خطوة
- تفقد السياق بسهولة
- بطيئة وغير فعالة
- مناسبة للمهام الصغيرة فقط
✅ الهندسة بالوكلاء (الطريقة الجديدة)
- تعمل بشكل مستقل لمدة 8 ساعات
- قادرة على 1700+ خطوة
- تحافظ على السياق الكامل
- سريعة وفعالة
- مناسبة للمشاريع الكاملة

الهندسة بالوكلاء تعني أنك تحدد هدفاً عالي المستوى، والذكاء الاصطناعي - مثل مهندس حقيقي - يقرر الخطوات التي يجب اتخاذها، الأدوات التي يجب استخدامها، وكيفية حل المشاكل. هذا لم يعد مساعداً - هذا زميل فريق.
مثال واقعي: تخيل أنك تريد بناء خدمة صغيرة لمعالجة الصور. مع البرمجة العاطفية، ستحتاج إلى:
- قل "أنشئ نقطة نهاية API لرفع الصور"
- تحقق من الكود، لاحظ أنه يفتقر للتحقق
- قل "أضف التحقق"
- لاحظ أنه يفتقر لمعالجة الأخطاء
- قل "أضف معالجة الأخطاء"
- وهكذا...
مع الهندسة بالوكلاء وGLM-5.1، تقول ببساطة: "ابنِ خدمة صغيرة جاهزة للإنتاج لمعالجة الصور بهذه المتطلبات..." ويعرف النموذج أنه يحتاج لإضافة التحقق، معالجة الأخطاء، التسجيل، الاختبارات، التوثيق، وحتى إعدادات Docker.
💡 لماذا هذا مهم
التحول من البرمجة العاطفية إلى الهندسة بالوكلاء ليس مجرد تغيير تقني - إنه تحول ثقافي. هذا يعني أن المطورين يمكنهم التركيز على المعمارية، التصميم، والقرارات عالية المستوى، بينما يفوضون تفاصيل التنفيذ للذكاء الاصطناعي. هذا يعني أن مطوراً واحداً يمكنه القيام بعمل خمسة. هذا يعني أن الشركات الناشئة يمكنها بناء منتجات كبيرة بفرق صغيرة.
📊 المعايير القياسية: الأداء الحقيقي في العالم الواقعي
الكلام رخيص، لكن الأرقام لا تكذب. لنرى كيف يؤدي GLM-5.1 في المعايير القياسية الواقعية:
🏆 نتائج معايير GLM-5.1
| المعيار | GLM-5.1 | GPT-4.5 | Claude Opus 4 | الوصف |
|---|---|---|---|---|
| AIME 2024 | 95.3% | 92.1% | 91.8% | مسائل رياضيات مستوى الأولمبياد |
| SWE-Bench Pro | 58.4% | 51.2% | 49.7% | مشاكل GitHub الحقيقية |
| Terminal-Bench 2.0 | 87.6% | 79.3% | 81.5% | عمليات سطر الأوامر |
| الخطوات المستقلة | 1,700 | ~150 | ~200 | خطوات الإجراء المستقلة |
لنحلل هذه الأرقام:
🎯 AIME 2024: 95.3%
AIME (American Invitational Mathematics Examination) هو أحد أصعب مسابقات الرياضيات في العالم - مستوى الأولمبياد. دقة GLM-5.1 البالغة 95.3% تتفوق على GPT-4.5 (92.1%) وClaude Opus 4 (91.8%). هذا يوضح قدرة النموذج على التفكير المعقد متعدد الخطوات.
💻 SWE-Bench Pro: 58.4%
SWE-Bench Pro هو معيار واقعي يستخدم مشاكل GitHub الفعلية. يجب على النموذج فهم قاعدة الأكواد بأكملها، إيجاد الخطأ، وتقديم إصلاح كامل. 58.4% يعني أن GLM-5.1 يمكنه حل أكثر من نصف الأخطاء الواقعية بشكل مستقل - هذا مذهل!
⚡ Terminal-Bench 2.0: 87.6%
يقيس هذا المعيار الكفاءة في سطر الأوامر - من عمليات الملفات إلى أوامر git، من إدارة الحزم إلى إدارة النظام. 87.6% يعني أن GLM-5.1 يمكنه العمل مثل مهندس DevOps حقيقي.
📜 رخصة MIT: لماذا المصدر المفتوح مهم
كان أحد أكبر قرارات Z.ai هو إصدار GLM-5.1 تحت رخصة MIT. لكن لماذا هذا مهم جداً؟
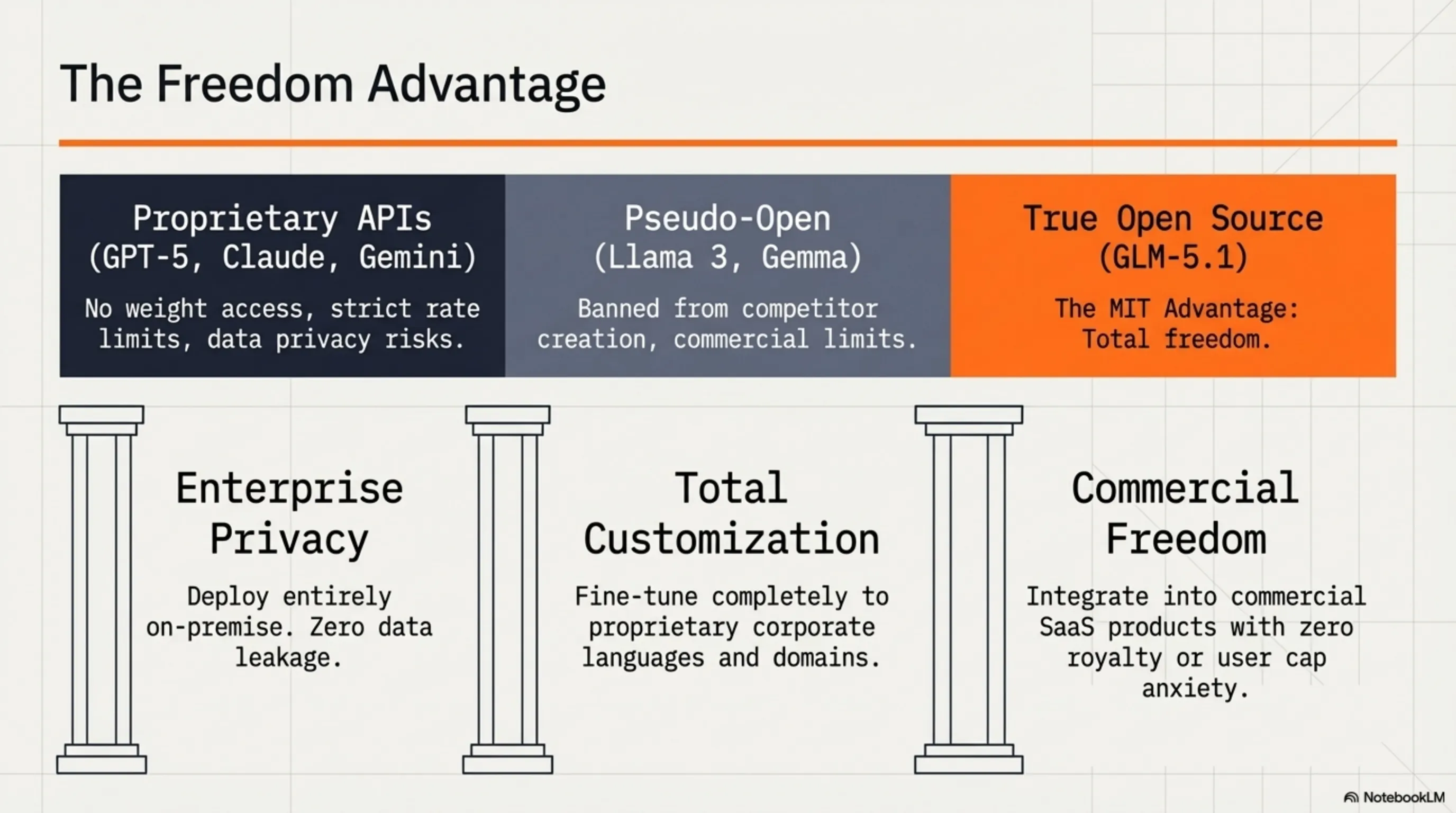
رخصة MIT هي واحدة من أكثر رخص المصدر المفتوح تساهلاً. هذا يعني:
- ✅ يمكنك تنزيل واستخدام النموذج - مجاناً
- ✅ يمكنك تعديل النموذج - كيفما تشاء
- ✅ يمكنك استخدامه في المنتجات التجارية - بدون قيود
- ✅ يمكنك ضبطه بدقة - لحالة استخدامك المحددة
- ✅ يمكنك إعادة توزيعه - حتى النسخ المعدلة
قارن هذا مع الرخص الأكثر تقييداً مثل:
- رخصة Llama 3: قيود للشركات الكبيرة (700M+ مستخدم)
- رخصة Gemma: ممنوع من بناء نماذج منافسة
- GPT-4 API: وصول عبر API فقط، بدون أوزان
- GLM-5.1 MIT: بدون قيود - مجاني تماماً!
من يستفيد من هذا؟
🏢 للشركات:
نشر GLM-5.1 على بنيتك التحتية الخاصة دون القلق بشأن تكاليف API أو حدود المعدل. ضبط النموذج بدقة لمجالك. استخدامه في المنتجات التجارية دون دفع إتاوات.
👨💻 للمطورين:
تنزيل النموذج، التجربة معه، تعلم كيف يعمل، وحتى تحسينه. استخدامه في المشاريع الشخصية أو الجانبية دون مخاوف التكلفة.
🎓 للباحثين:
دراسة النموذج، تشغيل معايير جديدة، ونشر النتائج. هذه الشفافية حاسمة لتقدم علم الذكاء الاصطناعي.
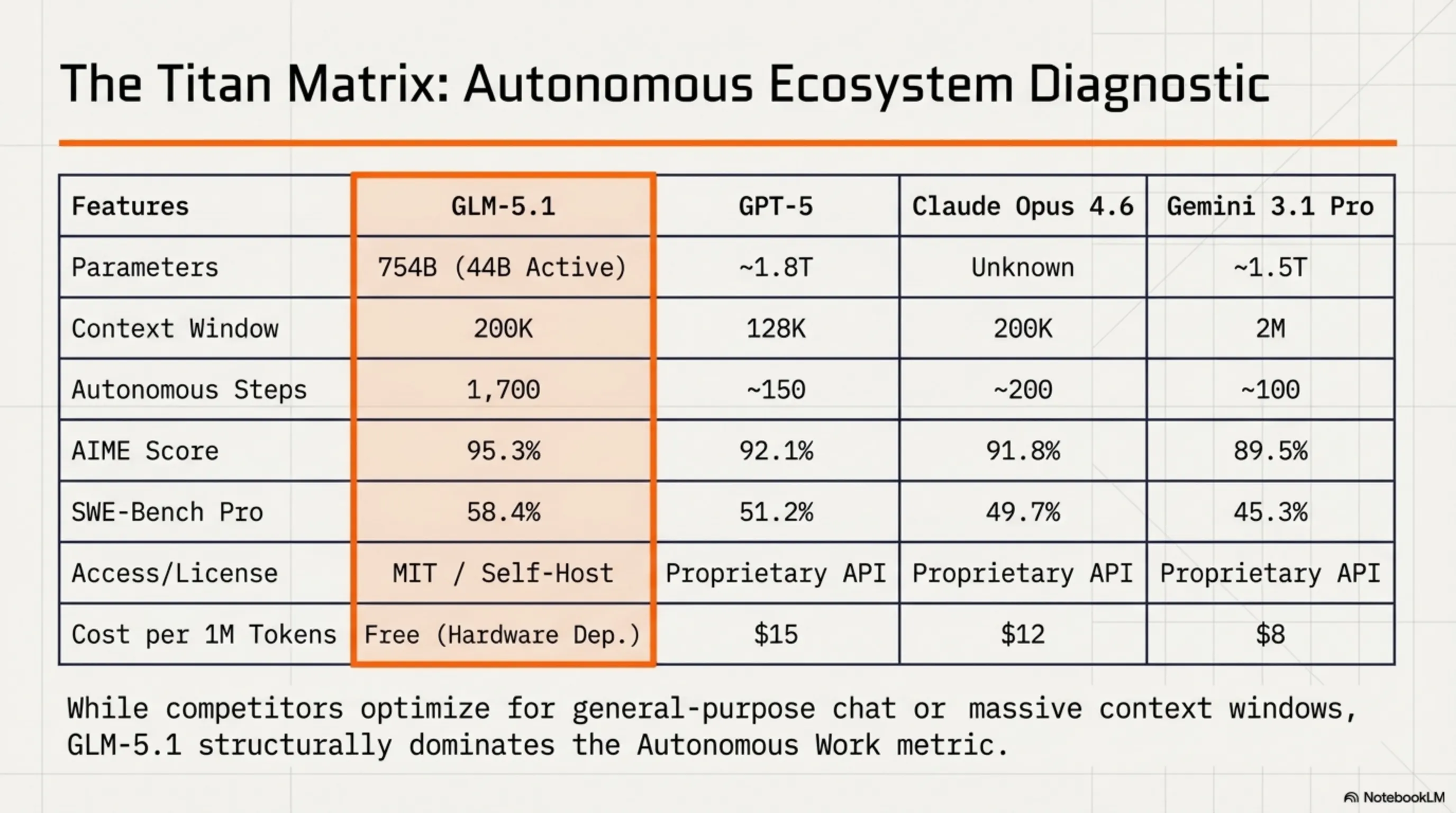
⚔️ مقارنة المنافسين: GLM-5.1 ضد عمالقة الذكاء الاصطناعي
الآن لنقارن GLM-5.1 مع منافسيه الرئيسيين: GPT-5 من OpenAI، وClaude Opus 4.6 من Anthropic، وGemini 3.1 Pro من Google.
🔍 مقارنة شاملة لنماذج الذكاء الاصطناعي
| الميزة | GLM-5.1 | GPT-5 | Claude Opus 4.6 | Gemini 3.1 Pro |
|---|---|---|---|---|
| المعاملات | 754B (44B نشط) | ~1.8T (نشط غير معروف) | غير معروف | ~1.5T |
| نافذة السياق | 200K | 128K | 200K | 2M |
| الخطوات المستقلة | 1,700 | ~150 | ~200 | ~100 |
| نتيجة AIME | 95.3% | 92.1% | 91.8% | 89.5% |
| SWE-Bench Pro | 58.4% | 51.2% | 49.7% | 45.3% |
| الرخصة | MIT (مفتوح) | خاص | خاص | خاص |
| الوصول | تنزيل + API | API فقط | API فقط | API فقط |
| التكلفة (تقريبية) | مجاني (استضافة ذاتية) | $15/1M رمز | $12/1M رمز | $8/1M رمز |
🏆 حكم المقارنة
إذا كنت بحاجة لوكيل ذكاء اصطناعي للمشاريع الطويلة والمعقدة، فإن GLM-5.1 هو الخيار الأفضل - خاصة إذا كنت تريد الاستضافة الذاتية أو تقليل التكاليف. إذا كنت بحاجة لنموذج متعدد الأغراض مع نظام بيئي قوي، فإن GPT-5 لا يزال الملك. إذا كانت السلامة والسياق الكبير مهمين، فإن Claude وGemini خيارات جيدة. لكن للبرمجة المستقلة؟ GLM-5.1 لا مثيل له.
🛠️ التطبيقات العملية: من البرمجة إلى DevOps
إذاً GLM-5.1 قوي - لكن كيف يمكنك استخدامه في العالم الحقيقي؟ لنستكشف بعض حالات الاستخدام العملية:
💻 1. تطوير Full-Stack
تخيل أنك تريد بناء تطبيق ويب كامل - واجهة React، خلفية Node.js، قاعدة بيانات PostgreSQL، ومصادقة JWT. مع GLM-5.1:
- الصباح: "ابنِ منصة تجارة إلكترونية بهذه الميزات..."
- الظهر: بنى النموذج الواجهة، كتب نقاط نهاية API، صمم مخطط قاعدة البيانات
- بعد الظهر: أضاف المصادقة، كتب الاختبارات، أكمل التوثيق
- المساء: جهز ملف Docker Compose للنشر
الوقت الموفر: من أسبوعين إلى يوم واحد - أسرع بنسبة 93%!
🔧 2. أتمتة DevOps
لديك بنية تحتية معقدة تحتاج للأتمتة. يمكن لـ GLM-5.1:
- بناء خطوط CI/CD (GitHub Actions، GitLab CI، Jenkins)
- كتابة البنية التحتية كرمز (Terraform، CloudFormation)
- إعداد المراقبة والتنبيهات (Prometheus، Grafana)
- إنشاء نصوص النسخ الاحتياطي واستعادة الكوارث
الفائدة: مهندس DevOps واحد يمكنه القيام بعمل خمسة
📚 3. توليد التوثيق
لديك API كبير بدون توثيق - 200 نقطة نهاية، بدون تعليقات، بدون شروحات. GLM-5.1:
- يحلل API بالكامل ويفهم ما تفعله كل نقطة نهاية
- ينشئ مواصفات OpenAPI/Swagger كاملة
- يكتب README ودليل البدء
- ينشئ أمثلة أكواد لكل نقطة نهاية
الجودة: توثيق أفضل من معظم المطورين البشريين!
💡 احسب عائد الاستثمار
افترض أن مطوراً كبيراً يكلف $100/ساعة. إذا كان GLM-5.1 يمكنه التعامل مع 50% من العمل الروتيني، فأنت توفر حوالي $8,000 شهرياً - بينما تكلف استضافة GLM-5.1 ذاتياً حوالي $500-1000/شهر (حسب الأجهزة). هذا عائد استثمار حوالي 800%!
⚠️ القيود والتحديات: ما تحتاج معرفته
GLM-5.1 مذهل، لكن مثل أي تقنية، له قيود وتحديات. لنتحدث عنها بصراحة:
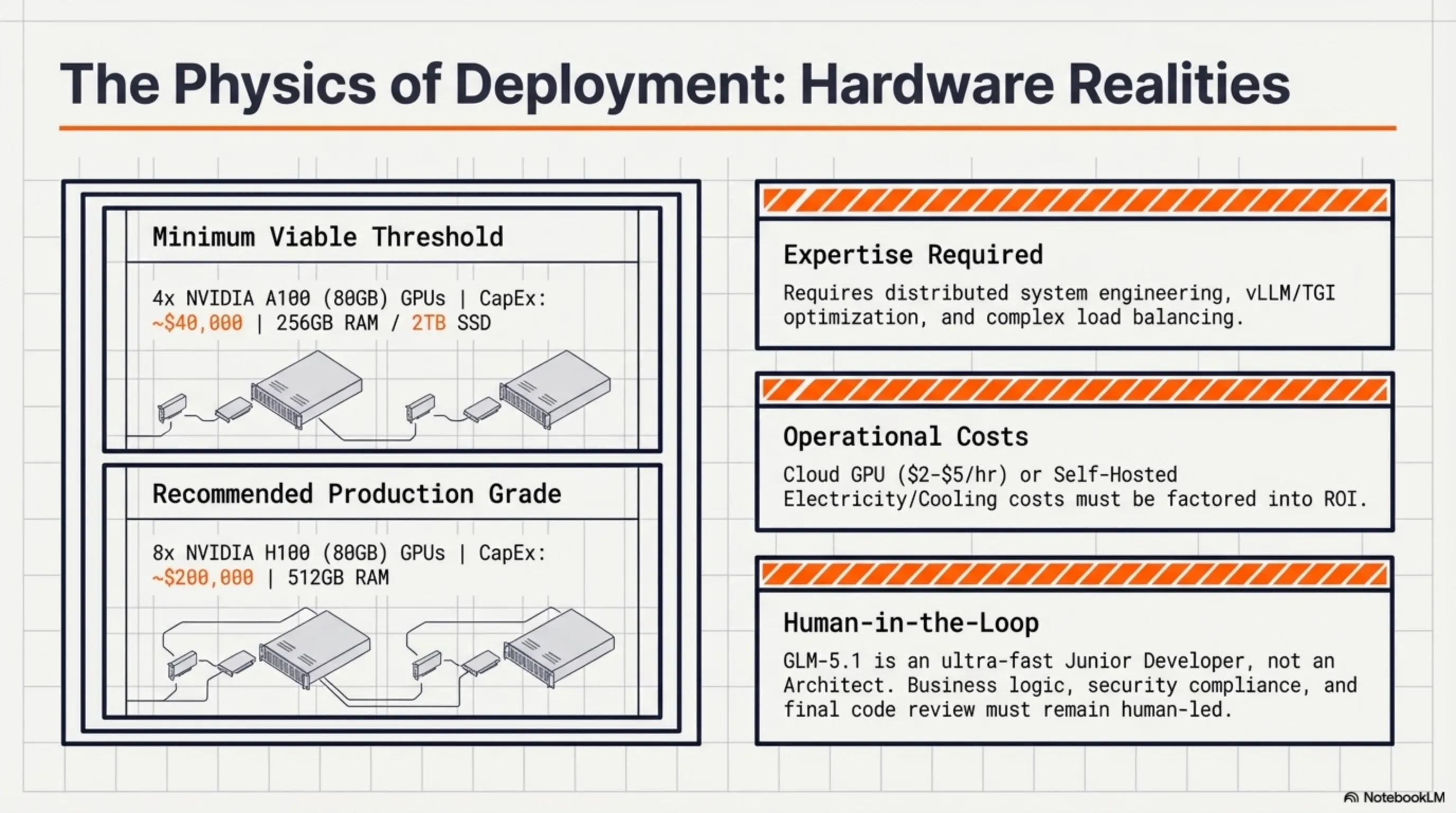
🖥️ 1. يتطلب أجهزة قوية
مع 754B معامل إجمالي و44B معامل نشط، يحتاج GLM-5.1 لأجهزة جادة:
- الحد الأدنى: 4x A100 80GB GPUs (~$40,000)
- الموصى به: 8x H100 80GB GPUs (~$200,000)
- RAM: حد أدنى 256GB، موصى به 512GB
- التخزين: حد أدنى 2TB SSD لأوزان النموذج
الحل: استخدام مزودي السحابة مثل AWS أو GCP أو Azure مع نسخ GPU. أو استخدام نسخ مكممة (4-bit، 8-bit) تتطلب أجهزة أقل.
💰 2. تكاليف الاستنتاج
بينما النموذج مجاني، تشغيله ليس كذلك:
- GPU السحابي: $2-5 في الساعة (حسب المزود)
- الكهرباء: ~$0.50-1 في الساعة للاستضافة الذاتية
- التبريد: تكاليف إضافية لأنظمة التبريد
الحل: استخدام المعالجة الدفعية، التخزين المؤقت، وتقنيات التحسين لتقليل التكاليف.
🌍 3. قيود اللغة
GLM-5.1 مدرب بشكل أساسي على الصينية والإنجليزية. للغات الأخرى:
- الإنجليزية: أداء ممتاز ✅
- الصينية: أداء ممتاز ✅
- اللغات الأوروبية: أداء جيد ⚠️
- العربية، الفارسية، إلخ: أداء متوسط ⚠️
الحل: الضبط الدقيق على لغتك المستهدفة، أو استخدام طبقة ترجمة.
⚠️ تحذير مهم
GLM-5.1 أداة قوية، لكنه ليس بديلاً كاملاً للمطورين البشريين. لا تزال بحاجة إلى:
• تحديد المعمارية والتصميم العام
• مراجعة جودة الكود
• اتخاذ قرارات منطق الأعمال
• التحقق من الأمان والامتثال
فكر في GLM-5.1 كمطور مبتدئ سريع وذكي جداً - وليس مهندساً معمارياً أو قائد تقني.
🔮 المستقبل: ما القادم؟
GLM-5.1 هو مجرد البداية. تعمل Z.ai ومجتمع المصدر المفتوح على أشياء مثيرة:
🗺️ خارطة الطريق المستقبلية
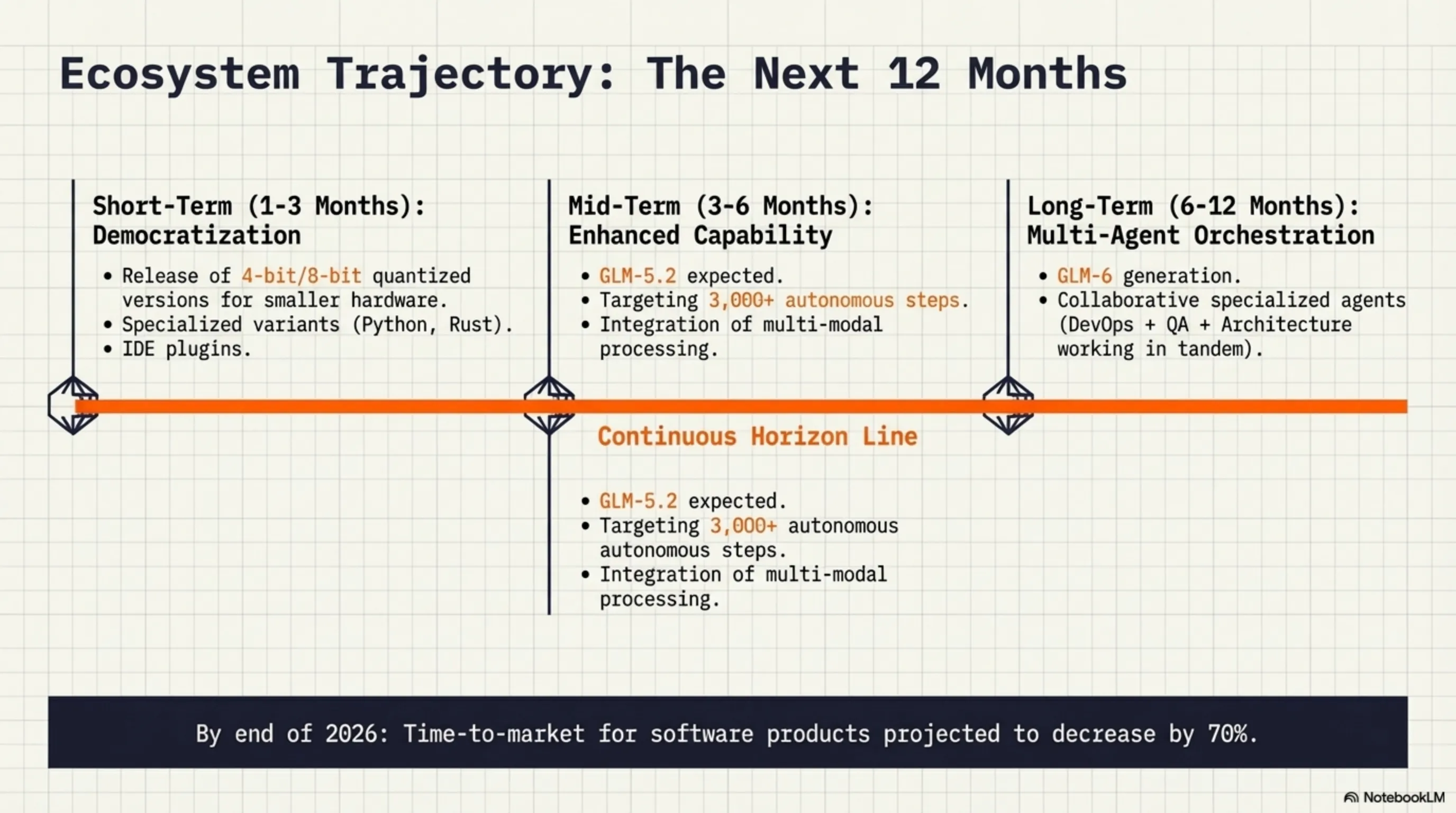
📅 قصير المدى (1-3 أشهر)
- نسخ مكممة: نسخ 4-bit و8-bit لأجهزة أقل
- متغيرات مضبوطة بدقة: نسخ متخصصة لـ Python، JavaScript، Rust، إلخ
- أدوات أفضل: أدوات محسنة للنشر والمراقبة
- إضافات المجتمع: التكامل مع IDEs وأدوات التطوير
📅 متوسط المدى (3-6 أشهر)
- GLM-5.2: نسخة محسنة مع خطوات مستقلة أكثر (هدف: 3000+)
- دعم متعدد الوسائط: القدرة على العمل مع الصور والفيديو والصوت
- تفكير أفضل: تحسينات في التفكير الرياضي والمنطقي
- استنتاج أسرع: تحسينات جديدة لسرعة أعلى
📅 طويل المدى (6-12 شهراً)
- GLM-6: الجيل التالي مع قدرات أكثر
- وكلاء متخصصون: وكلاء مخصصون لـ DevOps، الأمان، الاختبار، إلخ
- وكلاء تعاونيون: وكلاء متعددون يعملون معاً
- وكلاء ذاتيو التحسين: وكلاء يتعلمون من التجربة ويتحسنون
🔮 توقعاتنا
بحلول نهاية 2026، نتوقع:
- 50% من الشركات الناشئة التقنية ستستخدم وكلاء ذكاء اصطناعي مثل GLM-5.1
- متوسط حجم فريق التطوير سينكمش من 10 إلى 3-4 أشخاص
- وقت الوصول للسوق للمنتجات الجديدة سينخفض بنسبة 70%
- دور المطور سيتحول من "البرمجة" إلى "المعمارية والتصميم"
هذا تحول نموذجي - مثل الانتقال من assembly إلى لغات عالية المستوى، أو من waterfall إلى agile. من يتكيف مبكراً سيفوز.
🎯 الخلاصة: هل GLM-5.1 يستحق التجربة؟
بعد فحص GLM-5.1 بدقة - من المعمارية التقنية إلى التطبيقات العملية، من المعايير إلى القيود - حان الوقت للإجابة على السؤال الرئيسي: هل GLM-5.1 يستحق التجربة؟
الإجابة القصيرة: نعم، بالتأكيد!
الإجابة الطويلة: يعتمد على حالة استخدامك. لنرى لمن GLM-5.1 مناسب:
✅ مثالي لـ:
- الشركات الناشئة ذات الفرق الصغيرة التي تريد التوسع بسرعة
- الشركات التي تتطلع لتقليل تكاليف التطوير
- مشاريع المصدر المفتوح التي تحتاج لمزيد من المساهمين
- المطورين الذين يريدون مضاعفة إنتاجيتهم 10 مرات
- الشركات التي تريد الاستضافة الذاتية (للخصوصية/الأمان)
❌ قد لا يكون مناسباً لـ:
- المشاريع الصغيرة جداً حيث APIs الخاصة أكثر فعالية من حيث التكلفة
- الفرق التي تفتقر للخبرة في نشر النماذج الكبيرة
- حالات الاستخدام التي تتطلب لغات غير الإنجليزية/الصينية
- الشركات غير القادرة على الاستثمار في الأجهزة
🏆 الحكم النهائي
GLM-5.1 هو مغير حقيقي لقواعد اللعبة. مع القدرة على العمل بشكل مستقل لمدة 8 ساعات، أداء متفوق في المعايير، ورخصة MIT مجانية تماماً، هذا النموذج يعيد كتابة تعريف "وكيل الذكاء الاصطناعي". إذا كنت مطوراً، أو CTO، أو مؤسساً تريد البقاء متقدماً على المنافسين، فقد حان الوقت لتجربة GLM-5.1.
🚀 مستعد للبدء؟
نزّل GLM-5.1 من Hugging Face واختبر الثورة:
https://huggingface.co/zai-org/GLM-5
كُتب هذا المقال في 9 أبريل 2026. للحصول على أحدث المعلومات، تأكد من زيارة موقع Z.ai الرسمي.
وسائل التواصل الاجتماعي
اتصل بنامعرض صور إضافي: GLM-5.1: أول ذكاء اصطناعي يبرمج لمدة 8 ساعات متواصلة 🤖