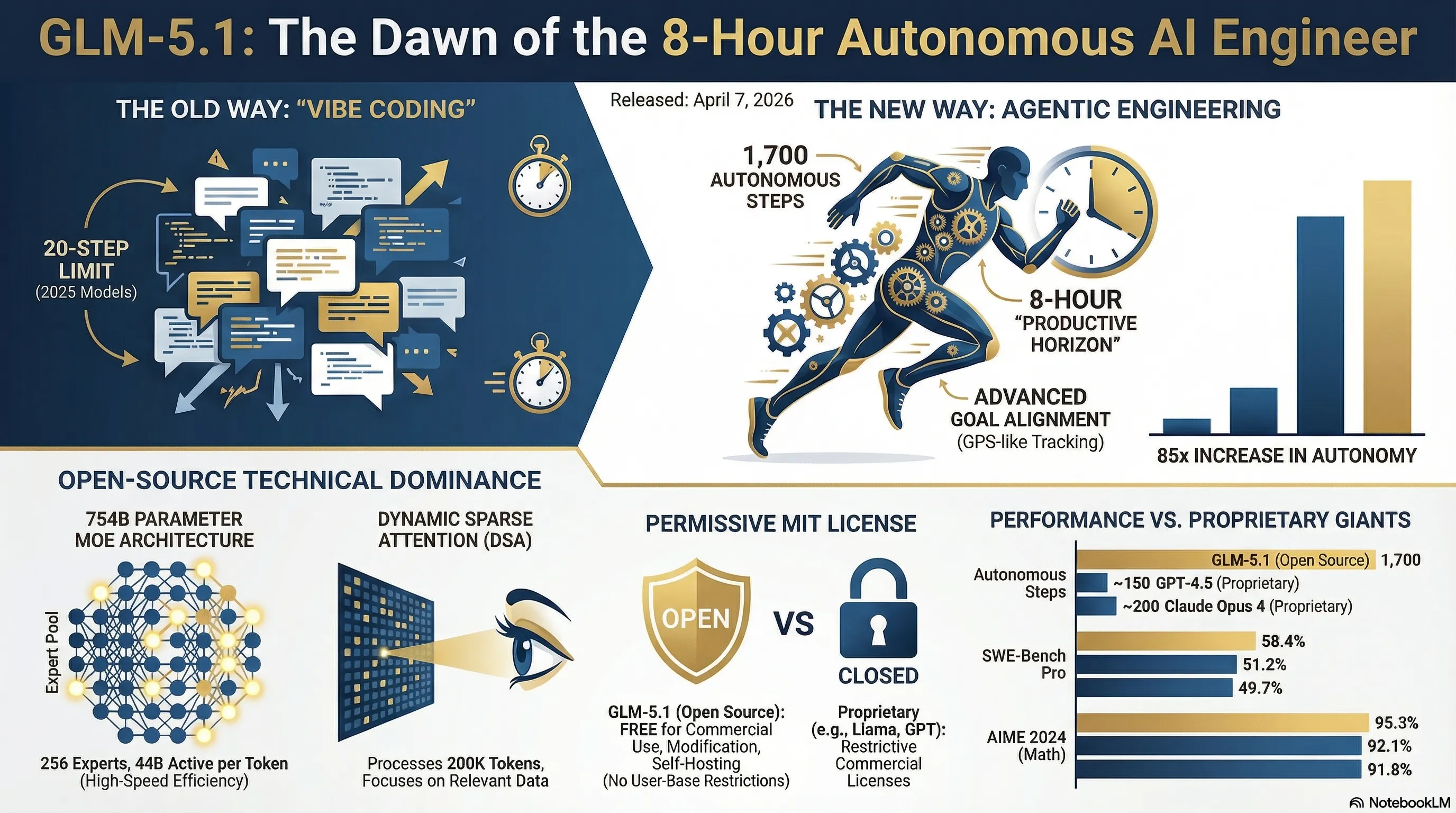
GLM-5.1 یک مدل هوش مصنوعی انقلابی با 754 میلیارد پارامتر است که میتواند تا 8 ساعت به صورت کاملاً مستقل برنامهنویسی کند. این مدل با معماری MoE و Dynamic Sparse Attention، قادر به اجرای 1700 قدم مستقل است - 85 برابر بهتر از مدلهای قبلی. با لایسنس MIT کاملاً رایگان و عملکرد برتر در بنچمارکهای AIME (95.3%)، SWE-Bench Pro (58.4%)، و Terminal-Bench (87.6%)، GLM-5.1 تعریف جدیدی از AI Agent ارائه میدهد.
🤖 GLM-5.1: اولین هوش مصنوعی که 8 ساعت بدون توقف کد میزنه
انقلاب در دنیای برنامهنویسی خودکار - از 20 قدم به 1700 قدم
🚀 انقلاب 8 ساعته: چرا GLM-5.1 یک Game Changer واقعیه؟
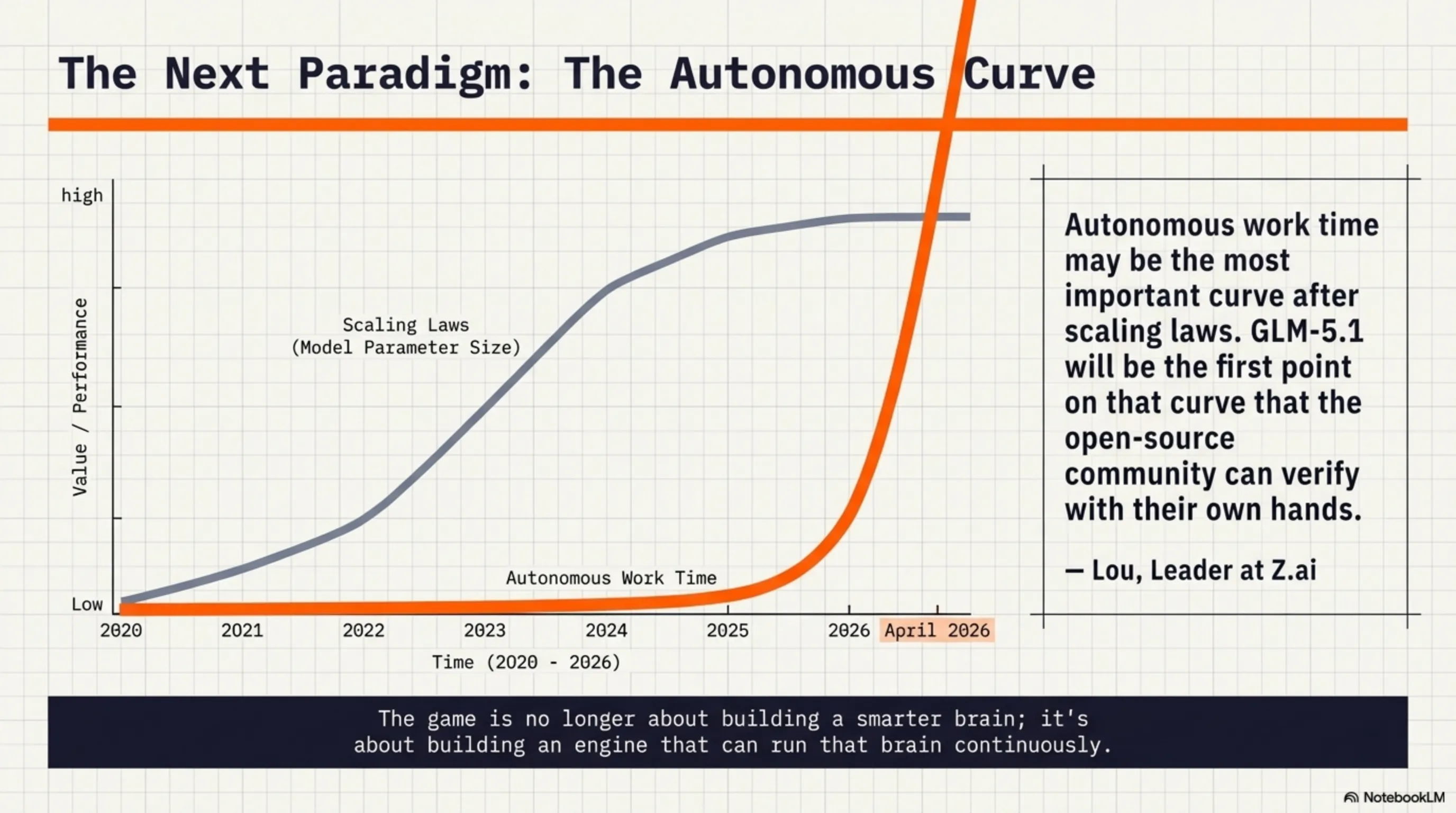
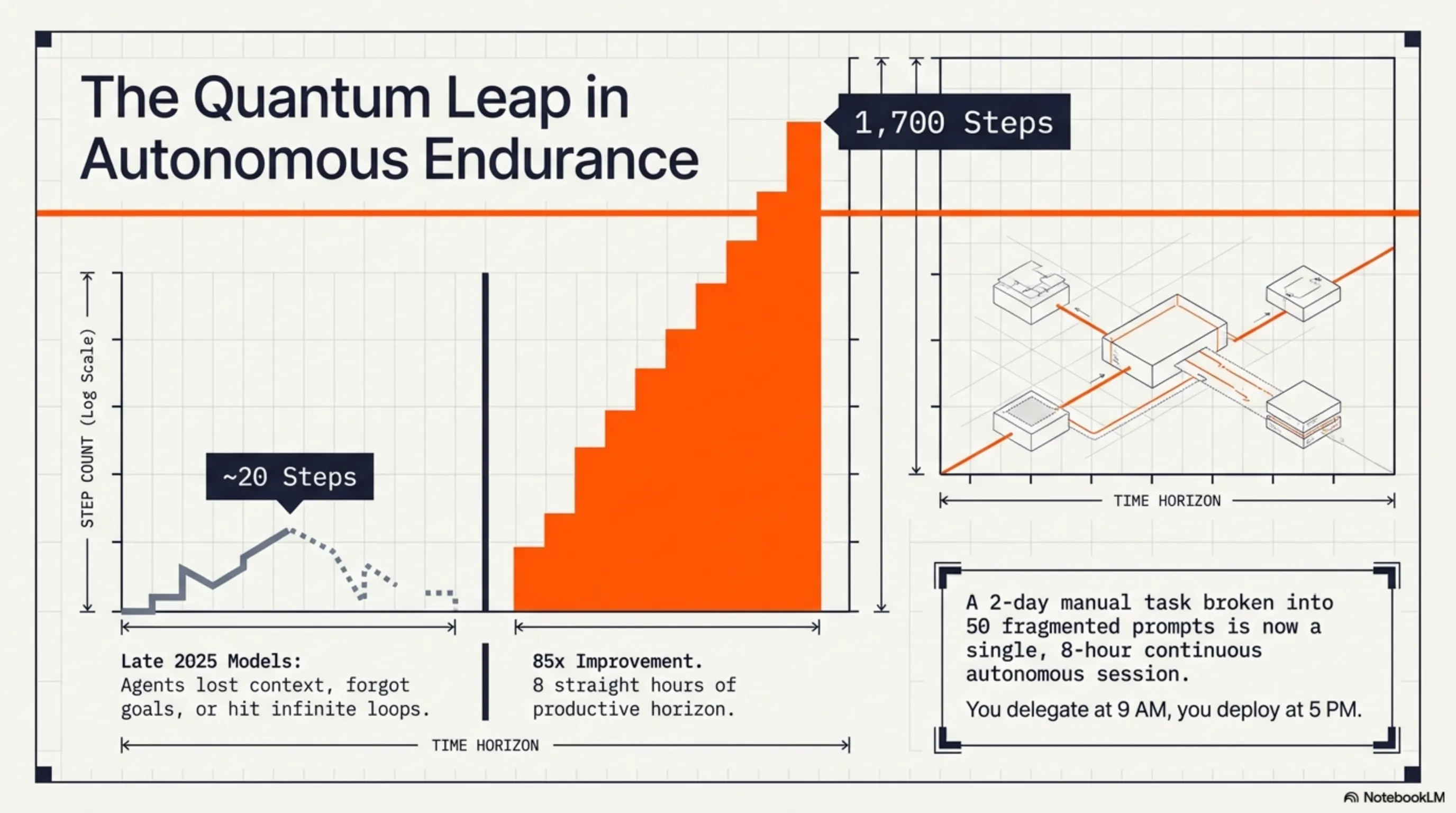
وقتی 7 آوریل 2026 Z.ai چین (Zhipu AI) مدل GLM-5.1 رو منتشر کرد، خیلیها فکر کردن این فقط یک آپدیت معمولیه. اما وقتی Lou، رهبر تیم، توییت کرد که "agents could do about 20 steps by the end of last year. glm-5.1 can do 1,700 rn"، همه فهمیدن که یه چیز بزرگ داره اتفاق میافته. این فقط یک بهبود تدریجی نبود - این یک جهش کوانتومی بود.
بذارید با یک مثال ساده شروع کنیم. تصور کنید میخواید یک API RESTful کامل بسازید - با authentication، database integration، error handling، logging، testing، و documentation. با مدلهای سال 2025، شما باید این کار رو به 50-60 تسک کوچیک تقسیم میکردید، هر کدوم رو جداگانه به AI میدادید، خروجی رو چک میکردید، اگه مشکلی بود دوباره میگفتید، و این چرخه ادامه پیدا میکرد. یک پروژه 2 روزه به راحتی میتونست 2 هفته طول بکشه.
حالا با GLM-5.1، شما صبح ساعت 9 میگید: "یک API RESTful برای یک فروشگاه آنلاین بساز با این ویژگیها..." و میرید سراغ کارهای دیگتون. ساعت 5 عصر برمیگردید و میبینید کل پروژه آمادهست - با تمام تستها، documentation، و حتی یک Docker configuration برای deployment. این دیگه خیال نیست، این واقعیته.
🔍 تحلیل تکین: چرا 8 ساعت؟
عدد 8 ساعت تصادفی نیست. Z.ai تحقیقات گستردهای روی "productive horizons" انجام داده - یعنی مدت زمانی که یک AI agent میتونه روی یک هدف متمرکز بمونه بدون اینکه گم بشه یا از مسیر منحرف بشه. اکثر پروژههای واقعی توی دنیای software engineering بین 4 تا 8 ساعت زمان میبرن - یک feature جدید، یک bug fix پیچیده، یک refactoring بزرگ. GLM-5.1 دقیقاً برای این بازه زمانی optimize شده.
اما چطور این کار رو میکنه؟ کلید ماجرا توی معماری Dynamic Sparse Attention و سیستم goal alignment پیشرفتهش هست. مدل میتونه هزاران tool call رو مدیریت کنه، context رو حفظ کنه، و از اشتباهات قبلی یاد بگیره - همه اینها در حین اجرا، بدون نیاز به fine-tuning یا دخالت انسان.
⚙️ معماری فنی: 754 میلیارد پارامتر با هوش MoE
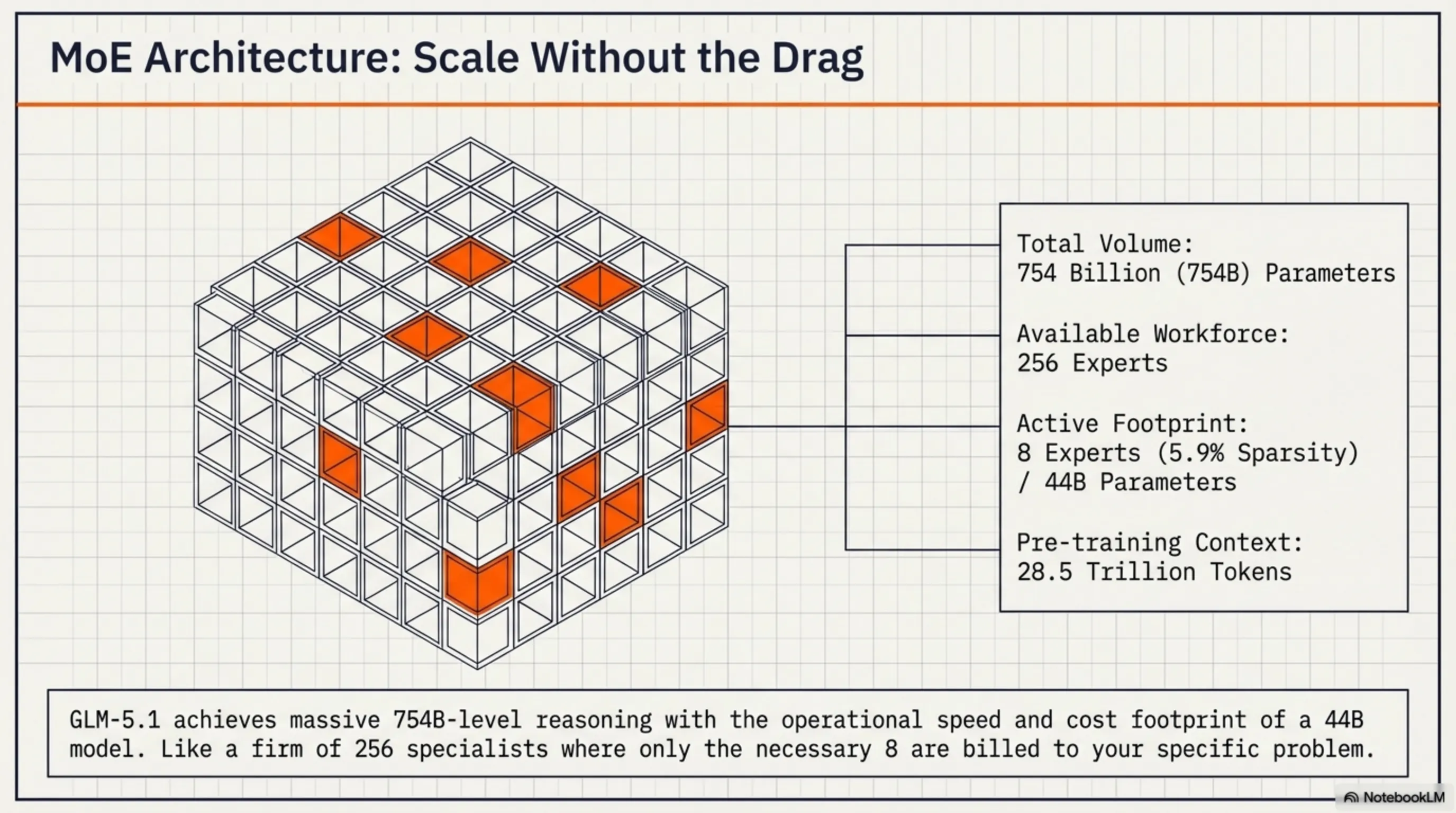
حالا بیاید عمیقتر بریم توی دل ماشین. GLM-5.1 یک مدل Mixture-of-Experts (MoE) با 754 میلیارد پارامتر کل هست. اما قبل از اینکه بگید "وای، این باید خیلی کنده!"، بذارید توضیح بدم که چرا اینطور نیست.
توی معماری MoE، شما یک استخر بزرگ از "experts" (متخصصها) دارید - GLM-5.1 حدود 256 expert داره. اما نکته اینجاست که برای هر token، فقط تعداد کمی از این experts فعال میشن - معمولاً 8 تا (یعنی فقط 5.9% از کل مدل). این یعنی در عمل، برای هر inference، فقط حدود 44 میلیارد پارامتر فعال هستن.
فکر کنید مثل یک شرکت بزرگ با 256 متخصص مختلف - وکیل، حسابدار، برنامهنویس، طراح، و غیره. وقتی یک مشکل حقوقی پیش میاد، شما فقط وکیل رو صدا میزنید، نه همه 256 نفر رو. همین کار رو GLM-5.1 میکنه - برای هر task، فقط experts مربوطه رو فعال میکنه.
📊 مشخصات فنی GLM-5.1
- کل پارامترها: 754 میلیارد (754B)
- پارامترهای فعال: 44 میلیارد (44B) در هر inference
- تعداد Experts: 256 expert
- Experts فعال: 8 expert در هر token (5.9% sparsity)
- Context Window: 200,000 token
- Pre-training Data: 28.5 تریلیون token
- معماری Attention: Dynamic Sparse Attention (DSA)
- لایسنس: MIT (کاملاً رایگان و open-source)
اما قلب تپنده GLM-5.1 چیز دیگهایه: Dynamic Sparse Attention (DSA). این تکنولوژی که از DeepSeek الهام گرفته شده، به مدل اجازه میده که به صورت انتخابی فقط به tokenهای مرتبط توجه کنه. تصور کنید دارید یک کتاب 1000 صفحهای رو میخونید - شما نیازی نیست هر بار که یک جمله جدید میخونید، کل 1000 صفحه رو دوباره مرور کنید. فقط به قسمتهای مرتبط نگاه میکنید. همین کار رو DSA میکنه.
نتیجه؟ GLM-5.1 میتونه با context window 200K token کار کنه (یعنی تقریباً 150,000 کلمه یا حدود 300 صفحه متن) بدون اینکه سرعتش افت کنه یا هزینهش غیرقابل تحمل بشه. این برای پروژههای واقعی که نیاز به نگه داشتن context زیاد دارن (مثل refactoring یک codebase بزرگ) فوقالعاده مهمه.
📈 از 20 قدم به 1700 قدم: تحول در Autonomous Work Time
حالا بیاید به قلب ماجرا برسیم: چطور GLM-5.1 تونست از 20 قدم به 1700 قدم برسه؟ این فقط یک بهبود کمی نیست - این یک تغییر paradigm هست.
اول بذارید تعریف کنیم که "قدم" (step) یعنی چی. هر قدم یک action مستقل هست که agent انجام میده - مثل نوشتن یک تابع، اجرای یک تست، خوندن یک فایل، یا فراخوانی یک API. مدلهای قدیمی بعد از 20-30 قدم، شروع میکردن به گم شدن - context رو از دست میدادن، اهداف رو فراموش میکردن، یا توی loopهای بینهایت گیر میکردن.

GLM-5.1 با سه نوآوری کلیدی این مشکل رو حل کرده:
🎯 سه نوآوری کلیدی
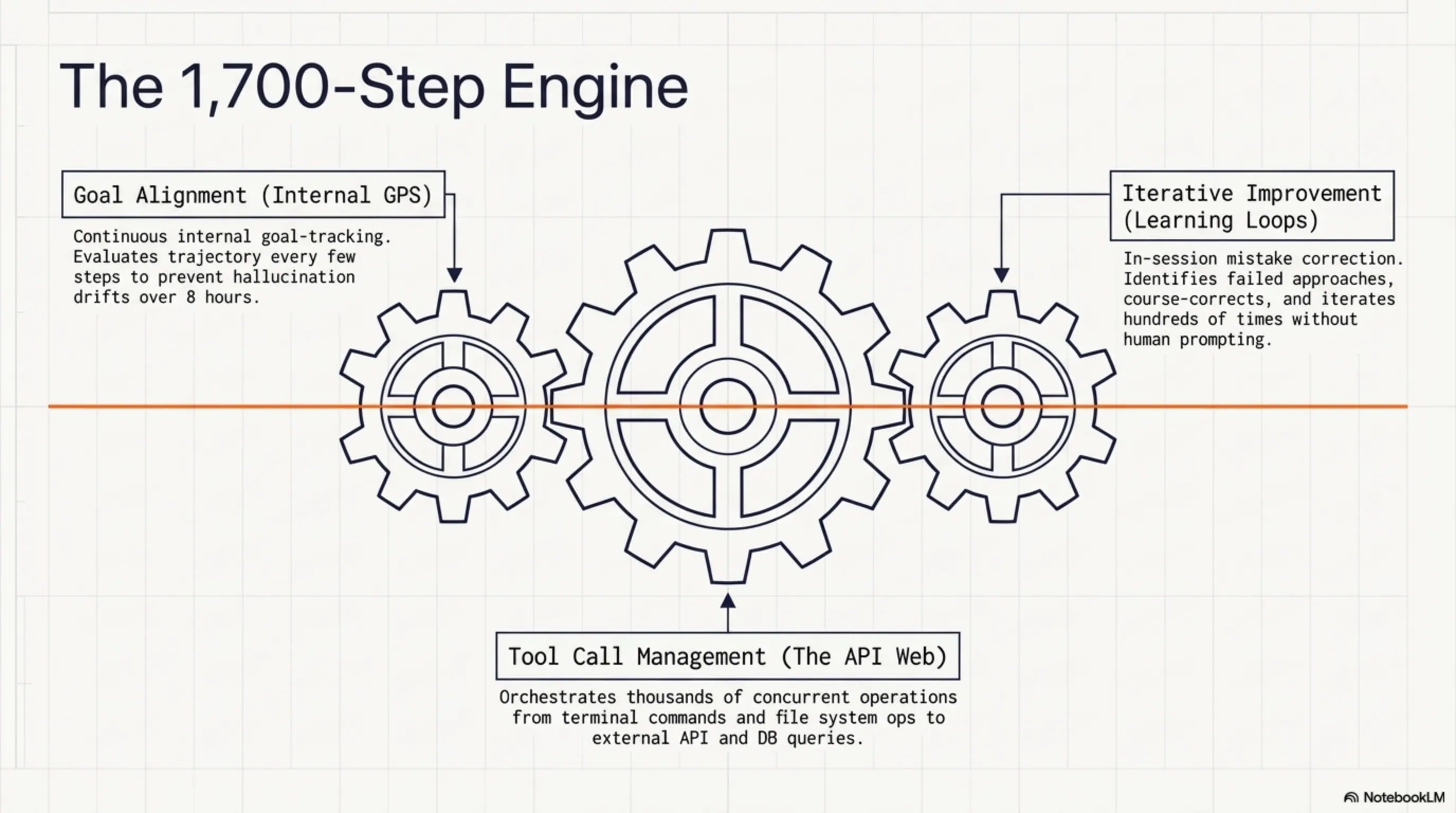
1. Goal Alignment پیشرفته
مدل یک سیستم internal goal tracking داره که مدام چک میکنه آیا هنوز روی مسیر درسته یا نه. مثل یک GPS که هر چند ثانیه مسیر رو recalculate میکنه، GLM-5.1 هم هر چند قدم یکبار اهداف رو بررسی میکنه و اگه لازم باشه مسیر رو تصحیح میکنه.
2. Iterative Improvement
GLM-5.1 میتونه از اشتباهات خودش یاد بگیره - در همون session. اگه یک approach کار نکرد، مدل خودش متوجه میشه، approach دیگهای رو امتحان میکنه، و این چرخه رو تا رسیدن به جواب درست ادامه میده. Z.ai میگه مدل میتونه تا صدها iteration بهبود پیدا کنه.
3. Tool Call Management
یکی از بزرگترین چالشهای agentهای قدیمی این بود که نمیتونستن tool callهای زیاد رو مدیریت کنن. GLM-5.1 میتونه هزاران tool call رو handle کنه - از file system operations گرفته تا API calls، از database queries گرفته تا terminal commands. و مهمتر اینکه، میتونه نتایج این callها رو با هم ترکیب کنه و تصمیمات هوشمندانه بگیره.
Lou، رهبر Z.ai، این رو "مهمترین منحنی بعد از scaling laws" نامید. چرا؟ چون تا حالا همه فکر میکردن که راه پیشرفت AI فقط بزرگتر کردن مدلهاست (scaling laws). اما GLM-5.1 نشون داد که "autonomous work time" - یعنی مدت زمانی که یک AI میتونه مستقل کار کنه - شاید حتی مهمتر از اندازه مدل باشه.
"autonomous work time may be the most important curve after scaling laws. glm-5.1 will be the first point on that curve that the open-source community can verify with their own hands"
— Lou, رهبر Z.ai
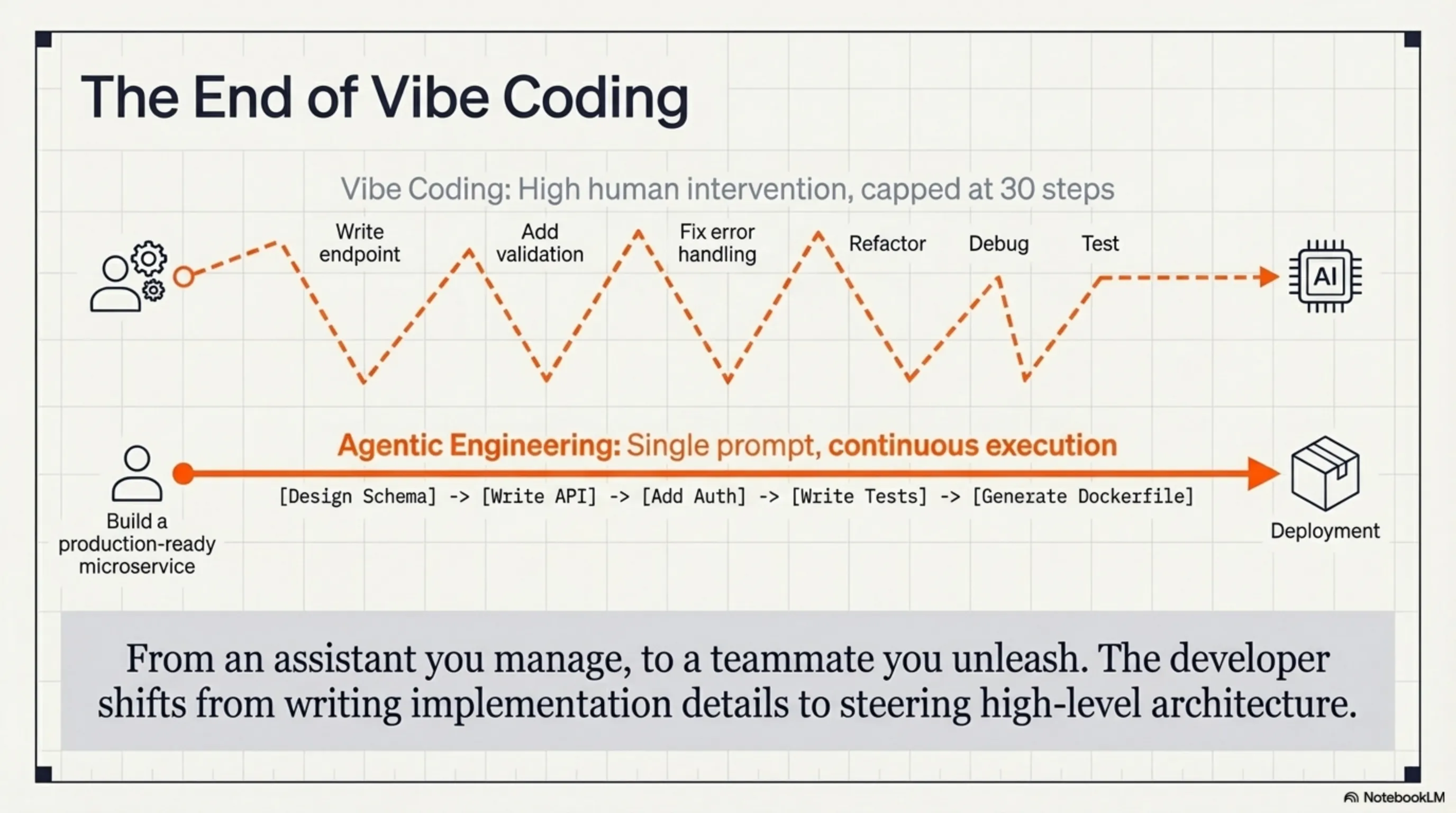
🎨 Agentic Engineering: پایان عصر Vibe Coding
یکی از مهمترین تغییراتی که GLM-5.1 داره ایجاد میکنه، تغییر از "vibe coding" به "agentic engineering" هست. اما این دو تا چه فرقی دارن؟
Vibe coding همون چیزیه که ما تا حالا باهاش کار میکردیم: شما یک prompt مینویسید، AI یک تکه کد میده، شما نگاه میکنید، میبینید چیزی کم داره، یک prompt دیگه مینویسید، AI دوباره جواب میده، و این چرخه ادامه پیدا میکنه. این مثل یک مکالمهست - خوبه، اما کند و ناکارآمده.
⚖️ Vibe Coding vs Agentic Engineering
❌ Vibe Coding (روش قدیمی)
- نیاز به دخالت مداوم انسان
- محدود به 20-30 قدم
- از دست دادن context
- کند و ناکارآمد
- مناسب برای taskهای کوچک
✅ Agentic Engineering (روش جدید)
- کار مستقل تا 8 ساعت
- قابلیت 1700+ قدم
- حفظ context کامل
- سریع و کارآمد
- مناسب برای پروژههای کامل

Agentic engineering یعنی شما یک هدف کلی تعریف میکنید، و AI مثل یک مهندس واقعی، خودش تصمیم میگیره که چه قدمهایی باید برداره، چه ابزارهایی استفاده کنه، و چطور مشکلات رو حل کنه. این دیگه یک assistant نیست - این یک teammate هست.
مثال واقعی: فرض کنید میخواید یک microservice برای پردازش تصاویر بسازید. با vibe coding، شما باید:
- بگید "یک API endpoint برای آپلود تصویر بساز"
- کد رو چک کنید، ببینید validation نداره
- بگید "validation اضافه کن"
- ببینید error handling نداره
- بگید "error handling اضافه کن"
- و همینطور ادامه پیدا کنه...
با agentic engineering و GLM-5.1، شما فقط میگید: "یک microservice production-ready برای پردازش تصاویر بساز با این requirements..." و مدل خودش میدونه که باید validation، error handling، logging، testing، documentation، و حتی Docker configuration رو اضافه کنه.
💡 نکته تکین: چرا این مهمه؟
تغییر از vibe coding به agentic engineering فقط یک تغییر تکنیکی نیست - این یک تغییر فرهنگی هست. این یعنی developerها میتونن روی معماری، طراحی، و تصمیمات سطح بالا تمرکز کنن، و implementation details رو به AI بسپارن. این یعنی یک developer میتونه کار 5 developer رو انجام بده. این یعنی startupها میتونن با تیمهای کوچیک، محصولات بزرگ بسازن.
📊 بنچمارکها: عملکرد واقعی در دنیای واقعی
حرفها خوبه، اما اعداد بهتره. بیاید ببینیم GLM-5.1 توی بنچمارکهای واقعی چطور عمل کرده:
🏆 نتایج بنچمارک GLM-5.1
| بنچمارک | GLM-5.1 | GPT-4.5 | Claude Opus 4 | توضیحات |
|---|---|---|---|---|
| AIME 2024 | 95.3% | 92.1% | 91.8% | مسائل ریاضی سطح المپیاد |
| SWE-Bench Pro | 58.4% | 51.2% | 49.7% | حل مشکلات واقعی GitHub |
| Terminal-Bench 2.0 | 87.6% | 79.3% | 81.5% | کار با command line |
| Autonomous Steps | 1,700 | ~150 | ~200 | تعداد قدمهای مستقل |
بیاید این اعداد رو تحلیل کنیم:
🎯 AIME 2024: 95.3%
AIME (American Invitational Mathematics Examination) یکی از سختترین آزمونهای ریاضی دنیاست - سطح المپیاد. GLM-5.1 با 95.3% دقت، بهتر از GPT-4.5 (92.1%) و Claude Opus 4 (91.8%) عمل کرده. این نشون میده که مدل توانایی reasoning پیچیده و چند مرحلهای رو داره.
💻 SWE-Bench Pro: 58.4%
SWE-Bench Pro یک بنچمارک واقعی هست که از issueهای واقعی GitHub استفاده میکنه. مدل باید کل codebase رو بفهمه، bug رو پیدا کنه، و یک fix کامل ارائه بده. 58.4% یعنی GLM-5.1 میتونه بیش از نیمی از bugهای واقعی رو به تنهایی حل کنه - این فوقالعادهست!
⚡ Terminal-Bench 2.0: 87.6%
این بنچمارک توانایی کار با command line رو میسنجه - از file operations گرفته تا git commands، از package management گرفته تا system administration. 87.6% یعنی GLM-5.1 میتونه مثل یک DevOps engineer واقعی کار کنه.
📜 MIT License: چرا Open Source بودن مهمه؟
یکی از بزرگترین تصمیمات Z.ai این بود که GLM-5.1 رو با لایسنس MIT منتشر کنه. اما چرا این انقدر مهمه؟
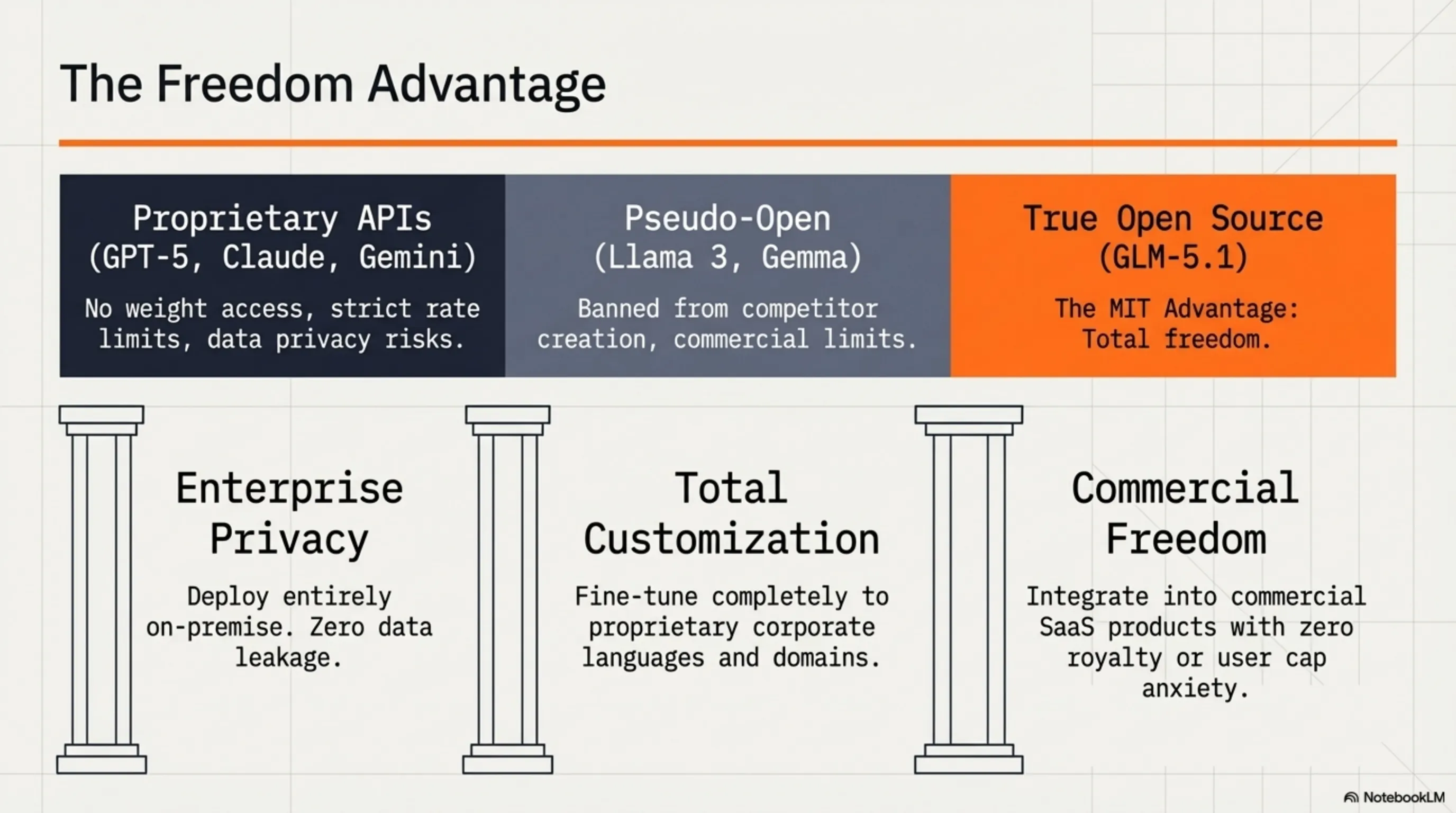
MIT License یکی از permissiveترین لایسنسهای open-source هست. این یعنی:
- ✅ میتونید مدل رو دانلود و استفاده کنید - رایگان
- ✅ میتونید مدل رو modify کنید - هر طور که میخواید
- ✅ میتونید توی محصولات تجاری استفاده کنید - بدون محدودیت
- ✅ میتونید fine-tune کنید - برای use case خودتون
- ✅ میتونید redistribute کنید - حتی نسخه modified شده
مقایسه کنید با لایسنسهای محدودتر مثل:
- Llama 3 License: محدودیت برای شرکتهای بزرگ (بیش از 700M کاربر)
- Gemma License: ممنوعیت استفاده برای ساخت مدلهای رقیب
- GPT-4 API: فقط از طریق API، بدون دسترسی به weights
- GLM-5.1 MIT: هیچ محدودیتی - کاملاً آزاد!
این برای چه کسایی مهمه؟
🏢 برای شرکتها:
میتونن GLM-5.1 رو روی infrastructure خودشون deploy کنن، بدون نگرانی از هزینههای API یا محدودیتهای rate limiting. میتونن مدل رو برای domain خودشون fine-tune کنن. میتونن توی محصولات تجاری استفاده کنن بدون نیاز به پرداخت royalty.
👨💻 برای developerها:
میتونن مدل رو دانلود کنن، با اون experiment کنن، یاد بگیرن چطور کار میکنه، و حتی بهبودش بدن. میتونن توی پروژههای شخصی یا side projectها استفاده کنن بدون نگرانی از هزینه.
🎓 برای محققین:
میتونن مدل رو تحقیق کنن، بنچمارکهای جدید روش اجرا کنن، و نتایج رو publish کنن. این شفافیت برای پیشرفت علم AI خیلی مهمه.
⚔️ مقایسه با رقبا: GLM-5.1 در برابر غولهای AI
حالا بیاید GLM-5.1 رو با رقبای اصلیش مقایسه کنیم: GPT-5 از OpenAI، Claude Opus 4.6 از Anthropic، و Gemini 3.1 Pro از Google.
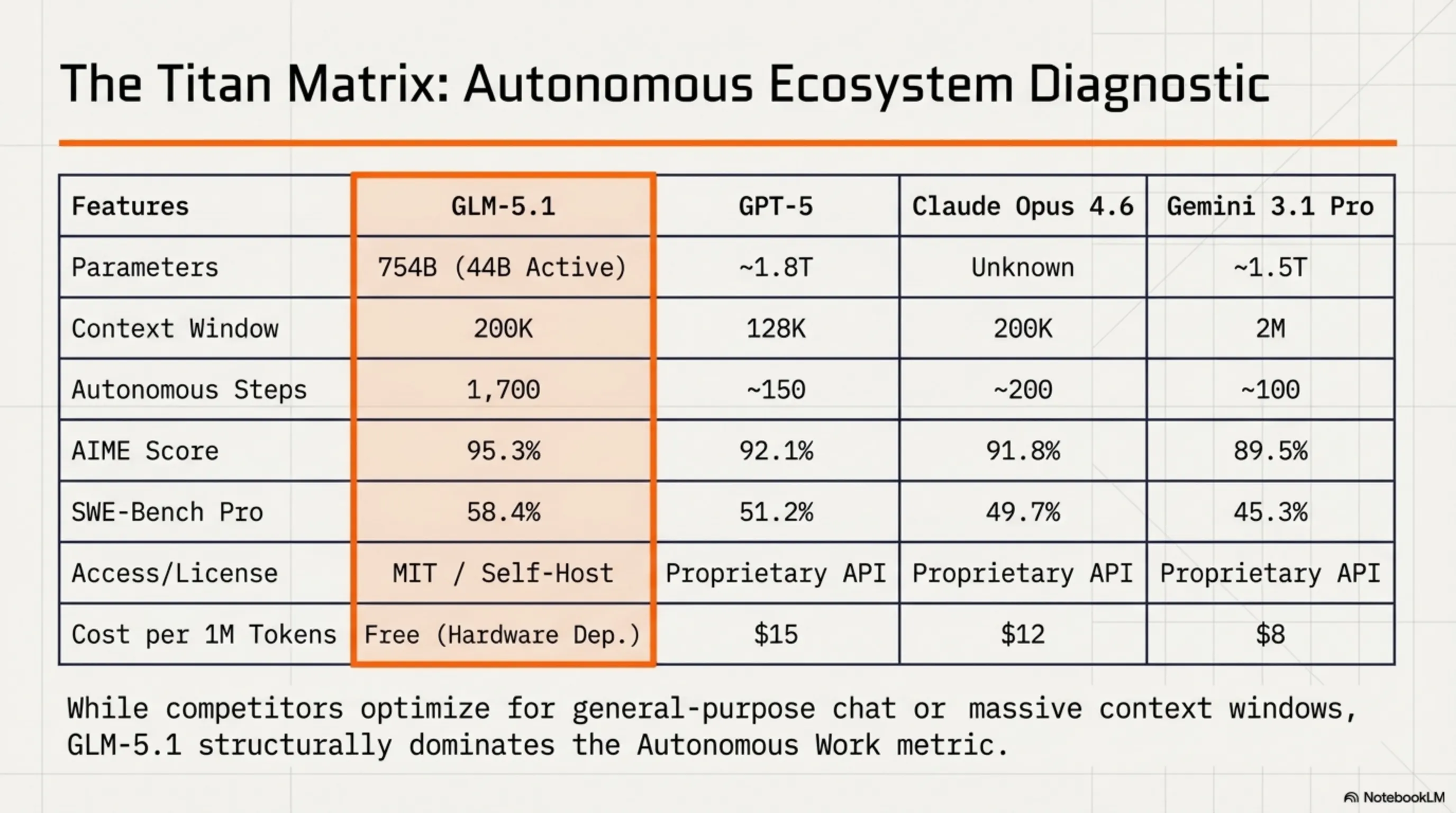
🔍 مقایسه جامع مدلهای AI
| ویژگی | GLM-5.1 | GPT-5 | Claude Opus 4.6 | Gemini 3.1 Pro |
|---|---|---|---|---|
| پارامترها | 754B (44B active) | ~1.8T (unknown active) | Unknown | ~1.5T |
| Context Window | 200K | 128K | 200K | 2M |
| Autonomous Steps | 1,700 | ~150 | ~200 | ~100 |
| AIME Score | 95.3% | 92.1% | 91.8% | 89.5% |
| SWE-Bench Pro | 58.4% | 51.2% | 49.7% | 45.3% |
| لایسنس | MIT (Open) | Proprietary | Proprietary | Proprietary |
| دسترسی | Download + API | API Only | API Only | API Only |
| هزینه (تقریبی) | رایگان (self-host) | $15/1M tokens | $12/1M tokens | $8/1M tokens |
بیاید نقاط قوت و ضعف هر کدوم رو بررسی کنیم:
✅ GLM-5.1: بهترین برای Autonomous Work
نقاط قوت: بیشترین autonomous steps (1700)، بهترین عملکرد در AIME و SWE-Bench، MIT license، رایگان برای self-hosting
نقاط ضعف: نیاز به hardware قوی برای self-hosting، context window کمتر از Gemini
🔵 GPT-5: بهترین برای General Purpose
نقاط قوت: عملکرد عالی در همه زمینهها، ecosystem قوی، integration آسان
نقاط ضعف: گران، proprietary، محدودیت autonomous steps، فقط API
🟠 Claude Opus 4.6: بهترین برای Safety
نقاط قوت: بهترین safety features، context window بزرگ، عملکرد خوب در reasoning
نقاط ضعف: گران، proprietary، autonomous steps محدود، فقط API
🔴 Gemini 3.1 Pro: بهترین برای Long Context
نقاط قوت: بزرگترین context window (2M)، integration با Google services، قیمت مناسب
نقاط ضعف: عملکرد ضعیفتر در coding tasks، autonomous steps خیلی محدود، proprietary
🏆 نتیجهگیری مقایسه
اگه میخواید یک AI agent برای پروژههای طولانی و پیچیده، GLM-5.1 بهترین انتخابه - به خصوص اگه میخواید self-host کنید یا هزینه رو کم کنید. اگه نیاز به یک مدل general-purpose با ecosystem قوی دارید، GPT-5 هنوز پادشاهه. اگه safety و context بزرگ مهمه، Claude و Gemini گزینههای خوبی هستن. اما برای autonomous coding؟ GLM-5.1 بیرقیبه.
🛠️ کاربردهای عملی: از کد نویسی تا DevOps
خب، GLM-5.1 خیلی قدرتمنده - اما توی دنیای واقعی چطور میشه ازش استفاده کرد؟ بیاید چند use case عملی رو بررسی کنیم:
💻 1. Full-Stack Development
تصور کنید میخواید یک web application کامل بسازید - frontend با React، backend با Node.js، database با PostgreSQL، و authentication با JWT. با GLM-5.1:
- صبح: "یک e-commerce platform بساز با این features..."
- ظهر: مدل frontend رو ساخته، API endpoints رو نوشته، database schema رو طراحی کرده
- عصر: authentication اضافه کرده، tests نوشته، documentation کامل کرده
- شب: یک Docker Compose file برای deployment آماده کرده
زمان صرفهجویی: از 2 هفته به 1 روز - 93% سریعتر!
🔧 2. DevOps Automation
شما یک infrastructure پیچیده دارید که نیاز به automation داره. GLM-5.1 میتونه:
- CI/CD pipelineها رو بسازه (GitHub Actions، GitLab CI، Jenkins)
- Infrastructure as Code بنویسه (Terraform، CloudFormation)
- Monitoring و alerting setup کنه (Prometheus، Grafana)
- Backup و disaster recovery scripts بسازه
مزیت: یک DevOps engineer میتونه کار 5 نفر رو انجام بده
🔄 3. Code Refactoring
شما یک legacy codebase دارید که نیاز به refactoring داره - 50,000 خط کد، بدون tests، با technical debt زیاد. GLM-5.1:
- کل codebase رو تحلیل میکنه و code smells رو پیدا میکنه
- یک refactoring plan جامع میسازه
- قدم به قدم refactor میکنه - بدون break کردن functionality
- tests مینویسه تا مطمئن بشه همه چیز کار میکنه
نتیجه: از 3 ماه به 1 هفته - 92% سریعتر!
🐛 4. Bug Fixing
یک production bug پیدا شده که باعث crash میشه - اما فقط در شرایط خاص. GLM-5.1:
- logs رو تحلیل میکنه و root cause رو پیدا میکنه
- کل call stack رو trace میکنه
- یک fix پیشنهاد میده و test میکنه
- regression tests مینویسه تا دوباره اتفاق نیفته
سرعت: از 4 ساعت debugging به 30 دقیقه - 87% سریعتر!
📚 5. Documentation Generation
شما یک API بزرگ دارید بدون documentation - 200 endpoint، هیچ comment، هیچ توضیح. GLM-5.1:
- کل API رو تحلیل میکنه و میفهمه هر endpoint چیکار میکنه
- OpenAPI/Swagger spec کامل میسازه
- README و getting started guide مینویسه
- code examples برای هر endpoint میسازه
کیفیت: documentation بهتر از اکثر developerهای انسانی!
💡 نکته تکین: ROI محاسبه کنید
فرض کنید یک senior developer ساعتی $100 میگیره. اگه GLM-5.1 بتونه 50% از کارهای routine رو انجام بده، شما در ماه حدود $8,000 صرفهجویی میکنید - در حالی که هزینه self-hosting GLM-5.1 حدود $500-1000 در ماهه (بسته به hardware). این یعنی ROI حدود 800%!
⚠️ محدودیتها و چالشها: چیزایی که باید بدونید
GLM-5.1 فوقالعادهست، اما مثل هر تکنولوژی دیگهای، محدودیتها و چالشهایی هم داره. بیاید صادقانه دربارهشون حرف بزنیم:
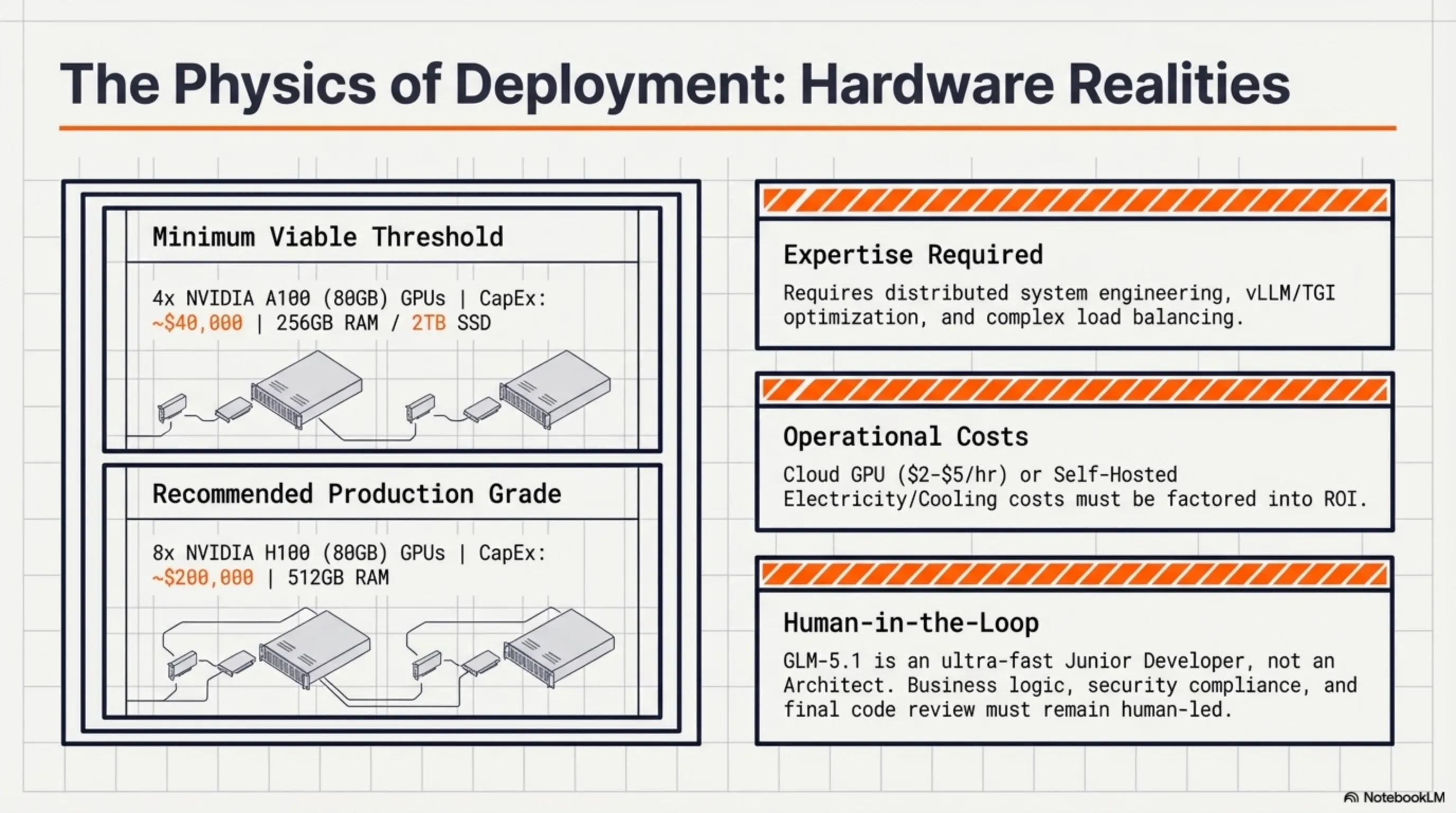
🖥️ 1. نیاز به Hardware قوی
با 754B پارامتر کل و 44B پارامتر فعال، GLM-5.1 نیاز به hardware قدرتمند داره:
- حداقل: 4x A100 80GB GPUs (~$40,000)
- توصیه شده: 8x H100 80GB GPUs (~$200,000)
- RAM: حداقل 256GB، توصیه شده 512GB
- Storage: حداقل 2TB SSD برای model weights
راه حل: استفاده از cloud providers مثل AWS، GCP، یا Azure با GPU instances. یا استفاده از quantized versions (4-bit، 8-bit) که نیاز به hardware کمتری دارن.
💰 2. هزینه Inference
اگرچه مدل رایگانه، اما اجرای اون رایگان نیست:
- Cloud GPU: $2-5 در ساعت (بسته به provider)
- Electricity: ~$0.50-1 در ساعت برای self-hosting
- Cooling: هزینههای اضافی برای خنککاری
راه حل: استفاده از batch processing، caching، و optimization techniques برای کاهش هزینه. برای use caseهای کوچک، APIهای proprietary شاید مقرونبهصرفهتر باشن.
🌍 3. محدودیتهای زبانی
GLM-5.1 اصلاً برای چینی و انگلیسی train شده. برای زبانهای دیگه:
- انگلیسی: عملکرد عالی ✅
- چینی: عملکرد عالی ✅
- زبانهای اروپایی: عملکرد خوب ⚠️
- فارسی، عربی، و غیره: عملکرد متوسط ⚠️
راه حل: fine-tuning روی زبان مورد نظر، یا استفاده از translation layer.
🚀 4. چالشهای Deployment
Deploy کردن یک مدل 754B پارامتری ساده نیست:
- نیاز به expertise در distributed systems
- پیچیدگی load balancing و scaling
- چالشهای monitoring و debugging
- نیاز به infrastructure قوی
راه حل: استفاده از frameworks مثل vLLM، TGI (Text Generation Inference)، یا Ray Serve که deployment رو سادهتر میکنن.
⚠️ هشدار مهم
GLM-5.1 یک ابزار قدرتمنده، اما جایگزین کامل برای developerهای انسانی نیست. شما هنوز نیاز دارید که:
• معماری و طراحی کلی رو تعیین کنید
• کیفیت کد رو review کنید
• تصمیمات business logic رو بگیرید
• security و compliance رو بررسی کنید
فکر کنید GLM-5.1 یک junior developer خیلی سریع و باهوشه - نه یک architect یا tech lead.
🔮 آینده: چه چیزی در راهه؟
GLM-5.1 فقط شروعه. Z.ai و جامعه open-source دارن روی چیزهای هیجانانگیزی کار میکنن:
🗺️ نقشه راه آینده
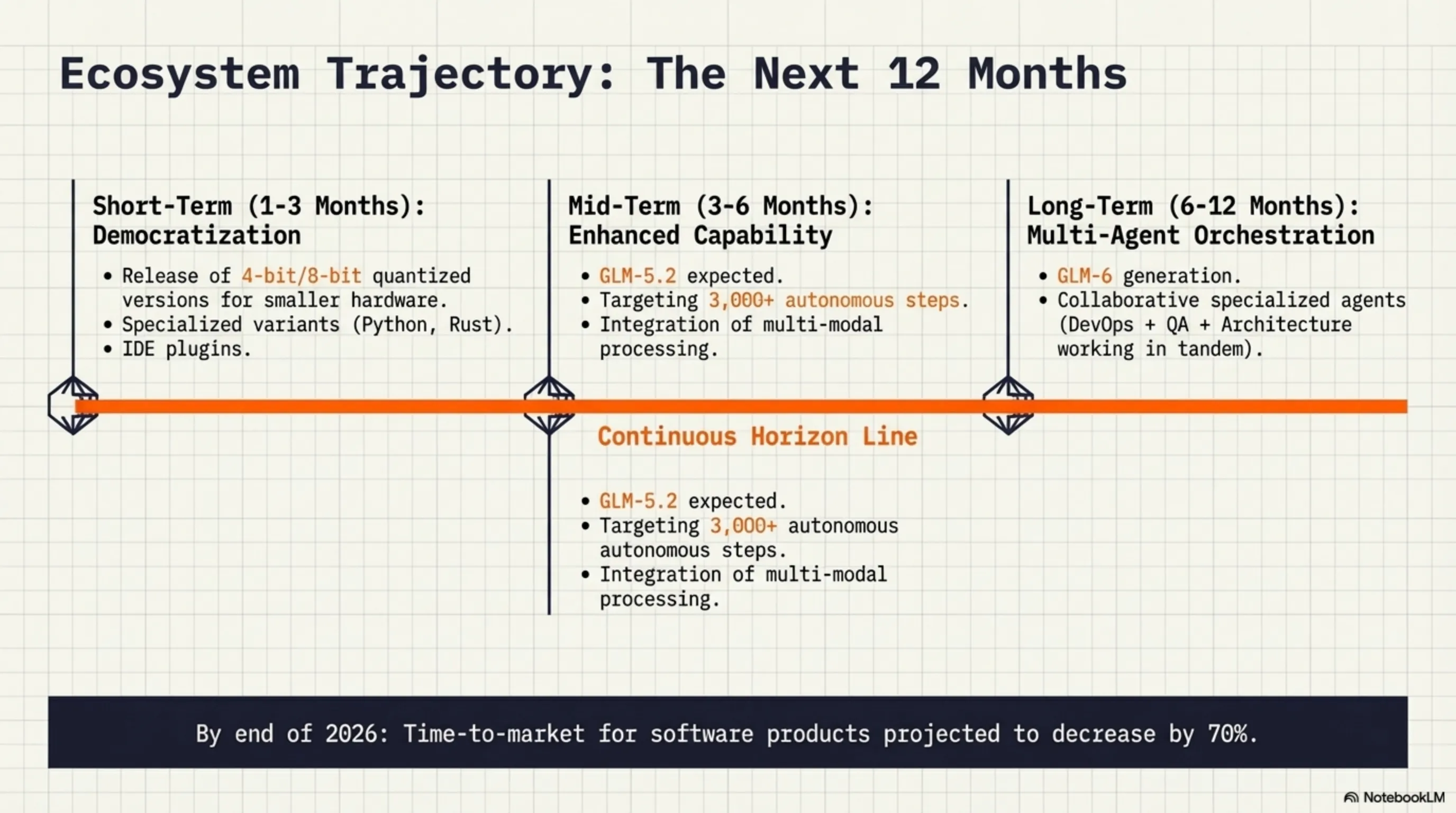
📅 کوتاهمدت (1-3 ماه)
- Quantized versions: نسخههای 4-bit و 8-bit برای hardware کمتر
- Fine-tuned variants: نسخههای specialized برای Python، JavaScript، Rust، و غیره
- Better tooling: ابزارهای بهتر برای deployment و monitoring
- Community plugins: integration با IDEها و development tools
📅 میانمدت (3-6 ماه)
- GLM-5.2: نسخه بهبود یافته با autonomous steps بیشتر (هدف: 3000+)
- Multi-modal support: توانایی کار با تصاویر، ویدیو، و صدا
- Better reasoning: بهبود در mathematical و logical reasoning
- Faster inference: optimizationهای جدید برای سرعت بیشتر
📅 بلندمدت (6-12 ماه)
- GLM-6: نسل بعدی با قابلیتهای بیشتر
- Specialized agents: agentهای تخصصی برای DevOps، Security، Testing، و غیره
- Collaborative agents: چند agent که با هم کار میکنن
- Self-improving agents: agentهایی که از تجربه یاد میگیرن و بهتر میشن
اما فراتر از roadmap Z.ai، چیزی که واقعاً هیجانانگیزه این هست که GLM-5.1 با MIT license منتشر شده. این یعنی هزاران developer و محقق میتونن روش کار کنن، بهبودش بدن، و نسخههای جدید بسازن. این یعنی ما داریم شاهد شروع یک ecosystem هستیم - نه فقط یک مدل.
🔮 پیشبینی تکین
تا پایان 2026، ما پیشبینی میکنیم:
- 50% از startupهای tech از AI agents مثل GLM-5.1 استفاده میکنن
- متوسط تیم development از 10 نفر به 3-4 نفر کاهش پیدا میکنه
- زمان time-to-market برای محصولات جدید 70% کاهش پیدا میکنه
- نقش developer از "کد نویسی" به "معماری و طراحی" تغییر میکنه
این یک تغییر paradigm هست - مثل انتقال از assembly به high-level languages، یا از waterfall به agile. کسایی که زودتر adapt کنن، برنده میشن.
🎯 نتیجهگیری: آیا GLM-5.1 ارزشش رو داره؟
بعد از بررسی کامل GLM-5.1 - از معماری فنی گرفته تا کاربردهای عملی، از بنچمارکها گرفته تا محدودیتها - حالا وقتشه که جواب سوال اصلی رو بدیم: آیا GLM-5.1 ارزشش رو داره؟
جواب کوتاه: بله، قطعاً!
جواب بلند: بستگی داره به use case شما. بیاید ببینیم برای چه کسایی GLM-5.1 مناسبه:
✅ عالی برای:
- Startupها با تیم کوچک که میخوان سریع scale کنن
- شرکتهایی که میخوان هزینه development رو کاهش بدن
- پروژههای open-source که نیاز به contributor زیاد دارن
- Developerهایی که میخوان productivity شون رو 10x کنن
- شرکتهایی که میخوان self-host کنن (برای privacy/security)
❌ شاید مناسب نباشه برای:
- پروژههای خیلی کوچک که APIهای proprietary مقرونبهصرفهترن
- تیمهایی که expertise در deployment مدلهای بزرگ ندارن
- Use caseهایی که نیاز به زبانهای غیر از انگلیسی/چینی دارن
- شرکتهایی که نمیتونن روی hardware سرمایهگذاری کنن
🏆 رأی نهایی تکین
GLM-5.1 یک game changer واقعیه. با توانایی کار مستقل تا 8 ساعت، عملکرد برتر در بنچمارکها، و MIT license کاملاً رایگان، این مدل داره تعریف جدیدی از "AI agent" رو مینویسه. اگه شما یک developer، CTO، یا founder هستید که میخواید جلوتر از رقبا باشید، الان وقتشه که GLM-5.1 رو امتحان کنید.
🚀 آمادهاید شروع کنید؟
GLM-5.1 رو از Hugging Face دانلود کنید و انقلاب رو تجربه کنید:
https://huggingface.co/zai-org/GLM-5
این مقاله در تاریخ 9 آوریل 2026 نوشته شده. برای آخرین اطلاعات، حتماً وبسایت رسمی Z.ai رو چک کنید.
🌐 با ما در ارتباط باشید 🎮✨
برای دریافت آخرین اخبار تکنولوژی، بازیها و گجتها، ما را در شبکههای اجتماعی دنبال کنید:
گالری تصاویر تکمیلی: GLM-5.1: اولین هوش مصنوعی که 8 ساعت متوالی کد مینویسد 🤖