Meta has officially launched an assault on NVIDIA's monopoly by unveiling 4 custom MTIA chips. This "Tekin Analysis" dissects the architecture of these processors, their battle against Google's TPU v7 and NVIDIA's Blackwell, and the strategic shift towards the "Inference Era." Can the entry of new hyperscalers permanently alter the economics and future of artificial intelligence?
🎯 Executive Briefing
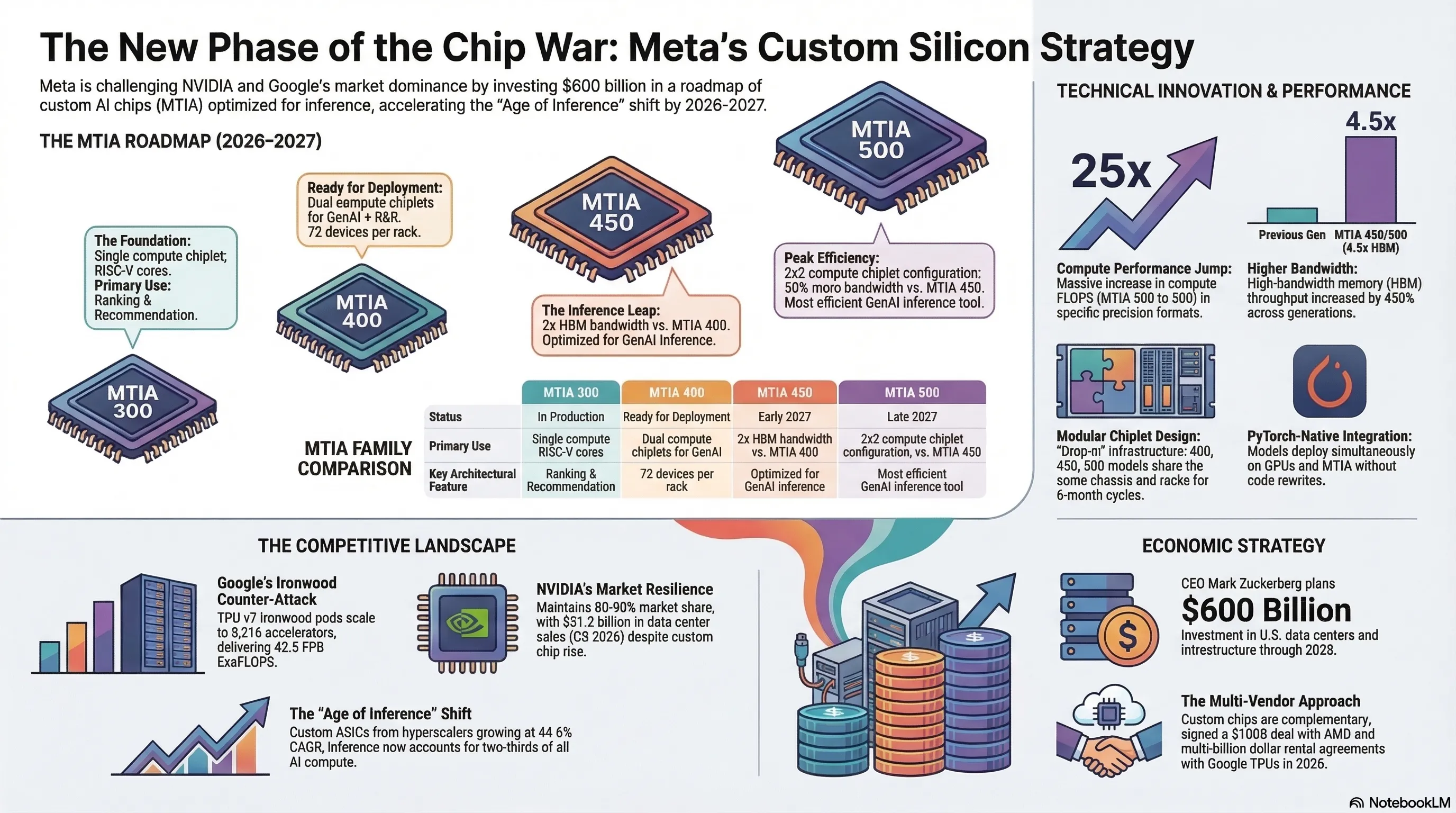
Meta has officially entered the AI chip war with the March 2026 unveiling of four custom MTIA processors. These 300-500 series chips, built in partnership with Broadcom, claim to deliver 25x better performance and 4.5x higher bandwidth compared to the first generation. Meanwhile, Google continues competing with TPU v7 Ironwood and NVIDIA with Blackwell architecture. This chip war, focused on inference optimization, could fundamentally reshape AI economics and challenge NVIDIA's 80-90% market dominance.

Introduction: Dawn of a New Era in the Chip Wars
The semiconductor industry in 2026 is witnessing one of the most significant transformations in its history. Meta, the social media giant, has officially declared war on NVIDIA's monopoly with the unveiling of four custom AI chips. This move, coinciding with Google's remarkable advances in TPU technology, signals entry into a new phase of competition that could determine the future of AI computing.
On March 11, 2026, Meta released comprehensive details about its MTIA (Meta Training and Inference Accelerator) chip family. These processors, comprising models 300, 400, 450, and 500, claim not only to compete with existing commercial products but to outperform them in several key areas.
The announcement represents more than just another product launch—it's a strategic declaration that the era of GPU monopoly is ending. As AI workloads shift from training to inference, and as hyperscalers seek greater control over their silicon destiny, the battle for AI chip supremacy has never been more intense.
MTIA Architecture and Technical Specifications
MTIA 300: Foundation of the Family
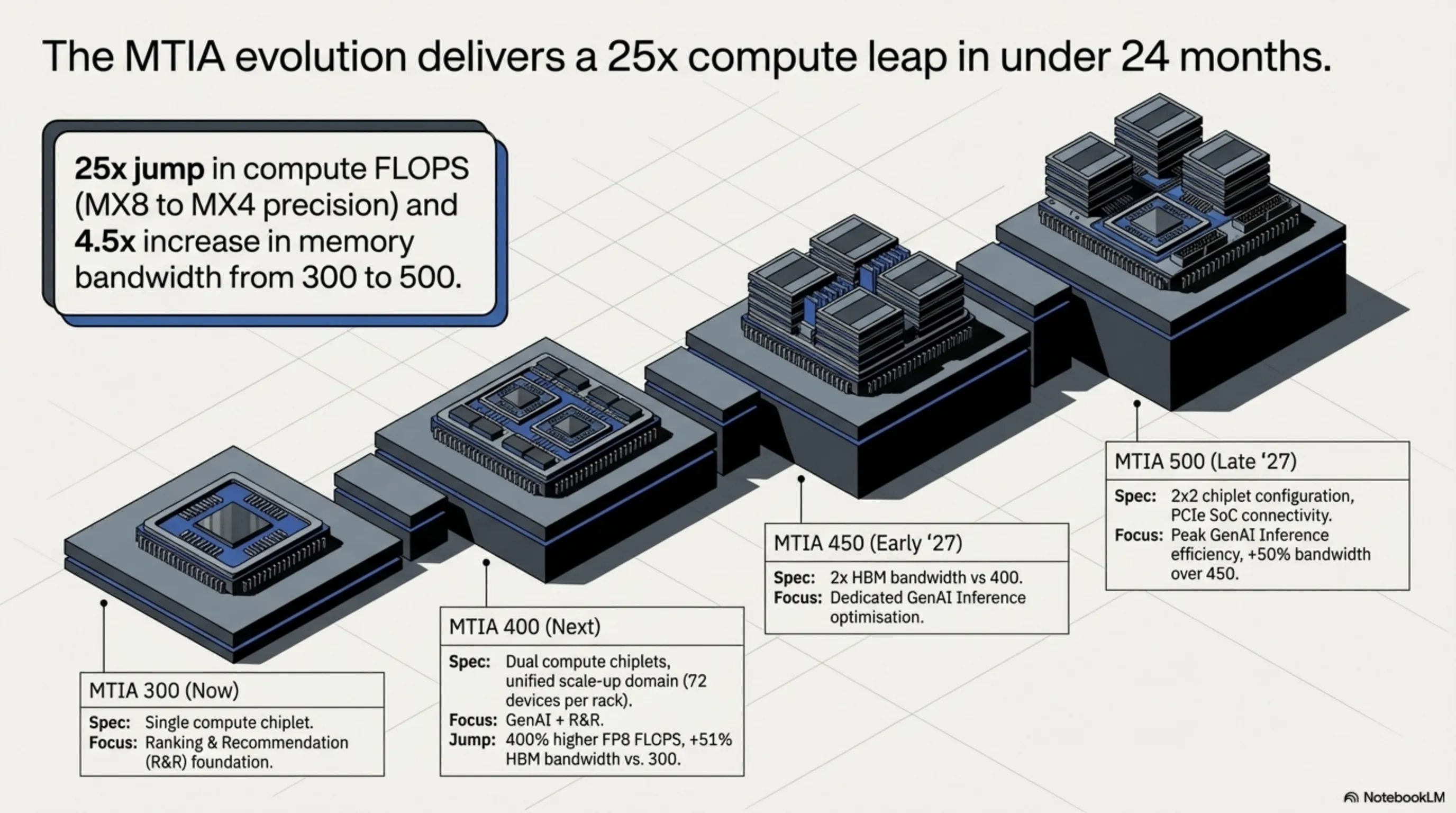
The MTIA 300, currently in mass production, serves as the inaugural representative of Meta's custom chip family. Optimized for ranking and recommendation workloads, this chip comprises one compute chiplet, two network chiplets, and several HBM memory stacks.
Each compute chiplet consists of a grid of processing elements (PEs), with some redundant PEs included to improve manufacturing yield. Each PE contains a pair of RISC-V vector cores, providing advanced processing capabilities that Meta claims are specifically tuned for its social media algorithms.
The chip's architecture reflects Meta's deep understanding of its own workloads. Unlike general-purpose GPUs that must accommodate diverse applications, the MTIA 300 is laser-focused on the specific computational patterns that drive Facebook, Instagram, and WhatsApp's recommendation engines.
MTIA 400: Entering Serious Competition
The MTIA 400, described as the evolution of the MTIA 300, represents Meta's first chip that claims "raw performance competitive with leading commercial products." This processor employs two compute chiplets and supports both generative AI models and R&R workloads.
One of the MTIA 400's standout features is its ability to house 72 devices in a single rack, connected via a switched backplane to form a unified scale-up domain. Meta has announced that following completion of testing phases, this chip is "on the path to deployment in our data centers."
The MTIA 400 delivers 400% higher FP8 FLOPS and 51% higher HBM bandwidth compared to the 300, representing a significant generational leap that positions Meta as a serious contender in the AI accelerator market.
| Model | Status | Primary Use | Key Feature |
|---|---|---|---|
| MTIA 300 | In Production | Ranking & Recommendation | Single compute chiplet |
| MTIA 400 | Ready for deployment | GenAI + R&R | Dual compute chiplets |
| MTIA 450 | Early 2027 | GenAI Inference | 2x HBM bandwidth |
| MTIA 500 | Late 2027 | Efficient GenAI | 50% more bandwidth |
MTIA 450: Inference Optimization
The MTIA 450, scheduled for mass deployment in early 2027, features specific optimizations for GenAI inference. This chip doubles the HBM bandwidth compared to the MTIA 400, with Meta claiming its performance is "much higher than that of existing leading commercial products."
The focus on inference reflects a broader industry shift. As AI models mature and deployment scales, the computational bottleneck has moved from training to serving billions of daily inference requests. The MTIA 450's architecture acknowledges this reality with dedicated optimizations for token generation and real-time response.
MTIA 500: Peak Efficiency
The MTIA 500, positioned as the most efficient GenAI inference chip, increases HBM bandwidth by an additional 50% over the MTIA 450. This processor uses a 2x2 configuration of smaller compute chiplets surrounded by several HBM stacks and two network chiplets.
Additionally, the MTIA 500 includes an SoC chiplet providing PCIe connectivity to the host CPU and scale-out NICs. Meta has announced plans for mass deployment of this chip throughout 2027, representing the culmination of its custom silicon strategy.
Performance Claims and Competitive Analysis
Meta's Performance Assertions
Meta claims that from MTIA 300 to 500, there's a 4.5x increase in high-bandwidth memory throughput and a 25x jump in compute FLOPS when comparing MX8 to MX4 precision formats. These numbers, if validated in production, would represent a remarkable achievement in silicon efficiency.
The company emphasizes that these improvements aren't just theoretical. The MTIA 300 is already running production workloads for ranking and recommendation training, providing real-world validation of the architecture's effectiveness.
Google's Counter: TPU v7 Ironwood
Google's response comes in the form of TPU v7 Ironwood, unveiled in November 2025. Each Ironwood chip delivers 4,614 teraflops of FP8 compute power, supported by 192 gigabytes of HBM3e memory running at 7.3 terabytes per second.
Built on an advanced 5-nanometer process, Ironwood consumes approximately 600 watts—impressive efficiency for its output. Ironwood pods can scale to 9,216 AI accelerators, delivering a total of 42.5 FP8 ExaFLOPS for training and inference, far exceeding NVIDIA's GB300 NVL72 system at 0.36 ExaFLOPS.
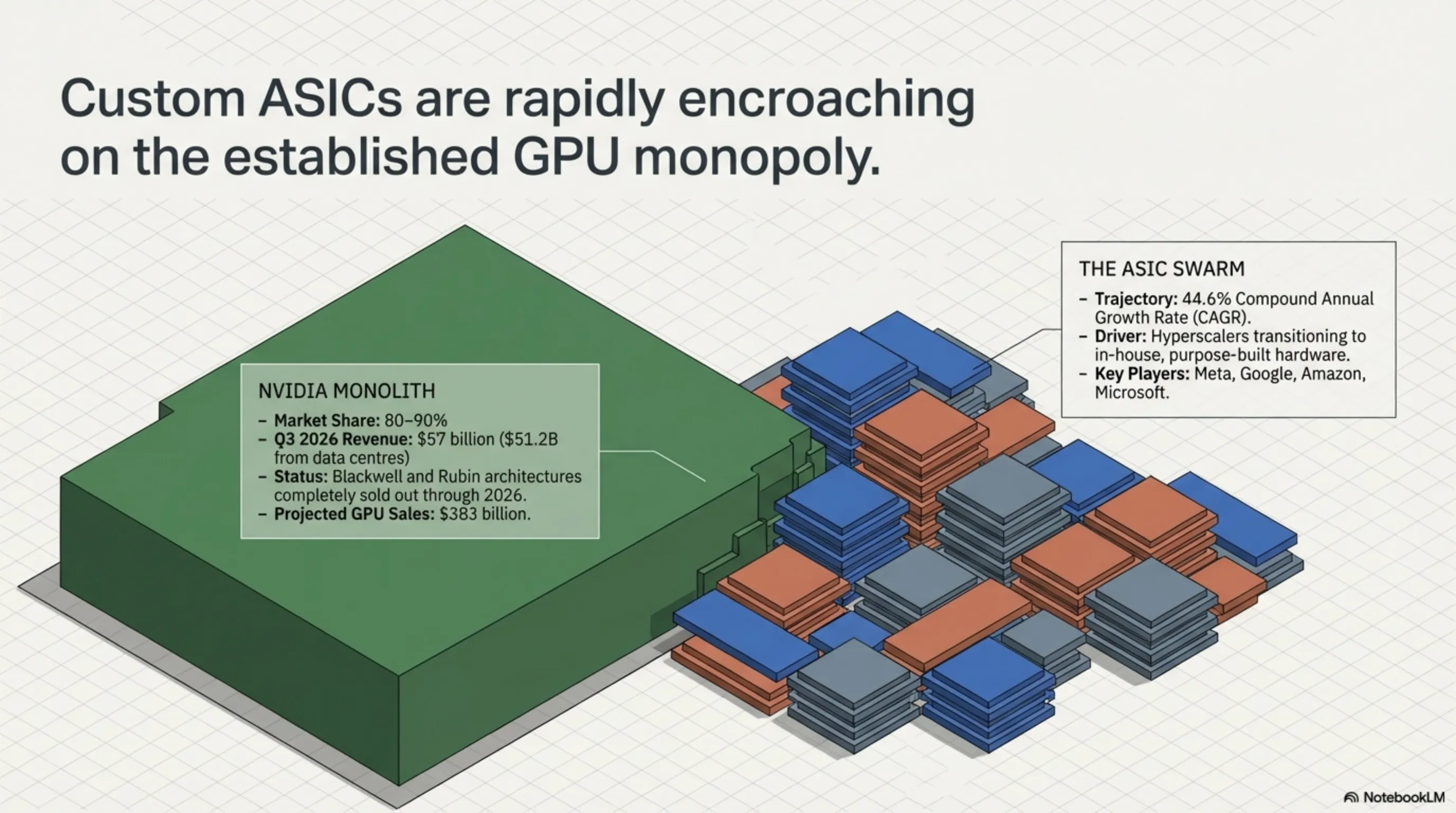
NVIDIA's Market Position
Despite intensifying competition, NVIDIA maintains control of 80-90% of the AI chip market. The company's CUDA ecosystem and Blackwell architecture continue to provide strong competitive advantages. NVIDIA's Q3 2026 revenue reached $57 billion, with $51.2 billion from data center sales.
The company's Blackwell and Rubin chips are sold out through 2026, with projected GPU sales of $383 billion and total revenue of $205 billion. These numbers underscore NVIDIA's continued dominance even as competitors gain ground.
Meta's Strategy: Why Custom Silicon?
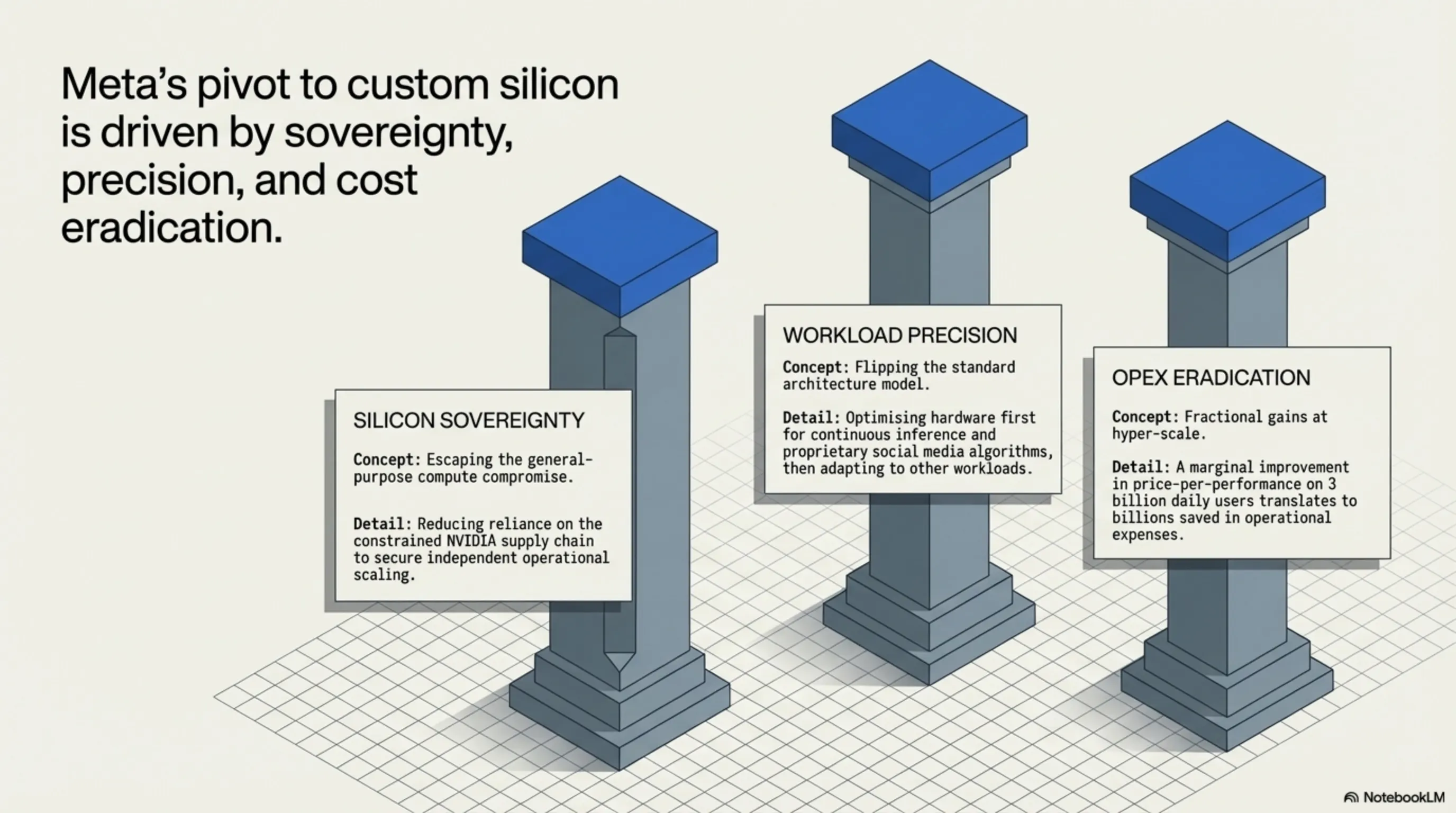
Reducing NVIDIA Dependence
Meta's custom chip development aims to reduce dependence on NVIDIA and gain greater control over its supply chain. This "portfolio diversification" strategy allows the company to reduce operational costs and optimize performance for specific applications.
The approach reflects a broader trend among hyperscalers seeking silicon sovereignty. By controlling their own chip destiny, companies like Meta can optimize for their specific workloads rather than accepting the compromises inherent in general-purpose solutions.
Focus on Inference
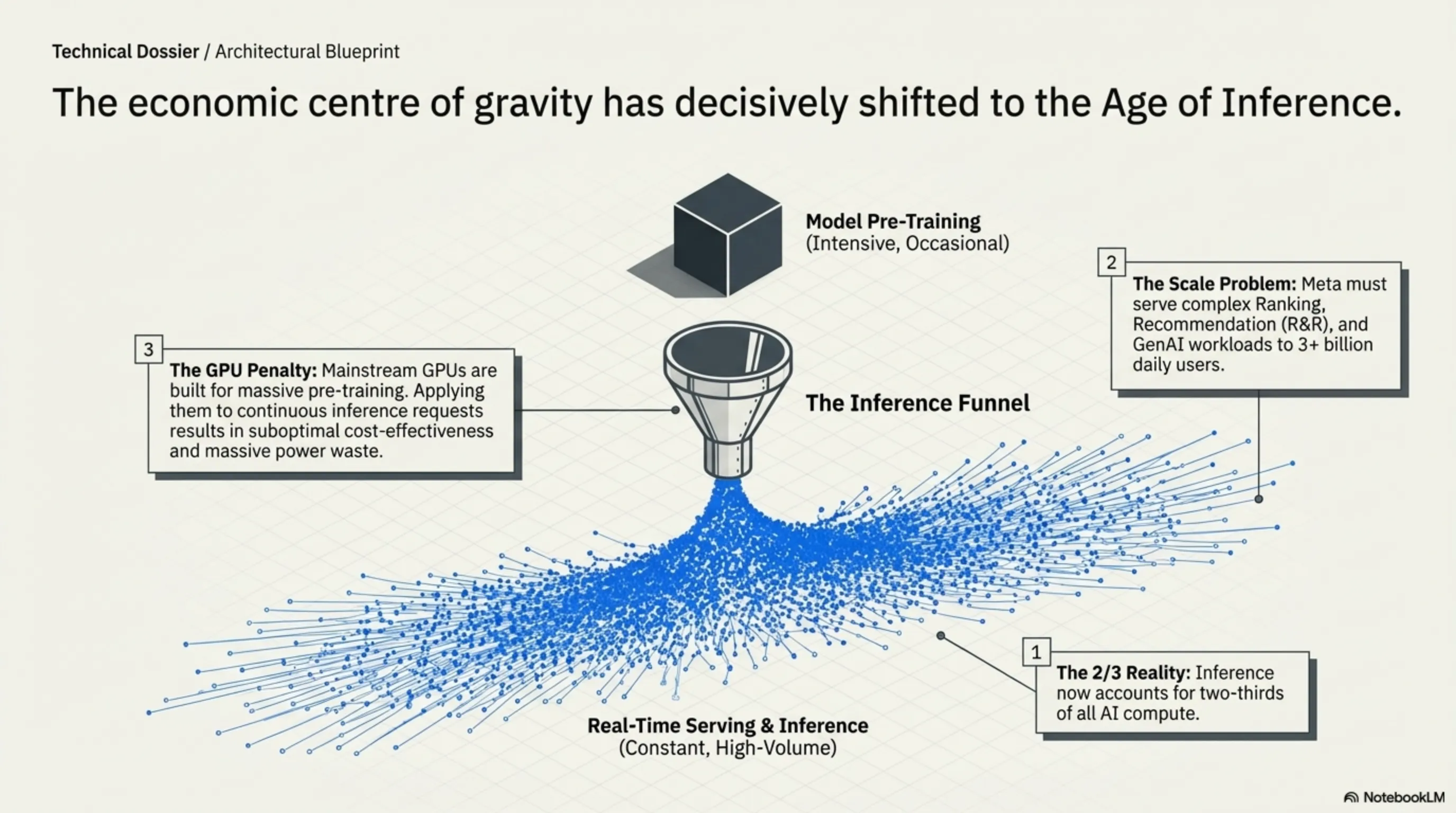
Unlike mainstream GPUs typically built for the most demanding workload—large-scale GenAI pre-training—and then applied, often less cost-effectively, to other workloads, MTIA flips this approach. These chips optimize first for inference, then adapt elsewhere.
This strategy acknowledges that inference workloads now represent two-thirds of all AI compute. As models mature and deployment scales, the economic center of gravity has shifted from training to serving.
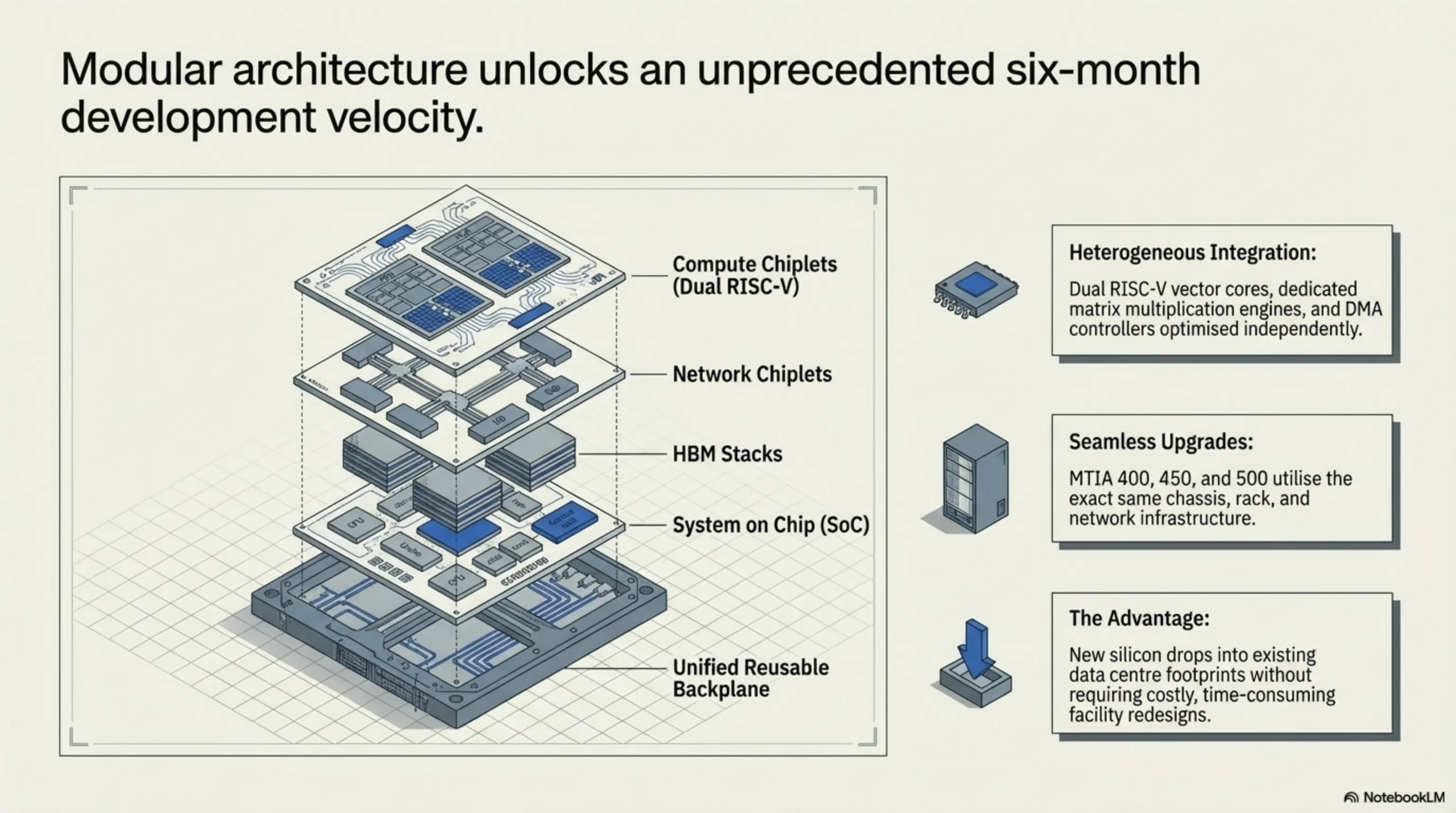
Modular Design Philosophy
The modular chiplet design allows Meta to swap components without complete redesigns. MTIA 400, 450, and 500 all utilize the same chassis, rack, and network infrastructure—new chips drop into existing data center footprints seamlessly.
This approach enables Meta's claimed ability to ship new chips "roughly every six months," a development velocity that could prove crucial in the rapidly evolving AI landscape.

Economic Context and Investment Scale
Meta's Massive Spending
Meta's infrastructure appetite is staggering. CEO Mark Zuckerberg has indicated plans to spend "at least $600 billion" on U.S. data centers and infrastructure through 2028. Capital expenditure projections for 2025 alone range from $60 to $65 billion.
These numbers reflect the scale required to serve AI recommendations for 3+ billion daily users across Meta's platform family. The company's willingness to invest at this scale demonstrates its commitment to maintaining technological leadership.
Cost Optimization Strategy
Custom silicon doesn't replace this spending—it optimizes it. Better price-per-performance on inference workloads could meaningfully impact operating costs when running AI at Meta's unprecedented scale.
The company's engineering team notes that mainstream GPUs often deliver suboptimal cost-effectiveness for specific workloads. Custom silicon allows Meta to escape this compromise, potentially saving billions in operational expenses.
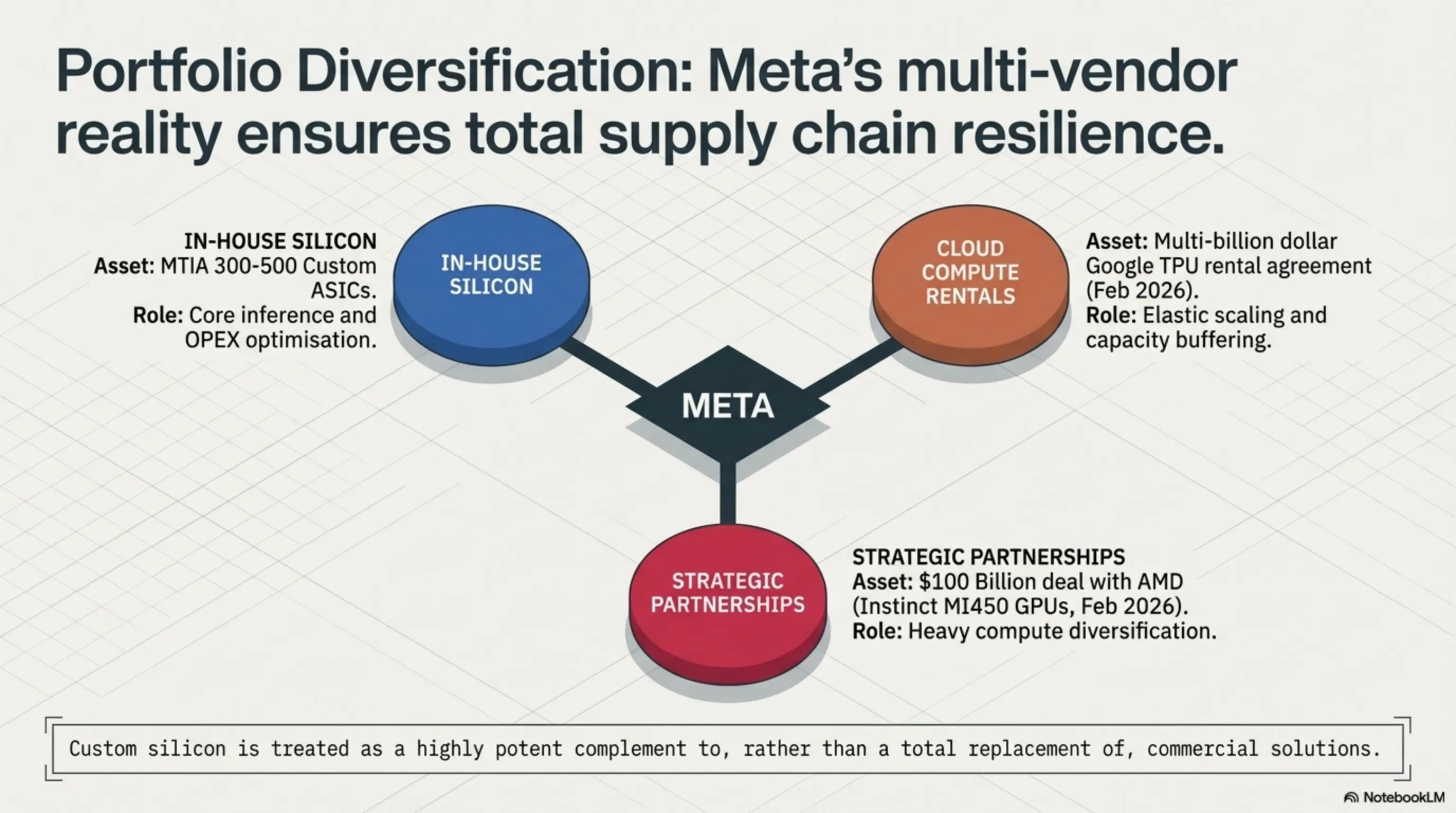
Parallel Partnerships
Interestingly, Meta continues massive partnerships with other suppliers alongside custom chip development. In February 2026, the company signed a $100 billion deal with AMD for custom Instinct MI450 GPUs. Additionally, on February 26, 2026, Meta signed a multi-billion dollar agreement with Google to rent TPUs.
This multi-vendor strategy suggests Meta views custom silicon as complementary to, rather than replacement for, commercial solutions.
Technical Architecture and Innovation
Chiplet Integration
Each MTIA chip combines compute chiplets, network chiplets, and HBM stacks in a carefully orchestrated design. The processing elements contain dual RISC-V vector cores, dedicated engines for matrix multiplication and reductions, plus DMA controllers for memory management.
This heterogeneous approach allows Meta to optimize each component for its specific function, potentially achieving better overall efficiency than monolithic designs.
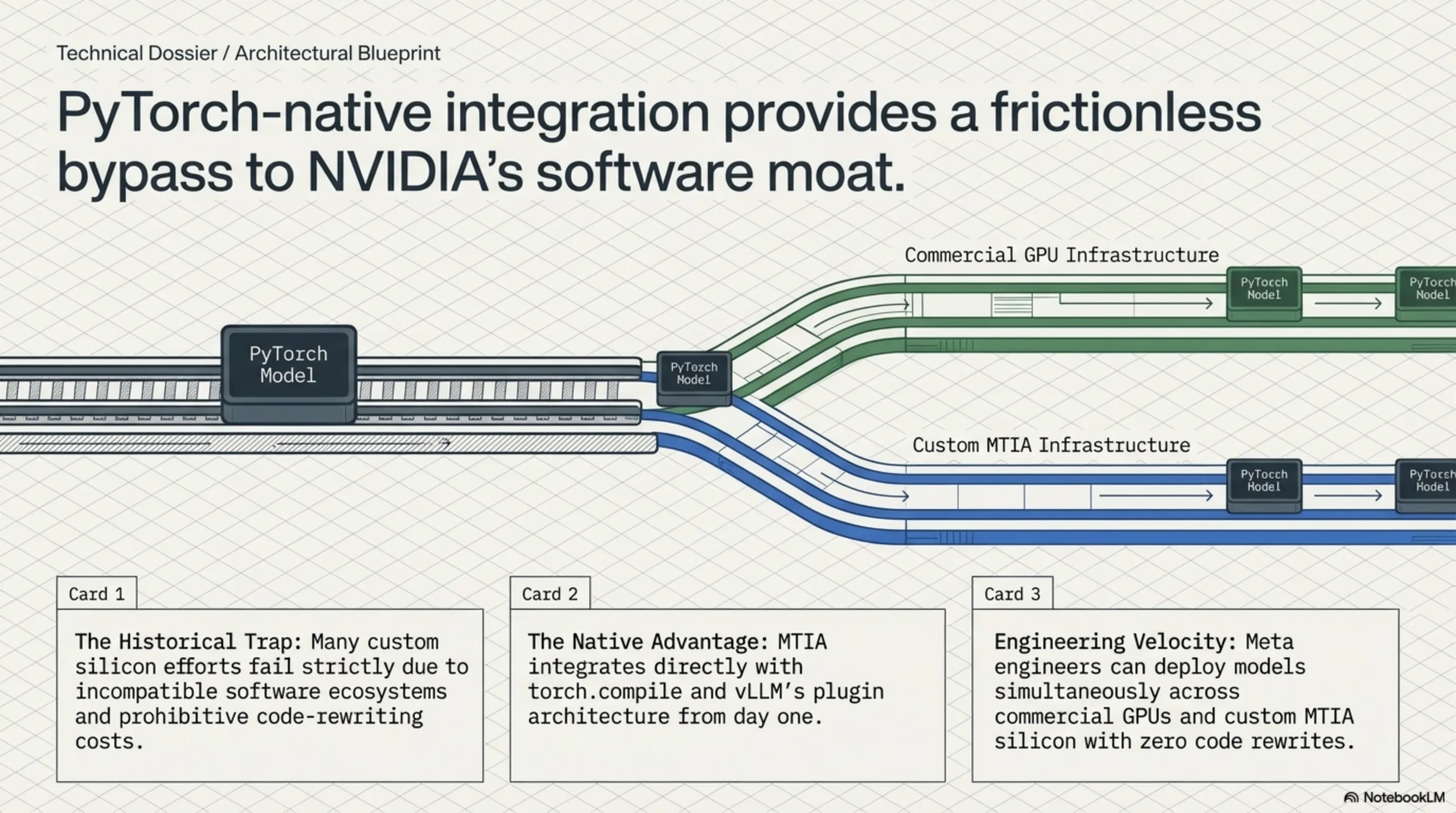
Software Stack Integration
The software stack runs PyTorch-native, integrating with torch.compile and vLLM's plugin architecture. Meta claims models can deploy simultaneously on GPUs and MTIA without rewrites—friction reduction that matters for engineering velocity.
This software compatibility represents a crucial advantage. Many custom chip efforts have failed due to software ecosystem challenges. Meta's PyTorch-native approach suggests the company has learned from these historical failures.
Development Velocity
Meta's claimed ability to ship new chips every six months represents remarkable development velocity. This speed is achieved through reusable and modular design across all levels: chiplets, chassis, racks, and network infrastructure.
Market Response and Competitive Analysis
Market Paradigm Shift
The AI accelerator market in 2026 has split into two diverging trajectories. Custom ASICs from Google (TPU v7 Ironwood), Microsoft (Maia 200), Amazon (Trainium 3), and Meta (MTIA) are growing at 44.6% CAGR, targeting inference workloads that now represent two-thirds of all AI compute.
This shift reflects the maturation of AI from research to production deployment. As workloads become more predictable and specialized, the advantages of custom silicon become more pronounced.
NVIDIA's Challenges
Despite maintaining market share, NVIDIA faces new challenges. Hyperscalers are increasingly moving toward self-reliance in AI hardware. This strategic shift could impact NVIDIA's market share in the long term, particularly in the inference segment.
However, NVIDIA's entrenched infrastructure (NVLink, software ecosystem) ensures ongoing relevance. The company's challenge is maintaining innovation leadership amid rising competition.
Custom ASIC Advantages
Hyperscaler ASICs offer cost efficiency for specific workloads, but NVIDIA's GPUs and CUDA ecosystem remain unmatched for versatility across industries (AI, gaming, robotics, etc.). The market appears to be bifurcating between specialized and general-purpose solutions.
Geopolitical Implications and Tech Wars
U.S.-China Export Restrictions
U.S.-China tech wars and export restrictions are pushing China (via Huawei) to develop domestic alternatives. However, NVIDIA's short-term dominance persists as the AI chip market rapidly expands.
These geopolitical tensions add another dimension to the chip wars, with national security considerations increasingly influencing commercial decisions.
Technological Competition
While hyperscalers carve out market niches, NVIDIA's entrenched infrastructure ensures continued relevance. Long-term leadership depends on innovation amid rising competition from both commercial rivals and nation-state initiatives.
Industry Future and Predictions
Fundamental Transformation
The AI revolution is reshaping the technology landscape at breakneck speed, and nowhere is this more evident than in the semiconductor industry. NVIDIA has long been the undisputed leader in AI hardware, powering everything from cloud computing to autonomous vehicles with cutting-edge GPUs.
However, the emergence of custom silicon from hyperscalers represents a fundamental challenge to this dominance. The question isn't whether NVIDIA will face competition, but how quickly and effectively competitors can scale their alternatives.
The Inference Era
Unlike previous generations primarily designed for training massive models, Ironwood and MTIA are built for the "age of inference"—an era where AI models aren't just being built but actively serving millions of users in real-time daily.
This shift from training to inference optimization represents a new phase in AI development, with different technical requirements and economic considerations.
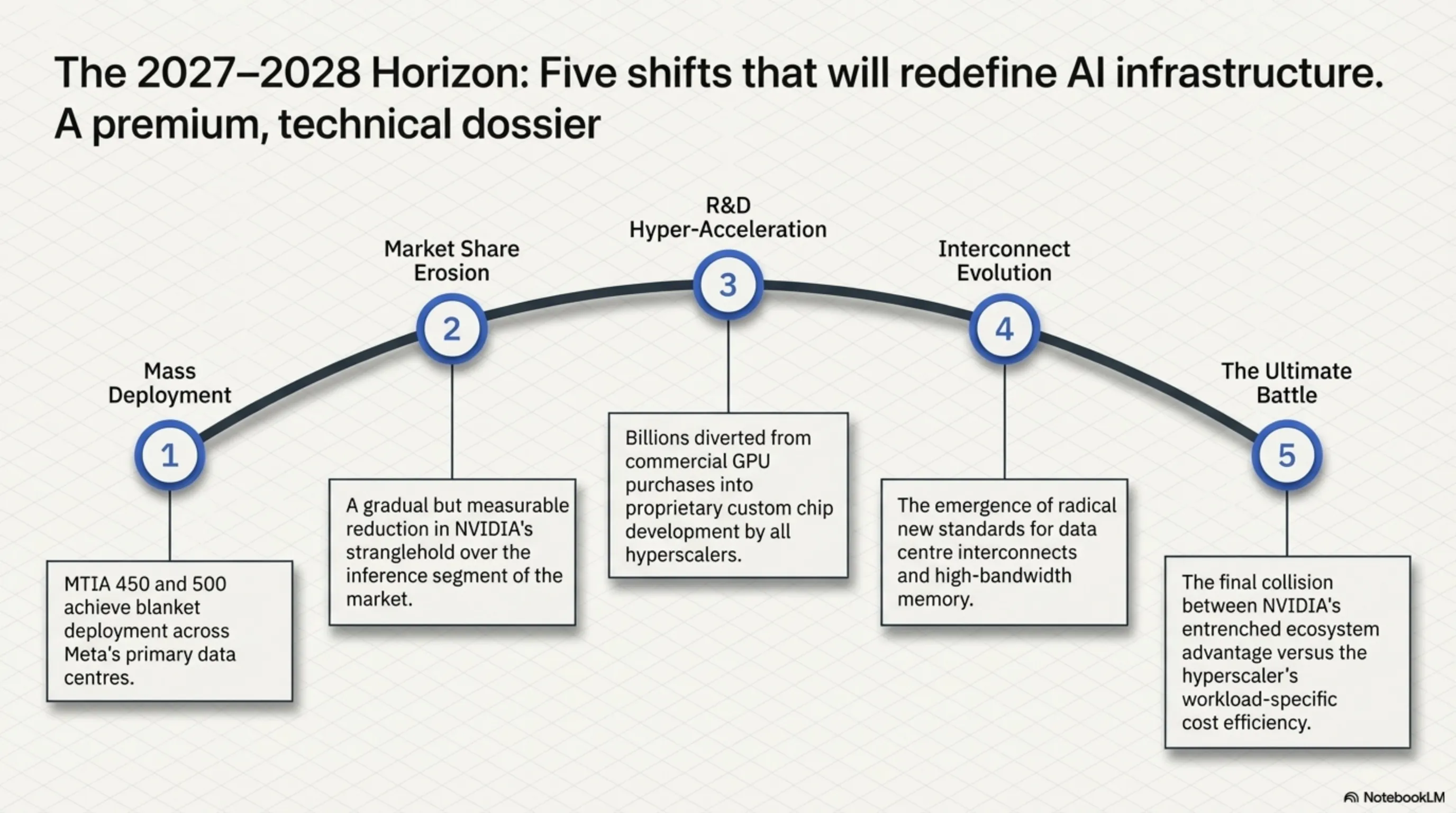
2027-2028 Predictions
- Mass deployment of MTIA 450 and 500 in Meta data centers
- Intensified competition between custom chips and general-purpose GPUs
- Gradual reduction in NVIDIA's inference market share
- Increased R&D investment in custom chip development
- Emergence of new standards for interconnect and memory technologies
The next two years will likely determine whether custom silicon can truly challenge NVIDIA's dominance or whether the GPU giant's ecosystem advantages prove insurmountable.
🎯 Conclusion
The AI chip war has entered a critical phase with Meta's entry into the battlefield. The four MTIA chips represent not just Meta's attempt to reduce NVIDIA dependence, but a fundamental transformation in the semiconductor industry. The competition between Meta, Google, and NVIDIA will ultimately benefit end users through improved performance, reduced costs, and increased innovation. The future belongs to whichever company can best balance performance, energy efficiency, and cost-effectiveness in the rapidly evolving AI landscape.
Final Note: This article is based on independent reports, official information from Meta, Google, NVIDIA, and Broadcom, and industry analysis from credible sources. Information is current as of March 12, 2026. Prices and specifications may vary by region.
🌐 Stay Connected With Us 🎮✨
For the latest tech, gaming, and gadget news, follow us on our official social media channels:
Supplementary Image Gallery: The Chip War Enters a New Phase: Meta Challenges NVIDIA and Google with 4 Custom AI Chips