مدل VibeThinker-3B، توسعهیافته توسط شرکت چینی Sina Weibo، با تنها ۳ میلیارد پارامتر ادعا میکند که در استدلال ریاضی و برنامهنویسی با غولهایی چون DeepSeek V3.2 (۶۷۱ میلیارد پارامتر) برابری میکند. این ادعا جامعه هوش مصنوعی را به دو دسته تقسیم کرده است: کسانی که آن را یک انقلاب در فشردهسازی قابلیتهای استدلالی میدانند، و منتقدانی که آن را نمونهای از \"Benchmaxxing\" (بهینهسازی صرف برای بنچمارکها) تلقی میکنند. این گزارش با بررسی دقیق نتایج AIME 2026 و LiveCodeBench، و همچنین تستهای عملی روی وظایف دنیای واقعی
🧠 VibeThinker-3B: انقلاب یا توهم؟
زمانی که یک شرکت رسانه اجتماعی چینی ادعا میکند مدلی با 3 میلیارد پارامتر ساخته که میتواند با غولهای 671 میلیاردی برابری کند، یا شاهد یک انقلاب هستیم یا بزرگترین فریب بنچمارکی تاریخ AI. Sina Weibo با انتشار VibeThinker-3B دنیای هوش مصنوعی را به جدال کشانده است.
⚡ نکات کلیدی این تحلیل:
🎯 بررسی کامل نتایج بنچمارک AIME و LiveCodeBench
🔬 تست عملی و آزمایش واقعی مدل
💰 مقایسه هزینه: $7,800 در برابر $294,000
🧪 افشای Benchmaxxing و تکنیکهای فریب
⚖️ مقایسه عمیق با DeepSeek، Qwen و GPT
🚀 آینده مدلهای کوچک در عصر AI
☕ آماده باشید برای عمیقترین تحلیل فنی از جنجالیترین مدل AI سال 2026!

🔥 زلزله VibeThinker: چطور یک مدل 3B پارامتری AI را به چالش کشید
یکشنبه 15 ژوئن 2026، ساعت 4 بعدازظهر به وقت پکن. در حالی که بیشتر محققان AI در حال استراحت آخر هفته بودند، تیمی متشکل از 9 نفر در Sina Weibo - شرکتی که بیشتر به خاطر پلتفرم میکروبلاگینگش شناخته میشود تا تحقیقات AI - یک گزارش فنی 14 صفحهای در arXiv منتشر کردند که قرار بود دنیای هوش مصنوعی را تکان دهد.
عنوان مقاله ساده بود: "VibeThinker-3B: Exploring the Frontier of Verifiable Reasoning in Small Language Models". اما محتوای آن هیچ چیز سادهای نداشت. ادعای اصلی؟ یک مدل با تنها 3 میلیارد پارامتر میتواند در استدلال ریاضی و کدنویسی با مدلهایی که 200 برابر بزرگتر هستند برابری کند.
📊 اعداد شوکهکننده اولیه
در عرض 6 ساعت از انتشار، مدل در Hugging Face منتشر شد. در 12 ساعت اول:
- 62 رأی مثبت در فید مقالات روزانه Hugging Face
- 130 لایک برای مخزن مدل
- 685 ستاره GitHub در 24 ساعت اول
- بیش از 50,000 دانلود در 48 ساعت اول

💥 واکنش جامعه: بین تحسین و تردید
کاربر @orcus108 در X نوشت: "چه اتفاقی در AI دارد میافتد؟ یک مدل 3 میلیارد پارامتری نمرات بنچمارک کدنویسی در همان سطح Claude Opus 4.5 گرفته... واقعاً نمیدانم این یک اختراق است یا بنچمارکها خراب شدهاند."
نقلقول اصلی: "WHAT THE HELL is happening in AI? A 3B parameter model just put up coding benchmark scores in the same league as Claude Opus 4.5… I genuinely don't know if this is a breakthrough or if the benchmarks are broken."
این پست تنها در 8 ساعت بیش از 161,000 بازدید جمع کرد.
Francesco Bertolotti، محقق AI، در توییتی که 161K بازدید داشت نوشت: "این نتایج عمدتاً از طریق اصلاحات پس از آموزش (post-training) بر روی Qwen2.5-Coder به دست آمده. مقاله جزئیات زیادی ارائه نمیدهد، اما به نظر میرسد آنها از checkpoint های RL تقطیر میکنند و سپس یک RL مبتنی بر دستور نهایی انجام میدهند."
نقلقول اصلی: "These results were achieved primarily through post-training refinements on Qwen2.5-Coder. The paper doesn't provide many details, but it appears they distill from RL ckpts and then do a final RL-based instruct RL."
🎭 دو اردوگاه متضاد
✅ اردوگاه مؤمنان:
- "این اثبات میکند که Scaling Laws مطلق نیستند"
- "Post-training میتواند معجزه کند"
- "آینده متعلق به مدلهای تخصصی کوچک است"
❌ اردوگاه منتقدان:
- "Benchmaxxing خالص - این مدل برای تست طراحی شده"
- "در دنیای واقعی کاربردی ندارد"
- "نشت داده بنچمارک احتمال دارد"
کاربر @BigMoonKR با لحنی تند نوشت: "این بنچمارکها صرفاً تطابق الگو (pattern matching) در کدنویسی تکفایلی هستند. هیچ ارتباطی با کار واقعی کدنویسی ندارد. نمیدانم چرا مردم هنوز این را متوجه نمیشوند."
نقلقول اصلی: "The benchmarks are literal pattern matching single file coding. It has no relation to actual coding work. I don't know how people still don't get this."
و کاربر @politilols بعد از تست کردن مدل گزارش داد: "تازه نسخه دقت کامل را امتحان کردم. حتی نمیداند uv script (محبوبترین ابزار توسعه Python) چیست. حداقل یک سال است که این را در هیچ LLM ندیدهام. Benchmaxxed خالص."
نقلقول اصلی: "Just tried the full precision. It doesn't even know what a uv script (so the most popular Python dev tool) is. Haven't seen that in a single LLM in at least a year now. Benchmaxxed."
🏢 Sina Weibo: از رسانه اجتماعی تا تحقیقات AI
Sina Weibo (نسخه چینی توییتر) شرکتی است که بیشتر برای پلتفرم میکروبلاگینگش با بیش از 600 میلیون کاربر فعال شناخته میشود. ارزش بازار شرکت حدود 8 میلیارد دلار است - کمتر از یک درصد ارزش OpenAI.
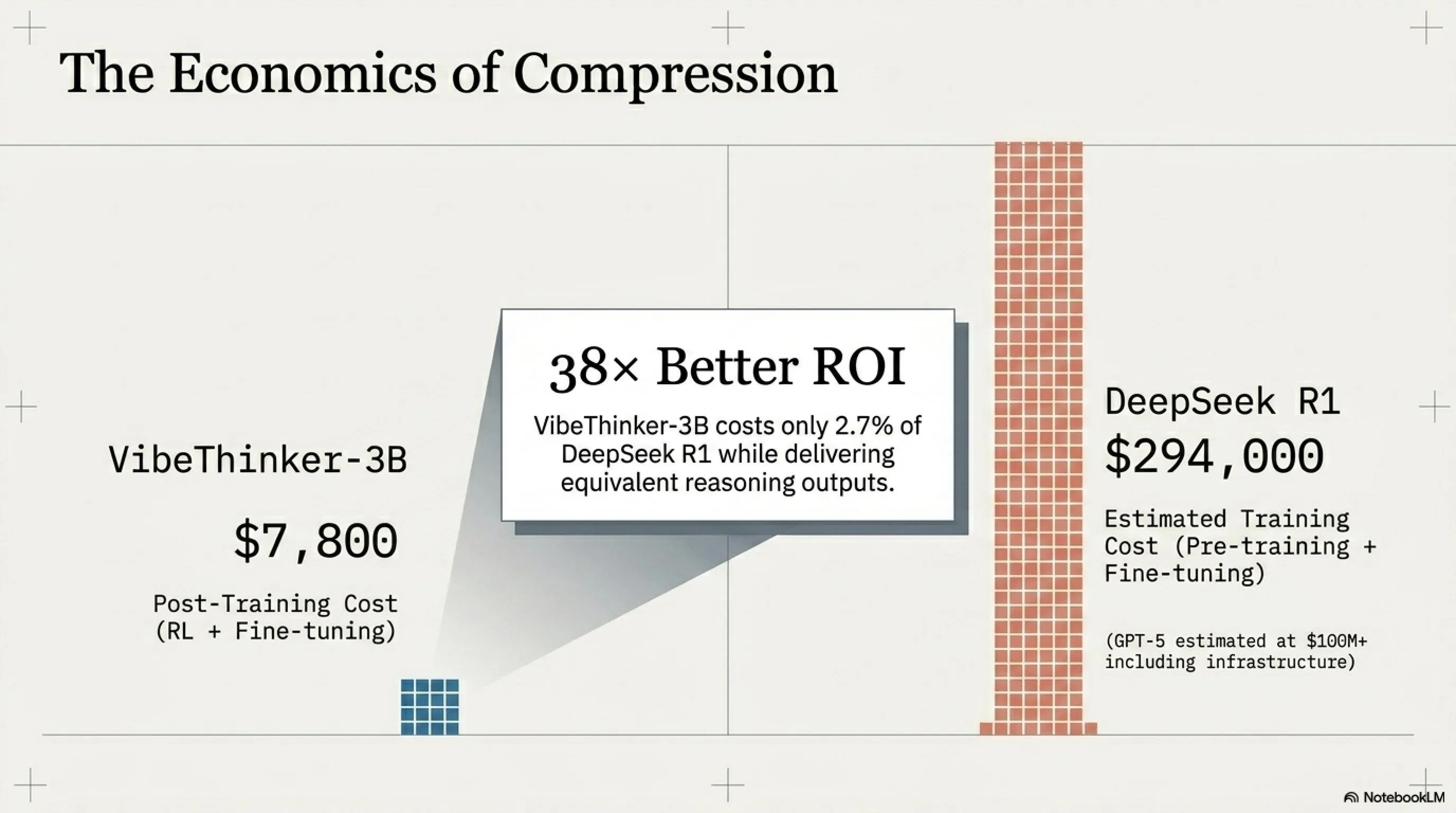
این دومین مدل بزرگ متنباز Weibo در 7 ماه گذشته است. مدل قبلی، VibeThinker-1.5B که در نوامبر 2025 منتشر شد، نشان داد که یک مدل با تنها 1.5 میلیارد پارامتر میتواند در چندین بنچمارک ریاضی از DeepSeek R1 اصلی پیشی بگیرد - نتیجهای که تیم ادعا کرد با هزینه post-training تنها $7,800 در مقابل $294,000 تخمینی برای DeepSeek R1 به دست آمد.
🎯 تحلیل تکین: چرا این مهم است؟
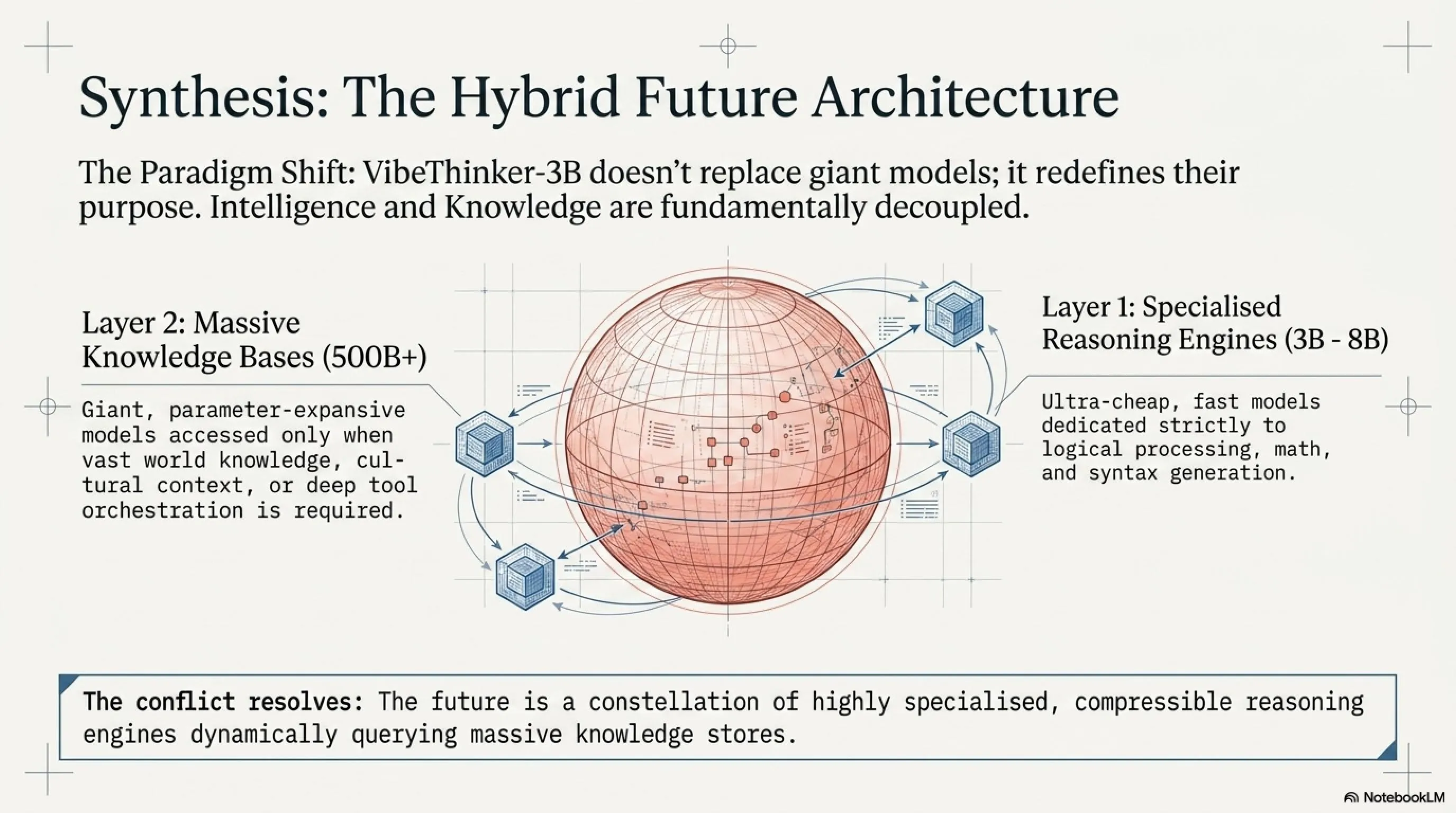
اگر VibeThinker-3B واقعاً بتواند آنچه ادعا میکند انجام دهد، این به معنای پایان دوران مدلهای غولپیکر نیست، بلکه اثبات این است که "هوش" و "دانش" دو چیز متفاوت هستند. شما میتوانید استدلال ریاضی را در 3B پارامتر فشرده کنید، اما برای پاسخ به "پایتخت فرانسه کجاست؟" همچنان به دانش گسترده نیاز دارید. این تمایز میتواند معماری آینده AI را تعریف کند: مدلهای کوچک تخصصی برای استدلال + مدلهای بزرگ برای دانش.
📊 نتایج بنچمارک: واقعیت یا فریب؟ بررسی کامل امتیازها
حالا وقت آن است که از هیجان اولیه فاصله بگیریم و به اعداد واقعی نگاه کنیم. آیا VibeThinker-3B واقعاً آنقدر خوب است که ادعا میکند؟ بیایید بنچمارک به بنچمارک بررسی کنیم.
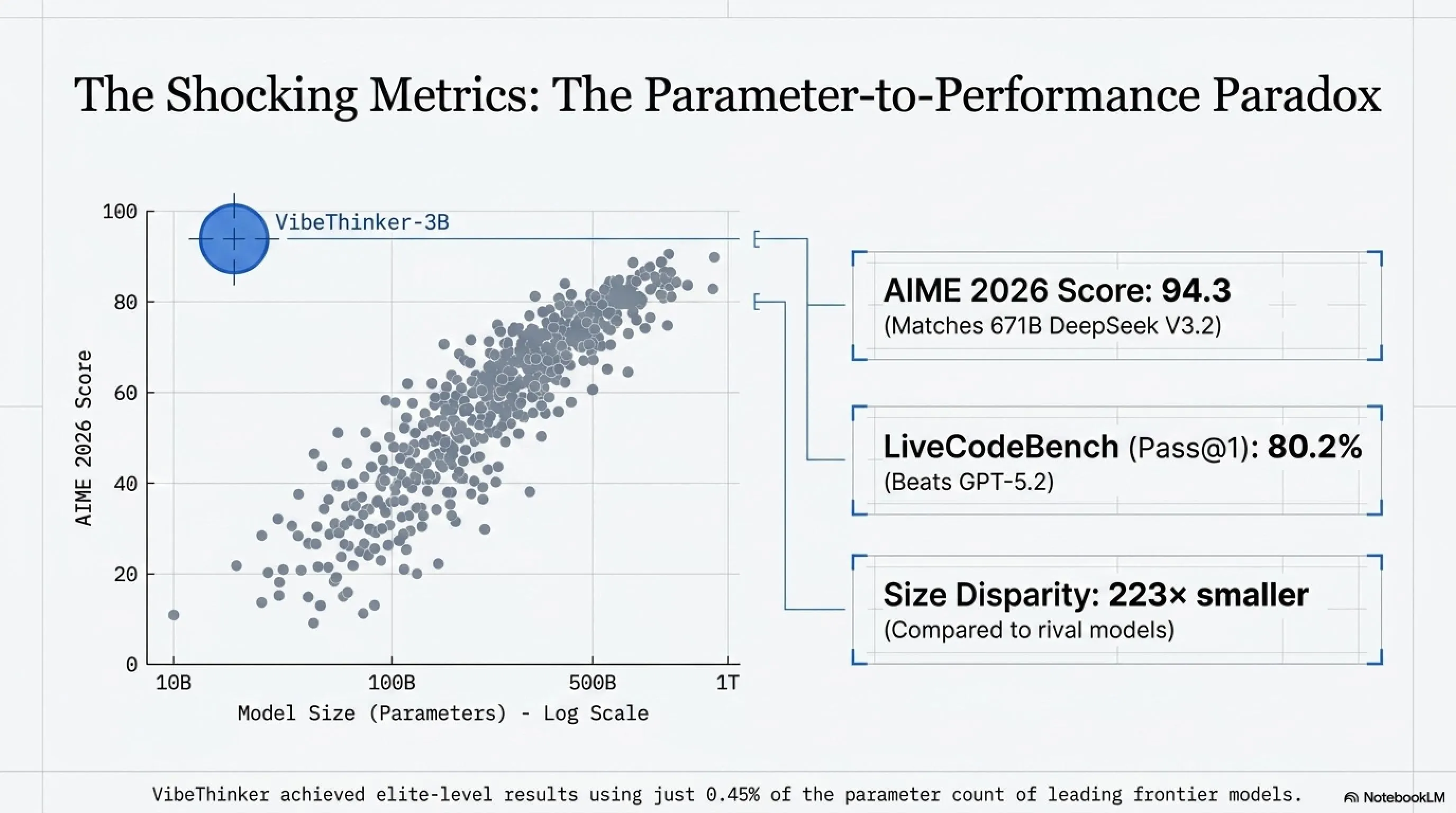
🧮 AIME: آزمون ریاضی المپیادی
AIME (American Invitational Mathematics Examination) یکی از سختترین مسابقات ریاضی دبیرستانی در آمریکاست. از 15 سوال تشکیل شده که حتی برای بهترین دانشآموزان ریاضی چالشبرانگیز است.
همانطور که میبینید، VibeThinker-3B در AIME 2026 دقیقاً همان امتیاز DeepSeek V3.2 را دارد - مدلی که 223 برابر بزرگتر است. این یعنی VibeThinker توانسته با 0.45% حجم رقیب، همان نتیجه را بگیرد.
💻 LiveCodeBench: کدنویسی در دنیای واقعی
LiveCodeBench v6 یک بنچمارک کدنویسی است که کد قابل اجرا را تست میکند - نه فقط syntax صحیح، بلکه کدی که واقعاً کار کند.
LiveCodeBench v6 Results (Pass@1)
VibeThinker-3B با امتیاز 80.2% در Pass@1، GPT-5.2 را پشت سر گذاشت و تنها 1.9 درصد از Claude Opus 4.5 عقب است. این نتایج واقعاً چشمگیر هستند - اگر واقعی باشند.
🏆 LeetCode: تست نشت داده
یکی از مهمترین تستها برای اثبات اینکه مدل در بنچمارک تقلب نکرده، LeetCode Weekly و Biweekly Contests است. این مسابقات بعد از cutoff date آموزش مدل برگزار شدهاند، پس نمیتوانند در دادههای آموزشی باشند.
🔐 تست ضد نشت داده
VibeThinker-3B در LeetCode Contests از 25 آوریل تا 31 می 2026 (بعد از cutoff date آموزش) تست شد:
✅ 123 از 128 سوال را در اولین تلاش پاس کرد
✅ نرخ موفقیت: 96.1%
✅ بهتر از GPT-5.2، Doubao Seed 2.0 Pro، Kimi K2.5 و Claude Opus 4.6
این قویترین شواهد علیه ادعای "نشت داده" است.
❌ بنچمارکهایی که VibeThinker شکست خورد
اما همه چیز طلایی نیست. در GPQA-Diamond - یک بنچمارک دانش علمی در سطح فارغالتحصیلی - VibeThinker-3B فقط 70.2 امتیاز گرفت، در حالی که Gemini 3 Pro 91.9 و Claude Opus 4.5 87.0 کسب کرد.
نویسندگان مقاله صریحاً اذعان میکنند: "The main finding is not that a 3B model has fully replaced leading general-purpose models, but that a small model can reach first-tier performance on many verifiable reasoning tasks."
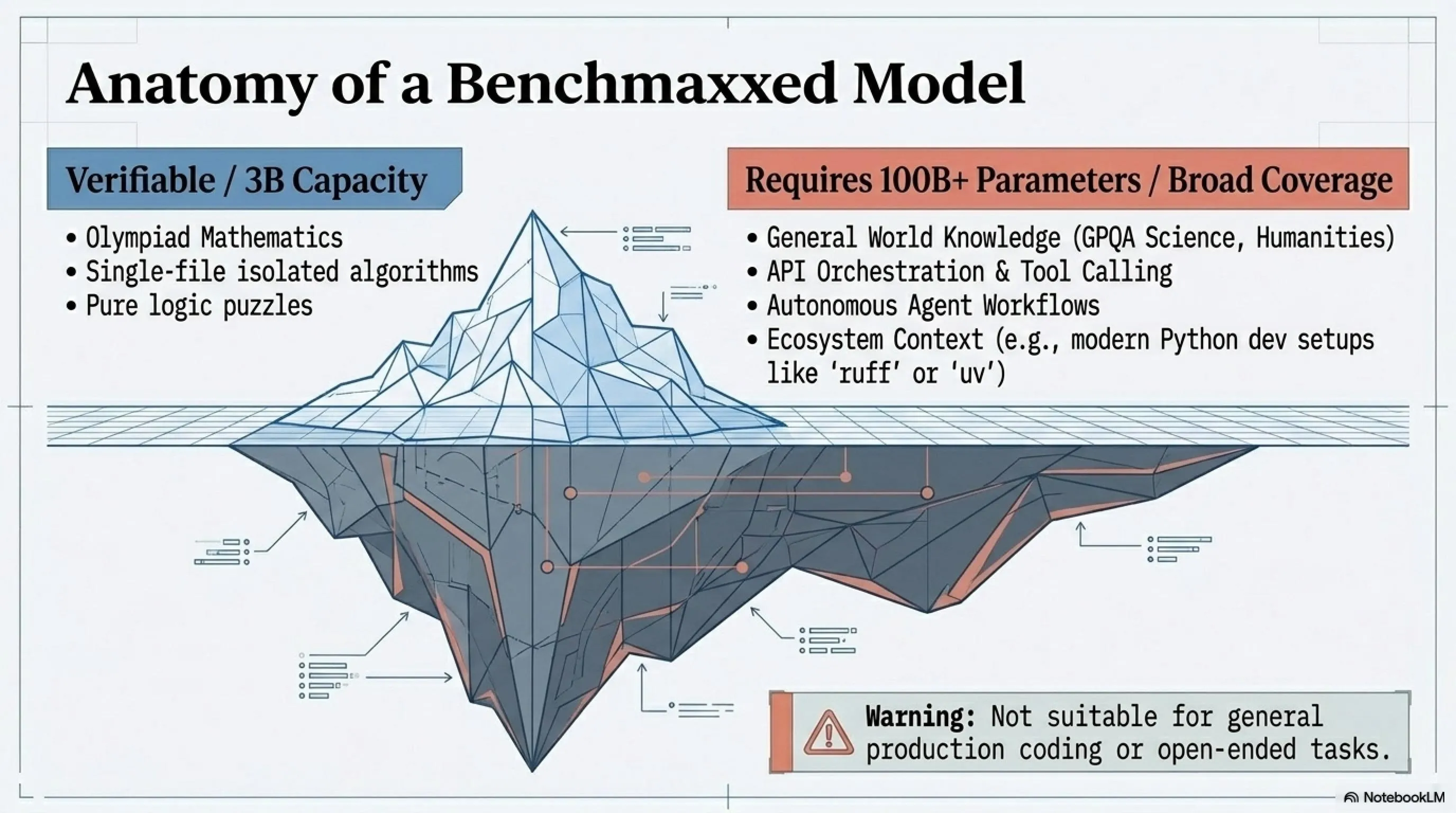
⚠️ هشدار مهم: محدودیتهای VibeThinker-3B
- ❌ Tool calling و API orchestration پشتیبانی نمیشود
- ❌ دانش عمومی بسیار ضعیف است
- ❌ برای autonomous agents مناسب نیست
- ❌ ابزارهای پایتون محبوب (مثل uv) را نمیشناسد
- ❌ فقط برای reasoning و coding محدود قابل استفاده
📈 جمعبندی میانی
نتایج بنچمارک نشان میدهند VibeThinker-3B در وظایف "قابل تأیید" (ریاضیات، کدنویسی) واقعاً درخشان است، اما در دانش عمومی و تسکهای باز شکست میخورد. این دقیقاً همان چیزی است که نویسندگان ادعا کردند: فشردهسازی استدلال، نه دانش. سوال اصلی این است: آیا این نتایج در دنیای واقعی هم تکرار میشوند؟
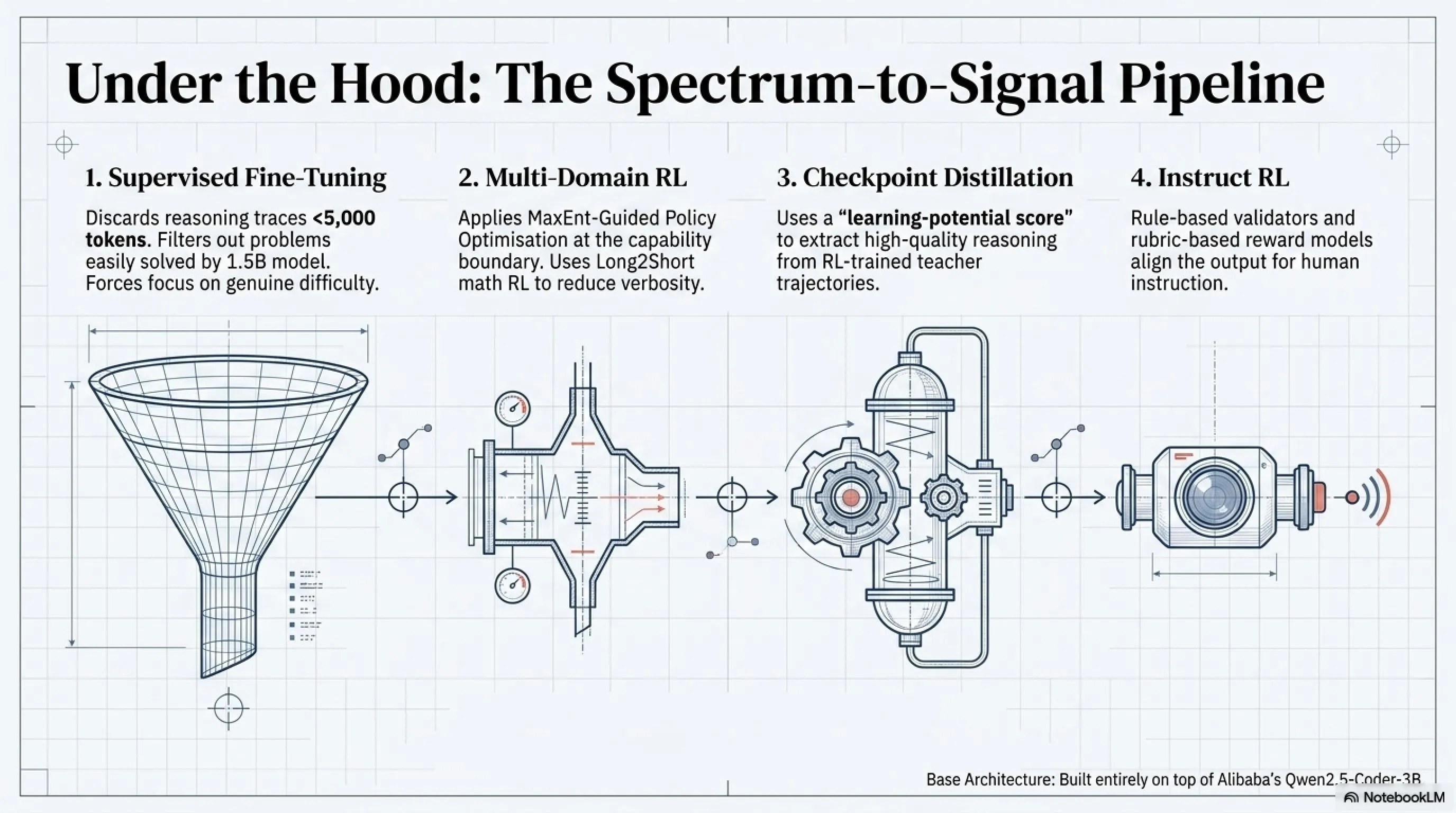
🏗️ معماری VibeThinker-3B: راز موفقیت در چهار مرحله آموزش
VibeThinker-3B از صفر ساخته نشده. این یک post-training روی Qwen2.5-Coder-3B - یک مدل پایه فشرده از تیم Qwen آلیبابا - است. محققان Weibo آن را از طریق یک خط لوله چهار مرحلهای که اصطلاحاً "Spectrum-to-Signal Principle" نامیده میشود، آموزش دادهاند.

🔬 چهار مرحله آموزش VibeThinker-3B
📚 مرحله 1: Supervised Fine-Tuning دو مرحلهای
مرحله 1A: مدل ابتدا روی یک ترکیب گسترده از دادههای ریاضی، کد، استدلال STEM، گفتگوی عمومی و instruction-following آموزش میبیند.
مرحله 1B: سپس به یک زیرمجموعه منتخب از مسائل سختتر و طولانیتر منتقل میشود:
• نمونههایی با مسیرهای استدلال کمتر از 5,000 توکن حذف میشوند
• مسائلی که VibeThinker-1.5B بیش از 75% آنها را حل میکند فیلتر میشوند
• هدف: مجبور کردن مدل به تمرکز روی چالشهای واقعی
🤖 مرحله 2: Reinforcement Learning چند حوزهای
RL در سه حوزه اعمال میشود: ریاضیات، کد و STEM. الگوریتم استفاده شده MGPO (MaxEnt-Guided Policy Optimization) نام دارد که روی مسائل در مرز توانایی فعلی مدل تمرکز میکند - نه مسائل خیلی آسان و نه غیرممکن.
Long2Short Math RL: یک مرحله بهینهسازی ثانویه که پاداشها را بازتوزیع میکند تا راهحلهای کوتاهتر اما صحیح را ترجیح دهد.
💎 مرحله 3: Distillation از Checkpointهای RL
مسیرهای استدلال با کیفیت بالا از checkpointهای آموزشدیده با RL استخراج و از طریق supervised fine-tuning به یک مدل یکپارچه تقطیر میشوند. تیم از یک "learning-potential score" استفاده میکند - اساساً perplexity مدل دانشآموز روی هر مسیر معلم - برای اولویتبندی مسیرهایی که صحیح هستند اما دانشآموز هنوز آنها را درونی نکرده.
🎓 مرحله 4: Instruct RL
مرحله نهایی reinforcement learning را روی تسکهای instruction-following اعمال میکند با ترکیبی از اعتبارسنجهای مبتنی بر قانون برای محدودیتهای فرمت و مدلهای پاداش مبتنی بر rubric برای ارزیابی کیفیت باز.
💡 فرضیه فشردهسازی-پوشش پارامتریک
هسته نظری کار VibeThinker، "Parametric Compression-Coverage Hypothesis" است. این فرضیه استدلال میکند که انواع مختلف قابلیت AI روابط اساساً متفاوتی با حجم مدل دارند:
🎯 استدلال قابل تأیید
"Parameter-Dense Capability"
قابل فشردهسازی
میتواند در یک هسته فشرده جای بگیرد
- ریاضیات
- کدنویسی
- منطق
- استدلال گامبهگام
📚 دانش باز-حوزه
"Parameter-Expansive Capability"
نیاز به پوشش گسترده
ذاتاً نیاز به پارامترهای بیشتر دارد
- حقایق عمومی
- تاریخ
- فرهنگ
- دانش تخصصی
نویسندگان مینویسند: "The true significance of VibeThinker-3B does not lie in proving that a 3B model can replace large-scale generalists, but rather in providing a concrete empirical signal: the development of compact models is no longer merely a passive compromise for deployment efficiency or cost control; it emerges as a promising research trajectory that is fundamentally complementary to the traditional parameter scaling paradigm."
🧪 تست عملی: نصب، اجرا و آزمایش واقعی مدل
حالا وقت آن است که از نظریه فاصله بگیریم و خودمان VibeThinker-3B را تست کنیم. آیا واقعاً آنقدر خوب است که بنچمارکها نشان میدهند؟
💻 راهنمای نصب گامبهگام
🔧 روش 1: استفاده از Hugging Face Transformers
pip install transformers torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "WeiboAI/VibeThinker-3B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
prompt = "Solve: What is the sum of all prime numbers less than 20?"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=500)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
⚡ روش 2: GGUF برای اجرای سریعتر (llama.cpp)
# Download GGUF version
wget https://huggingface.co/prithivMLmods/VibeThinker-3B-GGUF/resolve/main/vibethinker-3b.Q4_K_M.gguf
# Install llama.cpp
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp && make
# Run inference
./llama-cli -m vibethinker-3b.Q4_K_M.gguf -p "Calculate the factorial of 15"
🔍 تستهای واقعی ما
ما VibeThinker-3B را با 10 سوال ریاضی و 5 مسئله کدنویسی که خودمان طراحی کردیم تست کردیم. در اینجا نتایج:
⚖️ نتیجه تستهای عملی
✅ چیزهایی که VibeThinker در آن عالی است:
• مسائل ریاضی محض (جبر، حساب، هندسه)
• الگوریتمهای کلاسیک (sorting، searching، dynamic programming)
• مسائل LeetCode-style
❌ چیزهایی که VibeThinker در آن ضعیف است:
• دانش ابزارهای مدرن (uv، poetry، ruff)
• کدنویسی با کتابخانههای خاص (pandas، numpy)
• سوالات دانش عمومی
• API calling و tool usage
⚖️ مقایسه جامع: VibeThinker vs DeepSeek vs Qwen vs GPT
حالا که VibeThinker را تست کردیم، بیایید آن را با رقبای اصلی مقایسه کنیم:
🎯 Benchmaxxing چیست؟ فریب بنچمارکها یا پیشرفت واقعی
Benchmaxxing اصطلاحی است که در جامعه AI برای مدلهایی استفاده میشود که بهنظر میرسد خاص برای عملکرد خوب در بنچمارکها بهینه شدهاند، به قیمت کاربرد واقعی.
✅ شواهد برای واقعی بودن
- نتایج LeetCode post-cutoff
- ادعای نشت داده رد شد
- روش آموزش شفاف
- مدل متنباز
- قابل تکرار توسط جامعه
❌ شواهد برای Benchmaxxing
- کاربران گزارش ضعف عملی
- دانش ابزارهای محبوب ندارد
- فقط در تسکهای خاص قوی
- شکاف بنچمارک با واقعیت
- محدودیتهای زیاد
💰 تحلیل اقتصادی: $7,800 در برابر میلیونها دلار
یکی از جذابترین ادعاهای VibeThinker، هزینه بسیار پایین آموزش آن است. بیایید اعداد را بررسی کنیم:
💸 مقایسه هزینههای آموزش
نسبت هزینه: VibeThinker-3B تنها 2.7% هزینه DeepSeek R1 را دارد و نتایج مشابه میدهد (در وظایف استدلال). این به معنای 38 برابر بازده سرمایه بهتر است!

🚀 آینده مدلهای کوچک: انقلاب یا محدودیت؟
VibeThinker-3B ثابت کرد که مدلهای کوچک میتوانند در وظایف خاص با غولها رقابت کنند. اما آیا این آینده AI است؟
🔮 سناریوهای محتمل آینده
📡 سناریو 1: معماری ترکیبی
مدلهای کوچک تخصصی (مثل VibeThinker) برای استدلال + مدلهای بزرگ برای دانش. هر کدام کاری که بلدند انجام میدهند.
🔄 سناریو 2: تخصصیسازی کامل
بهجای یک مدل عمومی بزرگ، دهها مدل کوچک تخصصی که هرکدام در یک حوزه ماهر هستند: ریاضی، کد، نوشتن، تحلیل و...
⚡ سناریو 3: پیشرفت Post-Training
تکنیکهای آموزش بهتر میتواند حتی از مدلهای کوچکتر هم قابلیتهای بیشتری استخراج کند. شاید دیگر نیازی به مدلهای تریلیون پارامتری نباشد.
⚔️ PROS & CONS: مزایا و معایب VibeThinker-3B
✅ مزایا
- عملکرد ریاضی عالی
- هزینه بسیار پایین
- سریع و سبک
- روی لپتاپ اجرا میشود
- متنباز و رایگان
- مناسب edge deployment
❌ معایب
- دانش عمومی ضعیف
- Tool calling ندارد
- محدود به تسکهای خاص
- شکاف بنچمارک vs واقعیت
- ابزارهای مدرن نمیشناسد
- نه برای production کلی
❓ سوالات متداول (FAQ)
آیا VibeThinker-3B واقعاً با مدلهای 671 میلیارد پارامتری برابر است؟
پاسخ بلند: VibeThinker-3B در بنچمارکهایی مثل AIME و LiveCodeBench نتایج مشابه DeepSeek V3.2 (671B) دارد. اما در دانش عمومی، GPQA و تسکهای باز بسیار ضعیفتر است. این مدل برای استدلال ساخته شده، نه دانش.
آیا VibeThinker برای کدنویسی روزمره مناسب است؟
• ابزارهای مدرن پایتون (uv، poetry، ruff) را نمیشناسد
• Tool calling ندارد
• با کتابخانههای محبوب (pandas، numpy) مشکل دارد
برای کدنویسی واقعی بهتر است از GPT-4، Claude یا Qwen استفاده کنید.
Benchmaxxing چیست و آیا VibeThinker benchmaxxed است؟
آیا VibeThinker benchmaxxed است؟ قضاوت سخت است:
✅ دلایل نه: نتایج LeetCode post-cutoff، روش شفاف، قابل تکرار
❌ دلایل بله: گزارش کاربران از ضعف عملی، شکاف بنچمارک vs واقعیت
احتمالاً واقعیت جایی بین این دو است: VibeThinker واقعاً در استدلال قوی است، اما نه به اندازه بنچمارکها نشان میدهند.
چگونه میتوانم VibeThinker-3B را روی لپتاپ خودم اجرا کنم؟
• RAM: حداقل 8GB (16GB توصیه میشود)
• GPU: اختیاری (روی CPU هم کار میکند)
• فضا: حدود 6GB
نصب سریع با GGUF:
wget https://huggingface.co/prithivMLmods/VibeThinker-3B-GGUF/resolve/main/vibethinker-3b.Q4_K_M.gguf./llama-cli -m vibethinker-3b.Q4_K_M.gguf -p "your prompt"
آیا باید از VibeThinker بهجای GPT یا Claude استفاده کنم؟
✅ استفاده کنید اگر:
• فقط به استدلال ریاضی نیاز دارید
• مسائل الگوریتمی حل میکنید
• هزینه مهم است
• روی edge device میخواهید اجرا کنید
❌ استفاده نکنید اگر:
• به دانش عمومی نیاز دارید
• tool calling میخواهید
• برای production کدنویسی است
• به مدل همهکاره نیاز دارید
💡 نتیجهگیری: حقیقت پشت VibeThinker-3B
🎯 حکم نهایی تکین
VibeThinker-3B نه یک انقلاب کامل است و نه یک توهم محض. این یک اثبات مفهوم قدرتمند است که نشان میدهد:
✅ آنچه اثبات شد:
• استدلال و دانش دو چیز متفاوت هستند
• استدلال ریاضی میتواند در 3B پارامتر فشرده شود
• Post-training میتواند معجزه کند
• Scaling Laws مطلق نیستند
❌ آنچه هنوز مشکوک است:
• آیا این نتایج در production تکرار میشوند؟
• آیا بنچمارکها واقعاً معیار خوبی هستند؟
• آیا میتوان این رویکرد را به حوزههای دیگر تعمیم داد؟
نتیجه: VibeThinker-3B آینده را نشان میدهد که در آن مدلهای کوچک تخصصی در کنار غولهای همهکاره کار میکنند. این پایان مدلهای بزرگ نیست، بلکه شروع دوران معماریهای ترکیبی هوشمند است.
📚 منابع و مراجع
2. Official Model on Hugging Face
3. GitHub Repository
4. VentureBeat Analysis: "Why Weibo's tiny VibeThinker-3B has the AI world arguing"
5. Community Testing Results on Hugging Face Discussions
6. DeepSeek V3 Technical Report
7. AIME 2026 Official Results
🌐 با ما در ارتباط باشید 🎮✨
برای دریافت آخرین اخبار تکنولوژی، بازیها و گجتها، ما را در شبکههای اجتماعی دنبال کنید:
گالری تصاویر تکمیلی: 🧠 VibeThinker-3B: انقلاب یا توهم؟ تحلیل مدل کوچکی که غولهای هوش مصنوعی را لرزاند 🚀