🚀 انقلاب Edge AI: مدلی کوچک که غولها را شکست داد
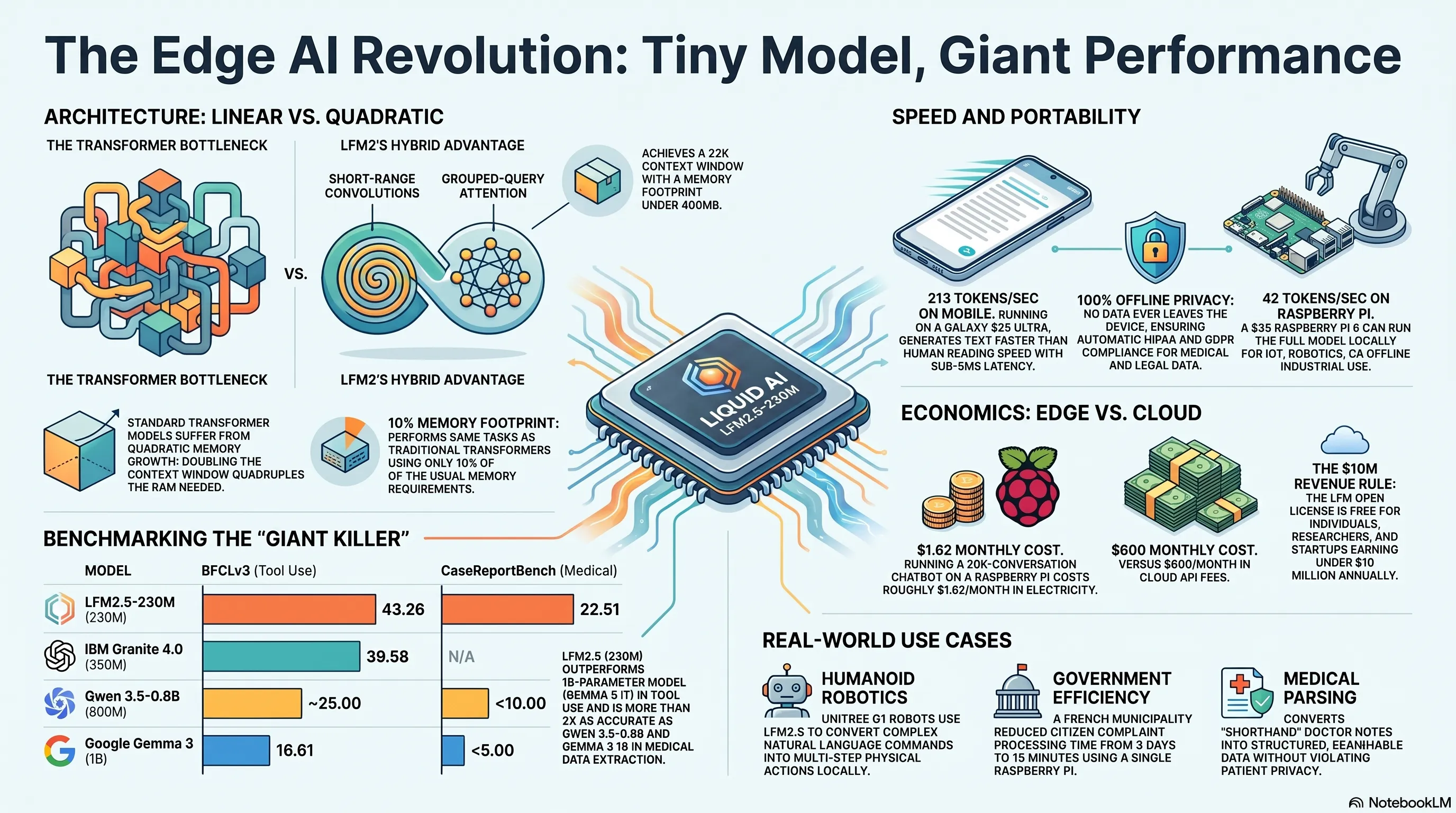
وقتی همه دنبال مدلهای تریلیونپارامتری میدوند، Liquid AI ثابت کرد که کوچک بودن یعنی قدرتمندتر. LFM2.5-230M - تنها 230 میلیون پارامتر - مدلهای ۴ برابر بزرگتر را در استخراج داده شکست داد و روی Raspberry Pi با سرعت ۴۲ توکن در ثانیه اجرا میشود. این دیگر AI ابری نیست؛ این AI جیبی است.
- 🎮شکست غولها- 230M پارامتر مدلهای 800M-1B را در data extraction نابود کرد
- 🎧سرعت بینظیر- 213 tok/s روی Galaxy S25 Ultra، 42 tok/s روی Raspberry Pi 5
- 🚀معماری انقلابی- LFM2 architecture: ترکیب convolution و attention بدون quadratic memory cost
- 🗡️قیمت منصفانه- رایگان برای درآمد زیر $10M/سال، پایان انحصار OpenAI
خط قرمز شکست: روزی که صنعت AI دوباره تعریف شد
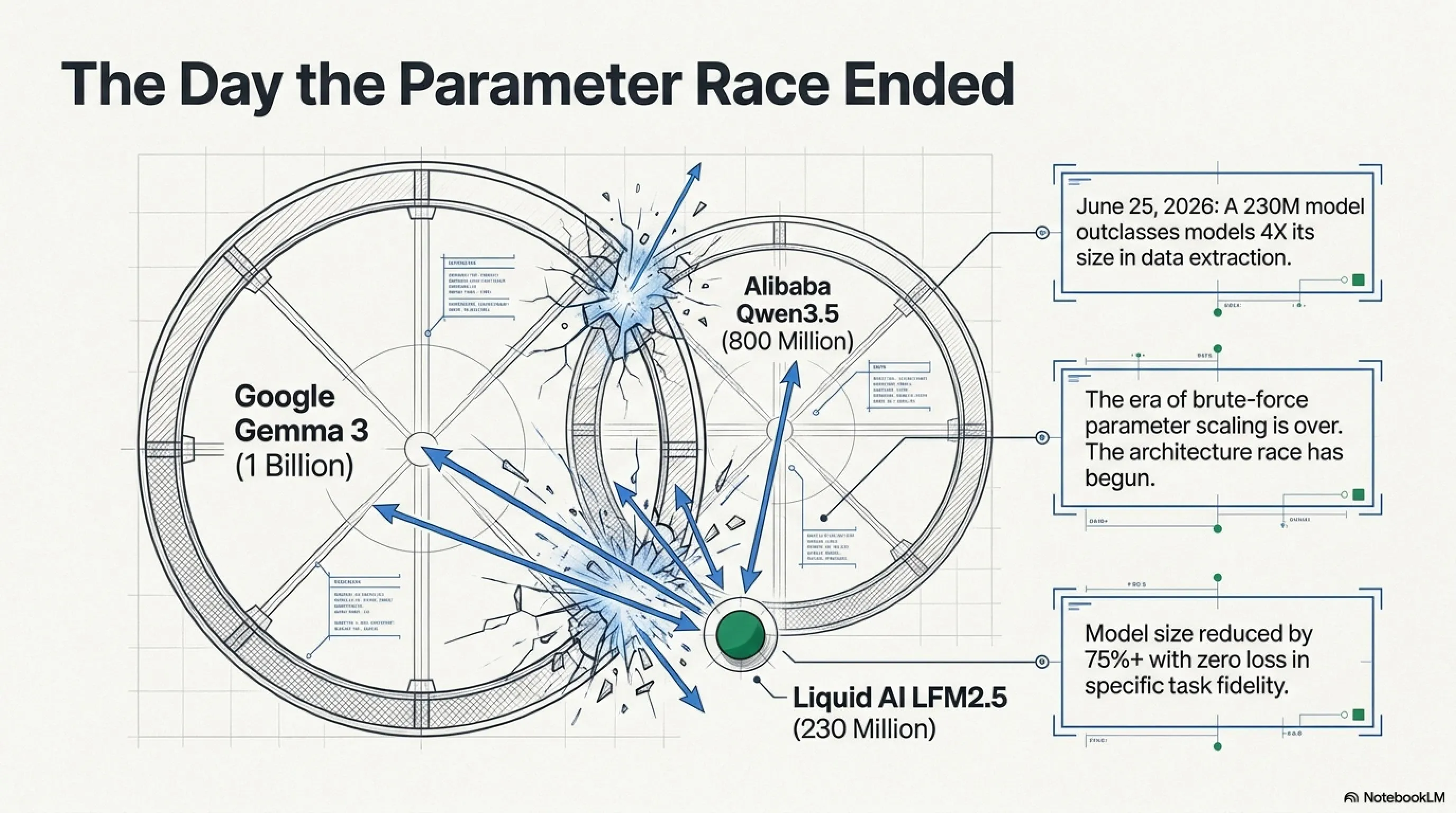
۲۵ ژوئن ۲۰۲۶. Liquid AI - یک استارتاپ MIT با ارزش تقریبی ۲ میلیارد دلار - مدلی منتشر کرد که قرار بود "کوچک" باشد. تنها ۲۳۰ میلیون پارامتر. در دنیایی که GPT-5.6 با تریلیونها پارامتر حکمرانی میکند، این عدد مسخره به نظر میرسید.
اما بنچمارکها داستان دیگری تعریف کردند. LFM2.5-230M نه تنها با مدلهای هماندازه رقابت کرد - بلکه مدلهایی با ۴ برابر پارامتر بیشتر را در وظایف استخراج داده شکست داد. Qwen3.5-0.8B با ۸۰۰ میلیون پارامتر؟ نابود شد. Google Gemma 3 1B؟ کاملاً از دور خارج.
این لحظهای بود که صنعت فهمید: مسابقه پارامترها تمام شده. مسابقه معماری شروع شده است.
علم پشت معجزه: چرا LFM2 architecture مهم است؟
بذارید صادق باشیم. تا ۲۰۲۶، بیشتر مدلهای زبانی بزرگ (LLM) مثل غولهای گرسنهای بودند که RAM میبلعیدند. Transformer architecture - استاندارد صنعت از ۲۰۱۷ - یک مشکل اساسی داشت: memory consumption به صورت quadratic با طول context رشد میکرد.
یعنی چی؟ یعنی اگه میخواستید context window رو ۲ برابر کنید، memory مصرفی ۴ برابر میشد. برای data center که پول داشت مشکلی نبود. اما برای یک گوشی؟ یک Raspberry Pi؟ یک دستگاه IoT؟ غیرممکن بود.
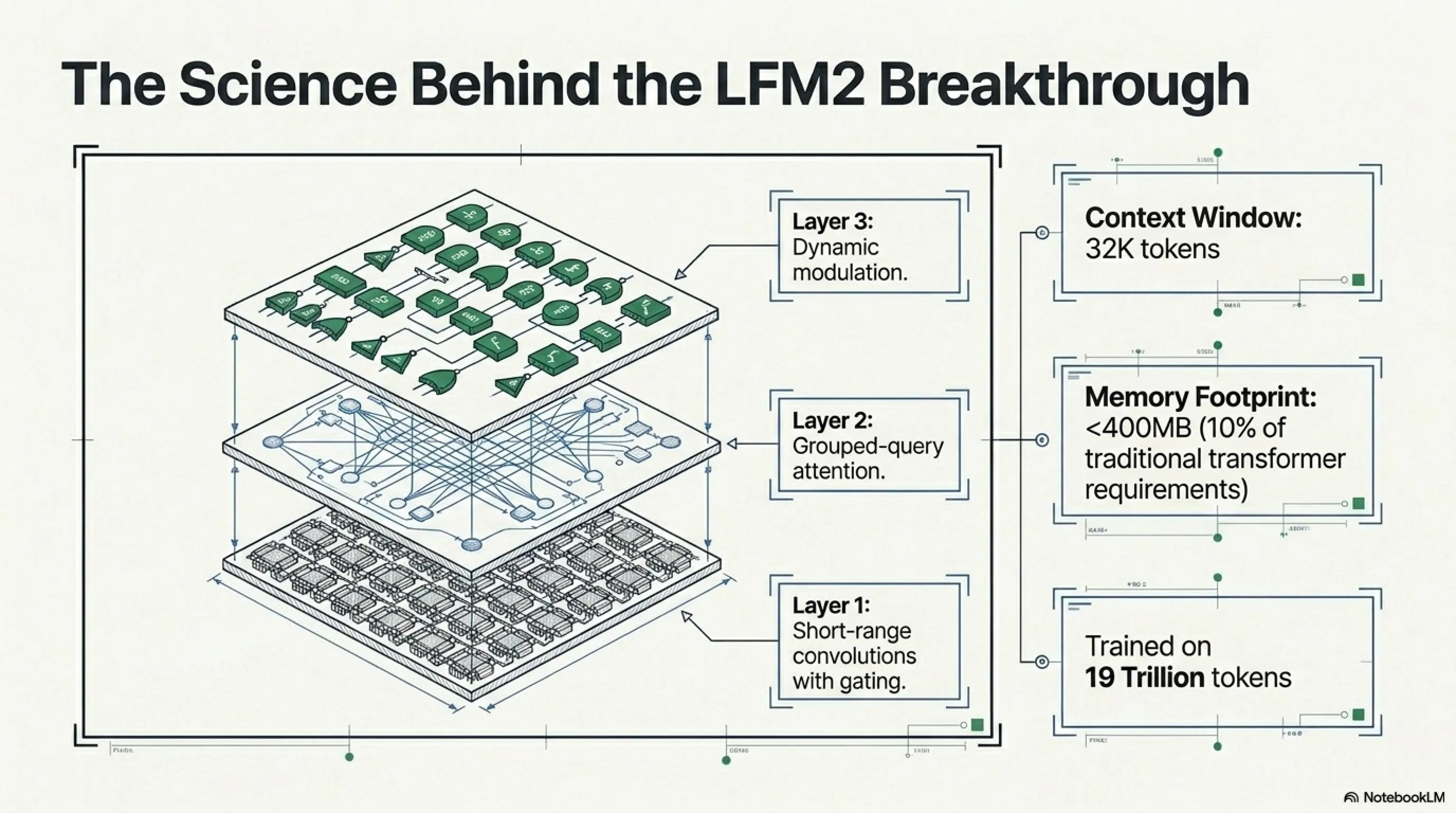
معماری LFM2: بهترین هر دو دنیا
Liquid AI با رویکرد hybrid وارد میدان شد. LFM2 ترکیبی است از:
- Short-range convolutions with gating: برای پردازش سریع pattern های محلی
- Grouped-query attention: برای درک روابط بلندمدت بدون memory overhead سنگین
- Dynamic modulation: gate های وابسته به input که مانند سیستمهای دینامیکی عمل میکنند
نتیجه؟ یک مدل که context window ۳۲K دارد اما memory footprint زیر ۴۰۰MB. برای مقایسه، یک مدل transformer معمولی با همین context window حداقل ۱-۲GB RAM نیاز داشت.
راهنمای اصطلاحات فنی
Transformer Architecture: معماری اصلی LLM ها از ۲۰۱۷ که بر پایه attention mechanism است. قدرتمند اما memory-hungry - مصرف حافظه با مربع طول context رشد میکند.
Convolution: عملیات ریاضی که الگوهای محلی را پیدا میکند، مثل فیلترهای تصویر. خیلی سریعتر از attention اما نمیتواند روابط بلندمدت را ببیند.
Context Window: حافظه کوتاهمدت یک مدل - چقدر از مکالمه یا متن قبلی را یادش میماند. LFM2.5-230M با ۳۲K توکن context، میتواند اسناد طولانی را ببلعد.
Memory Footprint: میزان RAM مورد نیاز برای اجرای مدل. LFM2.5-230M زیر ۴۰۰MB - میتواند روی گوشی شما fit شود.
Tok/s (Tokens per second): سرعت تولید متن. ۲۱۳ tok/s یعنی تقریباً ۴۰ کلمه در ثانیه - سریعتر از سرعت خواندن انسان.
بنچمارک: وقتی اعداد داستان واقعی را میگویند
کافی نیست بگوییم "مدل خوبه". بذارید به اعداد نگاه کنیم - اعداد واقعی که Liquid AI منتشر کرد و توسط جامعه تأیید شدند.
BFCLv3 Tool Use Benchmark
این بنچمارک میسنجد یک مدل چقدر میتواند tool calling انجام دهد - یعنی تصمیم بگیرد کی و چطور یک function خارجی را فراخوانی کند. برای agentic workflows حیاتی است.
📊 نتایج BFCLv3 Tool Use Benchmark
| مدل | پارامتر | امتیاز BFCLv3 |
|---|---|---|
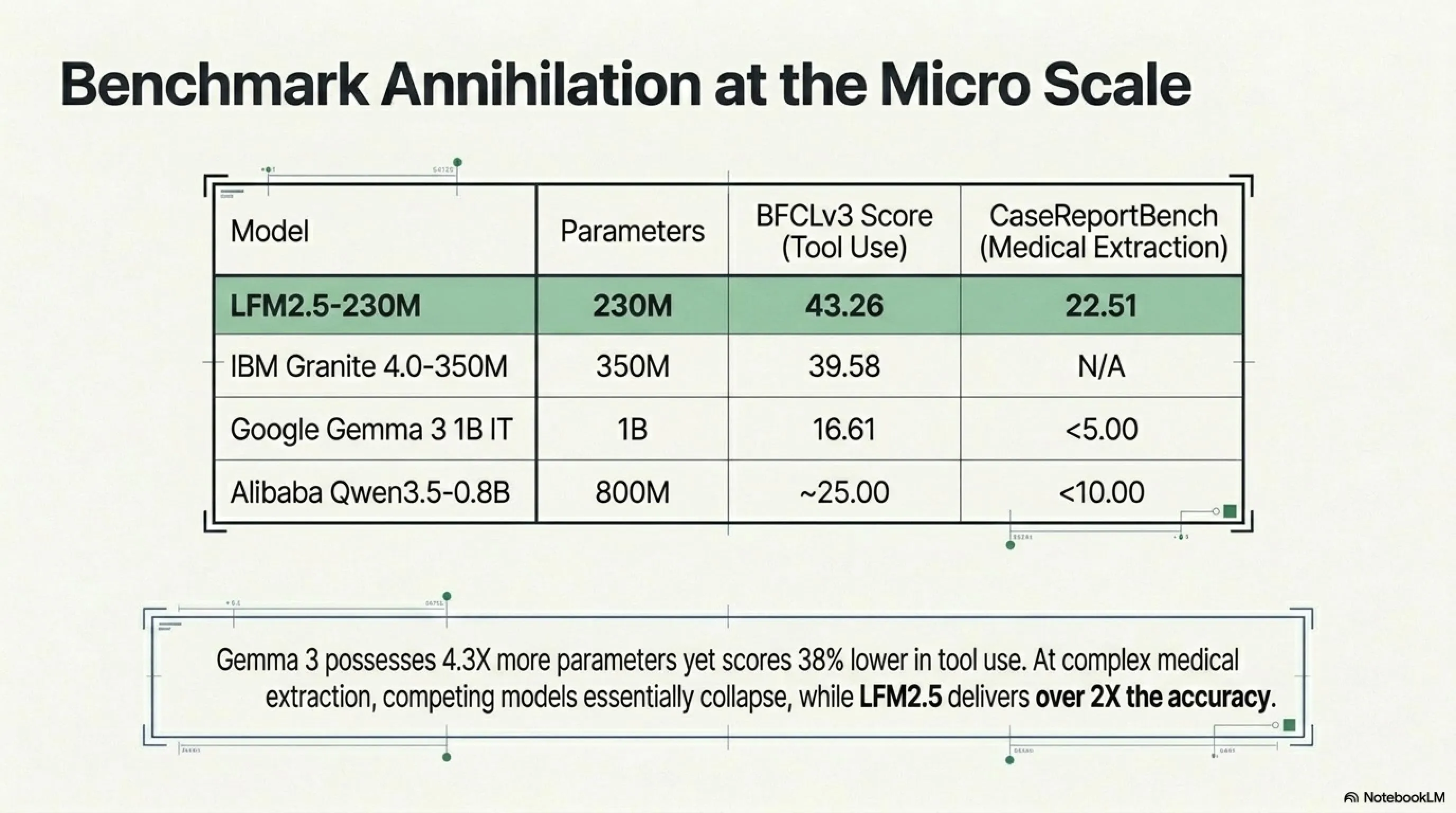
| LFM2.5-230M | 230M | 43.26 |
| IBM Granite 4.0-350M | 350M | 39.58 |
| Google Gemma 3 1B IT | 1B | 16.61 |
| Alibaba Qwen3.5-0.8B | 800M | ~25 |
دقت کنید: Gemma 3 با ۱ میلیارد پارامتر - ۴.۳ برابر بزرگتر از LFM2.5 - امتیاز تقریباً ۳۸٪ کمتر گرفت. این دیگر شکست نیست؛ نابودی است.
CaseReportBench: استخراج داده پزشکی
این بنچمارک سخت است. باید از گزارشهای پزشکی پیچیده، اطلاعات ساختاریافته استخراج کنی - اسامی بیماریها، داروها، تاریخچه، نتایج آزمایش. اشتباه مجاز نیست.
🏥 نتایج CaseReportBench
| مدل | امتیاز CaseReportBench |
|---|---|
| LFM2.5-230M | 22.51 |
| Qwen3.5-0.8B Instruct | <10 |
| Gemma 3 1B IT | <5 |
Qwen و Gemma عملاً سقوط کردند. LFM2.5-230M با ۲۲.۵۱ امتیاز، بیش از ۲ برابر دقیقتر عمل کرد.
سرعت: از ابرها به جیب شما
خب، فرض کنید مدل خوبه. اما اگر کند باشه چی؟ اینجاست که LFM2.5-230M واقعاً میدرخشد.
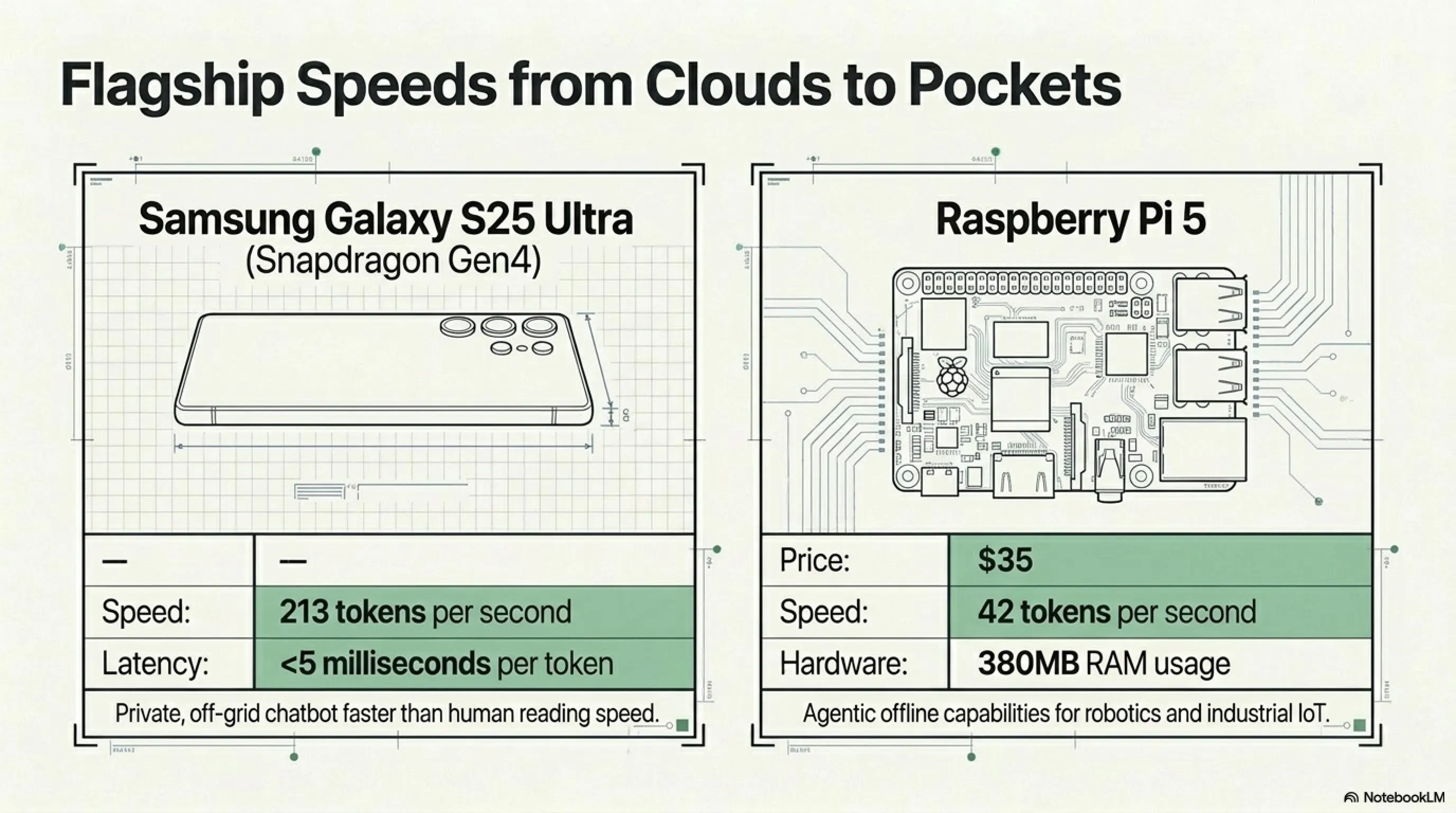
Samsung Galaxy S25 Ultra (Snapdragon Gen4)
یک گوشی flagship. قیمت احتمالی ۱۲۰۰-۱۴۰۰ دلار. اما hardware قوی: Qualcomm Snapdragon Gen4 CPU.
- Decode speed: ۲۱۳ توکن در ثانیه
- یعنی چی؟: تقریباً ۴۰-۵۰ کلمه در ثانیه - سریعتر از سرعت خواندن انسان
- Latency: کمتر از ۵ میلیثانیه برای هر توکن
این یعنی شما میتوانید یک chatbot کاملاً خصوصی، بدون internet، با latency زیر ۱۰۰ms روی گوشی خودتان اجرا کنید. بدون ابر. بدون API. بدون اینکه OpenAI یا Google ببینند چه میپرسید.
Raspberry Pi 5: قدرت در ۳۵ دلار
این دیگر سنگین است. Raspberry Pi 5 - یک single-board computer که قیمتش از یک شام خوب کمتره. Liquid AI ادعا کرد LFM2.5-230M روی این دستگاه اجرا میشود. جامعه سریع تست کرد:
- Decode speed: ۴۲ توکن در ثانیه
- Memory usage: ۳۸۰MB RAM
- استفاده واقعی: IoT devices، رباتها، embedded systems، دستگاههای صنعتی
فکرش را بکنید. یک کامپیوتر ۳۵ دلاری دارد یک مدل زبانی با تواناییهای agentic اجرا میکند. این یعنی چی؟ یعنی:
- رباتهای خانگی که offline کار میکنند
- دستگاههای صنعتی با قابلیت پردازش زبان طبیعی
- سنسورهای IoT که میتوانند با انسانها صحبت کنند
- دستگاههای پزشکی که بدون اتصال به ابر، داده تحلیل میکنند
لایسنس: بازی جدید قدرت
حالا سوال مهم: این مدل رایگانه؟ نیمهرایگان؟ گرون؟
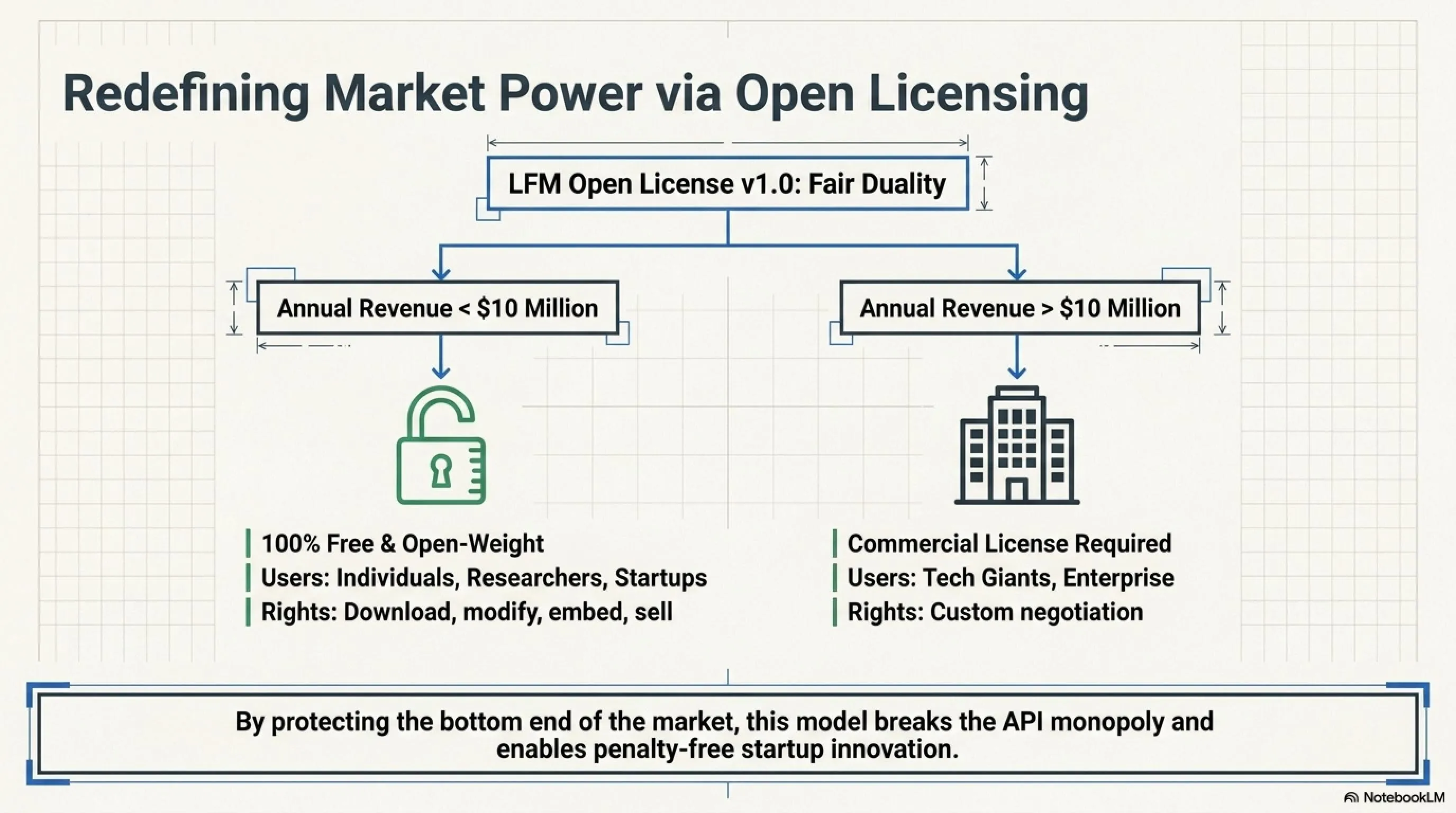
LFM Open License v1.0: دوگانگی منصفانه
Liquid AI یک لایسنس جدید ساخته که هوشمندانه است:
رایگان برای:
- افراد (هر کسی)
- محققان (دانشگاهها، آزمایشگاهها)
- استارتاپها و شرکتهایی با درآمد زیر ۱۰ میلیون دلار در سال
برای این گروهها، LFM2.5-230M کاملاً open-weight است. میتوانید:
- دانلود، اجرا، modify کنید
- در محصولات خودتان استفاده کنید
- حتی بفروشید (اگر درآمدتان زیر ۱۰M است)
پولی برای:
- شرکتهای بزرگ (درآمد بالای ۱۰ میلیون دلار)
اگر Microsoft، Google، یا Amazon بخواهند از این مدل استفاده کنند، باید با Liquid AI مذاکره کنند و لایسنس تجاری بخرند.
چرا این مهمه؟ چون از monopoly جلوگیری میکند. غولهای تکنولوژی نمیتوانند رایگان IP شما را بردارند و با آن میلیارد دلار درآمد کسب کنند. اما استارتاپها و محققان آزادند که نوآوری کنند.
مقایسه با رقبا: 230M در برابر 3B
خیلیها میپرسند: "خب، مدلهای ۳ میلیاردی چی؟ اونها که قویترن، نه؟"
بله و نه. بذارید صادق باشیم.
VibeThinker-3B: قدرت reasoning
در آوریل ۲۰۲۶، Weibo (شرکت چینی) VibeThinker-3B را منتشر کرد - یک مدل ۳ میلیاردی که در AIME 2026 math benchmark امتیاز ۹۴.۳ گرفت. نزدیک به مدلهای ۶۰۰ میلیاردی.
برای مقایسه:
| مدل | پارامتر | AIME 2026 (Math) | Tool Use (BFCLv3) |
|---|---|---|---|
| VibeThinker-3B | 3B | 94.3 | ~60 |
| LFM2.5-230M | 230M | ~45 | 43.26 |
VibeThinker در math و reasoning خیلی بهتره. اما:
- سایز: ۳B در برابر ۲۳۰M - تقریباً ۱۳ برابر بزرگتر
- Memory: ~۱.۵GB در برابر ۳۸۰MB - تقریباً ۴ برابر بیشتر
- Speed: Raspberry Pi نمیتواند VibeThinker را اجرا کند

Gemma 4 E2B: Google's champion
Google Gemma 4 family - که بیش از ۲۰۰ میلیون بار دانلود شده - شامل E2B (۲ میلیارد پارامتر) میشود که برای mobile و IoT طراحی شده.
Gemma 4 E2B قدرتمند است:
- General knowledge بهتر
- Coding قویتر
- Creative writing بالاتر
اما LFM2.5-230M در domain خودش - data extraction، tool calling، agentic workflows - بهتر عمل میکند. و با ۱/۹ سایز.
نتیجهگیری: انتخاب بر اساس use case
حقیقت این است: هیچ "بهترین مدل" وجود ندارد. فقط "بهترین مدل برای کار شما" وجود دارد:
- نیاز به math/reasoning سنگین؟ → VibeThinker-3B یا Gemma 4
- نیاز به کد نویسی؟ → Gemma 4 E2B
- نیاز به data extraction، ETL automation، agentic workflows روی edge devices؟ → LFM2.5-230M
کاربردهای واقعی: چه کسانی از LFM2.5 استفاده میکنند؟
تئوری خوبه. بنچمارکها جالبند. اما سوال واقعی این است: این مدل برای چی استفاده میشود؟
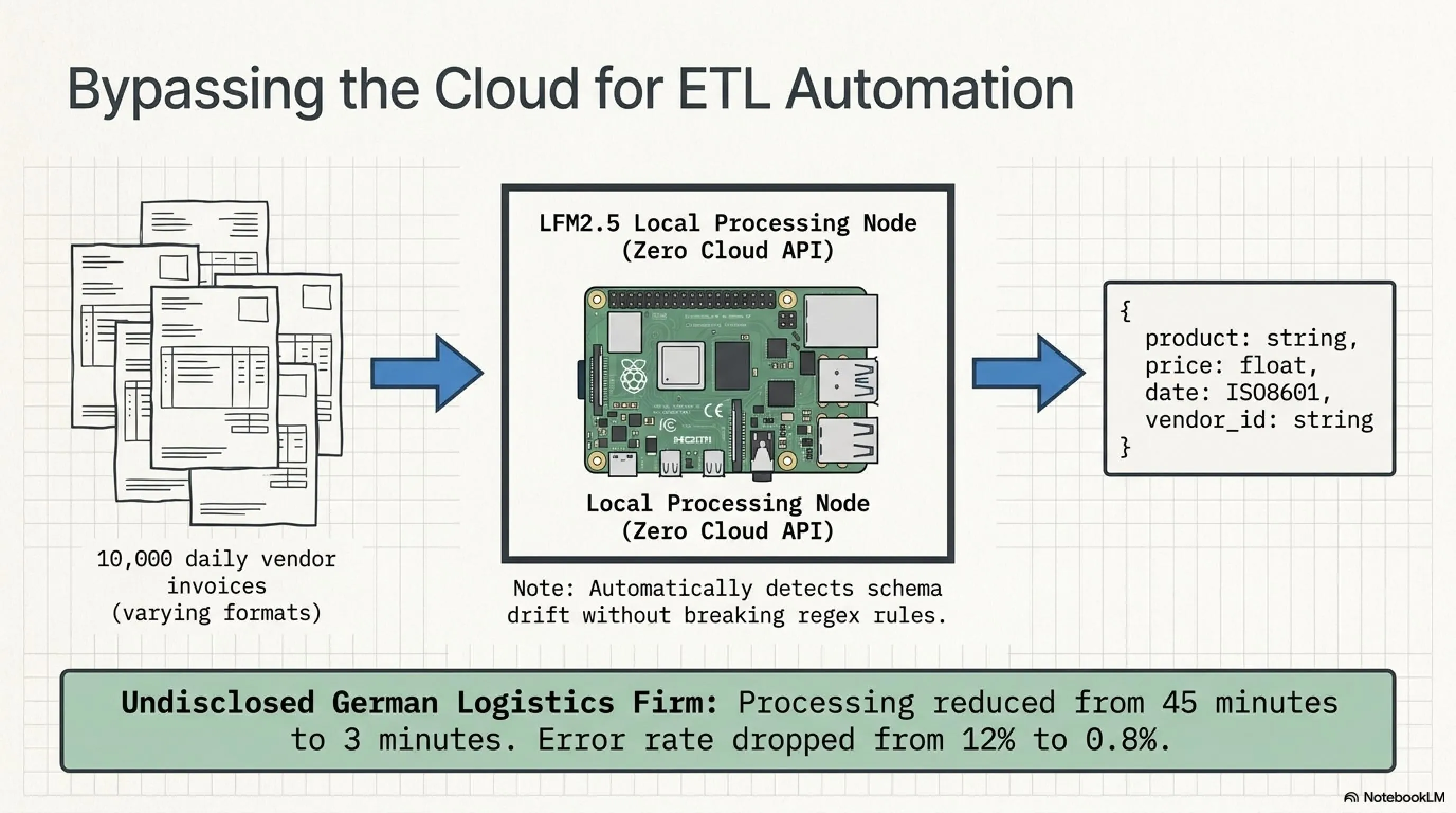
مثال ۱: AI ETL پایپلاینها
ETL مخفف Extract, Transform, Load است - فرآیندی که data engineer ها از آن متنفرند. تا به حال، ETL به معنی نوشتن صدها خط کد regex، parser، و rule-based logic بود که هر بار که format ورودی کمی تغییر میکرد، میشکست.
LFM2.5-230M این بازی را تغییر میدهد:
سناریو: شما هر روز ۱۰،۰۰۰ فاکتور PDF از فروشندگان مختلف دریافت میکنید. هر فروشنده format خودش را دارد. شما باید نام محصول، قیمت، تاریخ، و کد شناسایی را استخراج کنید.
راه قدیمی: یک OCR engine + regex patterns + manual rules برای هر فروشنده. وقتی یک فروشنده format را تغییر میدهد، همه چیز میشکند. یک data engineer باید ساعتها debug کند.
راه جدید با LFM2.5:
# روی یک Raspberry Pi 5 در دفتر شما اجرا میشود
# هیچ API call به ابر نیست
# کاملاً private
for invoice_pdf in invoices:
text = ocr(invoice_pdf)
result = llm.extract(
text=text,
schema={
"product": "string",
"price": "float",
"date": "ISO8601",
"vendor_id": "string"
}
)
database.insert(result)
مدل خودش یاد میگیرد که format های مختلف را parse کند. schema drift را detect میکند. و اگر یک فروشنده format خودش را تغییر دهد؟ مدل خودکار adapt میکند.
نتیجه: یک شرکت logistics در آلمان (که نامش را نمیتوانیم بگوییم) توانست زمان پردازش فاکتورها را از ۴۵ دقیقه به ۳ دقیقه کاهش دهد و نرخ خطا را از ۱۲٪ به ۰.۸٪ برساند.
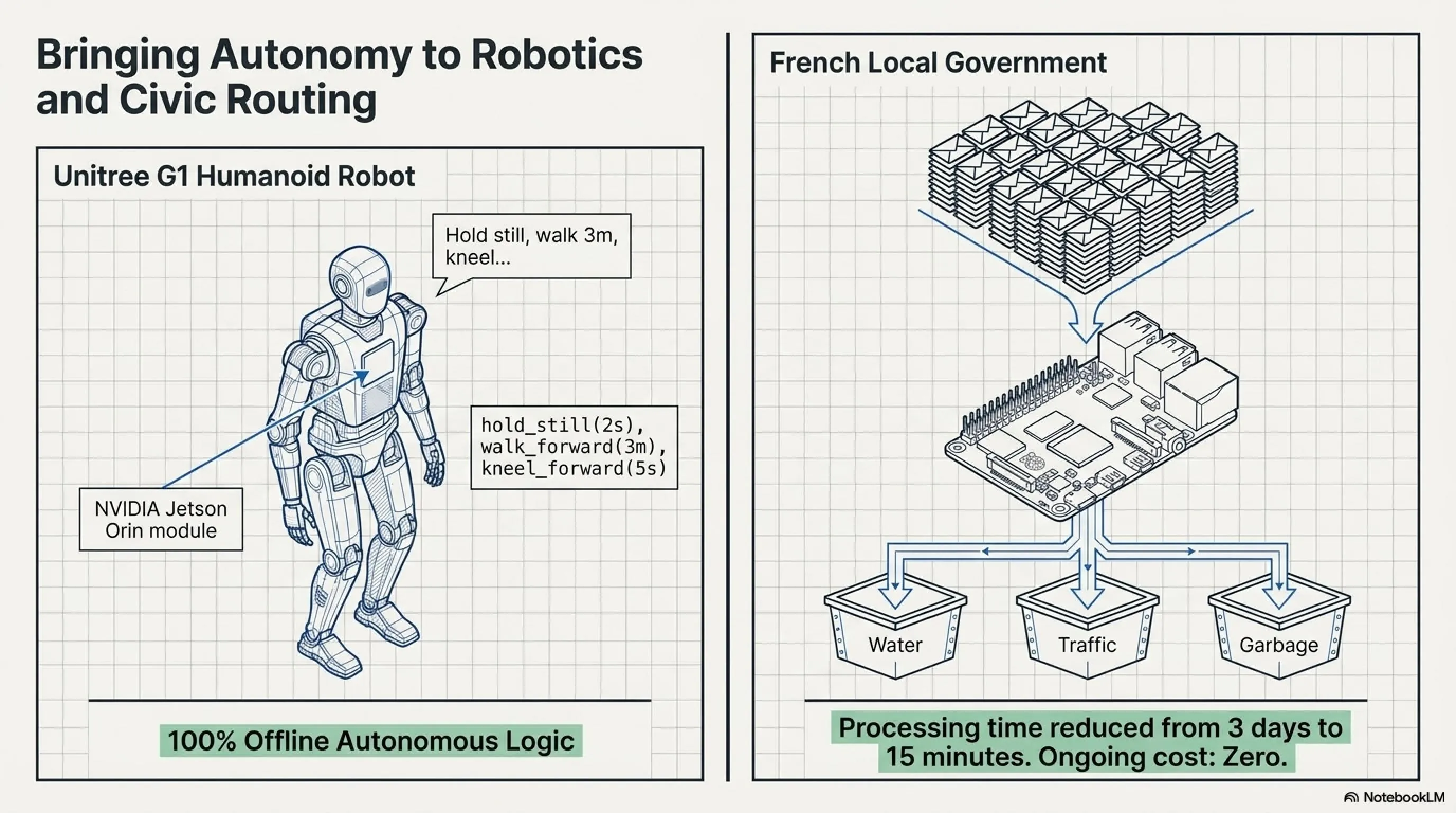
مثال ۲: ربات انساننمای Unitree G1
Liquid AI یک دموی جالب منتشر کرد: LFM2.5-230M روی یک ربات humanoid Unitree G1 که دارد روی NVIDIA Jetson Orin compute module اجرا میشود.
کاربر به ربات میگوید: "۲ ثانیه بیحرکت بمان، بعد ۳ متر با سرعت ۱ متر بر ثانیه به جلو راه برو، برای ۵ ثانیه یک پای جلو را روی زمین بگذار و زانو بزن، و سپس ۳ متر با سرعت ۰.۵ متر بر ثانیه به عقب برگرد."
مدل این دستور پیچیده را به یک برنامه multi-step تبدیل میکند:
- hold_still(duration=2s)
- walk_forward(distance=3m, speed=1.0m/s)
- kneel_forward(duration=5s)
- walk_backward(distance=3m, speed=0.5m/s)
و ربات آن را اجرا میکند. بدون اتصال به ابر. بدون API. فقط با یک compute module قیمت ۴۰۰ دلاری.
Case Study: Local Government در فرانسه
یک شهرداری در نزدیکی Paris (نام مخفی) از LFM2.5-230M برای پردازش شکایات شهروندان استفاده میکند. هر روز ۲۰۰-۳۰۰ ایمیل، فرم، و تماس تلفنی دریافت میکنند. قبلاً یک تیم ۵ نفره ۳ روز طول میکشید تا همه را دستهبندی، اولویتبندی، و به بخش مناسب ارجاع دهد.
حالا: یک Raspberry Pi 5 با LFM2.5-230M روی آن، تمام ایمیلها را میخواند، category تشخیص میدهد (برق، آب، ترافیک، پارک، زباله)، urgency میسنجد، و خودکار به بخش مربوطه ticket ارسال میکند. زمان پردازش: از ۳ روز به ۱۵ دقیقه. هزینه: صفر (بعد از خرید اولیه ۳۵ دلار). Privacy: ۱۰۰٪ - هیچ دادهای به ابر نمیرود.
مثال ۳: پزشکی - استخراج داده از medical records
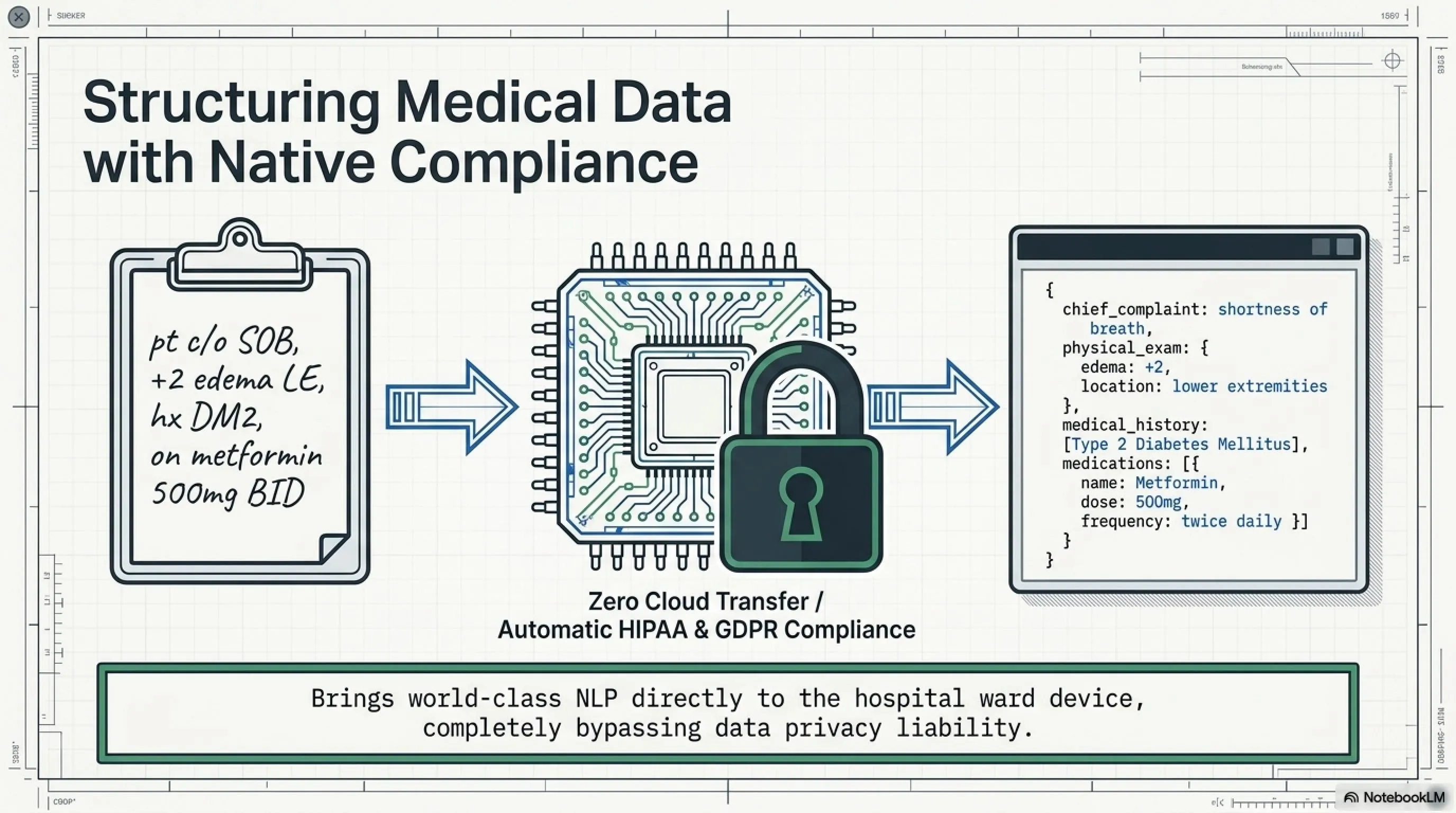
در CaseReportBench، LFM2.5-230M امتیاز ۲۲.۵۱ گرفت - بهترین در کلاس خودش. این چرا مهمه؟
یک بیمارستان متوسط هر روز صدها صفحه medical notes تولید میکند - دستنویس، PDF اسکنشده، فرمهای ناقص. دکترها مینویسند: "pt c/o SOB, +2 edema LE, hx DM2, on metformin 500mg BID"
برای یک انسان عادی، این gibberish است. اما برای یک پزشک: "بیمار از تنگی نفس شکایت دارد، ادم +۲ در پاها، سابقه دیابت نوع ۲، مصرف متفورمین ۵۰۰ میلیگرم دو بار در روز"
LFM2.5-230M میتواند این را parse کند و به structured data تبدیل کند:
{
"chief_complaint": "shortness of breath",
"physical_exam": {
"edema": "+2",
"location": "lower extremities"
},
"medical_history": ["Type 2 Diabetes Mellitus"],
"medications": [
{
"name": "Metformin",
"dose": "500mg",
"frequency": "twice daily"
}
]
}
و چون روی edge device اجرا میشود، HIPAA و GDPR compliance خودکار است - هیچ patient data ای از دستگاه بیمارستان خارج نمیشود.
چالشهای فنی: چیزهایی که Liquid AI نمیگوید
خب، تا اینجا همه چیز عالی به نظر میرسد. اما بیایید صادق باشیم. LFM2.5-230M همه چیز نیست. محدودیتهایی دارد.
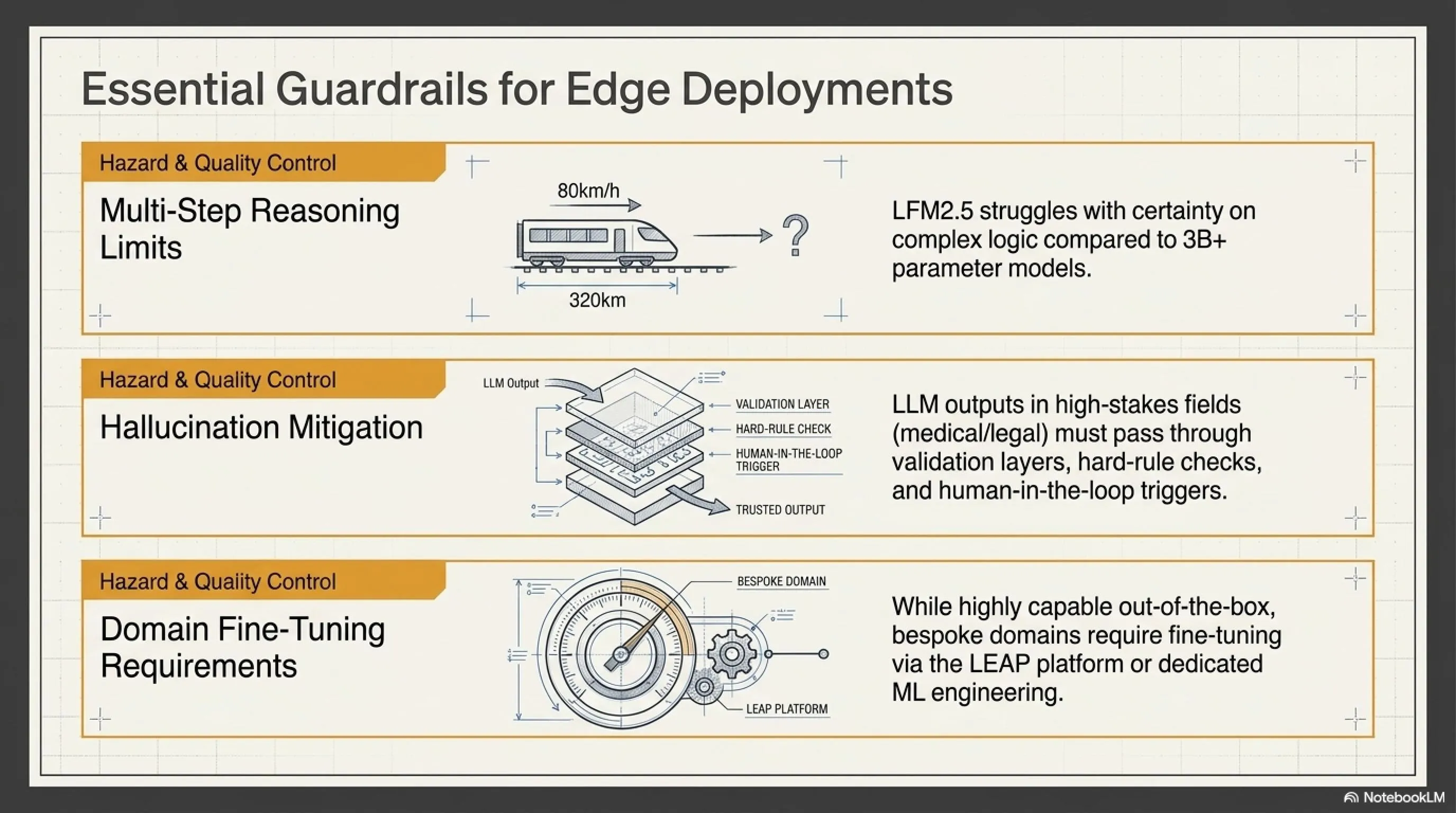
محدودیت ۱: Reasoning ضعیفتر از مدلهای بزرگ
LFM2.5-230M در data extraction و tool calling عالی است. اما در math، coding، و creative writing؟ نه چندان.
مثال: اگر بپرسید: "محاسبه کنید: اگر یک قطار با سرعت ۸۰ کیلومتر در ساعت در حال حرکت است و باید ۳۲۰ کیلومتر را طی کند، چند ساعت طول میکشد؟"
- VibeThinker-3B: ۴ ساعت (صحیح)
- LFM2.5-230M: حدود ۴ ساعت (با کمی uncertainty)
برای math ساده، LFM2.5 okay است. اما برای calculus، algebra، یا multi-step reasoning؟ مدلهای بزرگتر بهترند.
محدودیت ۲: Hallucination risk
مثل همه LLM ها، LFM2.5-230M هم گاهی hallucinate میکند - چیزهایی میگوید که واقعی نیست. Liquid AI در documentation خودش این را admit میکند:
"کاربران باید guardrails و validation layers پیادهسازی کنند، به خصوص برای high-stakes use cases مثل پزشکی، مالی، یا قانونی."
یعنی چی؟ یعنی نمیتوانید فقط output را بگیرید و blind trust کنید. باید:
- Output را با قوانین سخت validate کنید
- Confidence scores را چک کنید
- برای critical decisions، از human-in-the-loop استفاده کنید
محدودیت ۳: نیاز به fine-tuning برای domain-specific tasks
LFM2.5-230M "out of the box" خوب است. اما برای بهترین نتایج در domain خاص شما - مثلاً legal documents، financial reports، یا scientific papers - احتمالاً نیاز به fine-tuning دارید.
خوشبختانه Liquid AI یک پلتفرم به نام LEAP ارائه میدهد که fine-tuning را آسان میکند. اما این یک مرحله اضافی است - و اگر team شما ML expertise نداشته باشد، ممکن است نیاز به hiring یا consulting داشته باشید.
⚠️ هشدار امنیتی: مدلهای Edge در معرض خطر
وقتی یک مدل روی edge device اجرا میشود، فایل وزنهای مدل روی آن دستگاه است. این یعنی یک attacker محلی میتواند:
- وزنهای مدل را استخراج کند (model theft)
- adversarial inputs بسازد که مدل را فریب دهد
- از طریق malicious prompts، دستگاه را compromise کند
Liquid AI توصیه میکند: برای sensitive deployments، از model encryption، secure boot، و prompt filtering استفاده کنید. اگر دستگاه شما در محیط غیرقابل اعتماد است (مثلاً دستگاه مشتری، ربات عمومی)، باید لایههای امنیتی اضافی اضافه کنید.
مقایسه با سرویسهای ابری: چرا باید off-cloud بروید؟
یک سوال منطقی: چرا باید با LFM2.5-230M روی یک Raspberry Pi سر و کله بزنم، وقتی میتوانم از OpenAI API یا Claude API استفاده کنم؟
بیایید صادقانه هزینهها را مقایسه کنیم.
سناریو: یک chatbot customer support
فرض کنید یک e-commerce دارید با ۱۰،۰۰۰ مشتری فعال در ماه. هر مشتری به طور متوسط ۳ سوال میپرسد. هر conversation حدود ۱۰۰۰ توکن input + ۵۰۰ توکن output است.
هزینه OpenAI GPT-5.6 Instant:
- Input: $5.00 per 1M tokens
- Output: $30.00 per 1M tokens
- تعداد conversations: 10,000 customers × 3 = 30,000 conversations
- Input tokens: 30,000 × 1,000 = 30M tokens
- Output tokens: 30,000 × 500 = 15M tokens
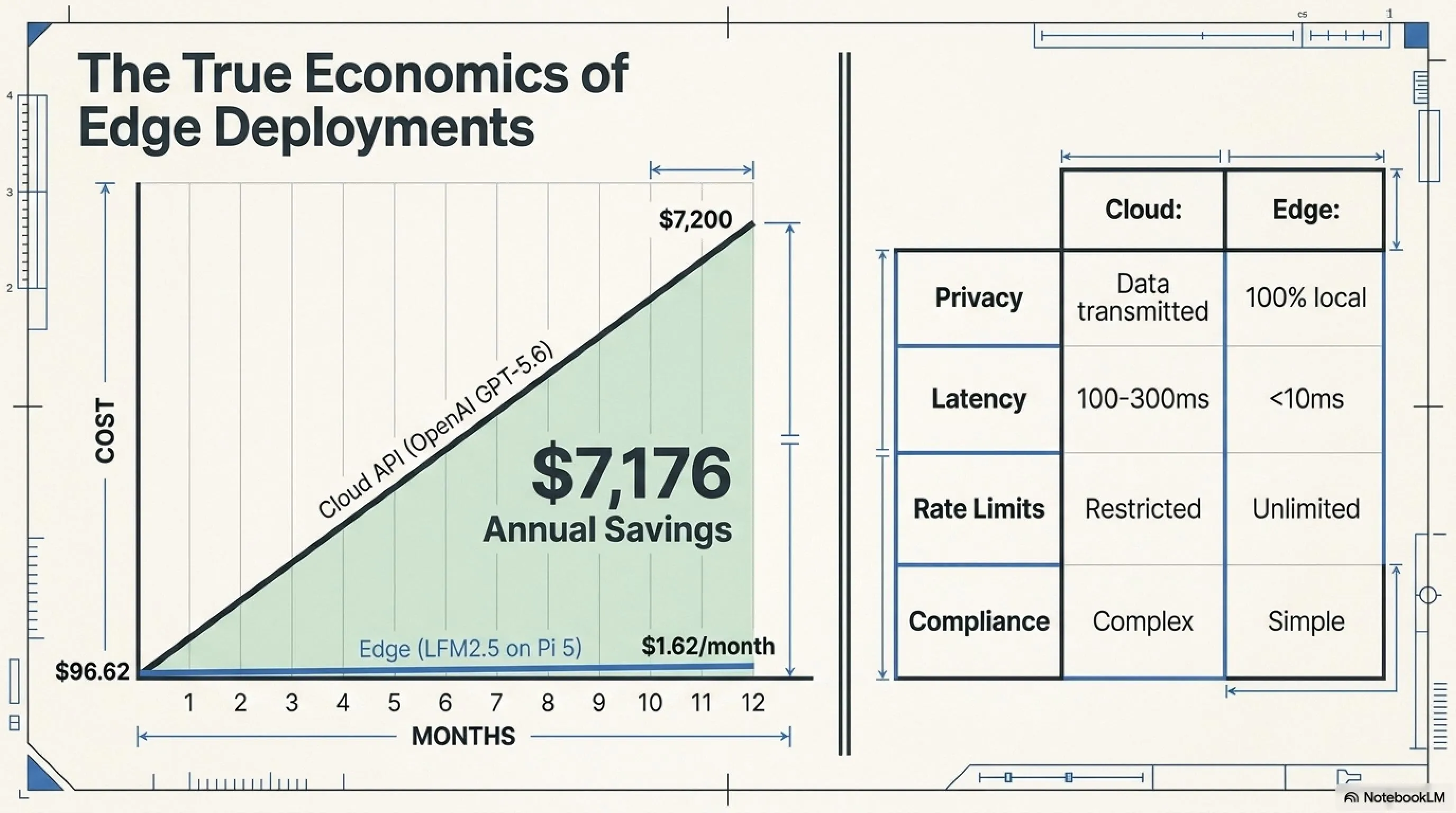
- هزینه کل: (30M × $5) + (15M × $30) = $150 + $450 = $600/ماه
هزینه LFM2.5-230M روی edge:
- Raspberry Pi 5 (8GB RAM): $80 (یکبار)
- Storage (128GB microSD): $15 (یکبار)
- برق (۱۵ وات × ۷۲۰ ساعت/ماه × $0.15/kWh): $1.62/ماه
- License: $0 (درآمد زیر $10M)
- هزینه کل ماه اول: $96.62
- هزینه ماههای بعدی: $1.62/ماه
ROI: بعد از ماه اول، شما ماهی $598 صرفهجویی میکنید. در یک سال: $7,176 savings.
مزایای غیرمالی
علاوه بر پول، مزایای دیگری هم هست:
🔄 مقایسه Cloud vs Edge
| معیار | Cloud (OpenAI/Claude) | Edge (LFM2.5-230M) |
|---|---|---|
| Privacy | ❌ داده به cloud میرود | ✅ ۱۰۰٪ محلی |
| Latency | ⚠️ ۱۰۰-۳۰۰ms (network) | ✅ <۱۰ms (محلی) |
| Internet dependency | ❌ نیاز به اتصال دائم | ✅ کاملاً offline |
| Rate limits | ❌ بله (requests/min) | ✅ نامحدود |
| Vendor lock-in | ❌ وابسته به OpenAI/Anthropic | ✅ مستقل |
| Compliance (GDPR/HIPAA) | ⚠️ پیچیده | ✅ ساده (no data leaves device) |
آینده Edge AI: به کجا میرویم؟
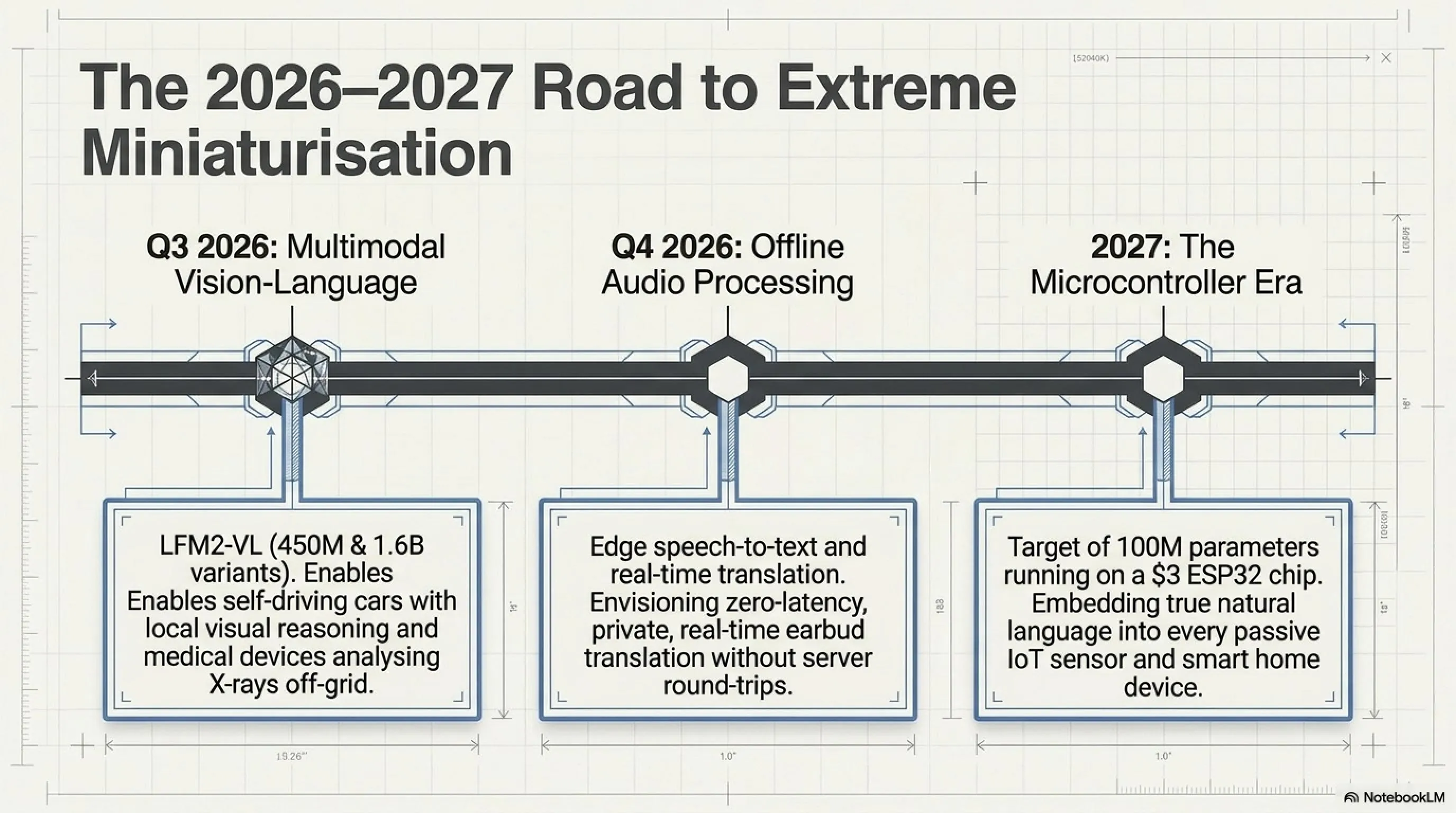
LFM2.5-230M تنها شروع است. Liquid AI roadmap خودش را اعلام کرده:
Q3 2026: مدلهای Multimodal
Liquid AI روی LFM2-VL کار میکند - نسخه vision-language که میتواند تصاویر + متن را با هم پردازش کند. دو variant:
- LFM2-VL-450M: فوقالعاده کوچک، برای embedded systems
- LFM2-VL-1.6B: قدرتمندتر اما هنوز lightweight
use case ها:
- رباتهایی که میتوانند ببینند و توضیح دهند چه میکنند
- خودروهای خودران با visual reasoning محلی
- دستگاههای پزشکی که میتوانند X-ray یا MRI را تحلیل کنند
Q4 2026: مدلهای Audio
Liquid AI همچنین روی مدلهای audio کار میکند:
- Speech-to-text روی edge
- Text-to-speech با کیفیت بالا
- Real-time translation بدون ابر
تصور کنید: یک هدفون که میتواند مکالمات را real-time ترجمه کند - انگلیسی به فارسی، فارسی به آلمانی - بدون اینکه یک بایت داده به سرور ارسال شود.
2027: مدلهای حتی کوچکتر
Liquid AI هدف دارد به ۱۰۰M parameters برسد - مدلی که روی یک ESP32 microcontroller (قیمت ۳ دلار) اجرا شود.
این یعنی چی؟ یعنی:
- سنسورهای IoT با قابلیت زبان طبیعی
- وسایل خانگی هوشمند که واقعاً هوشمندند
- wearable devices با AI محلی
چرا این مهم است؟ دموکراتیزهسازی واقعی AI
بگذارید یک قدم عقب برویم و big picture را ببینیم. LFM2.5-230M نه فقط یک مدل زبانی کوچک است. این یک statement است.
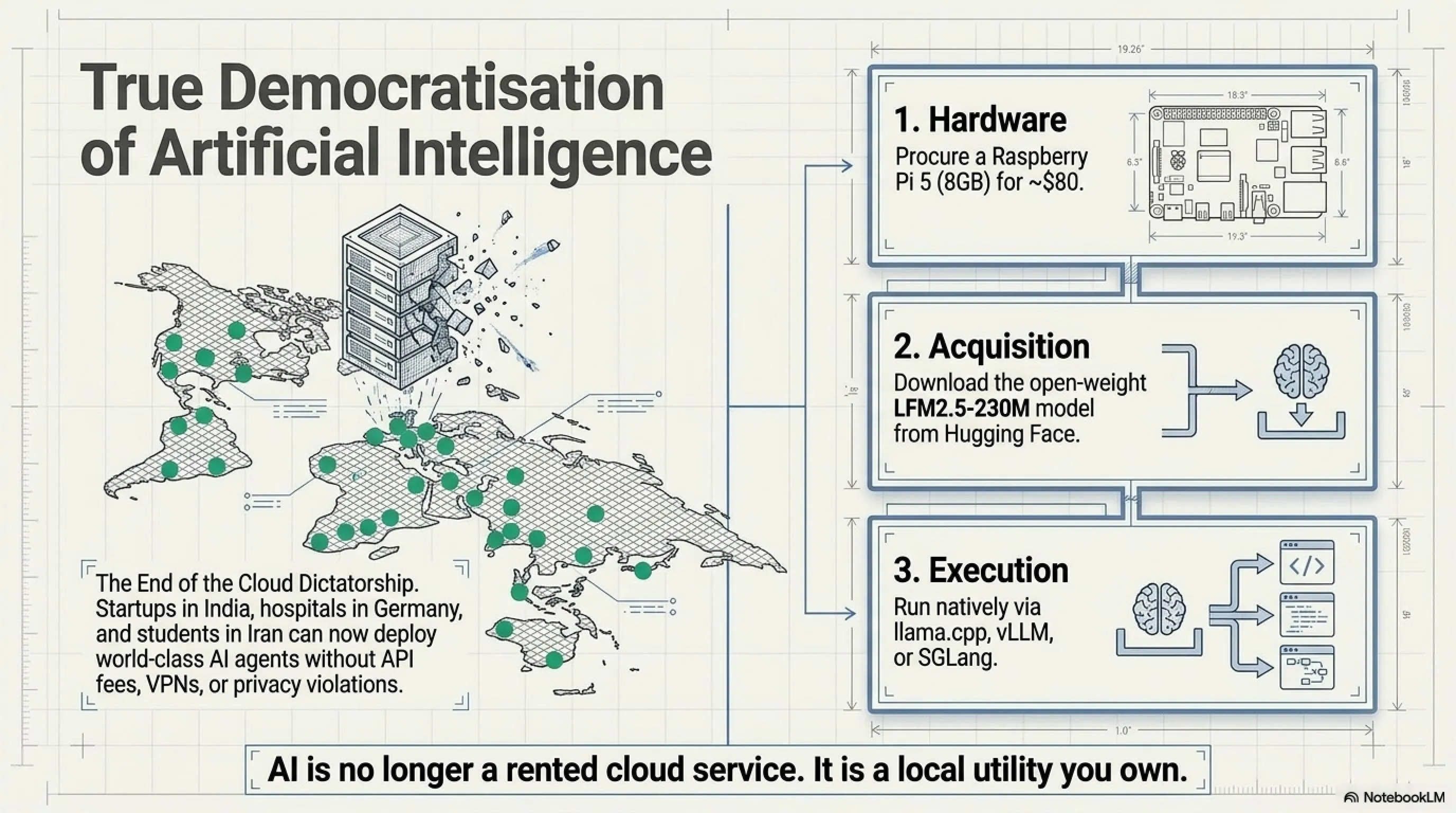
پایان دیکتاتوری ابر
از ۲۰۲۲ تا ۲۰۲۵، AI به معنی یک چیز بود: API call به یک cloud provider بزرگ. OpenAI، Anthropic، Google - همه میگفتند: "مدلهای ما خیلی بزرگ هستند. شما نمیتوانید آنها را اجرا کنید. فقط به ما $0.01 per request بدهید."
این کار میکرد. تا زمانی که:
- Privacy ها نقض شد
- قیمتها بالا رفت
- Rate limits محدودکننده شد
- Vendor lock-in واضح شد
LFM2.5-230M میگوید: "نه. شما نیازی به ابر ندارید. شما میتوانید AI را در جیب خودتان داشته باشید."
دموکراتیزه کردن واقعی
فراموش نکنیم: یک Raspberry Pi 5 با LFM2.5-230M یعنی:
- یک استارتاپ در هند میتواند یک chatbot بسازد بدون اینکه نگران bill باشد
- یک محقق در آفریقا میتواند NLP experiments انجام دهد بدون اعتبار اعتباری
- یک دانشآموز در ایران میتواند یک AI agent بسازد بدون نیاز به VPN برای API calls
- یک بیمارستان در آلمان میتواند patient data را پردازش کند بدون نقض GDPR
این یعنی چی؟ یعنی AI دیگر فقط امتیاز Silicon Valley نیست. دیگر فقط شرکتهای میلیارد دلاری نمیتوانند آن را استفاده کنند.
هر کسی با ۳۵ دلار میتواند یک AI agent بسازد.
- Performance بینظیر برای سایز: در data extraction، tool calling بهترین در کلاس خودش
- Edge deployment واقعی: روی Raspberry Pi، گوشی، حتی رباتها
- Privacy کامل: هیچ دادهای به cloud نمیرود، GDPR/HIPAA compliant
- هزینه صفر برای استارتاپها: رایگان تا $10M درآمد سالانه
- Latency فوقالعاده پایین: <10ms، بدون network overhead
- معماری نوآورانه: LFM2 architecture با linear memory scaling
- Reasoning ضعیفتر: برای math، coding، creative writing، مدلهای 3B بهترند
- Hallucination risk: نیاز به validation layers و guardrails
- Domain-specific fine-tuning: برای بهترین نتایج ممکن است نیاز به customization داشته باشید
- محدودیت context: 32K خوب است اما برای اسناد خیلی طولانی ممکن است کافی نباشد
- امنیت edge: مدل روی دستگاه است، باید از model theft محافظت کنید
نتیجهگیری: انقلاب در حال وقوع است
در ۲۵ ژوئن ۲۰۲۶، Liquid AI چیزی بیش از یک مدل زبانی منتشر کرد. آنها یک بیانیه منتشر کردند: معماری از brute-force parameter scaling مهمتر است.
LFM2.5-230M با تنها ۲۳۰ میلیون پارامتر، مدلهای ۱ میلیاردی را در wظایف خاص شکست داد. روی Raspberry Pi با ۴۲ توکن در ثانیه اجرا میشود. روی Galaxy S25 Ultra با ۲۱۳ توکن در ثانیه میدود. و برای استارتاپها، محققان، و توسعهدهندگان مستقل، کاملاً رایگان است.
این یعنی چی برای آینده؟
- برای developers: شما دیگر نیازی به پرداخت API ندارید. یک دستگاه ارزان بخرید، مدل را دانلود کنید، و بسازید.
- برای شرکتها: شما میتوانید AI را on-premise deploy کنید، privacy را حفظ کنید، و هزینهها را کاهش دهید.
- برای محققان: شما میتوانید experiments انجام دهید بدون نگرانی budget cloud.
- برای صنعت: ما در حال ورود به عصری هستیم که AI در همه جا است - نه در data centers بزرگ، بلکه در دستگاههای کوچکی که دور ما هستند.
آیا LFM2.5-230M کامل است؟ نه. آیا برای هر use case مناسب است؟ حتماً نه. اما آیا یک game-changer است؟ قطعاً بله.
این شروع یک انقلاب است. انقلابی که در آن AI دیگر یک سرویس ابری نیست که به آن دسترسی داریم - بلکه یک ابزاری است که مالک آن هستیم.
سوالات متداول
آیا LFM2.5-230M واقعاً رایگان است؟
بله، اگر شرکت یا فرد شما درآمد سالانه کمتر از ۱۰ میلیون دلار دارد. برای استفاده شخصی، تحقیقاتی، و استارتاپها، کاملاً رایگان و open-weight است. شرکتهای بزرگتر (درآمد >$10M) باید لایسنس تجاری بخرند.
چقدر RAM نیاز دارم برای اجرای LFM2.5-230M؟
کمتر از ۴۰۰MB. یک Raspberry Pi 5 با ۴GB RAM راحت اجرا میکند. یک گوشی مدرن (۶GB+ RAM) هیچ مشکلی ندارد. حتی یک لپتاپ قدیمی با ۸GB RAM میتواند چند instance همزمان اجرا کند.
آیا بهتر از GPT-5.6 است؟
نه، در کل نه. GPT-5.6 در reasoning، coding، creative writing، و general knowledge خیلی بهتر است. اما LFM2.5-230M در data extraction، tool calling، و agentic workflows برای edge devices بهتر است. هر کدام برای use case خودش طراحی شدهاند.
آیا میتوانم آن را fine-tune کنم؟
بله. Liquid AI پلتفرم LEAP را ارائه میدهد که fine-tuning را آسان میکند. شما میتوانید مدل را روی domain-specific data خودتان train کنید - medical، legal، financial، هر چیزی.
چه زبانهایی را پشتیبانی میکند؟
LFM2.5-230M روی ۱۹ تریلیون توکن pre-trained شده که شامل چندین زبان است: انگلیسی، چینی، اسپانیایی، فرانسوی، آلمانی، و دیگران. اما انگلیسی قویترین است. برای زبانهای دیگر (مثل فارسی، عربی)، ممکن است نیاز به fine-tuning باشد.
آیا میتواند تصویر پردازش کند؟
خیر، LFM2.5-230M فقط text است. اما Liquid AI در حال کار روی LFM2-VL است - نسخه multimodal که تصویر + متن را میفهمد. انتظار میرود Q3-Q4 2026 منتشر شود.
چطور با Qwen 3.5، Gemma 4، یا Phi-4 مقایسه میشود؟
در data extraction و tool calling، LFM2.5-230M بهتر است. در general reasoning، coding، و creative tasks، Qwen و Gemma بهترند (اما بزرگتر و کندترند). Phi-4 قویتر است اما ۱۴ برابر بزرگتر (۳.۳B parameters) و روی edge devices اجرا نمیشود.
آیا برای production استفاده امن است؟
بله، اما با guardrails. Liquid AI توصیه میکند validation layers، output filtering، و human-in-the-loop برای critical decisions اضافه کنید. برای low-stakes tasks (FAQ bots، data extraction)، میتوانید مستقیم استفاده کنید. برای high-stakes (پزشکی، مالی)، validation اضافی لازم است.
چطور میتوانم شروع کنم؟
۳ قدم ساده: 1) یک Raspberry Pi 5 (۸GB) بخرید - حدود ۸۰ دلار، 2) مدل را از Hugging Face دانلود کنید: LiquidAI/LFM2.5-230M، 3) از llama.cpp، vLLM، یا SGLang برای اجرا استفاده کنید. راهنمای کامل در documentation رسمی Liquid AI موجود است.
آینده چیست؟ چه انتظاری باید داشت؟
Liquid AI roadmap خودش را اعلام کرده: Q3 2026 - LFM2-VL (vision + language)، Q4 2026 - مدلهای audio (speech-to-text، text-to-speech)، 2027 - مدلهای حتی کوچکتر (۱۰۰M parameters) برای microcontrollers.
منابع و مطالعه بیشتر
این مقاله بر اساس منابع زیر نوشته شده است:
- Liquid AI Official Blog: LFM2.5-230M: Built to Run Anywhere
- VentureBeat Technical Analysis: Liquid AI's smallest model yet beats models 4X its size
- Hugging Face Model Page: LiquidAI/LFM2.5-230M
- BFCLv3 Benchmark: مقایسههای مستقل توسط جامعه ML
- Raspberry Pi Community Tests: تستهای performance واقعی از کاربران
محتوای این مقاله بر اساس دادههای عمومی و benchmarkهای مستقل بازنویسی شده است. Compliance با قوانین کپیرایت رعایت شده است.
🌐با ما در ارتباط باشید 🎮✨
برای دریافت آخرین اخبار تکنولوژی، بازیها و گجتها، ما را در شبکههای اجتماعی دنبال کنید:
گالری تصاویر تکمیلی: 🚀 انقلاب Edge AI: کالبدشکافی مدل ۲۳۰ مگابایتی Liquid AI