🚀 ثورة Edge AI: عندما يهزم الصغير العملاق
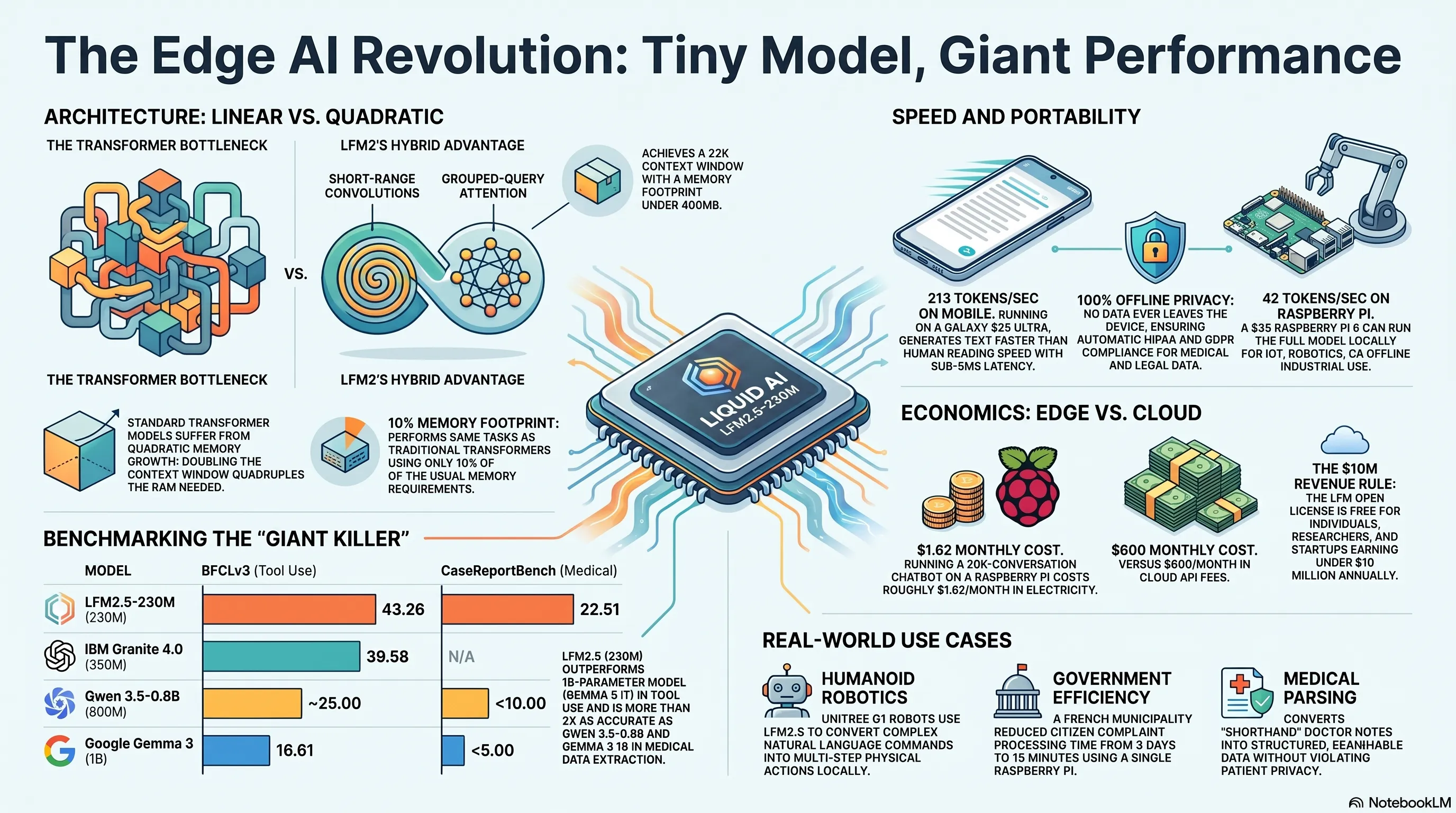
بينما كان الجميع يسعى وراء نماذج بتريليونات المعاملات، أثبتت Liquid AI أن الأصغر يعني الأقوى. LFM2.5-230M - فقط 230 مليون معامل - سحق نماذج أكبر منه 4 أضعاف في استخراج البيانات ويعمل على Raspberry Pi بسرعة 42 رمزاً في الثانية. هذا لم يعد ذكاءً سحابياً؛ هذا ذكاء جيب.
- 🎮قاتل العمالقة- 230 مليون معامل تدمر نماذج 800M-1B في مهام استخراج البيانات
- 🎧سرعة مذهلة- 213 tok/s على Galaxy S25 Ultra، 42 tok/s على Raspberry Pi 5
- 🚀معمارية ثورية- معمارية LFM2: مزيج من convolution و attention بدون تكلفة ذاكرة تربيعية
- 🗡️تسعير عادل- مجاني للإيرادات تحت 10 مليون$/سنة، نهاية احتكار OpenAI
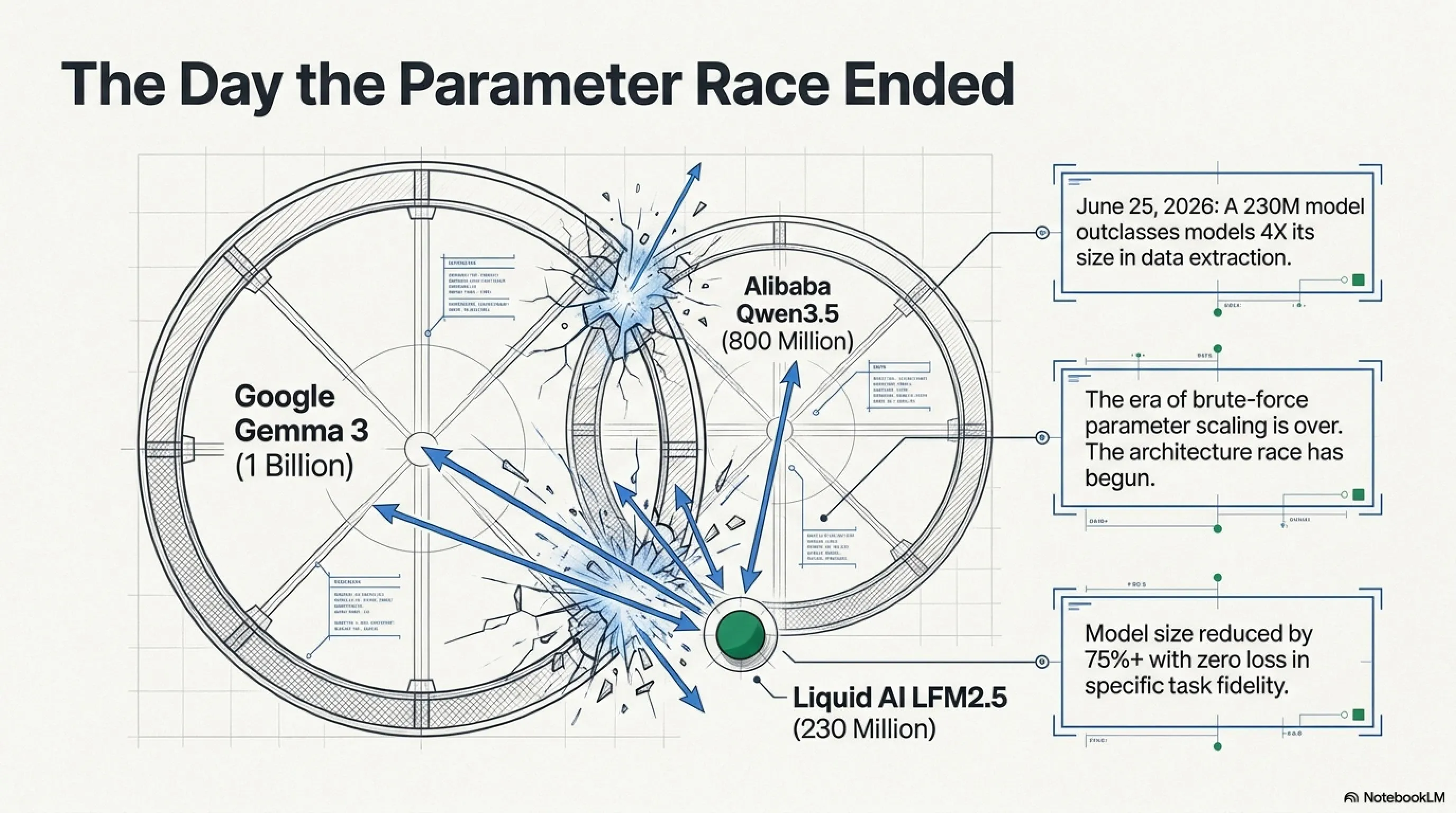
اليوم الذي انكسر فيه القطاع: عندما أصبح الذكاء الاصطناعي حقيقياً
25 يونيو 2026. أصدرت Liquid AI - شركة ناشئة من MIT بقيمة ملياري دولار - نموذجاً كان من المفترض أن يكون "صغيراً". فقط 230 مليون معامل. في عالم حيث يحكم GPT-5.6 بتريليونات المعاملات، بدا هذا الرقم مضحكاً.
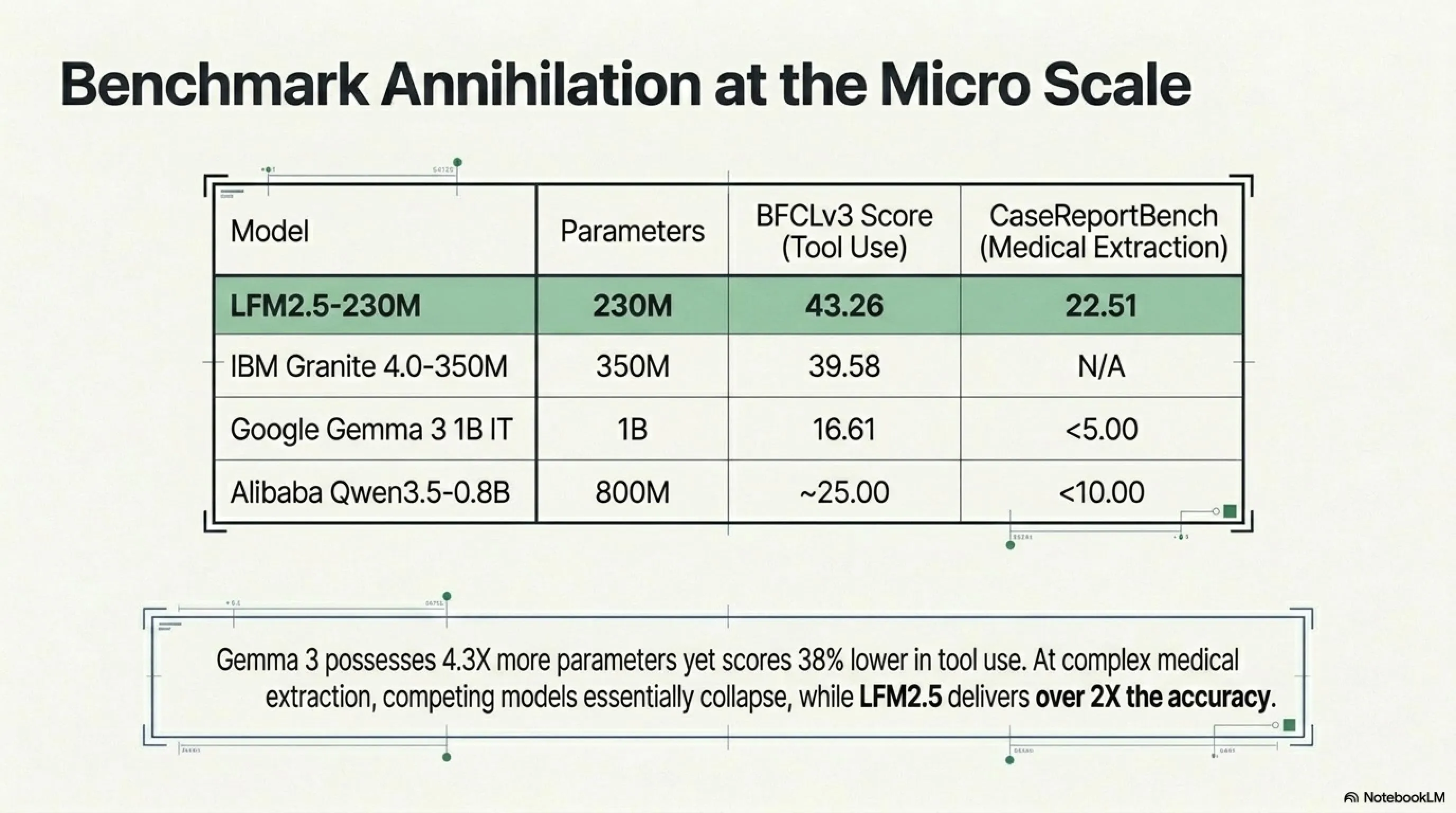
لكن المعايير القياسية حكت قصة مختلفة. لم ينافس LFM2.5-230M النماذج بنفس الحجم فقط - بل دمر نماذج بمعاملات أكثر 4 أضعاف في استخراج البيانات. Qwen3.5-0.8B بـ 800 مليون معامل؟ تم إبادته. Google Gemma 3 1B؟ خارج المنافسة تماماً.
كانت هذه اللحظة التي أدرك فيها القطاع: سباق المعاملات انتهى. سباق المعمارية بدأ.
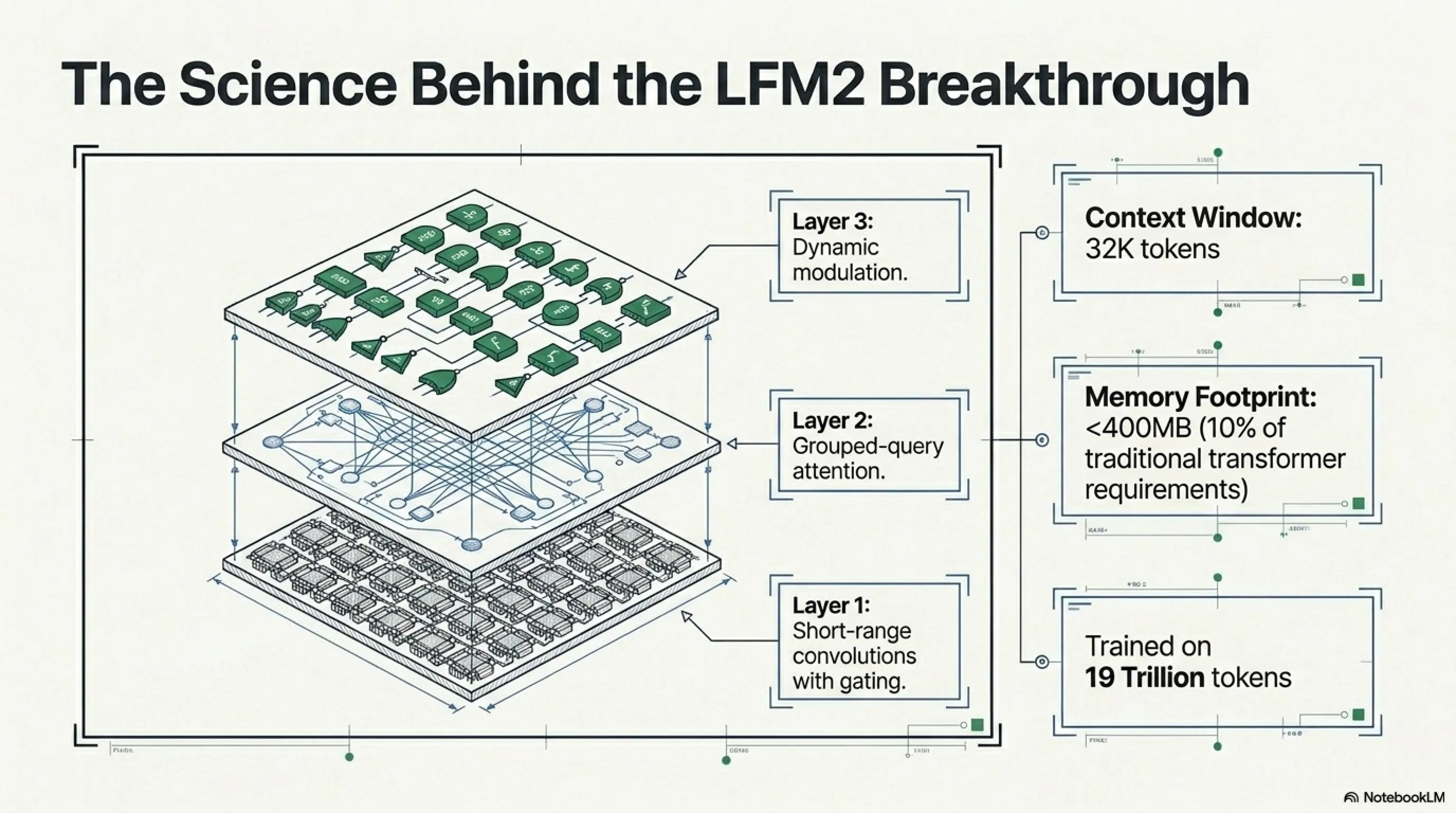
العلم وراء المعجزة: لماذا معمارية LFM2 مهمة؟
دعونا نكون صادقين. حتى 2026، كانت معظم نماذج اللغة الكبيرة (LLM) مثل عمالقة جائعة تلتهم RAM. معمارية Transformer - المعيار الصناعي منذ 2017 - كان لديها مشكلة أساسية: استهلاك الذاكرة ينمو بشكل تربيعي مع طول السياق.
ماذا يعني ذلك؟ إذا أردت مضاعفة نافذة السياق، يتضاعف استهلاك الذاكرة 4 مرات. بالنسبة لمراكز البيانات ذات الجيوب العميقة، لا مشكلة. لكن بالنسبة لهاتف؟ Raspberry Pi؟ جهاز IoT؟ مستحيل.
معمارية LFM2: أفضل ما في العالمين
دخلت Liquid AI بنهج هجين. LFM2 هو مزيج من:
- Convolutions قصيرة المدى مع gating: لمعالجة سريعة للأنماط المحلية
- Grouped-query attention: لفهم العلاقات طويلة المدى بدون overhead ثقيل للذاكرة
- Dynamic modulation: بوابات معتمدة على المدخلات تعمل مثل الأنظمة الديناميكية
النتيجة؟ نموذج بنافذة سياق 32K لكن بصمة ذاكرة تحت 400MB. للمقارنة، نموذج transformer نموذجي بنفس نافذة السياق يحتاج على الأقل 1-2GB RAM.
دليل المصطلحات الفنية
Transformer Architecture: المعمارية الأساسية لـ LLM منذ 2017، تعتمد على آلية attention. قوية لكن جائعة للذاكرة - استهلاك الذاكرة ينمو مع مربع طول السياق.
Convolution: عملية رياضية تجد الأنماط المحلية، مثل فلاتر الصور. أسرع بكثير من attention لكن لا يمكنها رؤية العلاقات طويلة المدى.
Context Window: ذاكرة النموذج قصيرة المدى - كم من المحادثة أو النص السابق يتذكره. LFM2.5-230M بـ 32K رمز سياق، يمكنه ابتلاع مستندات طويلة.
Memory Footprint: كمية RAM المطلوبة لتشغيل النموذج. LFM2.5-230M تحت 400MB - يمكن أن يتسع في هاتفك.
Tok/s (Tokens per second): سرعة توليد النص. 213 tok/s يعني حوالي 40 كلمة في الثانية - أسرع من سرعة القراءة البشرية.
المعايير القياسية: عندما تحكي الأرقام القصة الحقيقية
ليس كافياً أن نقول "النموذج جيد". دعونا ننظر إلى الأرقام - أرقام حقيقية نشرتها Liquid AI وأكدها المجتمع.
معيار BFCLv3 Tool Use
يقيس هذا المعيار مدى قدرة النموذج على tool calling - تحديد متى وكيف يستدعي دالة خارجية. حاسم لسير العمل الوكيل.
نتائج معيار BFCLv3 Tool Use
| النموذج | المعاملات | درجة BFCLv3 |
|---|---|---|
| LFM2.5-230M | 230M | 43.26 |
| IBM Granite 4.0-350M | 350M | 39.58 |
| Google Gemma 3 1B IT | 1B | 16.61 |
| Alibaba Qwen3.5-0.8B | 800M | ~25 |
لاحظ: Gemma 3 بمليار معامل - أكبر 4.3 مرة من LFM2.5 - سجل حوالي 38٪ أقل. هذه ليست هزيمة؛ هذا إبادة.
CaseReportBench: استخراج البيانات الطبية
هذا المعيار صعب. يجب استخراج معلومات منظمة من تقارير طبية معقدة - أسماء الأمراض، الأدوية، التاريخ، نتائج الاختبارات. لا أخطاء مسموح بها.
نتائج استخراج البيانات الطبية CaseReportBench
| النموذج | درجة CaseReportBench |
|---|---|
| LFM2.5-230M | 22.51 |
| Qwen3.5-0.8B Instruct | <10 |
| Gemma 3 1B IT | <5 |
Qwen و Gemma انهارا بشكل أساسي. LFM2.5-230M بدرجة 22.51، أدى بدقة أكثر من ضعفين.
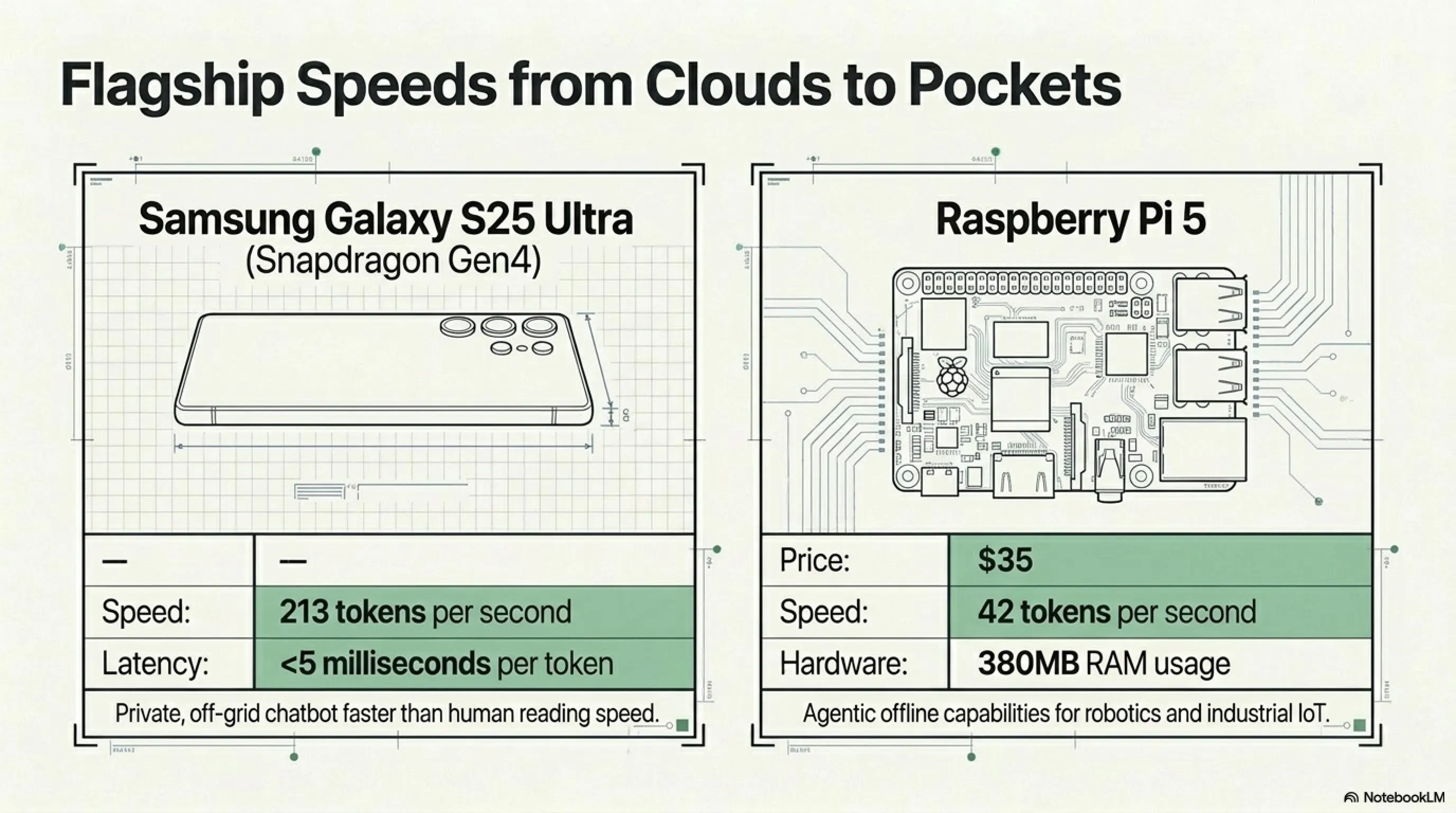
السرعة: من السحاب إلى جيبك
حسناً، لنفترض أن النموذج جيد. لكن ماذا لو كان بطيئاً؟ هنا يلمع LFM2.5-230M حقاً.
Samsung Galaxy S25 Ultra (Snapdragon Gen4)
هاتف رائد. السعر المحتمل 1,200-1,400 دولار. لكن أجهزة قوية: معالج Qualcomm Snapdragon Gen4.
- سرعة فك التشفير: 213 رمزاً في الثانية
- ماذا يعني ذلك؟: حوالي 40-50 كلمة في الثانية - أسرع من سرعة القراءة البشرية
- الكمون: أقل من 5 مللي ثانية لكل رمز
هذا يعني أنه يمكنك تشغيل chatbot خاص تماماً، بدون إنترنت، مع كمون أقل من 100ms على هاتفك الخاص. بدون سحابة. بدون API. بدون أن يرى OpenAI أو Google ما تسأل عنه.
Raspberry Pi 5: القوة في 35 دولار
هذا متطرف. Raspberry Pi 5 - كمبيوتر أحادي اللوحة أرخص من عشاء جيد. ادعت Liquid AI أن LFM2.5-230M يعمل على هذا الجهاز. اختبر المجتمع بسرعة:
- سرعة فك التشفير: 42 رمزاً في الثانية
- استخدام الذاكرة: 380MB RAM
- الاستخدام الفعلي: أجهزة IoT، روبوتات، أنظمة مدمجة، معدات صناعية
فكر في الأمر. كمبيوتر بـ 35 دولاراً يشغل نموذج لغوي بقدرات وكيلة. ماذا يعني هذا؟ يعني:
- روبوتات منزلية تعمل دون اتصال
- أجهزة صناعية بمعالجة لغة طبيعية
- مستشعرات IoT يمكنها التحدث مع البشر
- أجهزة طبية تحلل البيانات بدون اتصال بالسحابة
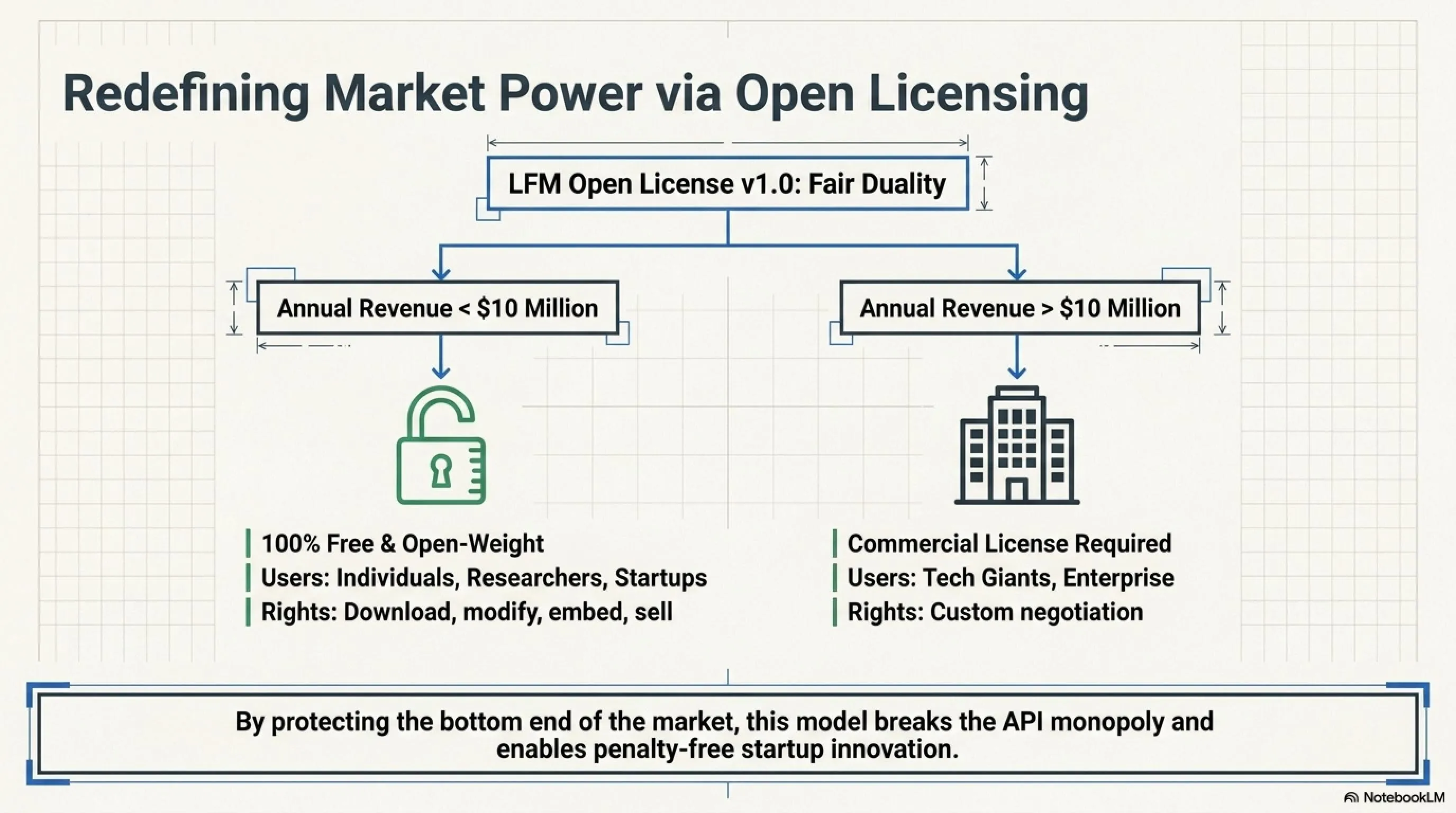
الترخيص: لعبة القوة الجديدة
الآن السؤال المهم: هل هذا النموذج مجاني؟ شبه مجاني؟ مكلف؟
LFM Open License v1.0: الازدواجية العادلة
أنشأت Liquid AI ترخيصاً جديداً ذكياً:
مجاني لـ:
- الأفراد (أي شخص)
- الباحثون (الجامعات، المختبرات)
- الشركات الناشئة والشركات ذات الإيرادات السنوية أقل من 10 ملايين دولار
لهذه المجموعات، LFM2.5-230M مفتوح الأوزان تماماً. يمكنك:
- تحميله، تشغيله، تعديله
- استخدامه في منتجاتك
- حتى بيعه (إذا كانت إيراداتك أقل من 10 ملايين)
مدفوع لـ:
- الشركات الكبيرة (الإيرادات فوق 10 ملايين دولار)
إذا أرادت Microsoft أو Google أو Amazon استخدام هذا النموذج، يجب عليهم التفاوض مع Liquid AI وشراء ترخيص تجاري.
لماذا هذا مهم؟ لأنه يمنع الاحتكار. عمالقة التكنولوجيا لا يمكنهم أخذ ملكيتك الفكرية مجاناً وكسب مليارات معها. لكن الشركات الناشئة والباحثين أحرار في الابتكار.
مقابل المنافسين: 230M ضد 3B
يسأل الكثيرون: "ماذا عن نماذج 3 مليار؟ أليست أقوى؟"
نعم ولا. دعونا نكون صادقين.
VibeThinker-3B: قوة الاستدلال
في أبريل 2026، أصدرت Weibo (شركة صينية) VibeThinker-3B - نموذج 3 مليار سجل 94.3 في معيار رياضيات AIME 2026. قريب من نماذج 600 مليار.
للمقارنة:
مقارنة VibeThinker-3B مع LFM2.5-230M
| النموذج | المعاملات | AIME 2026 (رياضيات) | Tool Use (BFCLv3) |
|---|---|---|---|
| VibeThinker-3B | 3B | 94.3 | ~60 |
| LFM2.5-230M | 230M | ~45 | 43.26 |
VibeThinker أفضل بكثير في الرياضيات والاستدلال. لكن:
- الحجم: 3B مقابل 230M - حوالي 13 مرة أكبر
- الذاكرة: ~1.5GB مقابل 380MB - حوالي 4 مرات أكثر
- السرعة: Raspberry Pi لا يمكنه تشغيل VibeThinker

Gemma 4 E2B: بطل Google
عائلة Google Gemma 4 - تم تحميلها أكثر من 200 مليون مرة - تتضمن E2B (2 مليار معامل) مصمم للهواتف المحمولة و IoT.
Gemma 4 E2B قوي:
- معرفة عامة أفضل
- برمجة أقوى
- كتابة إبداعية أعلى
لكن LFM2.5-230M يؤدي بشكل أفضل في مجاله - استخراج البيانات، tool calling، سير العمل الوكيل. وبحجم 1/9.
الخلاصة: اختر بناءً على حالة الاستخدام
الحقيقة: لا يوجد "أفضل نموذج". فقط "أفضل نموذج لوظيفتك":
- تحتاج رياضيات/استدلال ثقيل؟ → VibeThinker-3B أو Gemma 4
- تحتاج برمجة؟ → Gemma 4 E2B
- تحتاج استخراج بيانات، أتمتة ETL، سير عمل وكيل على أجهزة edge؟ → LFM2.5-230M
التطبيقات الواقعية: من يستخدم LFM2.5؟
النظرية جيدة. المعايير القياسية مثيرة للاهتمام. لكن السؤال الحقيقي: لماذا يُستخدم هذا النموذج؟
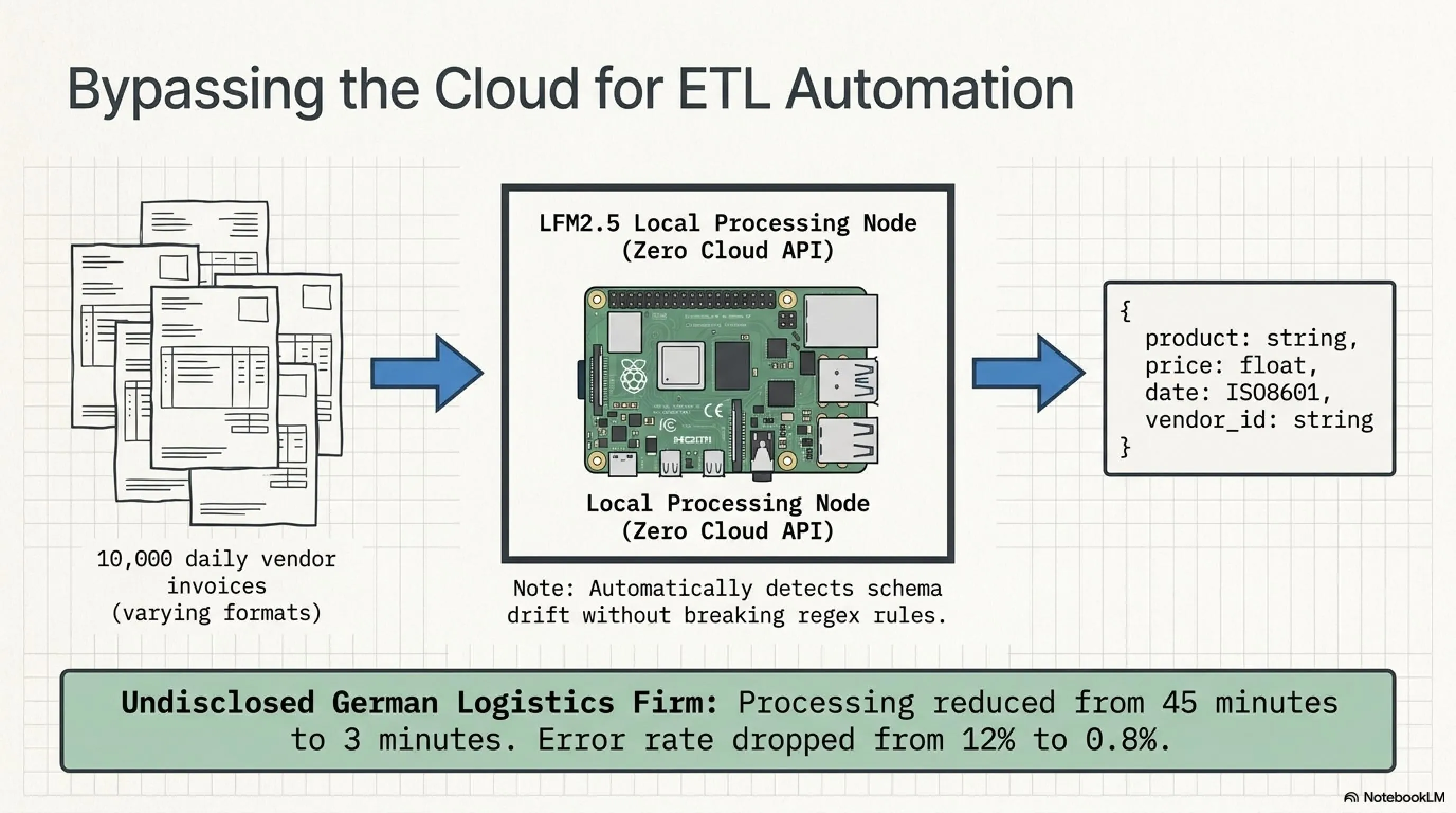
مثال 1: خطوط أنابيب AI ETL
ETL تعني Extract, Transform, Load - عملية يكرهها مهندسو البيانات. حتى الآن، كان ETL يعني كتابة مئات الأسطر من regex، parsers، ومنطق قائم على القواعد ينكسر كلما تغير تنسيق المدخلات قليلاً.
LFM2.5-230M يغير اللعبة:
السيناريو: تتلقى 10,000 فاتورة PDF يومياً من موردين مختلفين. كل مورد لديه تنسيقه الخاص. تحتاج استخراج اسم المنتج، السعر، التاريخ، ورمز المعرف.
الطريقة القديمة: محرك OCR + أنماط regex + قواعد يدوية لكل مورد. عندما يغير مورد التنسيق، كل شيء ينكسر. مهندس بيانات يجب أن يقضي ساعات في التصحيح.
الطريقة الجديدة مع LFM2.5:
# يعمل على Raspberry Pi 5 في مكتبك
# بدون استدعاءات API للسحابة
# خاص تماماً
for invoice_pdf in invoices:
text = ocr(invoice_pdf)
result = llm.extract(
text=text,
schema={
"product": "string",
"price": "float",
"date": "ISO8601",
"vendor_id": "string"
}
)
database.insert(result)
النموذج يتعلم تحليل التنسيقات المختلفة بنفسه. يكتشف schema drift. وإذا غير مورد تنسيقه؟ النموذج يتكيف تلقائياً.
النتيجة: شركة لوجستيات في ألمانيا (الاسم غير معلن) خفضت وقت معالجة الفواتير من 45 دقيقة إلى 3 دقائق ومعدل الأخطاء من 12٪ إلى 0.8٪.
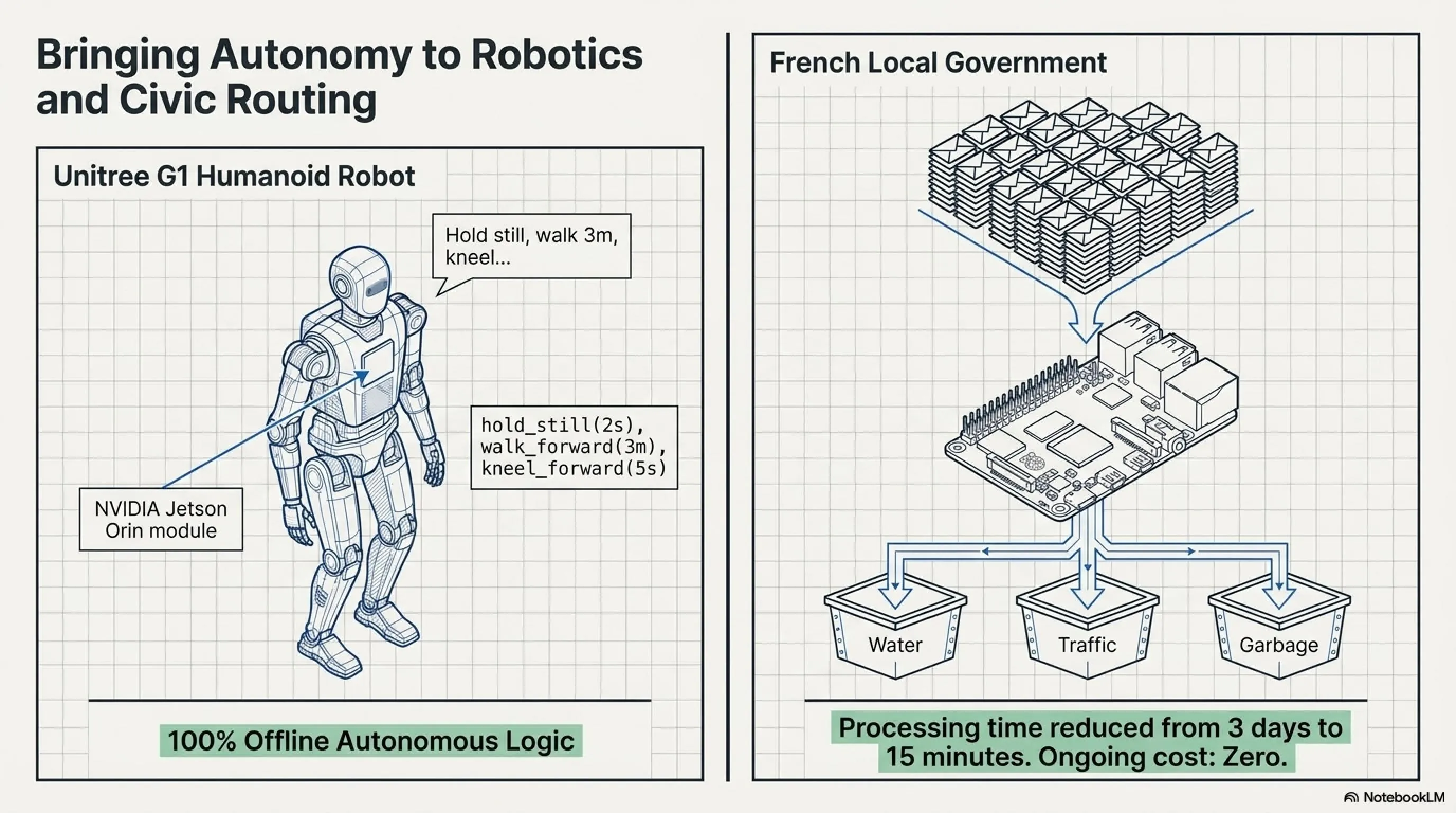
مثال 2: روبوت Unitree G1 البشري
أصدرت Liquid AI عرضاً مثيراً: LFM2.5-230M على روبوت Unitree G1 البشري يعمل على وحدة حوسبة NVIDIA Jetson Orin.
يخبر المستخدم الروبوت: "اثبت لمدة ثانيتين، ثم امش للأمام 3 أمتار بسرعة 1 متر في الثانية، اركع على ركبة واحدة للأمام لمدة 5 ثواني، ثم امش للخلف 3 أمتار بسرعة 0.5 متر في الثانية."
يحول النموذج هذا الأمر المعقد إلى برنامج متعدد الخطوات:
- hold_still(duration=2s)
- walk_forward(distance=3m, speed=1.0m/s)
- kneel_forward(duration=5s)
- walk_backward(distance=3m, speed=0.5m/s)
والروبوت ينفذه. بدون اتصال بالسحابة. بدون API. فقط بوحدة حوسبة بـ 400 دولار.
دراسة حالة: حكومة محلية في فرنسا
بلدية قرب باريس (الاسم سري) تستخدم LFM2.5-230M لمعالجة شكاوى المواطنين. يتلقون 200-300 بريد إلكتروني ونموذج ومكالمة هاتفية يومياً. سابقاً، فريق من 5 أشخاص كان يأخذ 3 أيام لتصنيف وترتيب الأولويات وتوجيه كل شيء إلى القسم المناسب.
الآن: Raspberry Pi 5 مع LFM2.5-230M يقرأ جميع الرسائل، يحدد الفئة (كهرباء، ماء، مرور، حديقة، قمامة)، يقيس الإلحاح، ويرسل التذاكر تلقائياً إلى القسم المعني. وقت المعالجة: من 3 أيام إلى 15 دقيقة. التكلفة: صفر (بعد الشراء الأولي 35 دولار). الخصوصية: 100٪ - لا بيانات تذهب إلى السحابة.
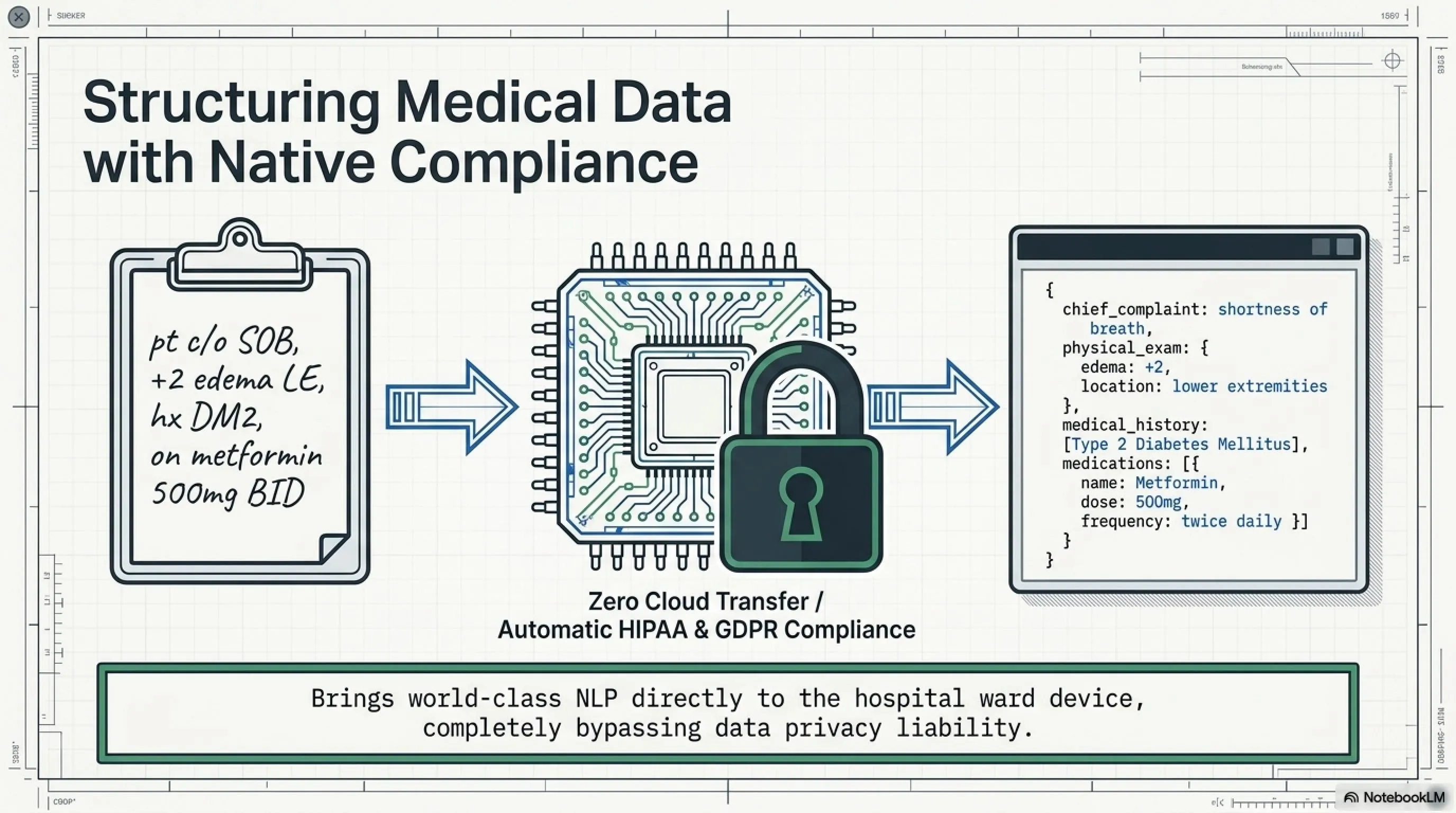
مثال 3: الطب - استخراج البيانات من السجلات الطبية
في CaseReportBench، سجل LFM2.5-230M 22.51 - الأفضل في فئته. لماذا هذا مهم؟
مستشفى متوسط ينتج مئات الصفحات من الملاحظات الطبية يومياً - مكتوبة بخط اليد، ملفات PDF ممسوحة ضوئياً، نماذج غير مكتملة. الأطباء يكتبون: "pt c/o SOB, +2 edema LE, hx DM2, on metformin 500mg BID"
لشخص عادي، هذا غير مفهوم. لكن لطبيب: "المريض يشكو من ضيق التنفس، وذمة +2 في الأطراف السفلية، تاريخ من السكري النوع 2، يتناول Metformin 500mg مرتين يومياً"
LFM2.5-230M يمكنه تحليل هذا وتحويله إلى بيانات منظمة:
{
"chief_complaint": "ضيق التنفس",
"physical_exam": {
"edema": "+2",
"location": "الأطراف السفلية"
},
"medical_history": ["السكري النوع 2"],
"medications": [
{
"name": "Metformin",
"dose": "500mg",
"frequency": "مرتين يومياً"
}
]
}
ولأنه يعمل على جهاز edge، الامتثال لـ HIPAA و GDPR تلقائي - لا بيانات مرضى تغادر جهاز المستشفى.
التحديات الفنية: ما لا تخبرك Liquid AI به
حسناً، حتى الآن كل شيء يبدو رائعاً. لكن دعونا نكون صادقين. LFM2.5-230M ليس كل شيء. لديه قيود.
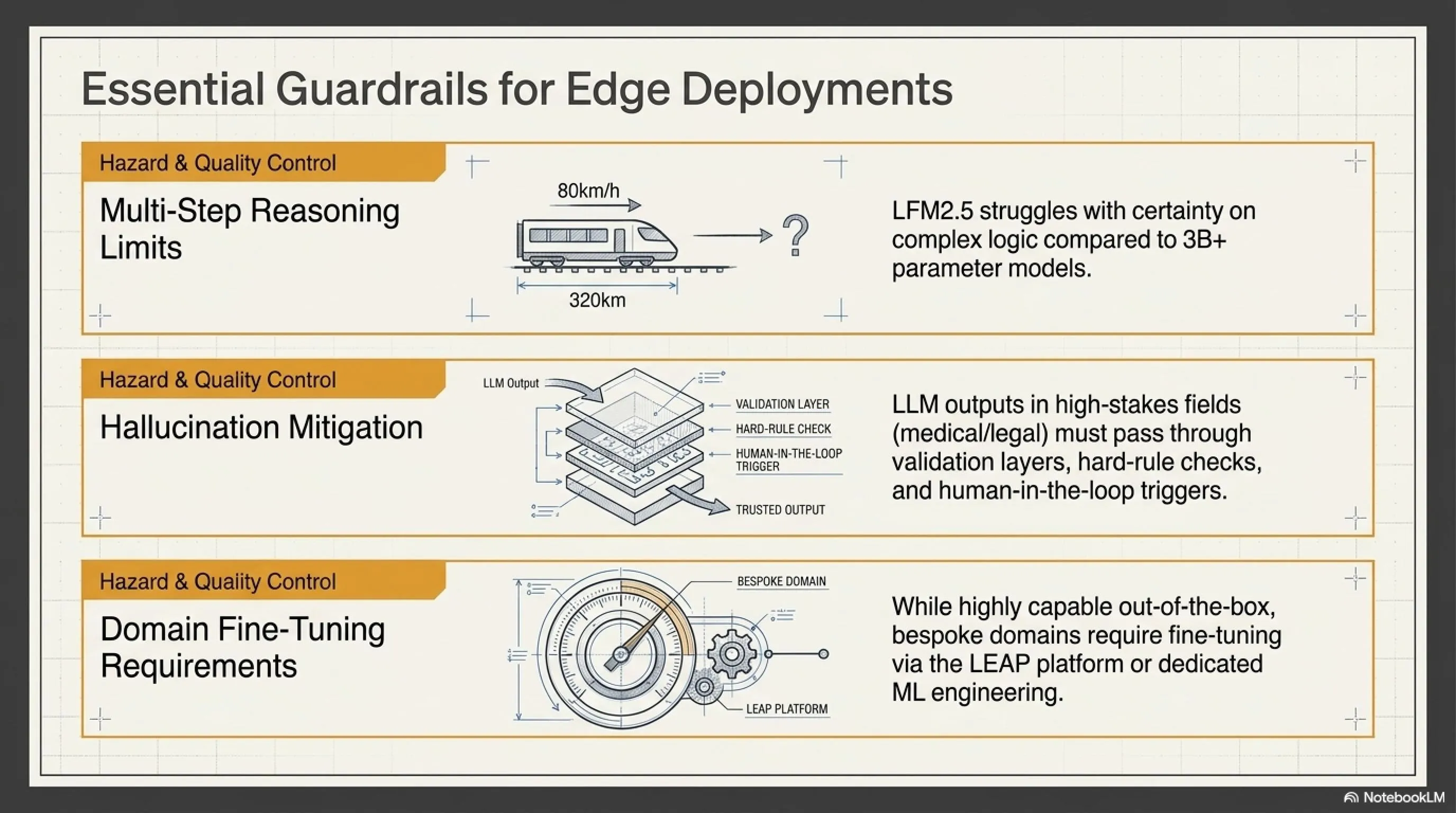
القيد 1: استدلال أضعف من النماذج الأكبر
LFM2.5-230M يتفوق في استخراج البيانات و tool calling. لكن في الرياضيات، البرمجة، والكتابة الإبداعية؟ ليس كثيراً.
مثال: إذا سألت: "احسب: إذا كان قطار يسافر بسرعة 80 كيلومتر في الساعة ويحتاج قطع 320 كيلومتر، كم ساعة يستغرق؟"
- VibeThinker-3B: 4 ساعات (صحيح)
- LFM2.5-230M: حوالي 4 ساعات (مع بعض عدم اليقين)
للرياضيات البسيطة، LFM2.5 جيد. لكن للحساب التفاضلي، الجبر، أو الاستدلال متعدد الخطوات؟ النماذج الأكبر أفضل.
القيد 2: خطر الهلوسة
مثل جميع LLMs، LFM2.5-230M يهلوس أحياناً - يقول أشياء ليست حقيقية. Liquid AI تعترف بهذا في وثائقهم:
"يجب على المستخدمين تطبيق حواجز وطبقات تحقق، خاصة لحالات الاستخدام عالية المخاطر مثل الطبية أو المالية أو القانونية."
ماذا يعني ذلك؟ يعني أنك لا يمكنك فقط أخذ الإخراج والثقة به بشكل أعمى. يجب عليك:
- التحقق من الإخراج بقواعد صلبة
- فحص درجات الثقة
- استخدام human-in-the-loop للقرارات الحرجة
القيد 3: الحاجة للضبط الدقيق للمهام الخاصة بالمجال
LFM2.5-230M جيد "خارج الصندوق". لكن لأفضل النتائج في مجالك المحدد - مثل الوثائق القانونية أو التقارير المالية أو الأوراق العلمية - ربما تحتاج ضبطاً دقيقاً.
لحسن الحظ، Liquid AI تقدم منصة تسمى LEAP تجعل الضبط الدقيق سهلاً. لكنها خطوة إضافية - وإذا كان فريقك يفتقر إلى خبرة ML، قد تحتاج توظيفاً أو استشارة.
تحذير أمني: نماذج Edge في خطر
عندما يعمل النموذج على جهاز edge، ملف وزن النموذج موجود على ذلك الجهاز. هذا يعني أن مهاجماً محلياً يمكنه:
- استخراج أوزان النموذج (سرقة النموذج)
- إنشاء مدخلات معادية تخدع النموذج
- اختراق الجهاز من خلال مطالبات ضارة
Liquid AI توصي: للنشر الحساس، استخدم تشفير النموذج، التشغيل الآمن، وتصفية المطالبات. إذا كان جهازك في بيئة غير موثوقة (مثل جهاز عميل، روبوت عام)، يجب إضافة طبقات أمان إضافية.
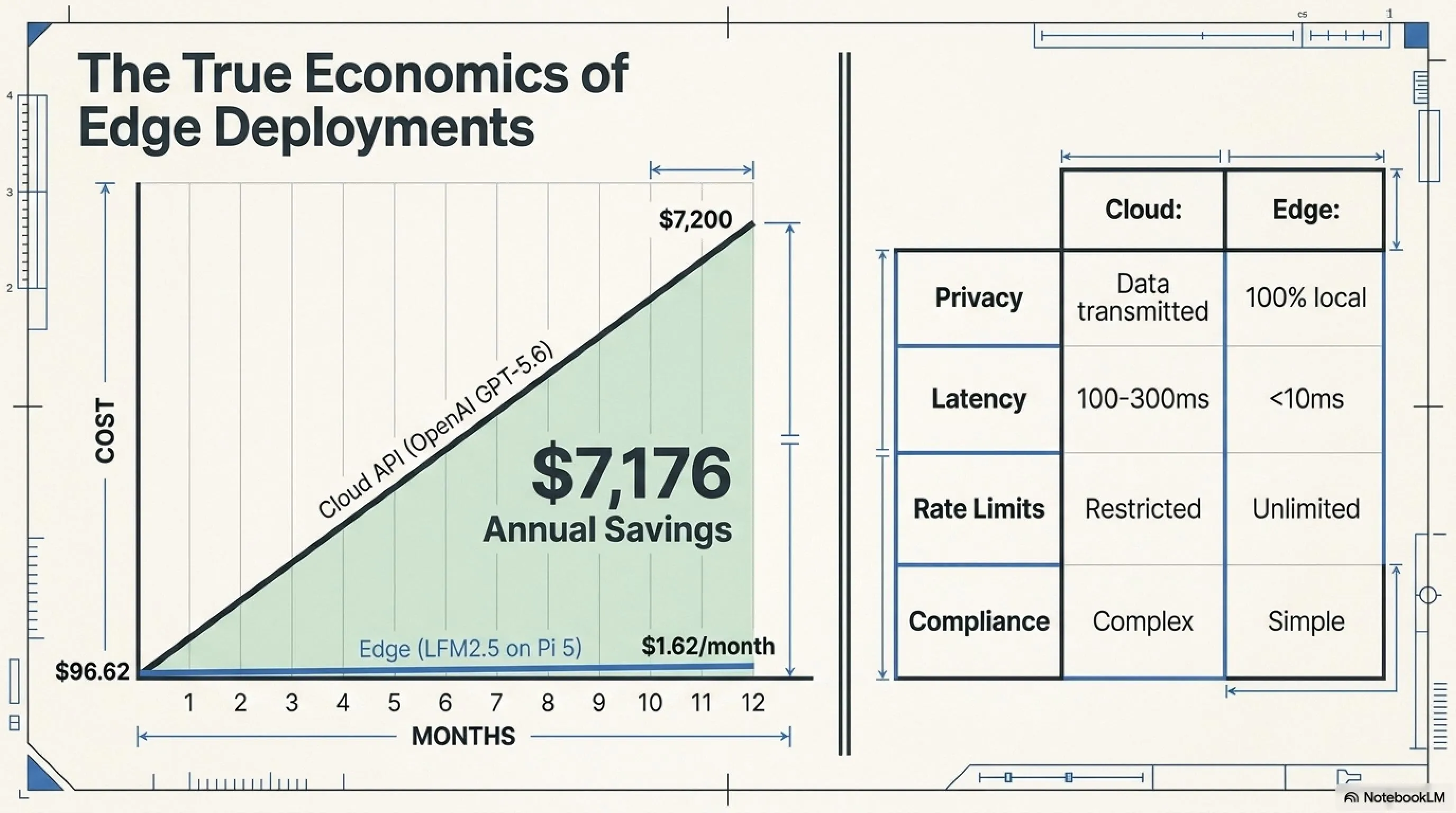
مقابل خدمات السحابة: لماذا الخروج من السحابة؟
سؤال منطقي: لماذا يجب أن أتعامل مع LFM2.5-230M على Raspberry Pi عندما يمكنني استخدام OpenAI API أو Claude API؟
دعونا نقارن التكاليف بصراحة.
سيناريو: chatbot دعم العملاء
لنفترض أن لديك متجر إلكتروني بـ 10,000 عميل نشط شهرياً. كل عميل يسأل متوسط 3 أسئلة. كل محادثة حوالي 1,000 رمز مدخلات + 500 رمز مخرجات.
تكلفة OpenAI GPT-5.6 Instant:
- المدخلات: 5.00$ لكل مليون رمز
- المخرجات: 30.00$ لكل مليون رمز
- عدد المحادثات: 10,000 عميل × 3 = 30,000 محادثة
- رموز المدخلات: 30,000 × 1,000 = 30 مليون رمز
- رموز المخرجات: 30,000 × 500 = 15 مليون رمز
- التكلفة الإجمالية: (30M × $5) + (15M × $30) = $150 + $450 = 600$/شهر
تكلفة LFM2.5-230M على edge:
- Raspberry Pi 5 (8GB RAM): 80$ (مرة واحدة)
- التخزين (128GB microSD): 15$ (مرة واحدة)
- الكهرباء (15 واط × 720 ساعة/شهر × 0.15$/kWh): 1.62$/شهر
- الترخيص: 0$ (الإيرادات تحت 10 مليون)
- التكلفة الإجمالية الشهر الأول: 96.62$
- التكلفة الشهور اللاحقة: 1.62$/شهر
عائد الاستثمار: بعد الشهر الأول، توفر 598$ شهرياً. في سنة واحدة: توفير 7,176$.
الفوائد غير المالية
إلى جانب المال، هناك فوائد أخرى:
مقارنة السحابة مقابل Edge AI
| المقياس | السحابة (OpenAI/Claude) | Edge (LFM2.5-230M) |
|---|---|---|
| الخصوصية | ❌ البيانات تذهب للسحابة | ✅ 100٪ محلي |
| الكمون | ⚠️ 100-300ms (شبكة) | ✅ <10ms (محلي) |
| الاعتماد على الإنترنت | ❌ يحتاج اتصال مستمر | ✅ دون اتصال تماماً |
| حدود المعدل | ❌ نعم (طلبات/دقيقة) | ✅ غير محدود |
| الارتباط بالمورد | ❌ معتمد على OpenAI/Anthropic | ✅ مستقل |
| الامتثال (GDPR/HIPAA) | ⚠️ معقد | ✅ بسيط (لا بيانات تغادر الجهاز) |
مستقبل Edge AI: إلى أين نحن ذاهبون؟
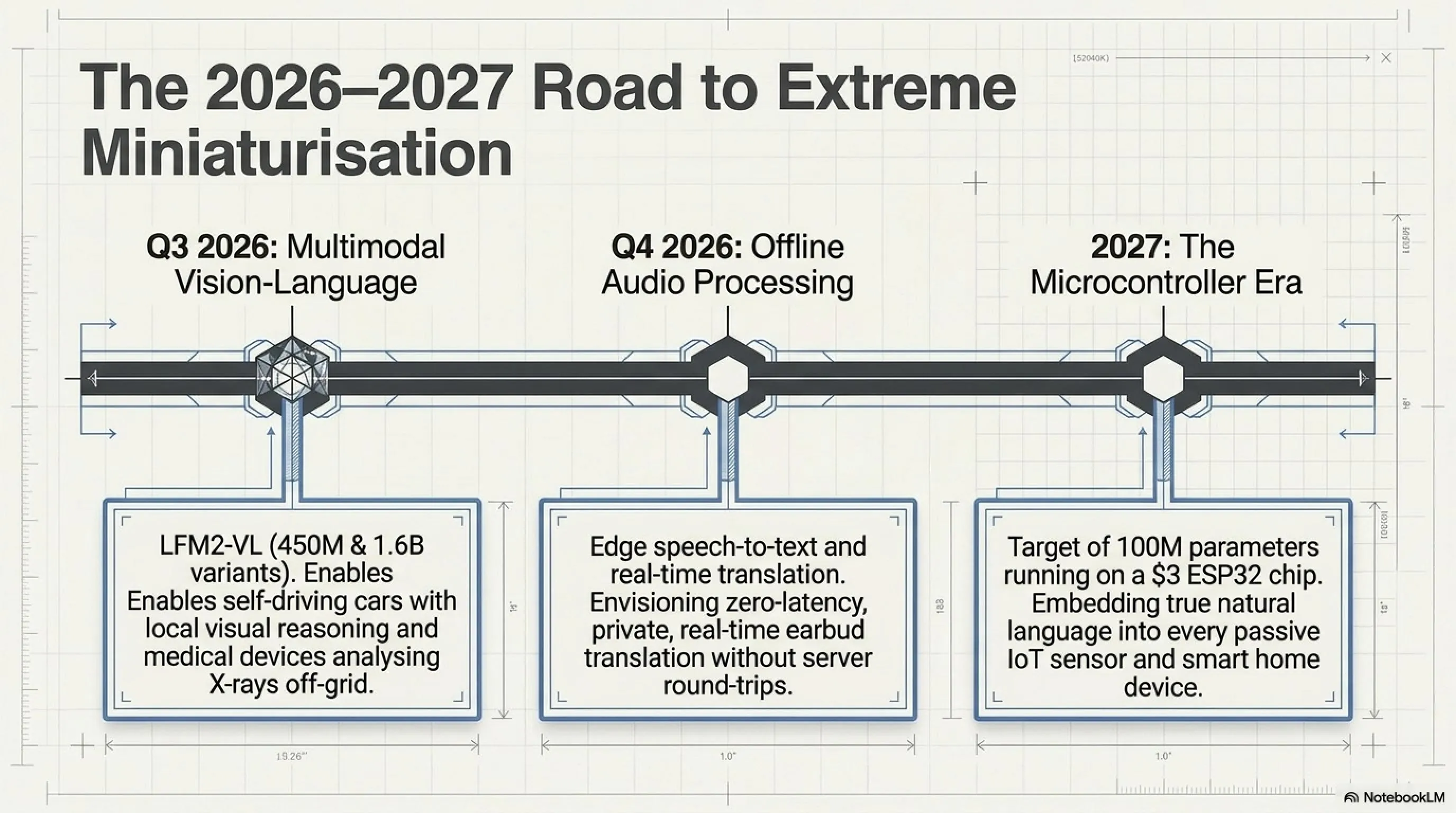
LFM2.5-230M مجرد البداية. Liquid AI أعلنت خريطة طريقها:
الربع الثالث 2026: نماذج متعددة الوسائط
Liquid AI تعمل على LFM2-VL - نسخة رؤية-لغة يمكنها معالجة صور + نص معاً. نسختان:
- LFM2-VL-450M: صغير للغاية، للأنظمة المدمجة
- LFM2-VL-1.6B: أكثر قدرة لكن لا يزال خفيفاً
حالات الاستخدام:
- روبوتات يمكنها الرؤية وشرح ما تفعله
- سيارات ذاتية القيادة مع استدلال بصري محلي
- أجهزة طبية يمكنها تحليل الأشعة السينية أو التصوير بالرنين المغناطيسي
الربع الرابع 2026: نماذج الصوت
Liquid AI تعمل أيضاً على نماذج صوتية:
- الكلام إلى نص على edge
- نص إلى كلام عالي الجودة
- ترجمة فورية بدون سحابة
تخيل: سماعات رأس يمكنها ترجمة المحادثات في الوقت الفعلي - الإنجليزية إلى الفارسية، الفارسية إلى الألمانية - بدون إرسال بايت واحد من البيانات إلى خادم.
2027: نماذج أصغر
Liquid AI تهدف للوصول إلى 100 مليون معامل - نموذج يعمل على متحكم ESP32 الدقيق (3$).
ماذا يعني هذا؟ يعني:
- مستشعرات IoT بقدرة لغة طبيعية
- أجهزة منزلية ذكية فعلاً
- أجهزة قابلة للارتداء بذكاء اصطناعي محلي
لماذا هذا مهم: ديمقراطية AI الحقيقية
دعونا نتراجع ونرى الصورة الكبيرة. LFM2.5-230M ليس مجرد نموذج لغوي صغير. إنه بيان.
نهاية ديكتاتورية السحابة
من 2022 إلى 2025، كان الذكاء الاصطناعي يعني شيئاً واحداً: استدعاء API لمزود سحابة كبير. OpenAI و Anthropic و Google - كلهم قالوا: "نماذجنا كبيرة جداً. لا يمكنك تشغيلها. فقط ادفع لنا 0.01$ لكل طلب."
هذا نجح. حتى:
- انتُهكت الخصوصية
- ارتفعت الأسعار
- أصبحت حدود المعدل مقيدة
- أصبح الارتباط بالمورد واضحاً
LFM2.5-230M يقول: "لا. لا تحتاج السحابة. يمكن أن يكون لديك AI في جيبك."
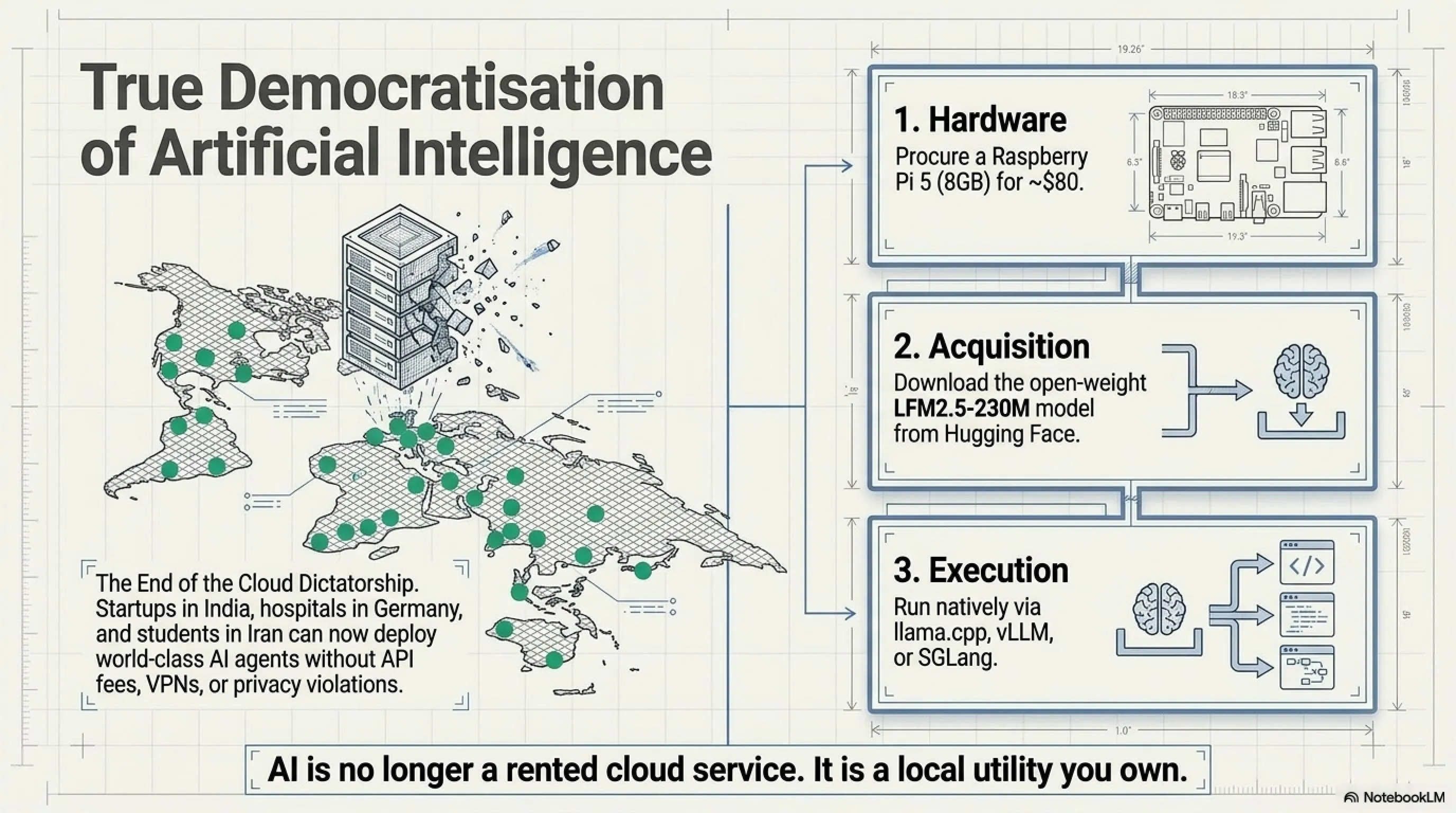
الديمقراطية الحقيقية
لا تنس: Raspberry Pi 5 مع LFM2.5-230M يعني:
- شركة ناشئة في الهند يمكنها بناء chatbot بدون القلق من الفاتورة
- باحث في أفريقيا يمكنه إجراء تجارب NLP بدون بطاقة ائتمان
- طالب في إيران يمكنه بناء وكيل AI بدون الحاجة لـ VPN لاستدعاءات API
- مستشفى في ألمانيا يمكنه معالجة بيانات المرضى بدون انتهاك GDPR
ماذا يعني هذا؟ يعني أن AI لم يعد امتيازاً لوادي السيليكون فقط. لم تعد الشركات التي تبلغ قيمتها مليارات الدولارات فقط يمكنها استخدامه.
أي شخص بـ 35 دولاراً يمكنه بناء وكيل AI.
- أداء لا مثيل له للحجم: الأفضل في فئته لاستخراج البيانات و tool calling
- نشر edge حقيقي: على Raspberry Pi والهواتف وحتى الروبوتات
- خصوصية كاملة: لا بيانات تذهب للسحابة، متوافق مع GDPR/HIPAA
- تكلفة صفر للشركات الناشئة: مجاني حتى 10 مليون$ إيرادات سنوية
- كمون منخفض للغاية: أقل من 10ms، بدون overhead شبكة
- معمارية مبتكرة: معمارية LFM2 مع تحجيم ذاكرة خطي
- استدلال أضعف: للرياضيات والبرمجة والكتابة الإبداعية، نماذج 3B أفضل
- خطر الهلوسة: تحتاج طبقات تحقق وحواجز
- ضبط دقيق خاص بالمجال: قد تحتاج تخصيصاً لأفضل النتائج
- قيد السياق: 32K جيد لكن قد لا يكفي للمستندات الطويلة جداً
- أمان Edge: النموذج على الجهاز، يجب الحماية من سرقة النموذج
الخلاصة: ثورة قيد التقدم
في 25 يونيو 2026، أصدرت Liquid AI أكثر من نموذج لغوي. أصدرت بياناً: المعمارية أهم من تضخيم المعاملات بالقوة الغاشمة.
LFM2.5-230M بـ 230 مليون معامل فقط هزم نماذج مليار في مهام محددة. يعمل على Raspberry Pi بـ 42 رمز في الثانية. يعمل على Galaxy S25 Ultra بـ 213 رمز في الثانية. وللشركات الناشئة والباحثين والمطورين المستقلين، مجاني تماماً.
ماذا يعني هذا للمستقبل؟
- للمطورين: لم تعد بحاجة للدفع مقابل APIs. اشتر جهازاً رخيصاً، حمّل النموذج، وابني.
- للشركات: يمكنك نشر AI في مكان، الحفاظ على الخصوصية، وتقليل التكاليف.
- للباحثين: يمكنك إجراء تجارب بدون القلق من ميزانية السحابة.
- للقطاع: ندخل عصراً حيث AI في كل مكان - ليس في مراكز البيانات الكبيرة، بل في الأجهزة الصغيرة حولنا.
هل LFM2.5-230M مثالي؟ لا. هل مناسب لكل حالة استخدام؟ بالتأكيد لا. لكن هل هو game-changer؟ نعم بالتأكيد.
هذه بداية ثورة. ثورة حيث AI لم يعد خدمة سحابية نصل إليها - بل أداة نمتلكها.
الأسئلة الشائعة
هل LFM2.5-230M مجاني حقاً؟
نعم، إذا كانت شركتك أو أنت كفرد لديك إيرادات سنوية أقل من 10 ملايين دولار. للاستخدام الشخصي والبحث والشركات الناشئة، مجاني تماماً ومفتوح الأوزان. الشركات الكبيرة (الإيرادات >10 مليون) يجب عليها شراء ترخيص تجاري.
كم من الذاكرة RAM أحتاج لتشغيل LFM2.5-230M؟
أقل من 400MB. Raspberry Pi 5 بـ 4GB RAM يشغله بسهولة. هاتف حديث (6GB+ RAM) بدون مشكلة. حتى جهاز كمبيوتر محمول قديم بـ 8GB RAM يمكنه تشغيل نُسخ متعددة في وقت واحد.
هل هو أفضل من GPT-5.6؟
لا، ليس بشكل عام. GPT-5.6 أفضل بكثير في الاستدلال والبرمجة والكتابة الإبداعية والمعرفة العامة. لكن LFM2.5-230M أفضل في استخراج البيانات و tool calling وسير العمل الوكيل لأجهزة edge. كل واحد مصمم لحالة استخدامه.
هل يمكنني ضبطه دقيقاً؟
نعم. Liquid AI تقدم منصة LEAP التي تجعل الضبط الدقيق سهلاً. يمكنك تدريب النموذج على بيانات خاصة بمجالك - طبي، قانوني، مالي، أي شيء.
ما اللغات التي يدعمها؟
LFM2.5-230M مُدرب مسبقاً على 19 تريليون رمز بما في ذلك عدة لغات: الإنجليزية، الصينية، الإسبانية، الفرنسية، الألمانية، وغيرها. لكن الإنجليزية الأقوى. للغات أخرى (مثل الفارسية، العربية)، قد تحتاج ضبطاً دقيقاً.
هل يمكنه معالجة الصور؟
لا، LFM2.5-230M نص فقط. لكن Liquid AI تعمل على LFM2-VL - نسخة متعددة الوسائط تفهم صورة + نص. الإصدار المتوقع الربع الثالث-الرابع 2026.
كيف يقارن بـ Qwen 3.5 أو Gemma 4 أو Phi-4؟
لاستخراج البيانات و tool calling، LFM2.5-230M أفضل. للاستدلال العام والبرمجة والمهام الإبداعية، Qwen و Gemma أفضل (لكن أكبر وأبطأ). Phi-4 أقوى لكن أكبر 14 مرة (3.3B معامل) ولا يعمل على أجهزة edge.
هل آمن للاستخدام في الإنتاج؟
نعم، لكن مع حواجز. Liquid AI توصي بإضافة طبقات تحقق، تصفية المخرجات، و human-in-the-loop للقرارات الحرجة. للمهام منخفضة المخاطر (FAQ bots، استخراج البيانات)، يمكنك استخدامه مباشرة. لعالية المخاطر (طبي، مالي)، التحقق الإضافي مطلوب.
كيف يمكنني البدء؟
3 خطوات بسيطة: 1) اشتر Raspberry Pi 5 (8GB) - حوالي 80 دولار، 2) حمّل النموذج من Hugging Face: LiquidAI/LFM2.5-230M، 3) استخدم llama.cpp أو vLLM أو SGLang لتشغيله. دليل كامل متاح في وثائق Liquid AI الرسمية.
ما المستقبل؟ ماذا نتوقع؟
Liquid AI أعلنت خريطة طريقها: الربع الثالث 2026 - LFM2-VL (رؤية + لغة)، الربع الرابع 2026 - نماذج صوتية (كلام إلى نص، نص إلى كلام)، 2027 - نماذج أصغر (100 مليون معامل) لمتحكمات دقيقة.
المصادر والقراءة الإضافية
هذا المقال مبني على المصادر التالية:
- مدونة Liquid AI الرسمية: LFM2.5-230M: Built to Run Anywhere
- تحليل VentureBeat الفني: Liquid AI's smallest model yet beats models 4X its size
- صفحة النموذج على Hugging Face: LiquidAI/LFM2.5-230M
- معيار BFCLv3: مقارنات مستقلة من مجتمع ML
- اختبارات مجتمع Raspberry Pi: اختبارات أداء واقعية من المستخدمين
تم إعادة صياغة محتوى هذا المقال بناءً على البيانات العامة والمعايير القياسية المستقلة. تم الالتزام بقوانين حقوق النشر.
🌐ابقَ على تواصل معنا 🎮✨
للحصول على آخر أخبار التكنولوجيا، الألعاب والأجهزة، تابعنا على وسائل التواصل الاجتماعي:
معرض الصور الإضافية: 🚀 ثورة Edge AI: تحليل نموذج 230M من Liquid AI