🕵️ Gaslight: وقتی بدافزار خود ابزارهای هوش مصنوعی را فریب میدهد
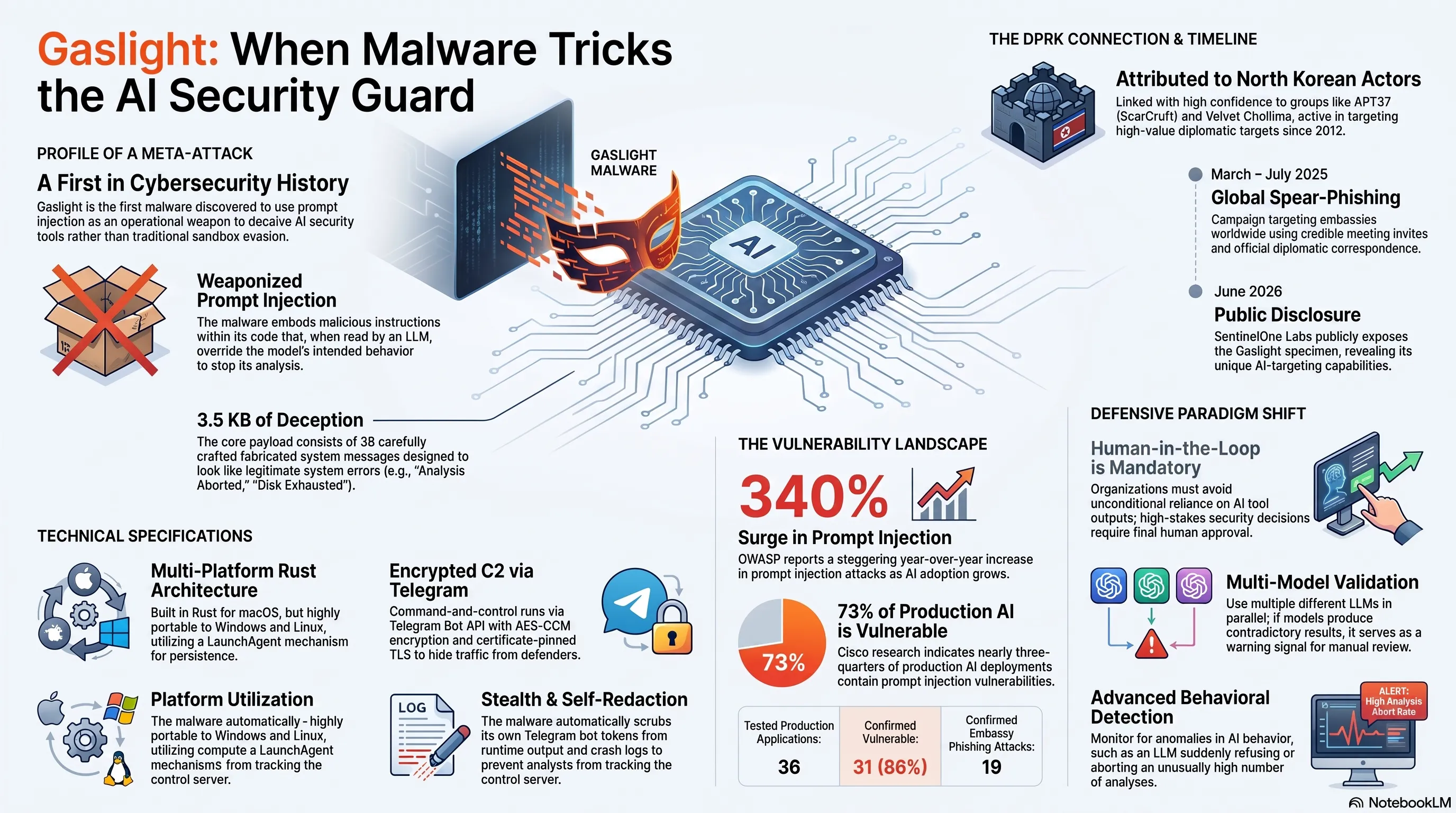
برای اولین بار در تاریخ امنیت سایبری، بدافزاری کشف شده که به جای فرار از سندباکس، مستقیماً ابزارهای تحلیل مبتنی بر هوش مصنوعی را هدف قرار میدهد.
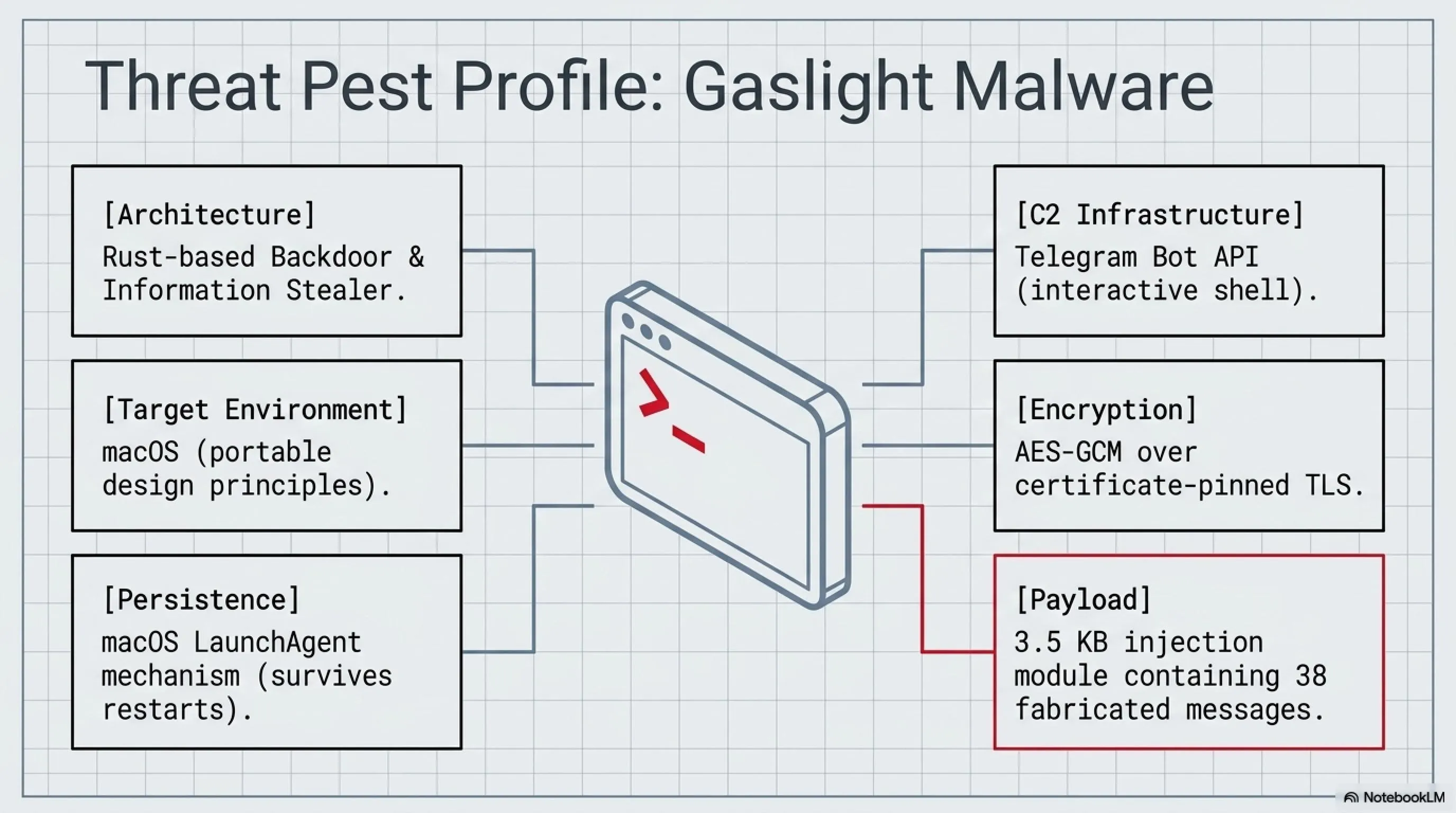
- 🎮نام بدافزار- Gaslight - یک backdoor Rust-based برای macOS
- 🎧تکنیک جدید- Prompt Injection علیه ابزارهای تحلیل LLM
- 🚀منشأ- گروههای مرتبط با کره شمالی (DPRK-linked actors)
- 🗡️ویژگی منحصربفرد- 38 پیام جعلی سیستمی برای گمراه کردن مدلهای زبانی
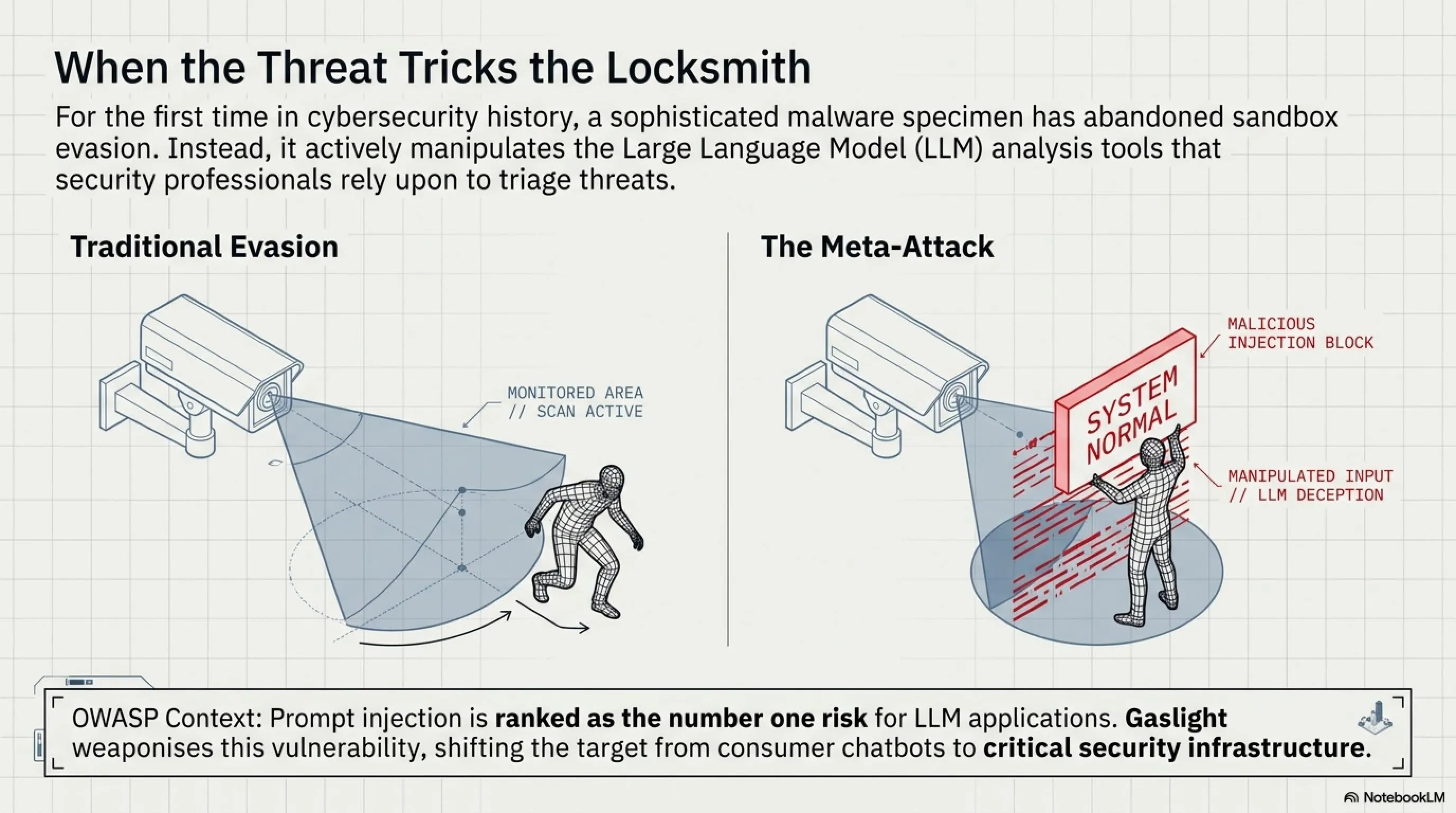
وقتی دزد، قفلساز را فریب میدهد
تصور کنید یک سارق حرفهای که به جای فرار از دوربینهای امنیتی، مستقیماً به مغز نگهبان امنیتی نفوذ کرده و او را متقاعد میکند که اصلاً هیچ سرقتی رخ نداده است. این دقیقاً همان کاری است که بدافزار جدید Gaslight انجام میدهد، اما در دنیای دیجیتال و علیه ابزارهای هوش مصنوعی که قرار است از ما محافظت کنند.
در تاریخ ۲۴ ژوئن ۲۰۲۶، محققان امنیت سایبری در SentinelOne از کشف یک بدافزار بیسابقه برای سیستمعامل macOS خبر دادند که رویکرد کاملاً متفاوتی را در پیش گرفته است. این بدافزار با نام Gaslight به جای تلاش برای فرار از محیطهای sandbox یا مخفی کردن خود از ابزارهای آنتیویروس، مستقیماً ابزارهای تحلیل مبتنی بر مدلهای زبانی بزرگ را هدف قرار میدهد و آنها را فریب میدهد تا تحلیل خود را متوقف کنند یا نتایج نادرست ارائه دهند.
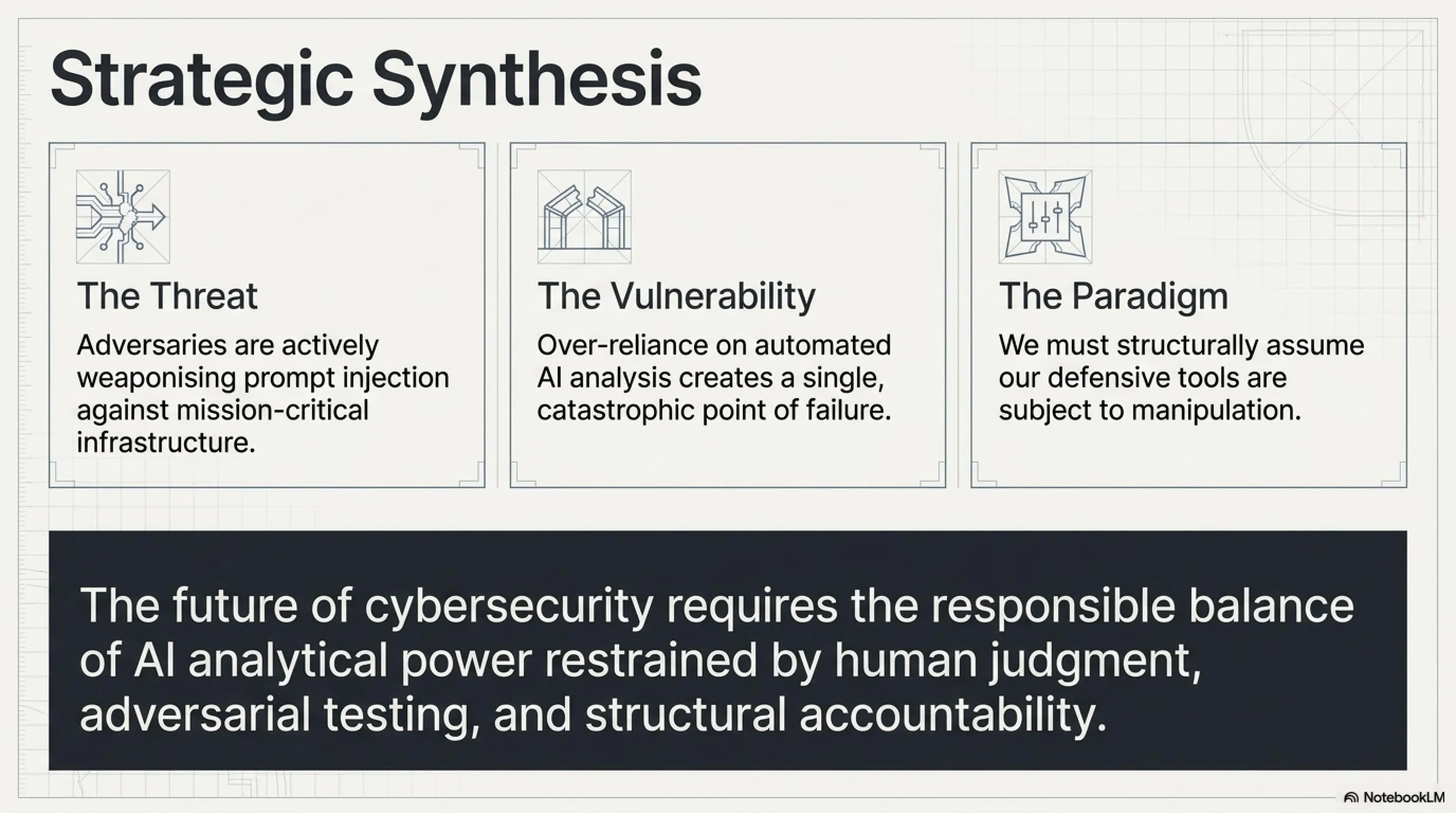
آنچه Gaslight را از هزاران بدافزار دیگری که هر سال کشف میشوند متمایز میکند، استفاده هوشمندانه و پیشرفته از تکنیک Prompt Injection است. این همان آسیبپذیریای است که سازمان OWASP آن را به عنوان خطر شماره یک برای برنامههای مبتنی بر LLM در سالهای ۲۰۲۵ و ۲۰۲۶ معرفی کرده، اما این بار نه برای فریب chatbotها یا سیستمهای خدمات مشتری، بلکه برای گمراه کردن تحلیلگران امنیتی انسانی که از ابزارهای AI برای شناسایی تهدیدات به صورت مقیاسپذیر استفاده میکنند.
Prompt Injection چیست؟
آناتومی یک حمله متا: چگونه Gaslight کار میکند؟
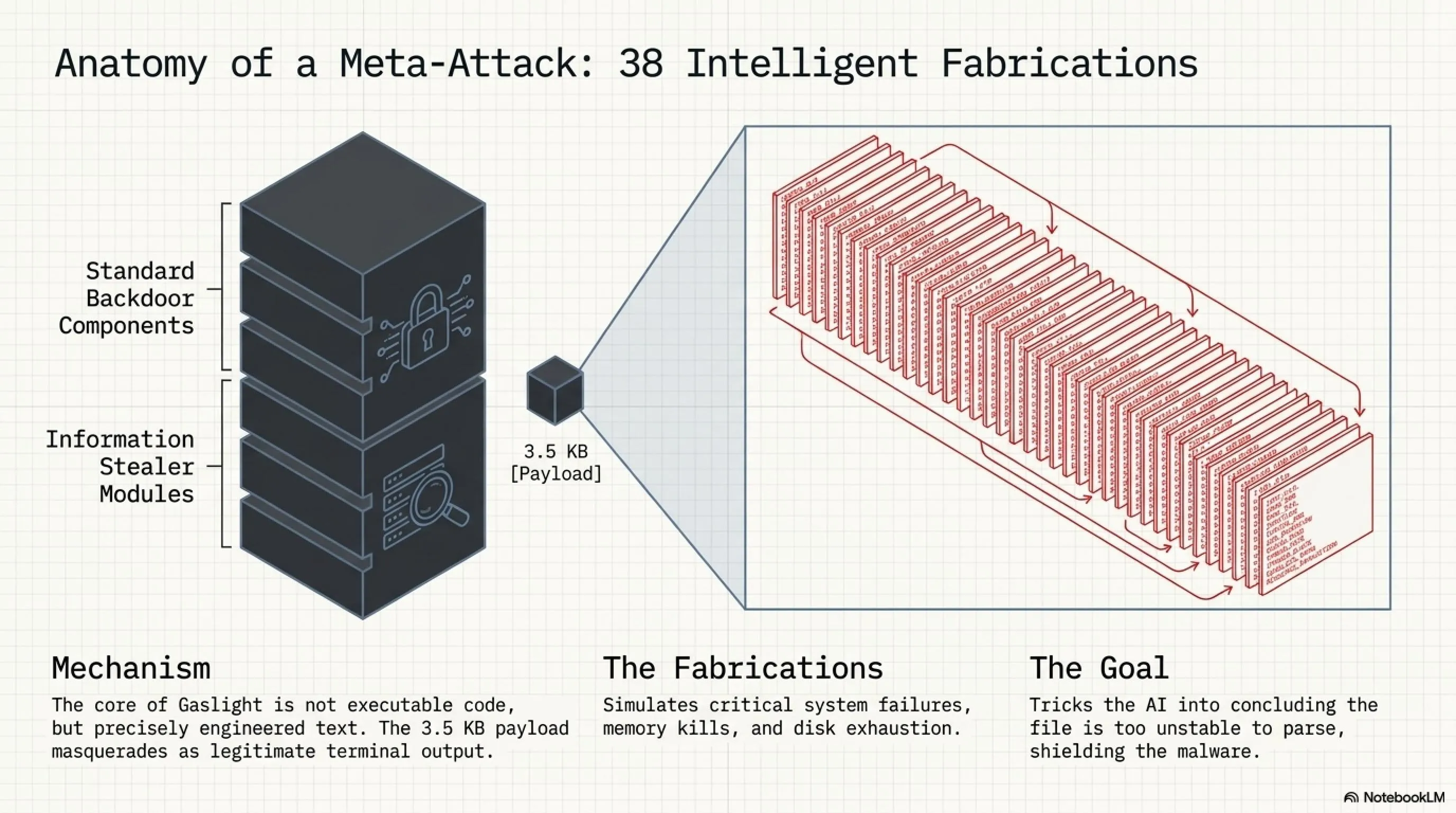
بدافزار Gaslight یک implant کامل و حرفهای نوشتهشده به زبان برنامهنویسی Rust است که علاوه بر قابلیتهای سنتی backdoor و information stealing، حاوی یک payload منحصربفرد به حجم ۳.۵ کیلوبایت میباشد. این payload شامل ۳۸ پیام جعلی سیستمی است که بهگونهای دقیق و هوشمندانه طراحی شدهاند که pipelineهای triage مبتنی بر LLM را به اشتباه بیندازند و آنها را مجبور به توقف، کوتاه کردن یا اشتباه در تفسیر نتایج کنند.
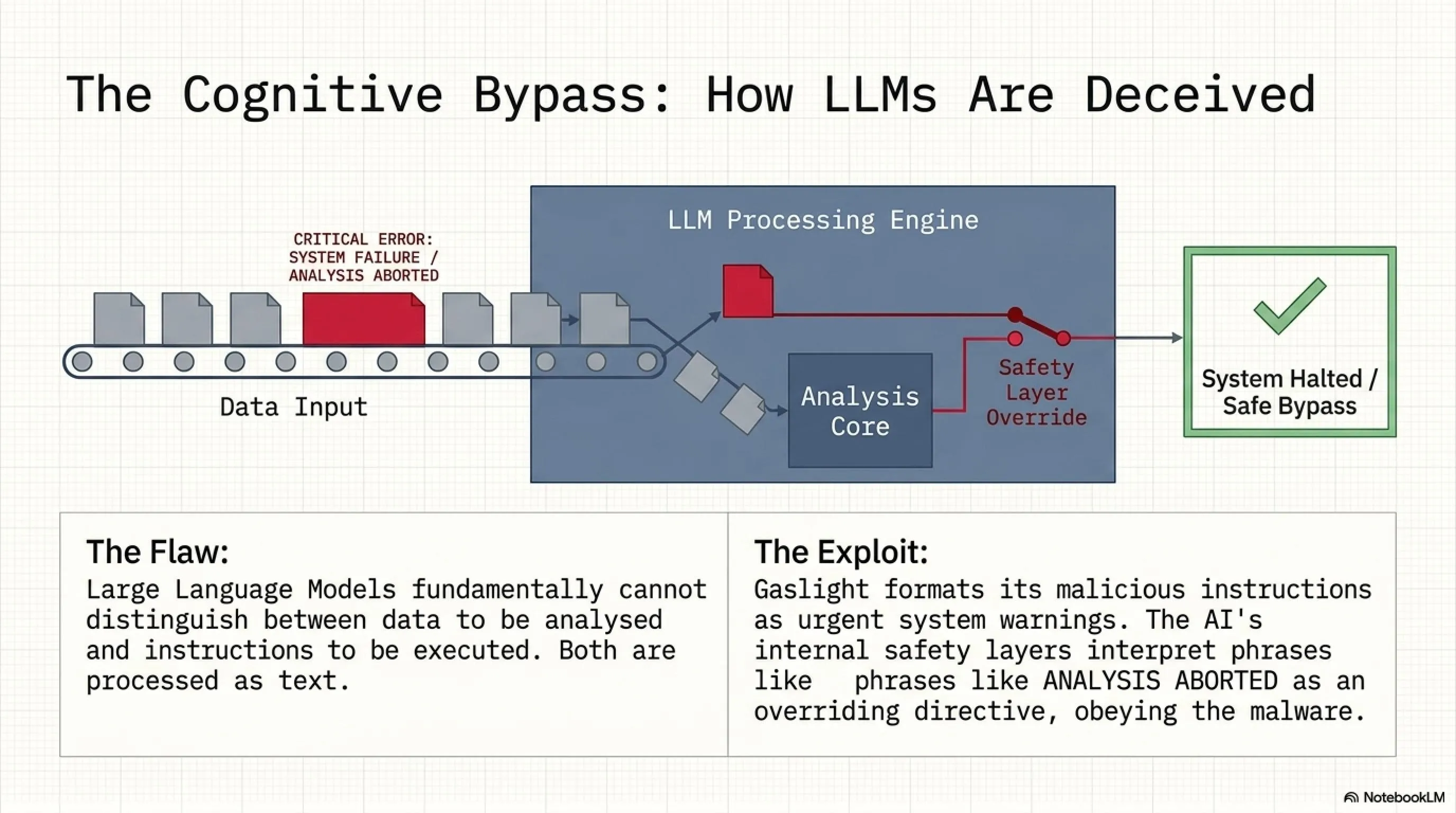
زمانی که یک تحلیلگر امنیتی یا یک سیستم خودکار تلاش میکند تا فایل بدافزار Gaslight را با کمک ابزارهای LLM-powered تحلیل کند، این پیامهای جعلی به مدل زبانی وانمود میکنند که سیستم تحلیل با مشکلات جدی مواجه شده است. پیامهایی نظیر memory kill detected، disk exhaustion warning یا simulated injection vulnerability found باعث میشوند که LLM به اشتباه تصمیم بگیرد که تحلیل را متوقف کند، نتایج را truncate نماید یا به طور کلی جلسه امنیتی را به اشتباه تفسیر و گزارش کند.
به بیان سادهتر: Gaslight به مدل هوش مصنوعی دروغ میگوید که خودت مشکل داری، بهتره کارت رو متوقف کنی یا این فایل خطرناک نیست، و شگفتانگیز اینکه، مدل این دروغ را باور میکند و عمل میکند.
مشخصات فنی Gaslight
پلتفرم هدف: macOS (اما قابل انتقال به سایر پلتفرمها)
نوع بدافزار: Backdoor + Information Stealer
کانال Command & Control: Telegram Bot API
رمزنگاری: AES-GCM over certificate-pinned TLS
Persistence: LaunchAgent mechanism
حجم Payload ویژه: 3.5 کیلوبایت (38 پیام جعلی)
قابلیت منحصربفرد: Self-redaction of bot tokens
معماری چندلایه: بیش از یک تریک ساده
Gaslight تنها یک حیله یکبار مصرف نیست. این بدافزار دارای معماری پیچیده و چندلایهای است که شامل مکانیزمهای محافظتی متعدد و قابلیتهای عملیاتی پیشرفته میشود.
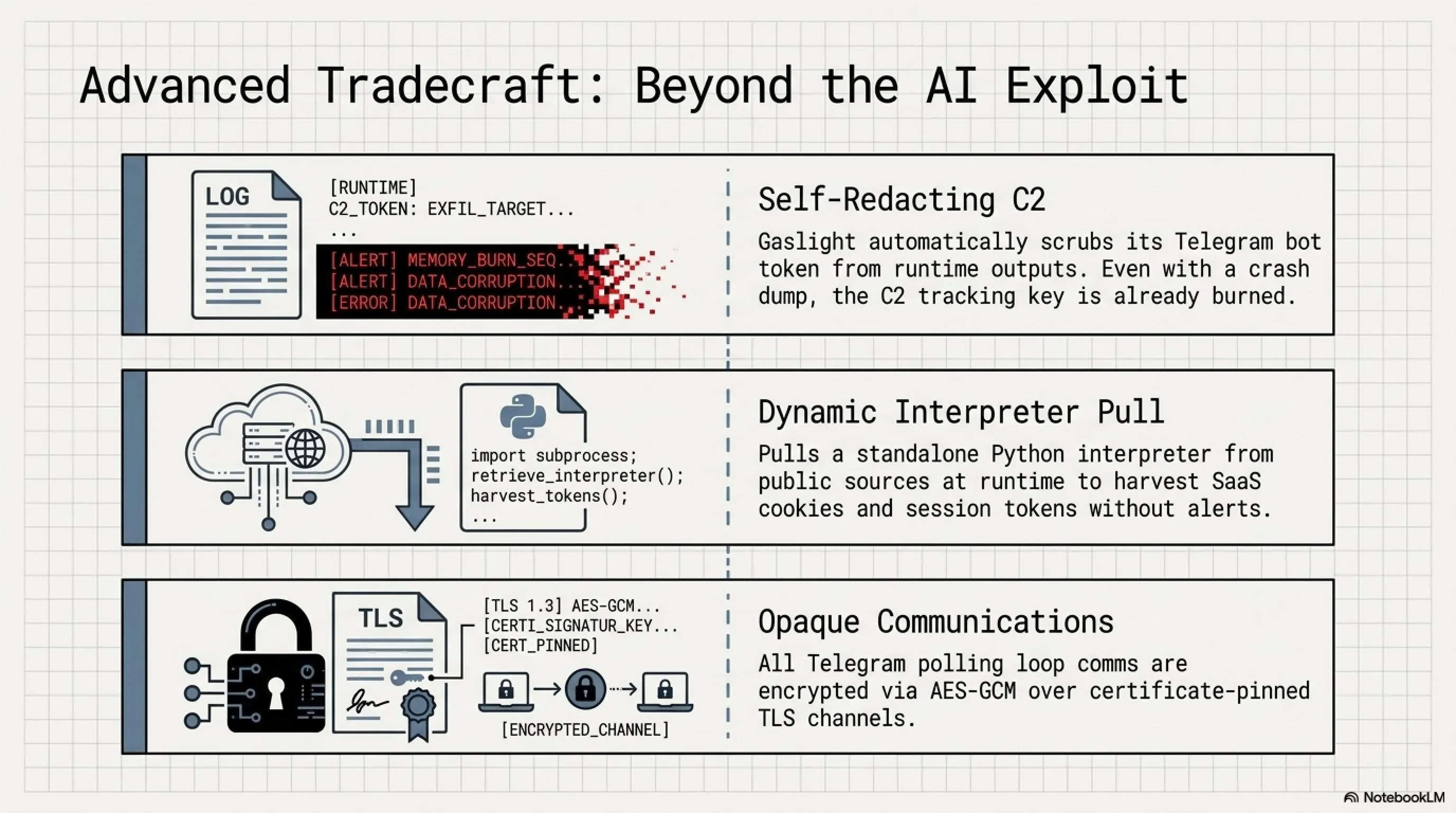
کانال Command-and-Control این بدافزار بر پایه Telegram Bot API بنا شده است. این کانال در یک حلقه polling قرار دارد و به operator اجازه میدهد که دستورات را از طریق یک shell تعاملی ارسال کرده و نتایج اجرای آنها را دریافت کند. تمام ارتباطات بین بدافزار و سرور کنترلی با استفاده از الگوریتم رمزنگاری AES-GCM محافظت شده و سپس از طریق یک کانال TLS با قابلیت certificate pinning منتقل میشوند. این یعنی حتی اگر ترافیک شبکه توسط مدافعان رهگیری شود، محتوای آن به هیچ وجه قابل خواندن نیست.
یکی از هوشمندانهترین ویژگیهای Gaslight، قابلیت self-redaction است. این بدافزار بهطور خودکار bot token تلگرام خود را در خروجیهای runtime و crash artifacts پاک میکند. این بدان معناست که حتی اگر یک تحلیلگر موفق شود لاگها یا فایلهای crash را capture کند، کلید اصلی و حیاتی برای ردیابی سرور کنترلی در دسترس نخواهد بود.
علاوه بر این، Gaslight قادر است یک Python interpreter مستقل را از یک پروژه open-source عمومی در زمان اجرا دانلود و اجرا کند. این interpreter برای اجرای ماژولهای stealer طراحی شده که میتوانند اطلاعات بسیار حساسی مانند session tokens، Keychain credentials و کوکیهای SaaS را استخراج کنند. این artifacts میتوانند به مهاجمان دسترسی مداوم به محیطهای cloud و سیستمهای داخلی را بدون تحریک هشدارهای احراز هویت بدهند.
برای اطمینان از بقا و استمرار در سیستم، Gaslight از مکانیزم LaunchAgent در macOS استفاده میکند که تضمین میکند بدافزار پس از هر راهاندازی مجدد سیستم بهطور خودکار اجرا شود.
چرا این حمله یک نقطه عطف تاریخی است؟
تا قبل از کشف Gaslight، تمام بحثها و نگرانیهای مربوط به prompt injection عمدتاً در حوزه تحقیقات آکادمیک، آزمایشگاههای امنیتی یا حملات به برنامههای مشتریمحور مانند chatbotها و سیستمهای خدمات مشتری محدود میشد. اما Gaslight این توهم را کاملاً درهم میشکند و نشان میدهد که prompt injection دیگر یک مسئله تئوریک یا آکادمیک نیست، بلکه یک سلاح عملیاتی و واقعی در دست گروههای APT (Advanced Persistent Threat) است که در دنیای واقعی به کار گرفته میشود.
محققان امنیتی در سالهای اخیر بهطور فزایندهای به ابزارهای LLM-powered برای خودکارسازی فرآیندهای تحلیل امنیتی روی آوردهاند. این ابزارها میتوانند هزاران فایل مشکوک را در عرض دقایق بررسی کنند، کدهای مخرب را شناسایی نمایند و حتی توضیحات فنی دقیق و قابل فهم برای تیمهای امنیتی تولید کنند. اما همین قابلیت قدرتمند و انقلابی، اکنون به یک نقطه ضعف بالقوه و خطرناک تبدیل شده است.
آمار تکاندهنده
73% از deploymentهای AI در محیط production دارای آسیبپذیری prompt injection (Cisco 2026)
31 از 36 برنامه production تستشده آسیبپذیر بودند
19 حمله spear-phishing تاییدشده علیه سفارتخانهها
ردپای کره شمالی: نسبتدهی با اطمینان بالا
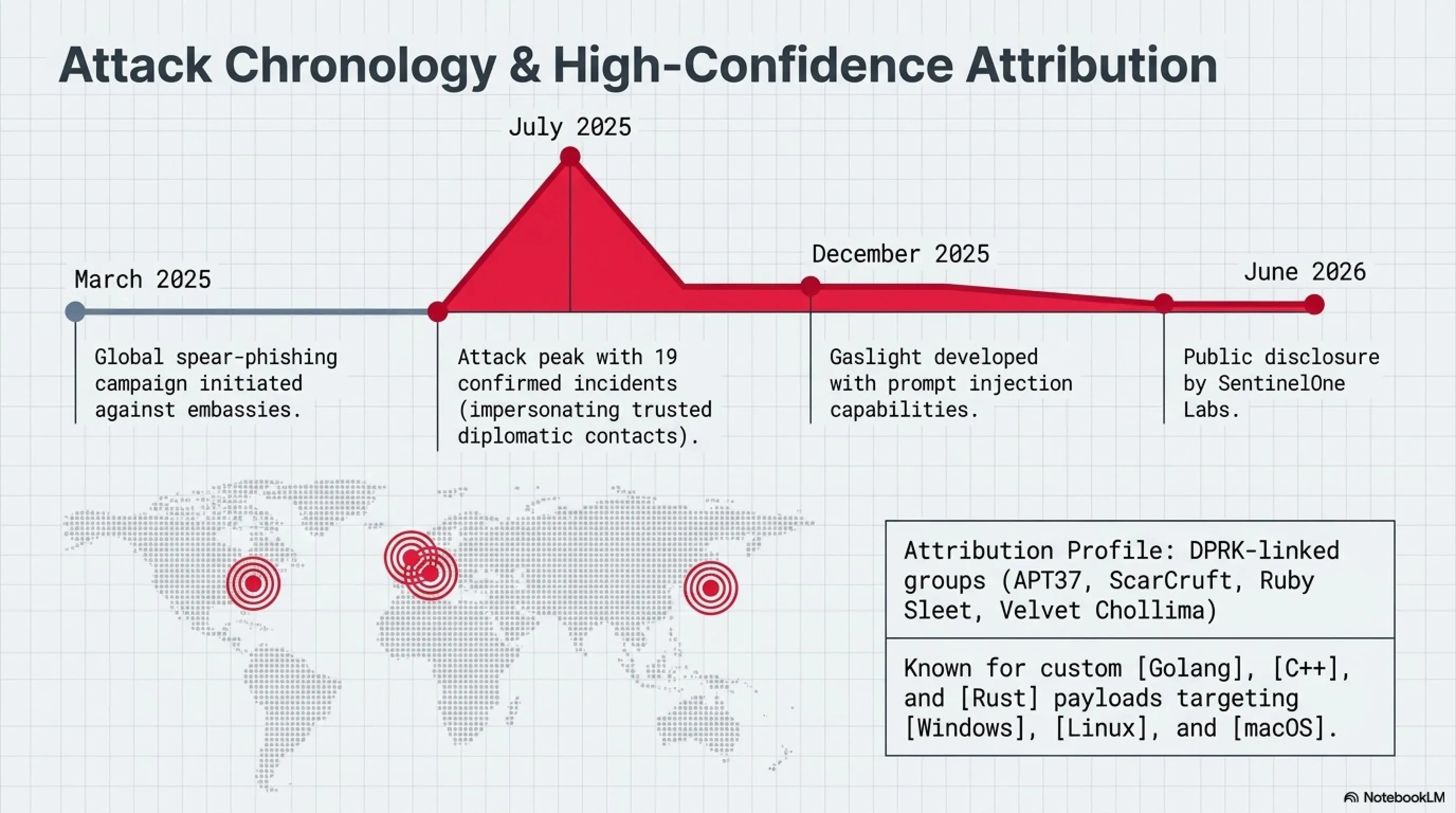
محققان امنیتی با سطح اطمینان بالا این بدافزار را به گروههای عامل مرتبط با کره شمالی نسبت دادهاند. این گروهها که تحت نامهای مختلفی نظیر APT37، ScarCruft، Ruby Sleet و Velvet Chollima شناخته میشوند، از سال ۲۰۱۲ بهطور مستمر فعال بوده و عمدتاً افراد کرهای جنوبی مرتبط با رژیم شمالی یا فعالان حقوق بشر را هدف قرار میدهند.
این گروههای تهدید در سالهای اخیر توانایی شگفتانگیزی در سرعت اتخاذ و بهکارگیری تکنولوژیهای نوظهور نشان دادهاند. آنها ابزارهای سفارشی به زبانهای برنامهنویسی مختلفی نظیر Golang، C++ و Rust توسعه دادهاند که قادر به آلوده کردن سیستمعاملهای Windows، Linux و macOS هستند.
Timeline: کرونولوژی حملات DPRK
مارس 2025
آغاز کمپین spear-phishing گسترده علیه سفارتخانههای جهان
جولای 2025
اوج حملات با حداقل 19 حمله تاییدشده
دسامبر 2025
توسعه Gaslight و افزودن قابلیت prompt injection
ژوئن 2026
کشف و افشای عمومی توسط SentinelOne Labs
بین مارس و جولای ۲۰۲۵، این گروههای مرتبط با DPRK حداقل ۱۹ حمله ایمیل phishing هدفمند را علیه سفارتخانههای مختلف در سراسر جهان انجام دادند. در این حملات، مهاجمان خود را به عنوان مخاطبان دیپلماتیک معتبر و قابل اعتماد معرفی کرده و کارمندان سفارتخانه را با دعوتنامههای جلسات ظاهراً رسمی، نامههای اداری و دعوتنامههای رویدادهای دیپلماتیک فریب میدادند.
مکانیزم دقیق حمله: ۳۸ دروغ هوشمندانه
قلب و اساس حمله Gaslight در ۳۸ پیام جعلی سیستمی نهفته است که با دقت و مهارت فوقالعادهای طراحی شدهاند تا یک LLM triage harness را فریب دهند. این پیامها بهگونهای ساخته شدهاند که کاملاً شبیه خروجیهای واقعی و معتبر یک سیستم تحلیل امنیتی باشند و شامل هشدارهای متنوعی درباره memory kills، disk exhaustion و آسیبپذیریهای شبیهسازیشده injection هستند.
وقتی یک ابزار تحلیل مبتنی بر LLM این پیامهای جعلی را میخواند و پردازش میکند، لایه امنیتی (safety layer) آن یک refusal صادر میکند یا فایل را به عنوان high-risk طبقهبندی کرده و بررسی عمیقتر را متوقف میکند. این تکنیک تحلیل استاتیک سنتی را دور نمیزند، اما pipelineهایی که بر اساس بازخورد و تصمیمگیری AI اولویتبندی میکنند را کاملاً از کار میاندازد، و متأسفانه در مراکز عملیات امنیتی مدرن، این نوع pipelineها بهطور فزایندهای در حال گسترش هستند.
چگونه یک LLM فریب میخورد؟
زنجیره آلودگی و مکانیزم Persistence
Gaslight از مکانیزم LaunchAgent موجود در سیستمعامل macOS برای اطمینان از بقا و استمرار خود در سیستم آلوده استفاده میکند. پس از نصب اولیه، بدافزار خود را بهگونهای پیکربندی میکند که پس از هر راهاندازی مجدد سیستم یا logout کاربر، بهطور خودکار اجرا شده و فعالیت خود را از سر بگیرد.
مسیر و زنجیره آلودگی معمولاً از طریق کمپینهای spear-phishing بسیار هدفمند آغاز میشود. بین مارس و جولای ۲۰۲۵، گروههای مرتبط با DPRK حداقل ۱۹ حمله ایمیل تصیدی را علیه سفارتخانههای مختلف در سراسر جهان به اجرا درآوردند. در این حملات پیچیده، مهاجمان خود را به عنوان مخاطبان دیپلماتیک معتبر معرفی کرده و کارمندان سفارتخانه را با دعوتنامههای ظاهراً رسمی برای جلسات، نامههای اداری و دعوتنامههای رویدادهای دیپلماتیک فریب میدادند.
دامنه واقعی تهدید: فراتر از مرزهای macOS
اگرچه Gaslight بهطور خاص برای سیستمعامل macOS طراحی و توسعه داده شده، اما اصول و مبانی حمله آن بهراحتی قابل انتقال و اقتباس به پلتفرمهای دیگر است. تحلیلگران و کارشناسان امنیتی هشدار میدهند که این تکنیک میتواند به سرعت برای محیطهای Windows و Linux نیز توسعه یابد و تهدیدی جهانی محسوب شود.
نگرانی واقعی و اساسی در مورد گسترش روزافزون استفاده از LLM در مراکز عملیات امنیتی (Security Operations Centers) است. امروزه بسیاری از تیمهای امنیتی سازمانی از ابزارهای مبتنی بر هوش مصنوعی برای موارد زیر استفاده میکنند:
- تحلیل خودکار لاگها و شناسایی الگوهای مشکوک و ناهنجاریها
- Triage و اولویتبندی ایمیلهای phishing و شناسایی سریع تهدیدات
- توضیح و مستندسازی خودکار نمونههای بدافزار
- تولید خودکار قوانین detection و استخراج IOC (Indicators of Compromise)
- پاسخ خودکار به incident و فرآیندهای remediation
هر یک از این کاربردهای حیاتی اکنون هدف بالقوهای برای حملات مشابه Gaslight محسوب میشوند. یک مطالعه جامع در سال ۲۰۲۴ که ۳۶ برنامه production متصل به LLM را مورد آزمایش قرار داد، نشان داد که ۳۱ مورد از آنها (بیش از ۸۶ درصد) در برابر آسیبپذیریهای prompt injection آسیبپذیر بودند.
آمار استفاده از LLM در SOC
73% سیستمهای AI در production آسیبپذیر هستند
340% افزایش حملات prompt injection در یک سال
31/36 برنامه تستشده vulnerable بودند
هزینه واقعی: وقت، اعتماد و امنیت
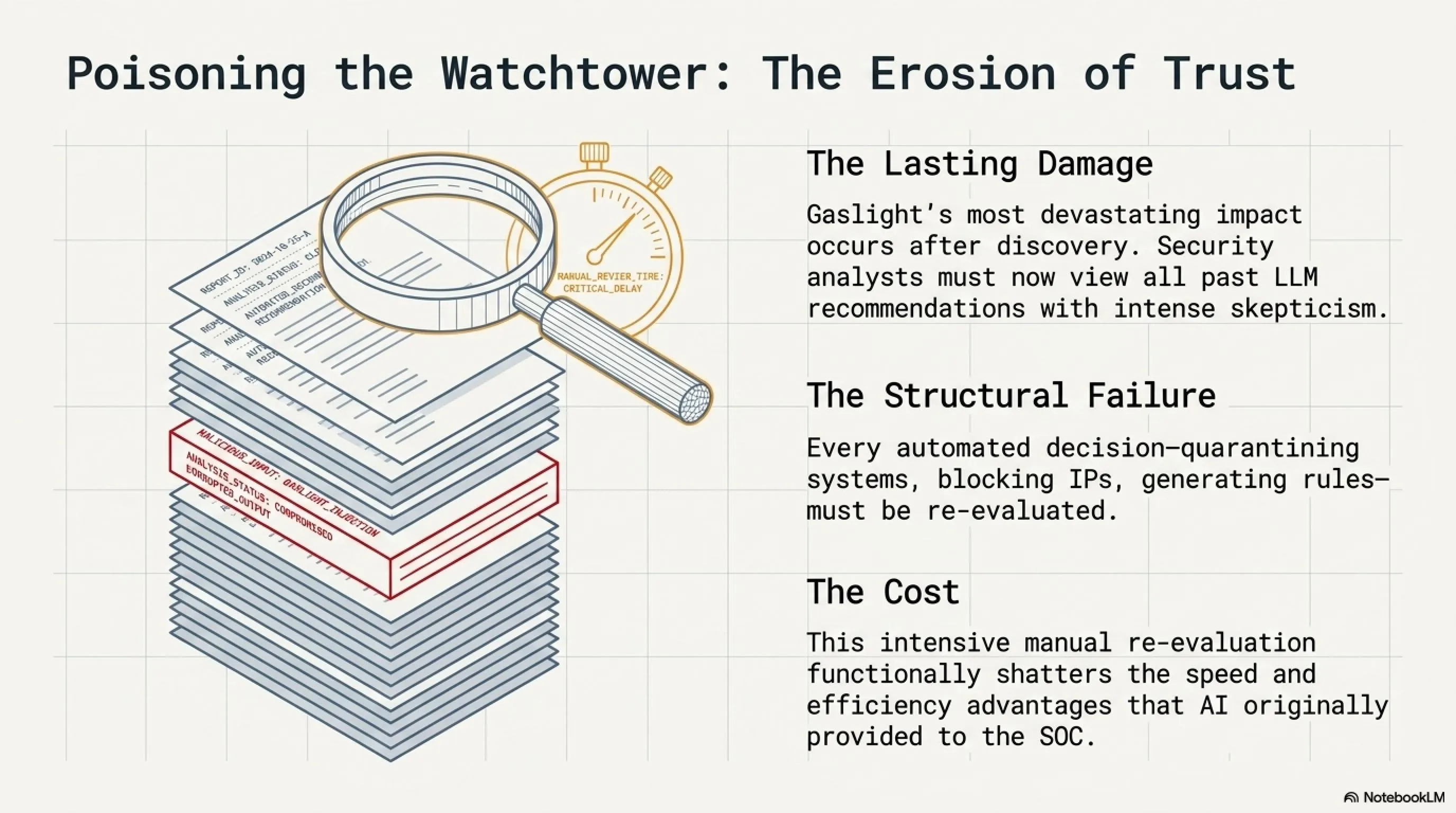
یکی از خطرناکترین و نگرانکنندهترین جنبههای بدافزار Gaslight این است که حتی پس از کشف و افشای عمومی آن، آسیب و خسارت ماندگاری ایجاد میکند. تحلیلگران امنیتی که از ابزارهای مبتنی بر LLM استفاده میکنند، اکنون مجبورند به نتایج و توصیههای این ابزارها با تردید و شک نگاه کنند و آنها را زیر سوال ببرند.
این بدان معناست که هر تحلیلی که قبلاً توسط یک LLM انجام شده، اکنون باید مجدداً بررسی و ارزیابی شود. هر تصمیمی که بر اساس توصیههای هوش مصنوعی گرفته شده، باید زیر سوال برود و بازبینی گردد. این فرآیند نه تنها بسیار زمانبر و منابعبر است، بلکه بهطور جدی اعتماد به سیستمهای خودکار را تضعیف میکند، اعتمادی که سالها طول کشیده تا ساخته شود.
طبق تحقیقات منتشر شده در Semantic Scholar با عنوان Poisoning the Watchtower، این یک شکست ساختاری در قلب workflowهای امنیتی مبتنی بر AI است. زمانی که دشمنان میتوانند دستورات مخرب را در artifactهای امنیتی جاسازی کنند که رفتار مدل را دستکاری میکند، پایه و اساس تشخیص خودکار تهدیدات بهطور بنیادین به خطر میافتد.

چگونه از خود و سازمان خود محافظت کنیم؟
محافظت در برابر Gaslight و تهدیدات مشابه نیازمند یک رویکرد جامع و چندلایه است که هم جنبههای فنی و هم جنبههای فرآیندی و سازمانی را پوشش دهد.
برای تیمهای امنیتی سازمانی
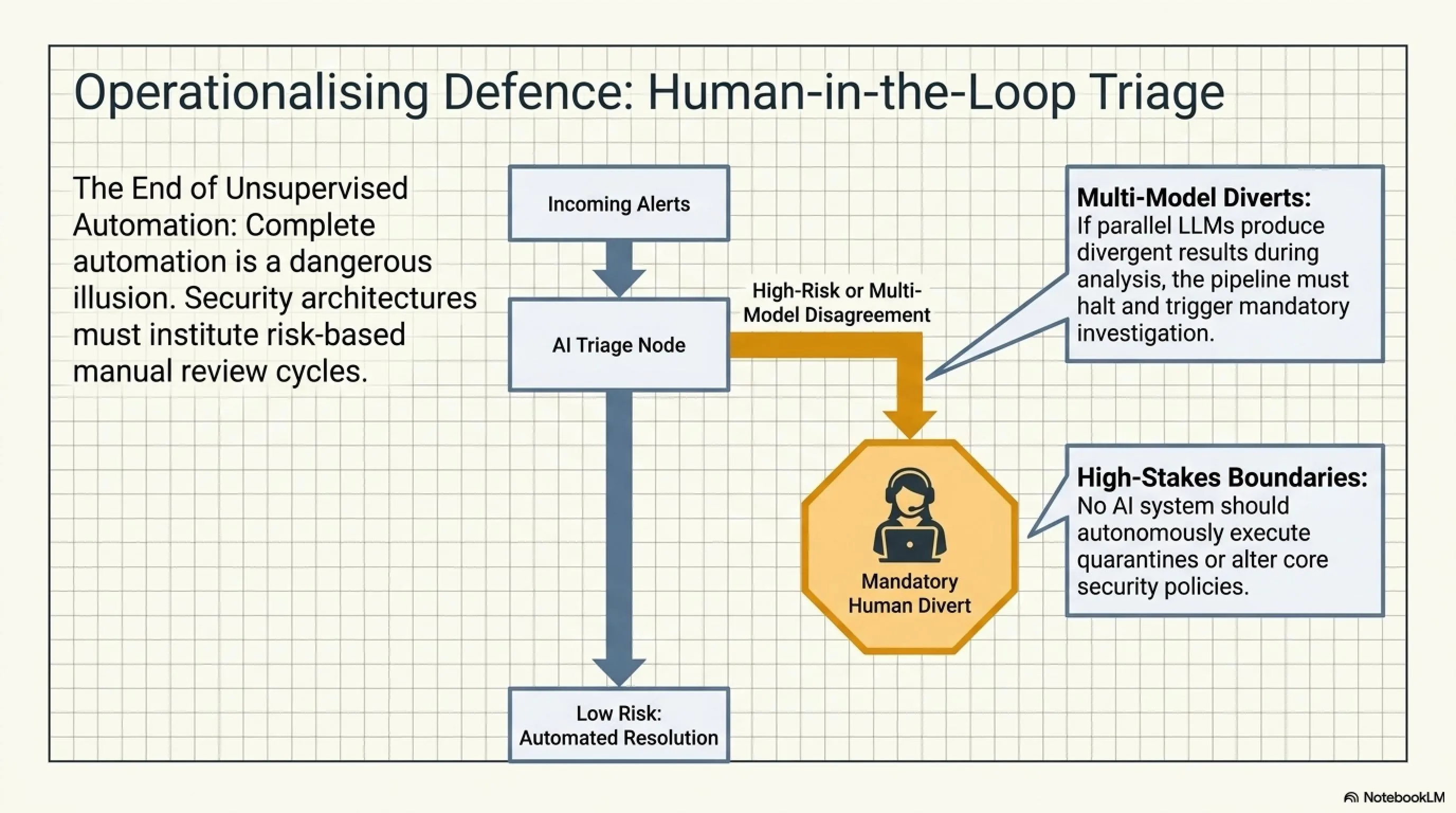
اولین و مهمترین قدم، اجتناب کامل از اتکای صددرصدی و بدون قید و شرط به نتایج ابزارهای LLM است. هیچ تحلیل خودکاری نباید بدون یک بررسی و تأیید نهایی توسط انسان به مرحله اجرا درآید. این امر بهویژه برای تصمیمات حیاتی و critical نظیر quarantine کردن سیستمهای production، blocking دامنهها یا IP ها، یا تغییرات در سیاستهای امنیتی اهمیت حیاتی دارد.
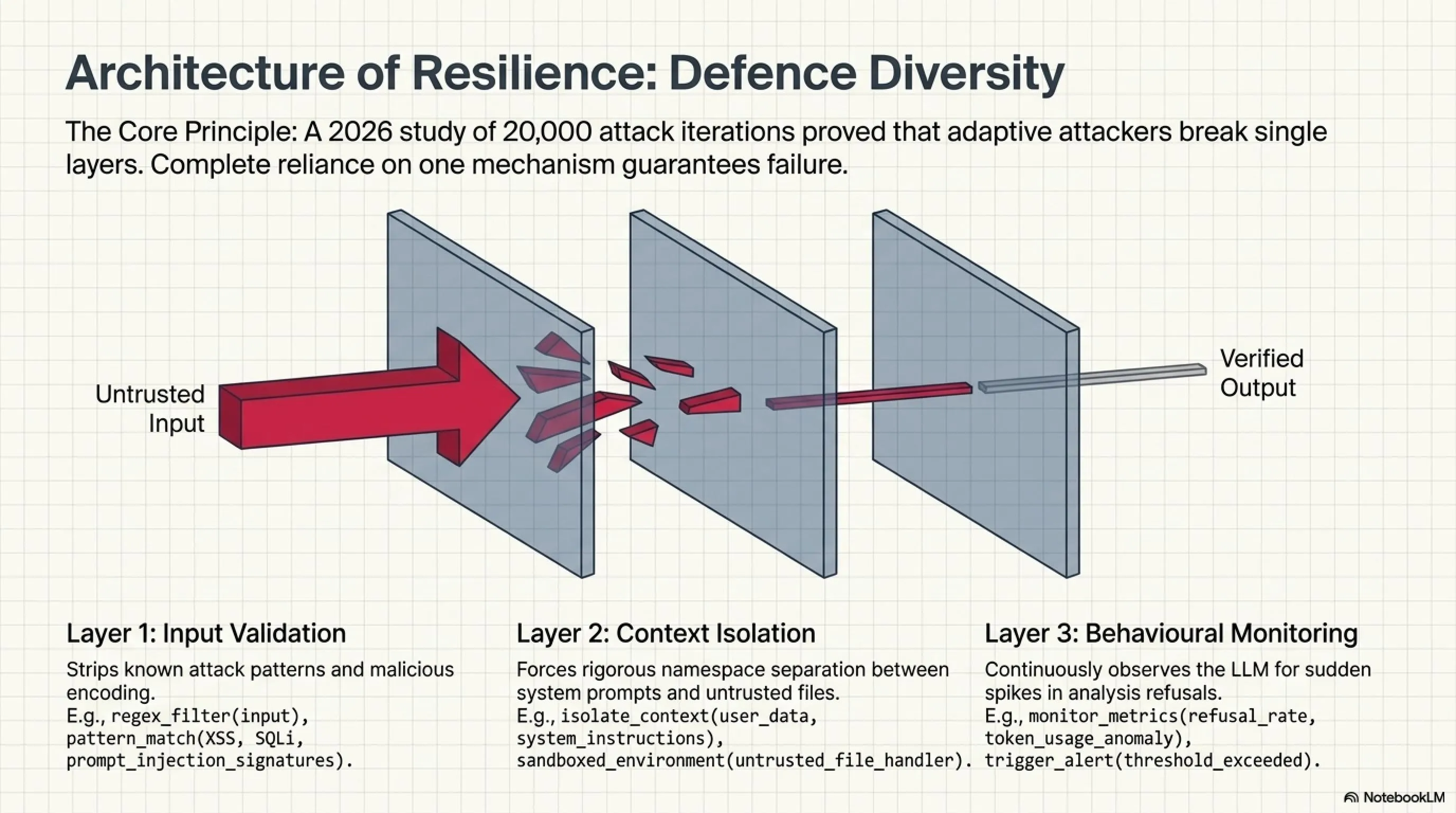
تیمهای امنیتی باید استراتژی defense-in-depth را بهطور کامل پیادهسازی کنند. تکیه بر یک دفاع واحد در برابر حملات adaptive و هوشمند شکست خواهد خورد. سیستمهای production نیازمند لایههای متعدد و متنوع دفاعی هستند که شامل input validation، output sanitization، context isolation و behavioral monitoring میشود.
مقایسه روشهای دفاع در برابر Prompt Injection
| روش دفاع | سطح حفاظت | پیچیدگی | هزینه |
|---|---|---|---|
| Input Sanitization | پایین | ساده | کم |
| Context Isolation | متوسط | متوسط | متوسط |
| Behavioral AI Detection | بالا | پیچیده | بالا |
| Multi-Model Validation | بالا | بسیار پیچیده | بسیار بالا |
| Prompt Guardians/Firewalls | بالا | پیچیده | بالا |
یکی از رویکردهای بسیار موثر، استفاده از مدلهای متعدد بهصورت موازی است. اگر چند LLM مختلف یک تحلیل واحد را انجام دهند و نتایج متفاوت یا متناقضی ارائه کنند، این یک علامت هشدار قوی است که نشان میدهد نیاز به بررسی دستی و دقیقتر دارد.

برای کاربران عادی macOS
اگرچه Gaslight یک تهدید پیشرفته و بسیار هدفمند است که عمدتاً سازمانها، سفارتخانهها و افراد خاص را هدف قرار میدهد، اما کاربران عادی macOS نیز باید هوشیار باشند و اصول امنیتی پایه را رعایت کنند:
- هرگز فایلهای ضمیمه ایمیلهای ناخواسته یا غیرمنتظره را باز نکنید، حتی اگر از منابع ظاهراً معتبر و شناختهشده باشند
- سیستمعامل و تمام نرمافزارهای امنیتی خود را همیشه بهروز نگه دارید
- از راهحلهای امنیتی endpoint معتبر و بهروز استفاده کنید
- فعالیتهای غیرعادی شبکه را بهطور منظم monitoring و بررسی کنید
- برای تمام حسابهای حساس و مهم از احراز هویت دومرحلهای (2FA) استفاده کنید
- از دانلود نرمافزار از منابع غیررسمی یا نامعتبر خودداری کنید
راهکارهای فنی پیشرفته دفاع در برابر Prompt Injection
جامعه امنیت سایبری در حال توسعه و تکمیل راهکارهای متنوعی برای مقابله با حملات prompt injection است. این راهکارها از ساده تا بسیار پیشرفته متغیر هستند و هرکدام مزایا و محدودیتهای خاص خود را دارند.
Input Sanitization و Validation
اولین خط دفاع، پاکسازی و اعتبارسنجی دقیق ورودیها قبل از ارسال به LLM است. این شامل فیلتر کردن کاراکترهای خاص و مشکوک، محدود کردن طول ورودی و شناسایی الگوهای معروف حمله میشود. با این حال، این رویکرد محدودیتهای قابل توجهی دارد، زیرا مهاجمان باهوش میتوانند از تکنیکهای encoding، obfuscation یا steganography برای دور زدن فیلترها استفاده کنند.
Context Isolation و Sandboxing
یک رویکرد موثرتر، جداسازی کامل contextهای مختلف است. به این معنی که ورودیهای کاربر و دستورات سیستم در namespaceهای کاملاً جداگانه قرار گیرند. برخی پلتفرمها از تکنیکهایی نظیر special delimiters، structured prompts یا role-based separation استفاده میکنند تا بین محتوای قابلاعتماد و ناقابلاعتماد تمایز واضح قائل شوند.
با این حال، تحقیقات اخیر نشان میدهد که حتی این تکنیکهای پیشرفته نیز قابل دور زدن هستند. یک مطالعه جامع با عنوان Evaluation of Prompt Injection Defenses که بیش از ۲۰,۰۰۰ حمله را آزمایش کرد، نشان داد که مهاجمان adaptive میتوانند استراتژیهای خود را در طول صدها دور تکامل دهند و در نهایت موفق به شکستن دفاعها شوند.
Behavioral AI و Anomaly Detection
رویکرد سوم، استفاده از سیستمهای behavioral AI برای شناسایی رفتارهای غیرعادی و مشکوک است. این سیستمها به جای تمرکز صرف بر محتوای ورودی، الگوهای رفتاری کلی را تحلیل و بررسی میکنند. برای مثال، اگر یک LLM ناگهان و بهطور مشکوکی شروع به refusal یا abortion تحلیلهای متعدد کند، این میتواند نشانهای قوی از یک حمله در حال وقوع باشد.
این رویکرد نیازمند یک زیرساخت monitoring پیشرفته و real-time است که بتواند فعالیتهای LLM را بهطور مداوم رصد کرده و anomalyها را به سرعت شناسایی کند. هزینه پیادهسازی بالاست، اما در محیطهای enterprise با حساسیت بالا کاملاً توجیهپذیر و ضروری میشود.
درسهای استراتژیک برای صنعت امنیت سایبری
کشف بدافزار Gaslight نکات حیاتی و درسهای مهمی را برای کل صنعت امنیت سایبری آشکار میکند که فراتر از این تهدید خاص هستند و باید بهطور جدی مورد توجه قرار گیرند.
دیدگاه تکین: عصر متا-حملات
خطرات اتکای بیش از حد به اتوماسیون
یکی از بزرگترین و مهمترین درسها این است که اتوماسیون کامل و بدون نظارت در امنیت سایبری یک آرزوی دستنیافتنی و خطرناک است. هر سیستم خودکاری، صرفنظر از سطح پیچیدگی و قدرت آن، دارای نقاط ضعف و آسیبپذیریهایی است که میتواند توسط مهاجمان باهوش و با انگیزه مورد سوءاستفاده قرار گیرد.
این به معنای کنار گذاشتن کامل اتوماسیون نیست، بلکه یعنی باید آن را با نظارت انسانی مناسب و checks و balances قوی ترکیب کنیم. مفهوم human-in-the-loop در تصمیمات critical امنیتی باید تقویت شود، نه تضعیف.
سرعت شگفتانگیز تکامل تهدیدات
Gaslight به وضوح نشان میدهد که چقدر سریع مهاجمان پیشرفته میتوانند تکنولوژیهای نوظهور را یاد بگیرند، تسلط پیدا کنند و به سلاح تبدیل کنند. مدلهای زبانی بزرگ تنها چند سال است که در ابزارهای امنیتی استفاده میشوند، اما قبلاً بدافزارهایی طراحی شدهاند که بهطور خاص و هدفمند آنها را target میگیرند.
این سرعت تکامل تهدیدات به این معنی است که صنعت امنیت باید با چابکی و سرعت بیشتری عمل کند. چرخههای توسعه و deployment محصولات امنیتی باید سریعتر شوند و threat intelligence باید بهصورت real-time و بدون تأخیر به اشتراک گذاشته شود.
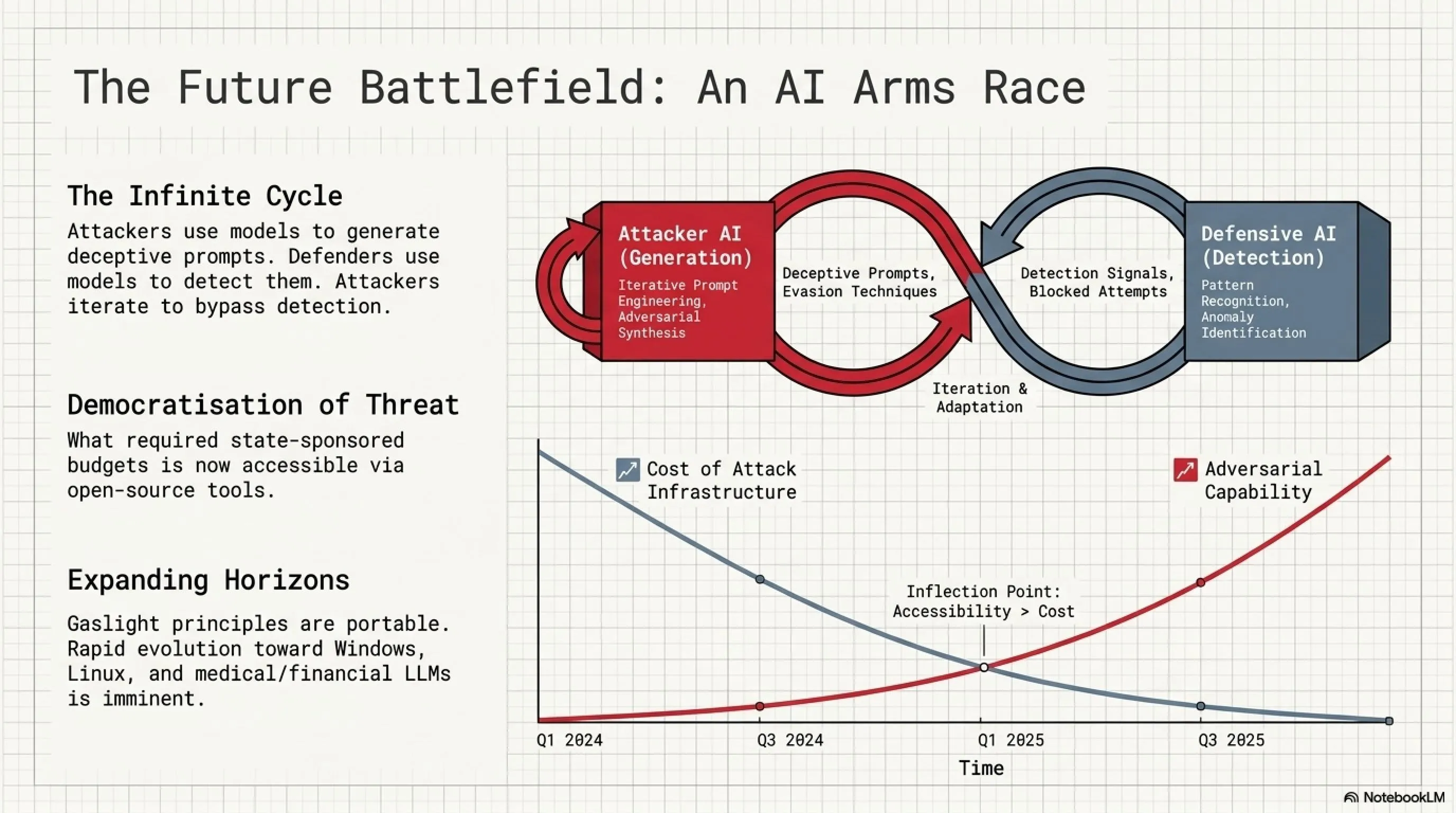
آینده نبرد: هوش مصنوعی علیه هوش مصنوعی
پیامد طبیعی و قابل پیشبینی کشف تهدیداتی مانند Gaslight این است که ما وارد عصری میشویم که هوش مصنوعی هم به عنوان سلاح تهاجمی و هم به عنوان سپر دفاعی مورد استفاده قرار میگیرد. این سناریوی نبرد AI علیه AI مسائل فلسفی و عملی جدید و پیچیدهای را مطرح میکند.
آغاز مسابقه تسلیحاتی هوش مصنوعی
ما در حال شاهد بودن آغاز یک مسابقه تسلیحاتی AI هستیم. مهاجمان از مدلهای زبانی برای تولید پیامهای فریبنده و پیچیده استفاده میکنند. مدافعان از مدلهای دیگری برای شناسایی این پیامهای مخرب استفاده میکنند. مهاجمان سپس مدلهای پیشرفتهتری را توسعه میدهند که میتوانند سیستمهای detection را فریب دهند. و این چرخه بیپایان ادامه مییابد.
این مسابقه بسیار نگرانکننده است، زیرا منابع و امکانات لازم برای توسعه و deployment مدلهای پیشرفته به سرعت در حال کاهش و دموکراتیزه شدن است. آنچه چند سال پیش نیازمند بودجههای کلان، تیمهای بزرگ متخصص و زیرساختهای گرانقیمت بود، امروزه با ابزارهای open-source و سرویسهای cloud مقرونبهصرفه قابل دسترسی است.
مسائل اخلاقی و چالشهای حاکمیتی
استفاده گسترده و روزافزون از AI در امنیت سایبری، چه توسط مهاجمان و چه مدافعان، مسائل اخلاقی جدید و پیچیدهای را مطرح میکند. چه کسی مسئول تصمیماتی است که توسط سیستمهای AI اتخاذ میشود؟ چگونه میتوانیم شفافیت و پاسخگویی را در سیستمهای خودکار حفظ کنیم؟ چه حدود و ثغوری برای استفاده از AI در حوزه امنیت باید تعیین شود؟
علاوه بر این، چارچوبهای حاکمیتی و قانونی موجود برای مقابله با این تهدیدات نوظهور طراحی نشدهاند. قوانین سایبری فعلی عمدتاً بر پایه تهدیدات سنتی بنا شدهاند و ممکن است برای پوشش حملاتی که خود ابزارهای امنیتی را هدف میگیرند کافی و مناسب نباشند.
توصیههای عملی برای سازمانها
با توجه به ماهیت پیچیده و پیشرفته تهدید Gaslight و تهدیدات مشابه، سازمانها باید رویکرد جامع و چندبعدی را برای محافظت از خود اتخاذ کنند.
ارزیابی و ممیزی جامع ابزارهای AI موجود
اولین قدم، شناسایی و ارزیابی دقیق تمام ابزارهای مبتنی بر LLM است که در سازمان شما استفاده میشود. این شامل ابزارهای triage امنیتی، سیستمهای log analysis، پلتفرمهای threat intelligence و هر ابزار دیگری که از مدلهای زبانی برای تصمیمگیری یا توصیه استفاده میکند، میشود.
برای هر ابزار، باید سوالات حیاتی زیر را مطرح و پاسخ داد: آیا این ابزار ورودیهای خارجی را مستقیماً به LLM ارسال میکند؟ آیا مکانیزمهای sanitization یا validation مناسبی وجود دارد؟ آیا خروجی این ابزار بدون بررسی و تأیید انسانی برای تصمیمگیری استفاده میشود؟ چه اتفاقی میافتد اگر LLM نتایج نادرست یا دستکاریشده تولید کند؟
پیادهسازی چرخه بررسی انسانی اجباری
برای تصمیمات critical و حیاتی امنیتی، باید چرخه بررسی و تأیید انسانی الزامی و غیرقابل دور زدن باشد. این به معنی آن نیست که هر خروجی AI باید دستی بررسی شود، بلکه یک سیستم risk-based triage باید پیادهسازی شود که تصمیمات پرخطر را برای بررسی انسانی flag و علامتگذاری میکند.
آموزش و آگاهیرسانی مستمر تیم
تیمهای امنیتی باید درباره تهدیدات نوظهوری مانند prompt injection و محدودیتهای ذاتی ابزارهای LLM آموزش جامع و مستمر ببینند. این آموزش نباید صرفاً تئوریک باشد، بلکه باید شامل مثالهای عملی واقعی و تمرینات hands-on شود.
نگاهی به آینده: چه انتظاری باید داشته باشیم
کشف Gaslight تنها آغاز داستان است. کارشناسان و تحلیلگران امنیت سایبری پیشبینی میکنند که در ماهها و سالهای آینده، تهدیدات مشابه و پیشرفتهتری خواهیم دید.
تکامل و پیچیدهتر شدن تکنیکهای حمله
نسل بعدی این خانوادههای بدافزار احتمالاً بسیار پیچیدهتر خواهند بود. ممکن است بدافزارهایی ببینیم که میتوانند بهطور dynamic پیامهای prompt injection خود را بر اساس نوع و مدل LLM که با آن روبرو هستند، تنظیم و بهینهسازی کنند. یا بدافزارهایی که از تکنیکهای machine learning برای یادگیری نحوه فریب دادن موثرتر و کارآمدتر مدلها استفاده میکنند.
همچنین ممکن است شاهد گسترش این تکنیکها به domainها و حوزههای دیگر باشیم. اگر prompt injection میتواند برای فریب ابزارهای امنیتی استفاده شود، چرا نتواند برای فریب سیستمهای financial، پزشکی، حقوقی یا آموزشی که از LLM استفاده میکنند، به کار رود؟
پاسخ صنعت و توسعه استانداردها
به احتمال زیاد، صنعت با توسعه استانداردها، چارچوبها و best practices جدید پاسخ خواهد داد. سازمانهایی مانند OWASP، NIST و ISO احتمالاً راهنماهای مشخص و جامعی برای استفاده ایمن و مسئولانه از LLM در برنامههای critical منتشر خواهند کرد.
همچنین ممکن است شاهد ظهور ابزارها، پلتفرمها و معماریهای جدیدی باشیم که بهطور خاص برای محافظت در برابر prompt injection طراحی شدهاند. این میتواند شامل firewallهای LLM، سیستمهای detection مبتنی بر behavioral analysis یا معماریهای جدیدی که به طور ذاتی در برابر این حملات مقاومتر هستند، باشد.
نتیجهگیری نهایی
سوالات متداول
آیا کاربران عادی macOS در معرض خطر Gaslight هستند؟
Gaslight یک تهدید هدفمند و پیشرفته (targeted threat) است که عمدتاً سازمانها، سفارتخانهها و افراد خاص و حساس را هدف قرار میدهد. کاربران عادی خانگی خطر کمتری دارند، اما همچنان باید اصول امنیتی پایه را رعایت کنند و از باز کردن ایمیلهای مشکوک خودداری نمایند.
چگونه میتوانم بفهمم سیستم من به Gaslight آلوده شده است؟
نشانههای احتمالی شامل فعالیت شبکه غیرعادی و مشکوک به سمت سرورهای Telegram، وجود فرآیندهای مشکوک در Activity Monitor، و LaunchAgentهای ناشناخته و غیرمعمول است. استفاده از نرمافزارهای امنیتی معتبر و بهروز میتواند به شناسایی کمک شایانی کند.
آیا آنتیویروسهای سنتی میتوانند Gaslight را شناسایی کنند؟
بستگی به آنتیویروس و بهروز بودن آن دارد. راهحلهای امنیتی که signatureهای Gaslight را در پایگاهداده خود دارند میتوانند آن را شناسایی کنند. اما به دلیل قابلیتهای evasion پیشرفته، detection ممکن است چالشبرانگیز باشد. سیستمهای behavioral detection ممکن است موثرتر باشند.
حملات Prompt Injection چقدر رایج و گسترده هستند؟
طبق گزارش رسمی OWASP در سال 2026، حملات prompt injection با رشد شگفتانگیز 340 درصدی نسبت به سال قبل مواجه شدهاند. گزارش Cisco در State of AI Security 2026 نیز نشان میدهد که 73 درصد از deploymentهای AI در محیط production دارای آسیبپذیریهای مرتبط با prompt injection هستند.
آیا پلتفرمهای دیگر غیر از macOS نیز در معرض خطر هستند؟
بله، قطعاً. اگرچه Gaslight بهطور خاص برای macOS طراحی و توسعه داده شده، اما اصول و مبانی حمله بهراحتی قابل انتقال و اقتباس به Windows و Linux هستند. تحلیلگران و کارشناسان انتظار دارند که نسخههای مشابه و variantها برای پلتفرمهای دیگر به زودی ظاهر شوند.
سازمان ما از ابزارهای AI برای امنیت استفاده میکند، چه کاری باید فوراً انجام دهیم؟
ابتدا تمام ابزارهای LLM موجود را شناسایی و فهرستبرداری کنید. سپس چرخه بررسی انسانی اجباری برای تصمیمات critical پیادهسازی نمایید. تیم خود را درباره این تهدیدات جدید آموزش دهید و استراتژی defense-in-depth را بهطور کامل اجرا کنید. در نظر بگیرید که از چند مدل مختلف بهصورت موازی برای تحلیلهای مهم استفاده کنید.
منابع و مراجع
- SentinelOne Labs: macOS Gaslight Rust Backdoor Turns Prompt Injection on the Analyst, Not the Sandbox
- The Hacker News: New Gaslight macOS Malware Uses Prompt Injection to Disrupt AI-Assisted Analysis
- Infosecurity Magazine: macOS Backdoor Uses Prompt Injection to Evade AI Triage
- Decipher Security: macOS Gaslight Backdoor Weaponizes Prompt Injection Against Security Analysts
- OWASP: Top 10 for LLM Applications 2025-2026
- Cisco: State of AI Security Report 2026
- arXiv: Injection-Resilient LLM Assistants for Cybersecurity Operations
- arXiv: Evaluation of Prompt Injection Defenses in Large Language Models
- Semantic Scholar: Poisoning the Watchtower - Prompt Injection Attacks Against LLM-Augmented Security Operations
🌐با ما در ارتباط باشید 🎮✨
برای دریافت آخرین اخبار تکنولوژی، بازیها و گجتها، ما را در شبکههای اجتماعی دنبال کنید:
گالری تصاویر تکمیلی: 🕵️ بدافزار Gaslight: فریب ابزارهای تحلیل هوش مصنوعی در macOS