Sina Weibo's VibeThinker-3B has sent shockwaves through the AI community by claiming to match the mathematical and coding reasoning capabilities of behemoths like DeepSeek V3.2 (671B parameters) using only 3 billion parameters. This unprecedented feat has sparked intense debate: is it a breakthrough in parametric compression, or simply a masterclass in \"Benchmaxxing\" (optimizing solely for benchmark tests)? Our comprehensive analysis dissects the model's performance on AIME 2026 and LiveCodeBench, and puts it ...
🧠 VibeThinker-3B: Revolution or Illusion?
When a Chinese social media company claims it built a 3-billion parameter model that can match 671-billion giants, we're either witnessing a revolution or the biggest benchmark gaming scandal in AI history. Sina Weibo's VibeThinker-3B has thrown the AI world into heated debate.
⚡ What You'll Discover:
🎯 Complete AIME & LiveCodeBench benchmark analysis
🔬 Hands-on testing with real-world experiments
💰 Cost comparison: $7,800 vs $294,000
🧪 Exposing benchmaxxing techniques
⚖️ Deep comparison with DeepSeek, Qwen, and GPT
🚀 The future of compact AI models
☕ Prepare for the deepest technical analysis of 2026's most controversial AI model!

🔥 The VibeThinker Earthquake: How a 3B Model Challenged AI Orthodoxy
Sunday, June 15, 2026, 4 PM Beijing time. While most AI researchers were enjoying their weekend, a team of nine at Sina Weibo—a company better known for its microblogging platform than cutting-edge AI research—published a 14-page technical report on arXiv that would shake the artificial intelligence community to its core.
The paper's title was straightforward: "VibeThinker-3B: Exploring the Frontier of Verifiable Reasoning in Small Language Models". But its content was anything but simple. The core claim? A model with just 3 billion parameters can match the mathematical reasoning and coding performance of systems that are 200 times larger.
📊 The Shocking Initial Numbers
Within 6 hours of publication, the model was released on Hugging Face. In the first 12 hours:
- 62 upvotes on Hugging Face's daily papers feed
- 130 likes for the model repository
- 685 GitHub stars in 24 hours
- 50,000+ downloads in 48 hours

💥 Community Reaction: Between Praise and Doubt
User @orcus108 on X wrote: "WHAT THE HELL is happening in AI? A 3B parameter model just put up coding benchmark scores in the same league as Claude Opus 4.5… I genuinely don't know if this is a breakthrough or if the benchmarks are broken." This post alone garnered over 161,000 views in just 8 hours.
AI researcher Francesco Bertolotti, in a tweet that drew 161K views, noted: "These results were achieved primarily through post-training refinements on Qwen2.5-Coder. The paper doesn't provide many details, but it appears they distill from RL ckpts and then do a final RL-based instruct RL."
🎭 Two Opposing Camps
✅ The Believers:
- "This proves Scaling Laws aren't absolute"
- "Post-training can work miracles"
- "The future belongs to specialized compact models"
❌ The Skeptics:
- "Pure benchmaxxing—built to game the tests"
- "No real-world utility"
- "Likely benchmark data leakage"
User @BigMoonKR wrote bluntly: "The benchmarks are literal pattern matching single file coding. It has no relation to actual coding work. I don't know how people still don't get this."
And user @politilols after testing the model reported: "Just tried the full precision. It doesn't even know what a uv script (so the most popular Python dev tool) is. Haven't seen that in a single LLM in at least a year now. Benchmaxxed."
🏢 Sina Weibo: From Social Media to AI Research
Sina Weibo (China's Twitter equivalent) is a company primarily known for its microblogging platform with over 600 million active users. The company's market capitalization hovers around $8 billion—less than 1% of OpenAI's valuation.
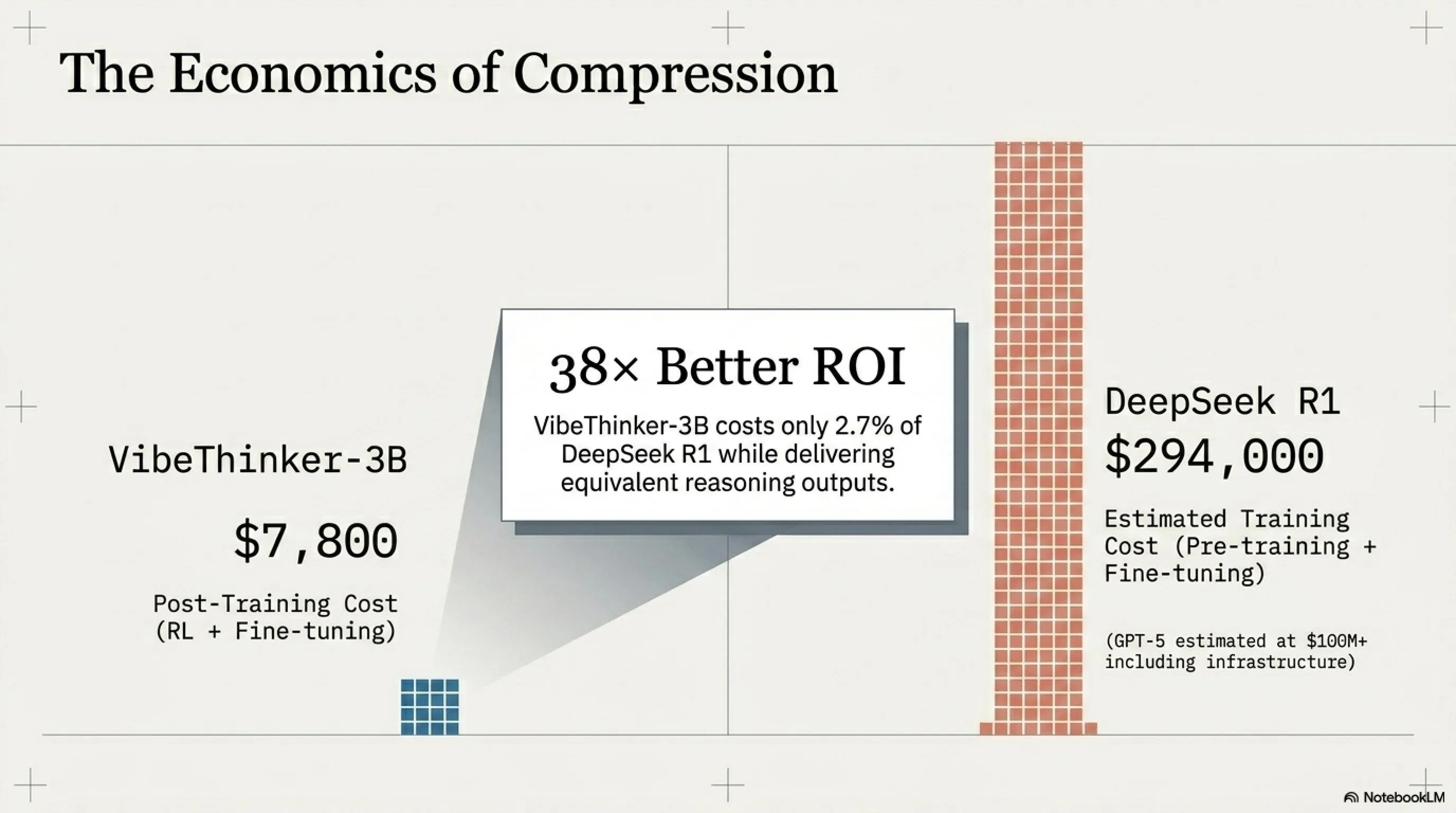
This is Weibo's second major open-source language model in 7 months. The previous model, VibeThinker-1.5B released in November 2025, demonstrated that a model with just 1.5 billion parameters could outperform the original DeepSeek R1 on several math benchmarks—a result the team claimed cost only $7,800 in post-training compared to an estimated $294,000 for DeepSeek R1.
🎯 Tekin Analysis: Why This Matters
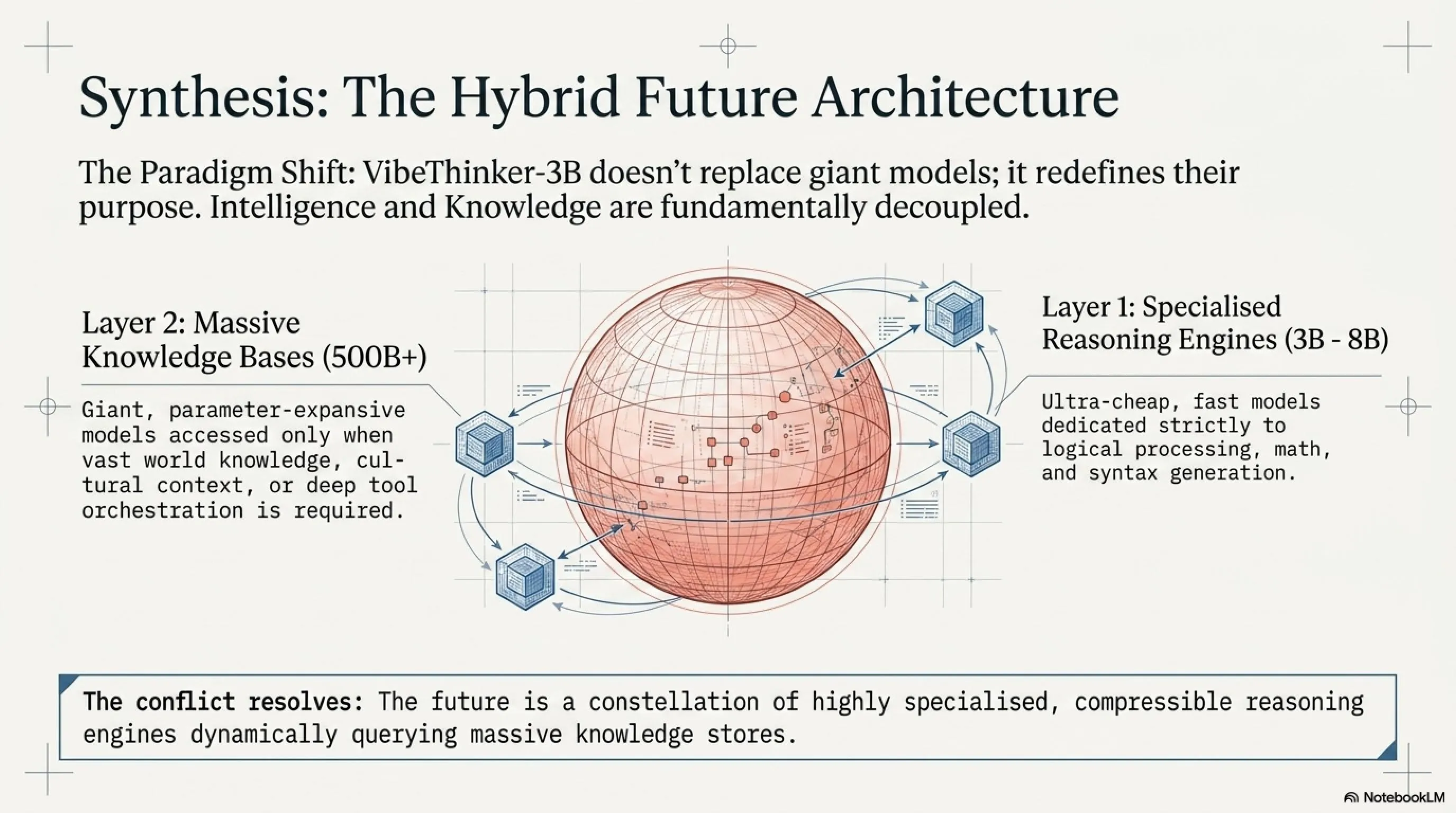
If VibeThinker-3B can truly do what it claims, this doesn't spell the end of giant models, but rather proves that "intelligence" and "knowledge" are two different things. You can compress mathematical reasoning into 3B parameters, but you still need broad knowledge to answer "What's the capital of France?" This distinction could define the future AI architecture: small specialized models for reasoning + large models for knowledge.
📊 Benchmark Reality Check: Dissecting the Numbers Behind the Hype
Let's step back from the initial excitement and examine the actual numbers. Is VibeThinker-3B really as good as it claims? Let's go benchmark by benchmark.
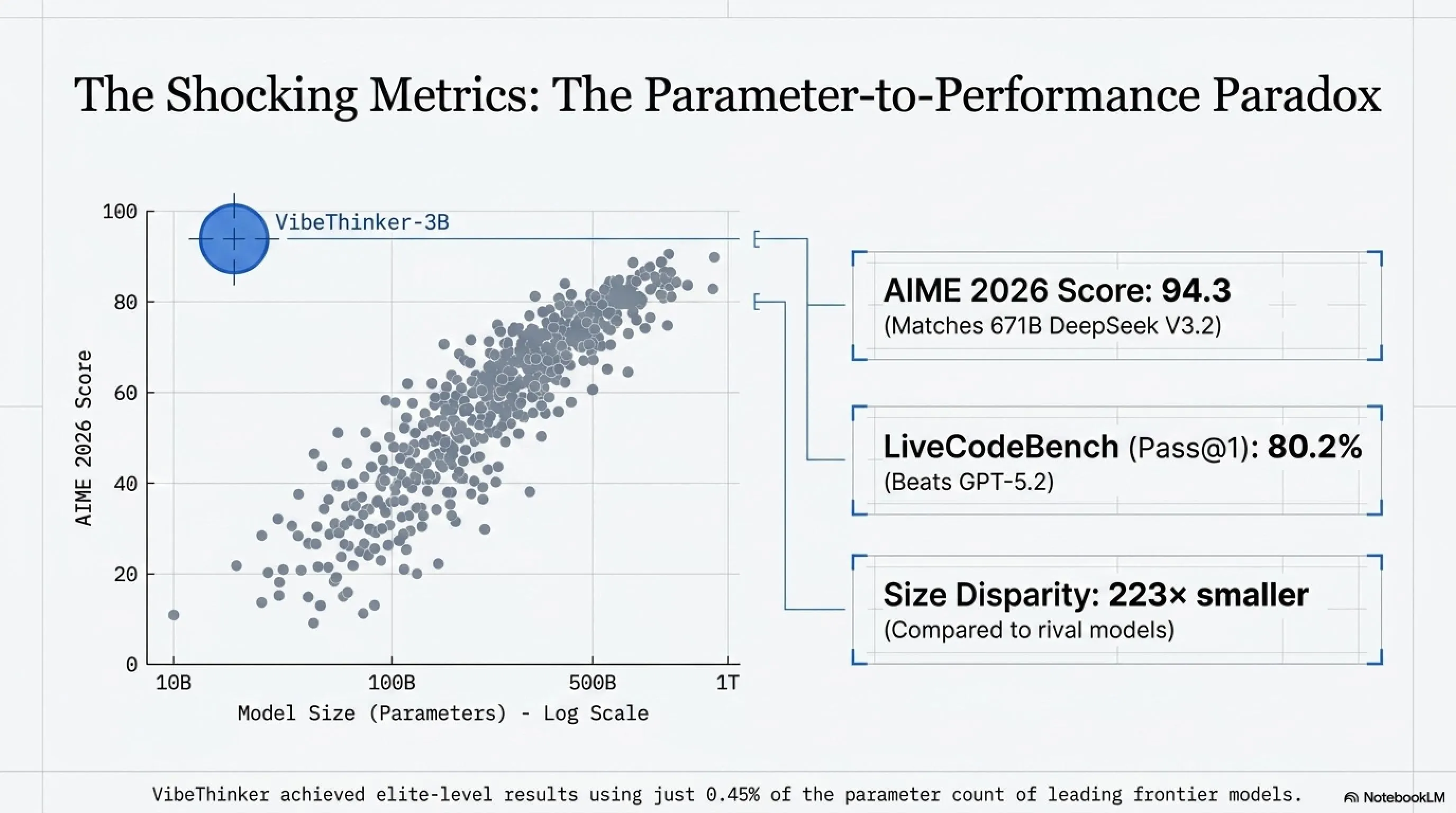
🧮 AIME: The Olympiad-Level Math Test
AIME (American Invitational Mathematics Examination) is one of the most challenging high school mathematics competitions in America. It consists of 15 problems that are difficult even for the best math students.
As you can see, VibeThinker-3B scored exactly the same as DeepSeek V3.2 on AIME 2026—a model that is 223 times larger. This means VibeThinker achieved the same result with just 0.45% of the size.
💻 LiveCodeBench: Real-World Coding
LiveCodeBench v6 is a coding benchmark that tests executable code—not just correct syntax, but code that actually works.
LiveCodeBench v6 Results (Pass@1)
VibeThinker-3B with an 80.2% Pass@1 score beat GPT-5.2 and is only 1.9 percentage points behind Claude Opus 4.5. These results are genuinely impressive—if they're real.
🏆 LeetCode: The Data Leakage Test
One of the most important tests to prove the model didn't cheat on benchmarks is LeetCode Weekly and Biweekly Contests. These contests were held after the training cutoff date, so they couldn't be in the training data.
🔐 Anti-Leakage Test
VibeThinker-3B was tested on LeetCode Contests from April 25 to May 31, 2026 (after training cutoff):
✅ Passed 123 out of 128 questions on first attempt
✅ Success rate: 96.1%
✅ Better than GPT-5.2, Doubao Seed 2.0 Pro, Kimi K2.5, and Claude Opus 4.6
This is the strongest evidence against "data leakage" claims.
❌ Where VibeThinker Fails
But it's not all golden. On GPQA-Diamond—a graduate-level science knowledge benchmark—VibeThinker-3B scored only 70.2, while Gemini 3 Pro achieved 91.9 and Claude Opus 4.5 scored 87.0.
The paper's authors explicitly acknowledge: "The main finding is not that a 3B model has fully replaced leading general-purpose models, but that a small model can reach first-tier performance on many verifiable reasoning tasks."
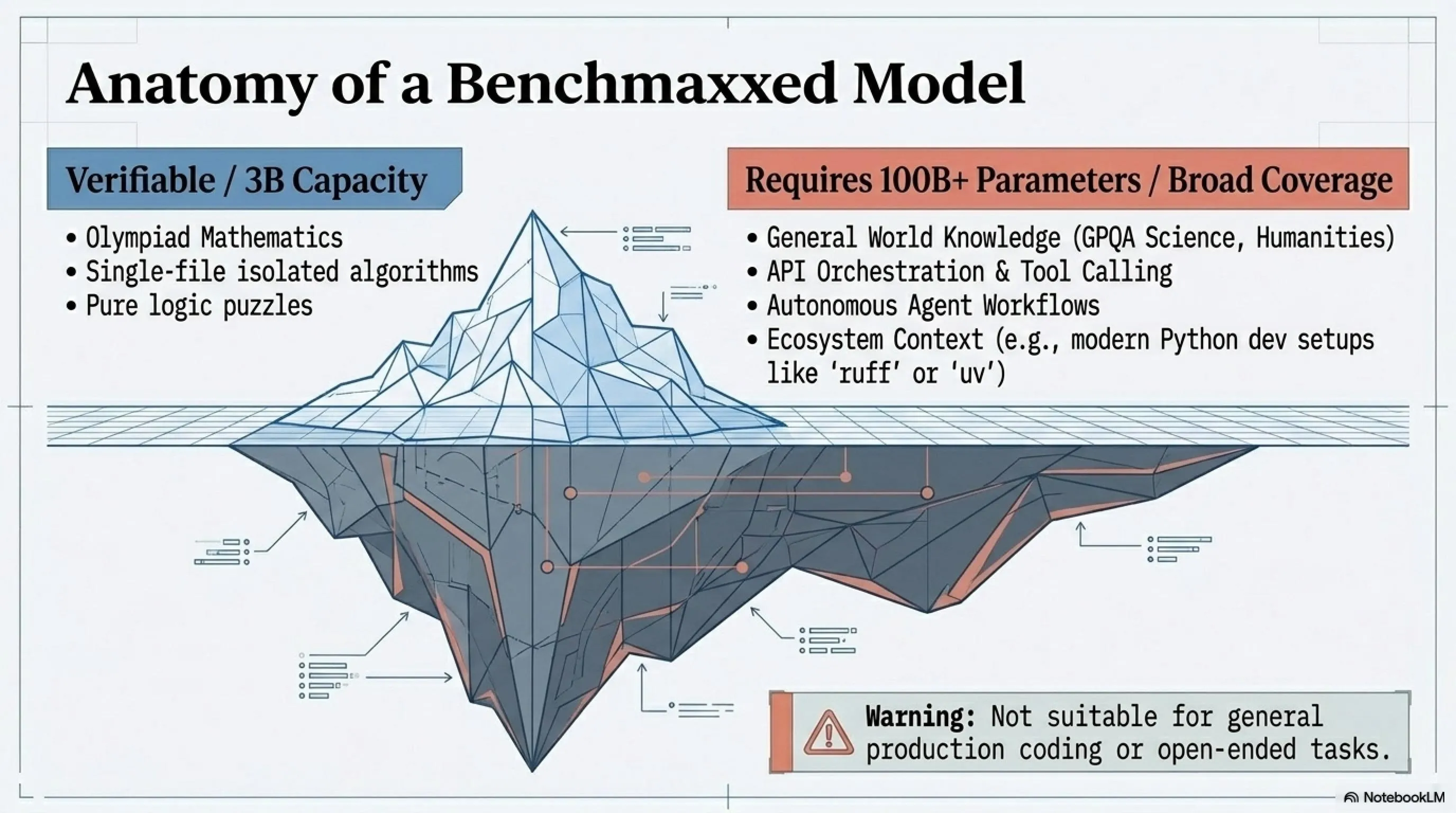
⚠️ Critical Warning: VibeThinker-3B Limitations
- ❌ Tool calling and API orchestration not supported
- ❌ General knowledge is very weak
- ❌ Not suitable for autonomous agents
- ❌ Doesn't recognize popular Python tools (like uv)
- ❌ Only useful for limited reasoning and coding tasks
📈 Interim Summary
Benchmark results show VibeThinker-3B truly shines in "verifiable" tasks (mathematics, coding) but fails in general knowledge and open-ended tasks. This is exactly what the authors claimed: reasoning compression, not knowledge. The main question is: do these results replicate in the real world?
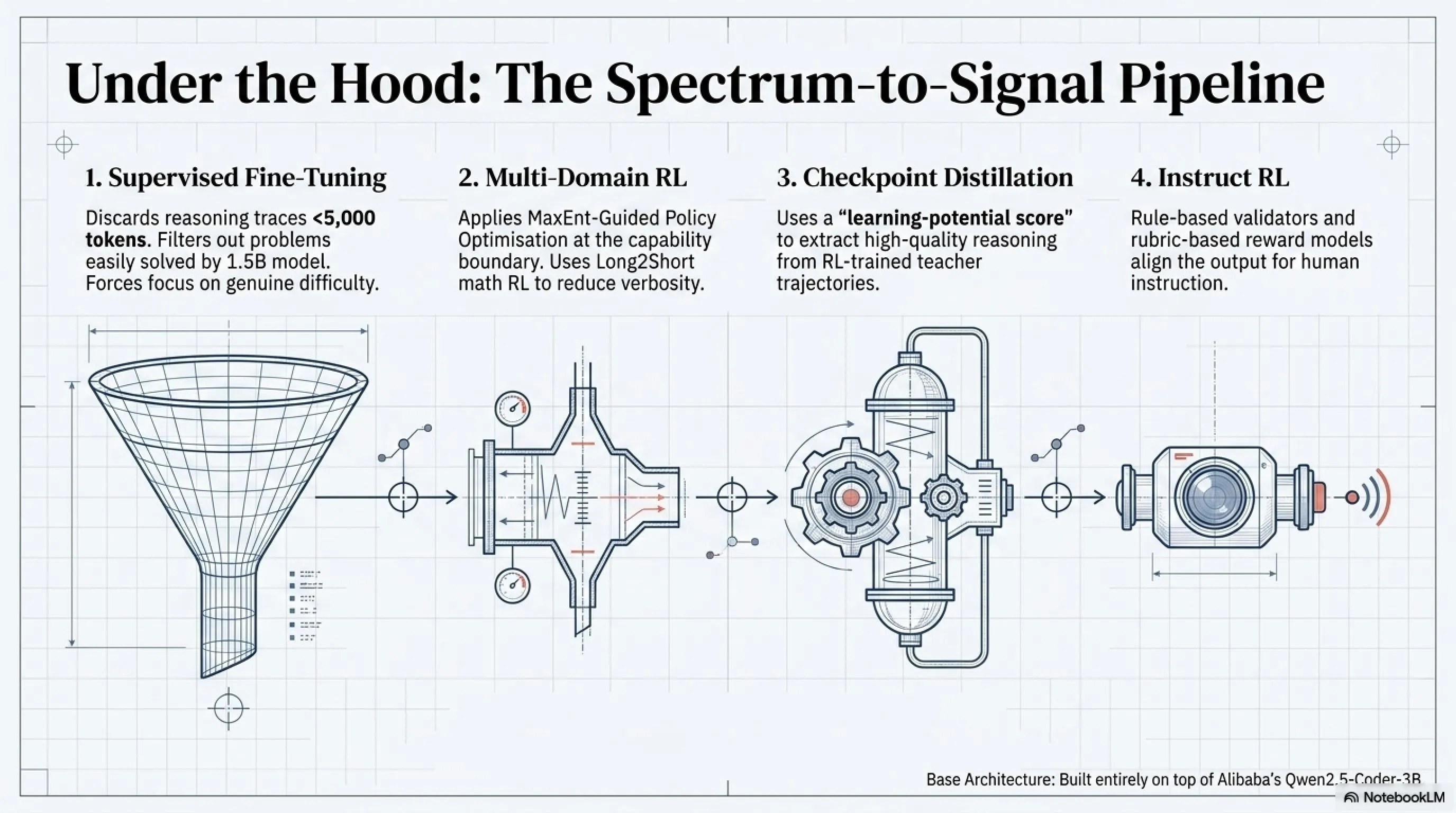
🏗️ VibeThinker-3B Architecture: The Four-Stage Training Pipeline
VibeThinker-3B wasn't built from scratch. It's post-training on top of Qwen2.5-Coder-3B—a compact foundation model from Alibaba's Qwen team. The Weibo researchers trained it through a four-stage pipeline they call the "Spectrum-to-Signal Principle".

🔬 The Four Training Stages of VibeThinker-3B
📚 Stage 1: Two-Phase Supervised Fine-Tuning
Phase 1A: The model first trains on a broad mixture of math, code, STEM reasoning, general dialogue, and instruction-following data.
Phase 1B: Then shifts to a curated subset of harder, longer-horizon reasoning problems:
• Samples with reasoning traces shorter than 5,000 tokens are discarded
• Problems that VibeThinker-1.5B can solve >75% of the time are filtered out
• Goal: Force the model to focus on genuinely difficult challenges
🤖 Stage 2: Multi-Domain Reinforcement Learning
RL is applied across three domains: mathematics, code, and STEM. The algorithm used is MGPO (MaxEnt-Guided Policy Optimization), which prioritizes training on problems at the model's current capability boundary—not problems it already solves easily or finds impossible.
Long2Short Math RL: A secondary optimization stage that redistributes rewards to favor shorter correct solutions, reducing verbosity without sacrificing accuracy.
💎 Stage 3: Distillation from RL Checkpoints
High-quality reasoning trajectories are extracted from RL-trained checkpoints and distilled back into a unified model through supervised fine-tuning. The team uses a "learning-potential score"—essentially the student model's perplexity on each teacher trajectory—to prioritize traces that are correct but the student hasn't yet internalized.
🎓 Stage 4: Instruct RL
The final phase applies reinforcement learning on instruction-following tasks using a combination of rule-based validators for format constraints and rubric-based reward models for open-ended quality assessment.
💡 The Parametric Compression-Coverage Hypothesis
The theoretical core of VibeThinker's work is the "Parametric Compression-Coverage Hypothesis". This hypothesis argues that different types of AI capability have fundamentally different relationships to model size:
🎯 Verifiable Reasoning
"Parameter-Dense Capability"
Compressible
Can fit in a compact core
- Mathematics
- Coding
- Logic
- Step-by-step reasoning
📚 Open-Domain Knowledge
"Parameter-Expansive Capability"
Needs Broad Coverage
Inherently requires more parameters
- General facts
- History
- Culture
- Specialized knowledge
The authors write: "The true significance of VibeThinker-3B does not lie in proving that a 3B model can replace large-scale generalists, but rather in providing a concrete empirical signal: the development of compact models is no longer merely a passive compromise for deployment efficiency or cost control; it emerges as a promising research trajectory that is fundamentally complementary to the traditional parameter scaling paradigm."
🧪 Hands-On Testing: Real-World Performance Beyond the Benchmarks
Time to step away from theory and test VibeThinker-3B ourselves. Is it really as good as the benchmarks suggest?
💻 Step-by-Step Installation Guide
🔧 Method 1: Using Hugging Face Transformers
pip install transformers torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "WeiboAI/VibeThinker-3B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
prompt = "Solve: What is the sum of all prime numbers less than 20?"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=500)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
⚡ Method 2: GGUF for Faster Execution (llama.cpp)
# Download GGUF version
wget https://huggingface.co/prithivMLmods/VibeThinker-3B-GGUF/resolve/main/vibethinker-3b.Q4_K_M.gguf
# Install llama.cpp
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp && make
# Run inference
./llama-cli -m vibethinker-3b.Q4_K_M.gguf -p "Calculate the factorial of 15"
🔍 Our Real-World Tests
We tested VibeThinker-3B with 10 math problems and 5 coding challenges we designed ourselves. Here are the results:
⚖️ Real-World Testing Verdict
✅ What VibeThinker Excels At:
• Pure math problems (algebra, arithmetic, geometry)
• Classic algorithms (sorting, searching, dynamic programming)
• LeetCode-style problems
❌ What VibeThinker Struggles With:
• Modern tool knowledge (uv, poetry, ruff)
• Coding with specific libraries (pandas, numpy)
• General knowledge questions
• API calling and tool usage
⚖️ Comprehensive Comparison: VibeThinker vs DeepSeek vs Qwen vs GPT
Now that we've tested VibeThinker, let's compare it head-to-head with its main competitors:
🎯 Benchmaxxing Exposed: Gaming Metrics or Genuine Innovation
Benchmaxxing is a term used in the AI community for models that appear optimized specifically for good benchmark performance at the expense of real-world utility.
✅ Evidence It's Real
- Post-cutoff LeetCode results
- Data leakage claims refuted
- Transparent training method
- Open-source model
- Community replicable
❌ Evidence of Benchmaxxing
- Users report practical weakness
- Lacks popular tool knowledge
- Only strong in specific tasks
- Benchmark vs reality gap
- Many limitations
💰 Economic Analysis: $7,800 vs Millions in Training Costs
One of VibeThinker's most compelling claims is its extremely low training cost. Let's examine the numbers:
💸 Training Cost Comparison
Cost Ratio: VibeThinker-3B costs only 2.7% of DeepSeek R1 while delivering similar results (on reasoning tasks). That's 38× better ROI!

🚀 The Future of Compact AI: Revolution or Limitation?
VibeThinker-3B proved that small models can compete with giants on specific tasks. But is this the future of AI?
🔮 Possible Future Scenarios
📡 Scenario 1: Hybrid Architecture
Specialized small models (like VibeThinker) for reasoning + large models for knowledge. Each does what it's best at.
🔄 Scenario 2: Complete Specialization
Instead of one large general model, dozens of small specialized models, each expert in one domain: math, code, writing, analysis, etc.
⚡ Scenario 3: Post-Training Breakthrough
Better training techniques can extract more capabilities from even smaller models. Maybe we don't need trillion-parameter models anymore.
⚔️ PROS & CONS: VibeThinker-3B Battle Box
✅ Pros
- Excellent math performance
- Extremely low cost
- Fast and lightweight
- Runs on laptop
- Open-source and free
- Perfect for edge deployment
❌ Cons
- Weak general knowledge
- No tool calling
- Limited to specific tasks
- Benchmark vs reality gap
- Doesn't know modern tools
- Not for general production
❓ Frequently Asked Questions (FAQ)
Is VibeThinker-3B really equal to 671B parameter models?
Long answer: VibeThinker-3B achieves similar results to DeepSeek V3.2 (671B) on benchmarks like AIME and LiveCodeBench. But on general knowledge, GPQA, and open-ended tasks, it's much weaker. This model is built for reasoning, not knowledge.
Is VibeThinker suitable for everyday coding?
• Doesn't know modern Python tools (uv, poetry, ruff)
• No tool calling support
• Struggles with popular libraries (pandas, numpy)
For real-world coding, stick with GPT-4, Claude, or Qwen.
What is benchmaxxing and is VibeThinker guilty of it?
Is VibeThinker benchmaxxed? It's hard to judge:
✅ Arguments against: Post-cutoff LeetCode results, transparent method, replicable
❌ Arguments for: User reports of practical weakness, benchmark vs reality gap
The truth is probably somewhere in between: VibeThinker is genuinely strong at reasoning, but not as much as benchmarks suggest.
How can I run VibeThinker-3B on my laptop?
• RAM: Minimum 8GB (16GB recommended)
• GPU: Optional (works on CPU too)
• Space: About 6GB
Quick install with GGUF:
wget https://huggingface.co/prithivMLmods/VibeThinker-3B-GGUF/resolve/main/vibethinker-3b.Q4_K_M.gguf./llama-cli -m vibethinker-3b.Q4_K_M.gguf -p "your prompt"
Should I use VibeThinker instead of GPT or Claude?
✅ Use VibeThinker if:
• You only need mathematical reasoning
• Solving algorithmic problems
• Cost is important
• Want to run on edge devices
❌ Don't use if:
• Need general knowledge
• Want tool calling
• Production coding
• Need general-purpose model
💡 Final Verdict: The Truth Behind VibeThinker-3B
🎯 Tekin's Final Judgment
VibeThinker-3B is neither a complete revolution nor pure illusion. It's a powerful proof of concept that demonstrates:
✅ What's Been Proven:
• Reasoning and knowledge are two different things
• Mathematical reasoning can be compressed into 3B parameters
• Post-training can work miracles
• Scaling Laws aren't absolute
❌ What Remains Questionable:
• Do these results replicate in production?
• Are benchmarks really good metrics?
• Can this approach generalize to other domains?
Conclusion: VibeThinker-3B shows a future where specialized small models work alongside general-purpose giants. This isn't the end of large models, but the beginning of intelligent hybrid architectures.
📚 Sources & References
2. Official Model on Hugging Face
3. GitHub Repository
4. VentureBeat Analysis: "Why Weibo's tiny VibeThinker-3B has the AI world arguing"
5. Community Testing Results on Hugging Face Discussions
6. DeepSeek V3 Technical Report
7. AIME 2026 Official Results
🌐 Stay Connected With Us 🎮✨
For the latest tech, gaming, and gadget news, follow us on our official social media channels:
Additional Gallery: 🧠 VibeThinker-3B: Revolution or Illusion? The Tiny AI Model Shocking the Industry 🚀