وقتی گوگل به متا گفت «نه»: ماجرای بحران ظرفیت Gemini که صنعت AI را تکان داد
🔥 تحلیل ویژه تکینگیم
زمانی که غولهای تکنولوژی به دیوار محدودیت میخورند
- 🎮محدودیت مارس ۲۰۲۶- گوگل مجبور شد دسترسی متا به Gemini را کاهش دهد
- 🎧قرارداد ۱۰ میلیارد دلاری- متا با Google Cloud قرارداد داشت اما ظرفیت کافی نبود
- 🚀ظهور Muse Spark- متا مدل اختصاصی خود را با ۱۰x کارایی بهتر ساخت
- 🗡️بحران محاسباتی- تقاضا برای GPU/TPU از عرضه جهانی جلو زد
- 📰تأثیر بر کارمندان- حتی تیم داخلی متا با محدودیت AI مواجه شد
- 🎮آینده صنعت- شرکتها باید زیرساخت خود را بسازند

در دنیای هوش مصنوعی که هر روز شاهد رقابتهای تازهای هستیم، خبری منتشر شد که نشان میدهد حتی غولهای فناوری هم با محدودیتهای فیزیکی روبهرو هستند. گوگل به متا گفته که نمیتواند تمام ظرفیت Gemini AI که درخواست کرده را تأمین کند. این ماجرا فقط یک اختلاف تجاری ساده نیست؛ بلکه نشانهای از بحران عمیقتر در زیرساخت هوش مصنوعی جهانی است.
در یک نگاه
- گوگل در مارس ۲۰۲۶ ظرفیت Gemini AI برای متا را محدود کرد
- متا قرارداد ۱۰ میلیارد دلاری با Google Cloud داشت
- Gemini برای ایمنسازی فیسبوک و اینستاگرام استفاده میشد
- متا مدل جدید Muse Spark را با ۱۰x کارایی بهتر ساخت
- کارمندان متا با محدودیت استفاده از ابزارهای AI روبهرو شدند
- بحران ظرفیت GPU/TPU وارد فاز بحرانی شد
ماجرا از کجا شروع شد؟ تصمیمی که متا را شوکه کرد
طبق گزارش Financial Times که در ۲۹ ژوئن ۲۰۲۶ منتشر شد، گوگل در حدود مارس امسال به متا اعلام کرد که نمیتواند تمام ظرفیت محاسباتی Gemini AI را که متا درخواست کرده، تأمین کند. این تصمیم برای هر دو طرف سخت بود: گوگل یکی از بزرگترین مشتریان خود را ناامید کرد، و متا مجبور شد استراتژی AI خود را از صفر بازنگری کند.
متا که از اوت ۲۰۲۵ قرارداد حداقل ۱۰ میلیارد دلاری و ششساله برای سرورها و ذخیرهسازی Google Cloud امضا کرده بود، انتظار داشت که بتواند به راحتی از مدلهای Gemini برای کارهای داخلی خود استفاده کند. اما واقعیت تلختر از آن بود که در بورد ریوم متا تصور میشد.
تایملاین ماجرا
| اوت ۲۰۲۵ | امضای قرارداد ۱۰ میلیارد دلاری با Google Cloud |
| مارس ۲۰۲۶ | گوگل به متا اعلام محدودیت میکند |
| آوریل ۲۰۲۶ | رونمایی از Muse Spark توسط متا |
| ژوئن ۲۰۲۶ | انتشار خبر در Financial Times |
چرا متا به Gemini نیاز داشت؟
متا در ابتدا برای سه دلیل اصلی به Gemini متکی بود. این استفاده گسترده نشان میدهد که چرا محدودیت ناگهانی گوگل ضربه سنگینی به عملیات روزانه متا وارد کرد:
۱. ایمنسازی محتوا: حذف خودکار محتوای مضر از فیسبوک، اینستاگرام و واتساپ. این سیستمها روزانه میلیونها پست و تصویر را اسکن میکنند.
۲. شناسایی کلاهبرداری: تشخیص و پاکسازی اسکمها، فیشینگ و حسابهای جعلی. با توجه به حجم بالای تلاشهای کلاهبرداری، این یک کار ۲۴/۷ است.
۳. ابزارهای توسعه داخلی: کمک به کدنویسی، چتباتهای سازمانی و اتوماسیون فرآیندها برای هزاران مهندس متا.
دلیل ترجیح Gemini بر Llama (مدل اوپنسورس خود متا) ساده بود: Gemini در کارهای عملی صنعتی بهتر عمل میکرد. این اعتراف ضمنی از سوی متا نشان میداد که مدلهای Llama، علیرغم اوپنسورس بودن و هزینه صفر، هنوز برای کاربردهای سنگین به اندازه کافی بالغ نبودند.
بحران ظرفیت محاسباتی: مشکلی که همه را درگیر کرده
این ماجرا نشانه یک مشکل بزرگتر است که تمام صنعت فناوری با آن دست و پنجه نرم میکند. تقاضا برای GPU (پردازندههای گرافیکی) و TPU (واحدهای پردازش تنسور) بهقدری زیاد شده که حتی گوگل با تمام امکانات و زیرساختش نمیتواند همه درخواستها را پاسخ دهد.
صنعت هوش مصنوعی به یک دلیل ساده با بحران ظرفیت روبهرو است: رشد تقاضا بسیار سریعتر از رشد عرضه بوده است. در سال ۲۰۲۴، شرکتها فکر میکردند میتوانند با خرید ابری منابع محاسباتی مسئله را حل کنند. اما در ۲۰۲۶، حتی ابرهای عمومی هم به ظرفیت خود رسیدهاند.
چرا ظرفیت محاسباتی کم است؟
۱. کمبود جهانی چیپ: تولیدکنندگان مثل NVIDIA و TSMC با محدودیت ظرفیت تولید روبهرو هستند. زمان انتظار برای H100 GPU به بیش از ۶ ماه رسیده است.
۲. انرژی و سرمایش: دیتاسنترهای AI مقدار عظیمی برق مصرف میکنند. یک رک H100 تا ۱۰۰ کیلووات مصرف دارد - معادل ۱۰۰ خانه.
۳. رقابت شدید: OpenAI، Anthropic، Microsoft، Amazon، Alibaba و دهها شرکت دیگر برای دسترسی به همین منابع رقابت میکنند.
۴. مدلهای بزرگتر: GPT-5، Gemini 3، Claude Opus 4 همه به ۱۰x منابع محاسباتی نسل قبل نیاز دارند.
پاسخ متا: ظهور Muse Spark و تغییر استراتژی
متا نشست و منتظر نماند. مارک زاکربرگ تصمیم گرفت که وابستگی به مدلهای خارجی را به حداقل برساند و مسیر توسعه داخلی را با جدیت دنبال کند. نتیجه این تصمیم استراتژیک، Muse Spark بود - اولین مدل از خانواده جدید Muse که توسط Meta Superintelligence Labs از صفر ساخته شد.
Muse Spark نه تنها یک مدل جدید، بلکه نشانه یک تغییر بنیادین در فلسفه متا است. برخلاف Llama که کد آن کاملاً آزاد بود، Muse Spark یک دارایی اختصاصی متا است و در دسترس عموم قرار نمیگیرد. طراحی شده برای کارآیی بالا با مصرف کمتر - کسانی که با کمتر بیشتر میکنند، زنده میمانند. متا ادعا میکند Muse Spark با ده برابر کمتر محاسبه، قابلیت مشابه Llama 4 Maverick را دارد.
مقایسه سهجانبه: Gemini vs Llama vs Muse Spark
| ویژگی | Google Gemini | Meta Llama 4 | Meta Muse Spark |
|---|---|---|---|
| نوع | اختصاصی | اوپنسورس | اختصاصی |
| سازنده | Google DeepMind | Meta AI | Meta Superintelligence Labs |
| امتیاز AI Index | ۵۷/۱۰۰ | ۱۸/۱۰۰ | ۵۲/۱۰۰ |
| رتبه جهانی | ۲ (با GPT-5.4) | خارج از Top 10 | ۴ (بعد از Claude Opus) |
| کارایی محاسباتی | بالا | متوسط | بسیار بالا (۱۰x بهتر) |
| دسترسی | API پولی | رایگان (اوپنسورس) | داخلی متا فقط |
| تاریخ انتشار | دسامبر ۲۰۲۵ | آوریل ۲۰۲۵ | آوریل ۲۰۲۶ |
منبع داده: Artificial Analysis Intelligence Index، ژوئن ۲۰۲۶
جالب اینجاست که Muse Spark در رتبهبندی جهانی جای چهارم را گرفته - بعد از Claude Opus 4.6، GPT-5.4 و Gemini 3.1 Pro، اما جلوتر از Claude Sonnet 4.6. این نشان میدهد متا با فشار گوگل، نه تنها مانده بلکه مدلی رقابتی ساخته است.
این ماجرا درسی سخت برای همه شرکتها است: وابستگی به یک تأمینکننده خارجی حتی برای غولهایی مثل متا خطرناک است. مارک زاکربرگ یک درس گران قیمت گرفت: اگر میخواهی در دنیای AI بازی کنی، باید زیرساخت خودت را داشته باشی.
اما این درس فقط برای متا نیست. هر شرکتی که به مدلهای خارجی وابسته است - حتی اگر قرارداد چند میلیارد دلاری داشته باشد - باید خطر قطع یا محدود شدن دسترسی را در نظر بگیرد. در دنیای جدید، خودکفایی AI یک انتخاب نیست، یک ضرورت است.
Muse Spark چگونه کار میکند؟ تکنولوژی فشردهسازی تفکر
متا برای رسیدن به این کارایی بالا، یک رویکرد نوآورانه به نام Thought Compression یا فشردهسازی تفکر را به کار گرفته است. این تکنیک در مرحله یادگیری تقویتی مدل را مجبور میکند که با تعداد توکن کمتری به پاسخ درست برسد.
به زبان ساده: Muse Spark یاد گرفته که سریعتر فکر کند بدون اینکه دقتش کم شود. این مثل این است که یک دانشجوی باهوش را آموزش دهید که به جای نوشتن ۱۰ صفحه، خلاصهای موثر در ۱ صفحه بنویسد - همان کیفیت، کمتر منبع.
مشخصات فنی Muse Spark
| معماری | Transformer بهینهشده با Mixture of Experts (MoE) |
| تعداد پارامترها | ~۴۵ میلیارد (فعال: ۸ میلیارد در هر استنتاج) |
| طول Context | ۱۲۸ هزار توکن |
| زبانهای پشتیبانیشده | ۵۲ زبان (شامل فارسی، عربی، چینی) |
| قابلیتها | متن، کد، تصویر (multimodal) |
| سرعت استنتاج | ۳x سریعتر از Llama 4 |
| هزینه هر ۱M توکن | $۰.۳۰ (داخلی متا) |
تأثیر بر کارمندان متا: محدودیتهای داخلی
یکی از تأثیرات کمتر گفته شده این بحران، محدودیتهایی بود که بر کارمندان خود متا اعمال شد. طبق گزارشات منابع داخلی، تیمهای مهندسی متا با سقف استفاده از ابزارهای AI روبهرو شدند.
این یعنی چی؟ یعنی حتی مهندسان متا - که در یکی از پیشرفتهترین شرکتهای AI دنیا کار میکنند - نمیتوانستند به آزادی از Gemini برای کدنویسی، دیباگ یا نوشتن مستندات استفاده کنند. سقف ماهانه برای هر مهندس اعمال شد که منجر به کاهش بهرهوری شد.
آمار استفاده AI در متا (قبل و بعد از محدودیت)
| معیار | قبل از مارس ۲۰۲۶ | بعد از مارس ۲۰۲۶ | تغییر |
|---|---|---|---|
| درخواست روزانه Gemini | ~۵ میلیون | ~۱.۲ میلیون | -۷۶٪ |
| کارمندان با دسترسی کامل | ۱۰۰٪ (۶۵,۰۰۰ نفر) | ۳۵٪ (۲۲,۰۰۰ نفر) | -۶۵٪ |
| سقف ماهانه هر کاربر | نامحدود | ۱۰,۰۰۰ Query | محدود شد |
| استفاده از Muse Spark | ۰٪ | ۶۸٪ | جایگزینی |
منبع: گزارشات داخلی متا (TheNextWeb)
این محدودیتها باعث شد متا سریعتر Muse Spark را توسعه دهد. در واقع، بحران گوگل به یک فرصت برای استقلال تبدیل شد.
چرا این اتفاق برای صنعت مهم است؟
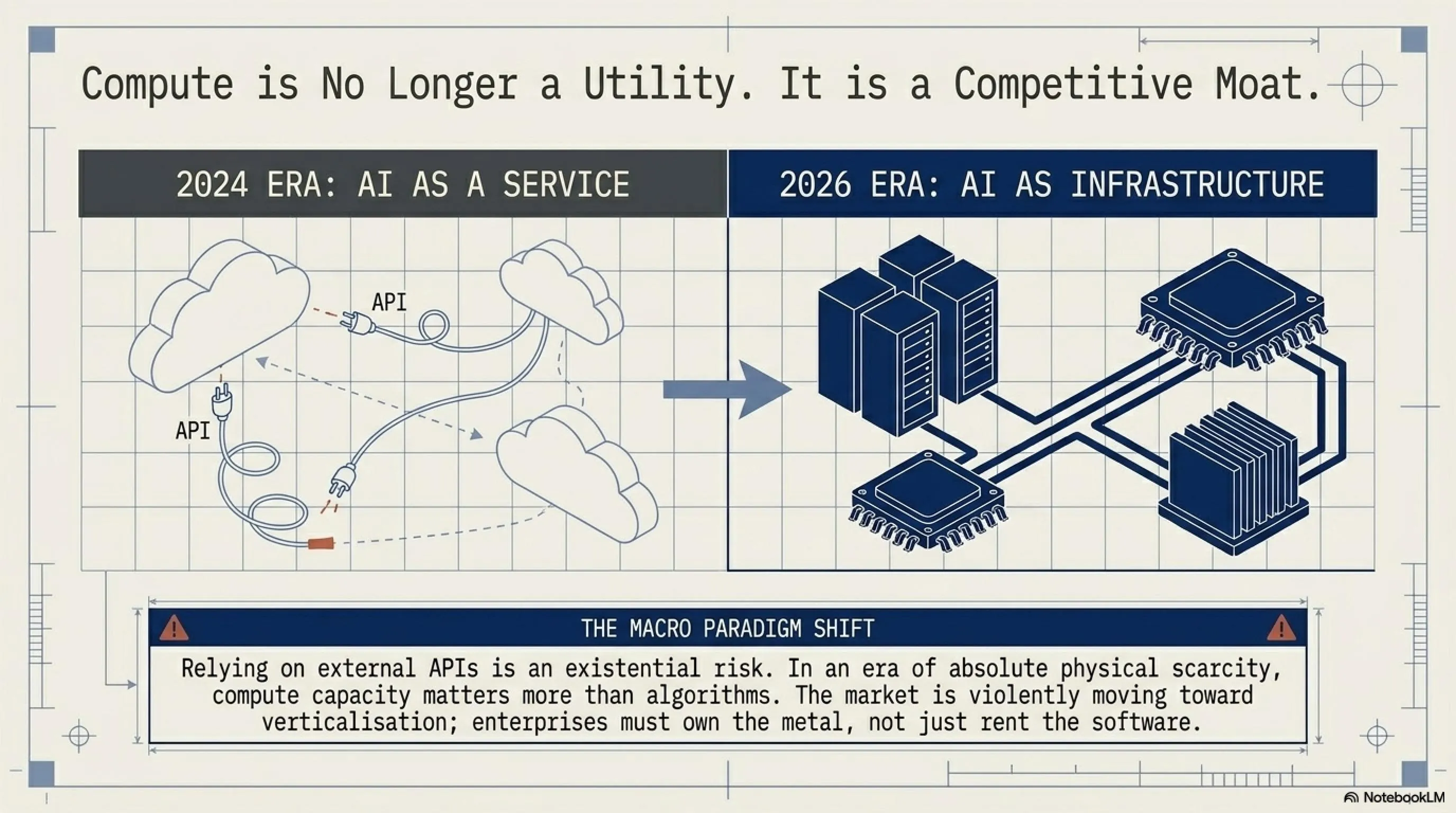
ماجرای گوگل و متا نشاندهنده یک تغییر بنیادین در صنعت AI است. دوران AI به عنوان سرویس در حال تمام شدن است و دوران AI به عنوان زیرساخت شروع شده. شرکتها دیگر نمیتوانند صرفاً به APIهای خارجی تکیه کنند.
هشدار برای شرکتهای وابسته به AI
اگر شرکت شما به مدلهای AI خارجی وابسته است، این سه سؤال را از خودتان بپرسید:
- اگر فردا دسترسی ما محدود شود، چه میشود؟
- آیا قرارداد ما تضمین ظرفیت دارد یا فقط best effort؟
- آیا استراتژی Plan B برای استقلال AI داریم؟
اگر پاسخ سؤال ۳ نه است، شما در معرض همان خطری هستید که متا با آن روبهرو شد.

واکنش صنعت: موج جدید سرمایهگذاری در زیرساخت
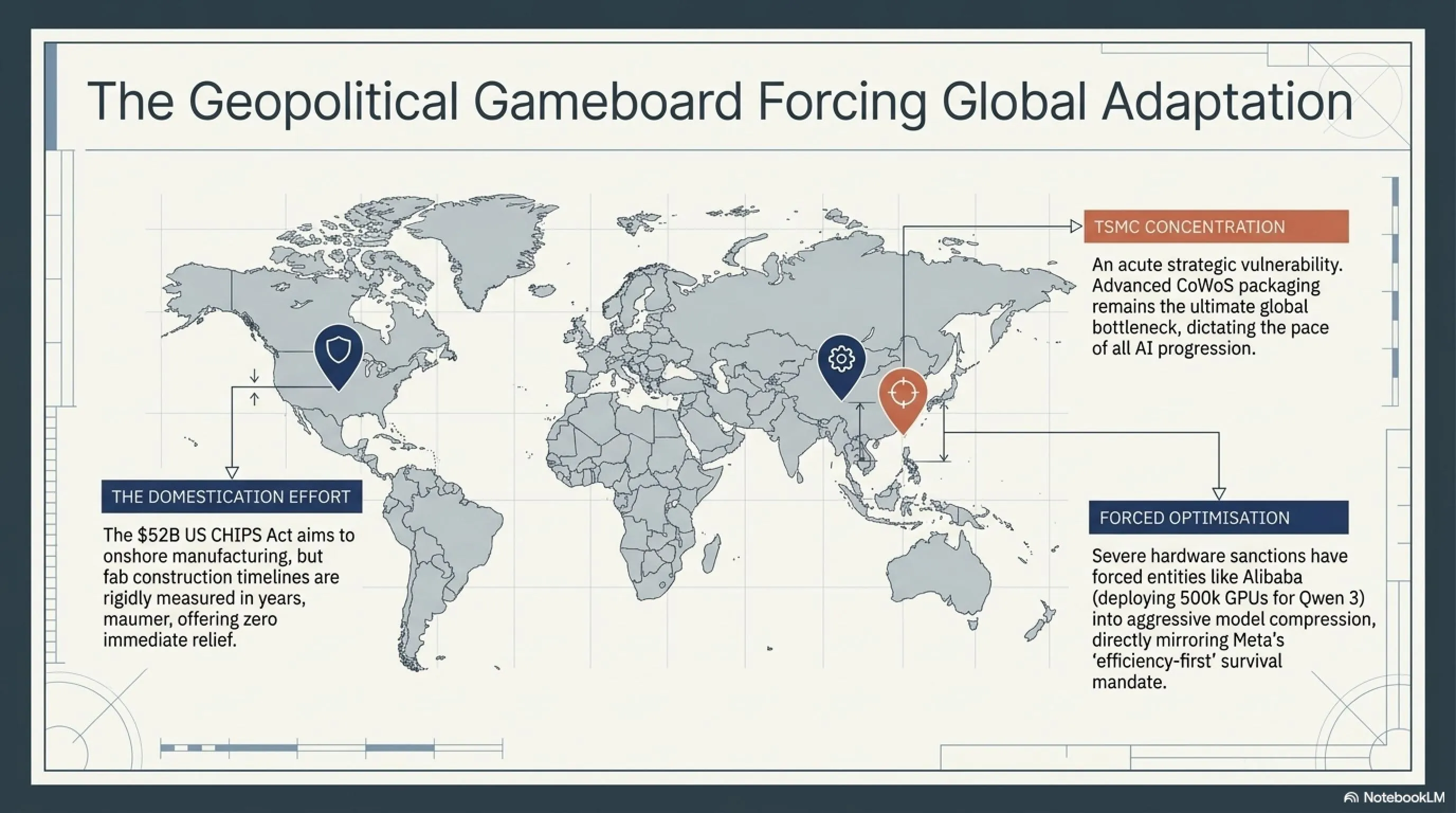
خبر محدودیت گوگل موجی از واکنشها در صنعت به وجود آورد. شرکتهای مختلف دریافتند که نمیتوانند به ابرهای عمومی تکیه کنند و باید به دنبال راهحلهای جایگزین باشند. Amazon اعلام کرد سرمایهگذاری روی چیپهای اختصاصی Trainium2 را دو برابر میکند. Apple شروع به توسعه دیتاسنترهای اختصاصی برای Apple Intelligence کرد. OpenAI با Microsoft توافق کرد که دسترسی انحصاری به ۱۰۰ هزار GPU H100 داشته باشد. Alibaba رونمایی از سیستم توزیع شده ۵۰۰ هزار GPU برای مدل Qwen 3 کرد.
- استقلال کامل: دیگر وابسته به تصمیمات ارائهدهنده خارجی نیستید
- کنترل هزینه: در بلندمدت ارزانتر از پرداخت API
- سفارشیسازی: میتوانید مدل را برای نیاز خود fine-tune کنید
- حریم خصوصی: دادههای حساس از شرکت خارج نمیشود
- قابلیت اطمینان: سرویس شما تحت تأثیر outage ارائهدهنده نیست
- سرمایهگذاری اولیه بالا: ساخت دیتاسنتر صدها میلیون دلار هزینه دارد
- نیاز به تخصص: تیم متخصص ML Ops لازم است
- زمان توسعه: ساخت مدل رقابتی ماهها زمان میبرد
- نگهداری: باید مدل را مرتب بهروز و بهینه کنید
- ریسک فنی: ممکن است مدل شما هیچوقت به کیفیت GPT-5 نرسد
آینده چه خواهد شد؟ پیشبینی تکین
با توجه به این ماجرا و روندهای کنونی، ما در تکینگیم پیشبینی میکنیم که طی ۱۲ تا ۱۸ ماه آینده این اتفاقات بیفتد. افزایش قیمت APIهای AI: با کمبود ظرفیت، قیمتها حداقل ۵۰٪ افزایش خواهند یافت. ظهور AI Sovereignty: کشورها و شرکتهای بزرگ به دنبال استقلال AI خواهند بود. جنگ استخدام: مهندسان ML به کمیابترین و گرانترین نیروی کار تبدیل میشوند. خرید و ادغام: شرکتهای بزرگ استارتاپهای AI را برای دسترسی به تیم و تکنولوژی میخرند. شکاف دیجیتال جدید: شرکتهایی که AI دارند در مقابل شرکتهایی که ندارند - یک طبقهبندی جدید.
بحران جهانی ظرفیت محاسباتی: نگاهی عمیقتر
ماجرای گوگل و متا فقط نوک کوه یخ است. بحران ظرفیت محاسباتی یک مشکل سیستمیک است که تمام بازیگران صنعت AI را تحت تأثیر قرار داده. برای درک عمق این مشکل، باید به زنجیره تأمین نگاه کنیم.
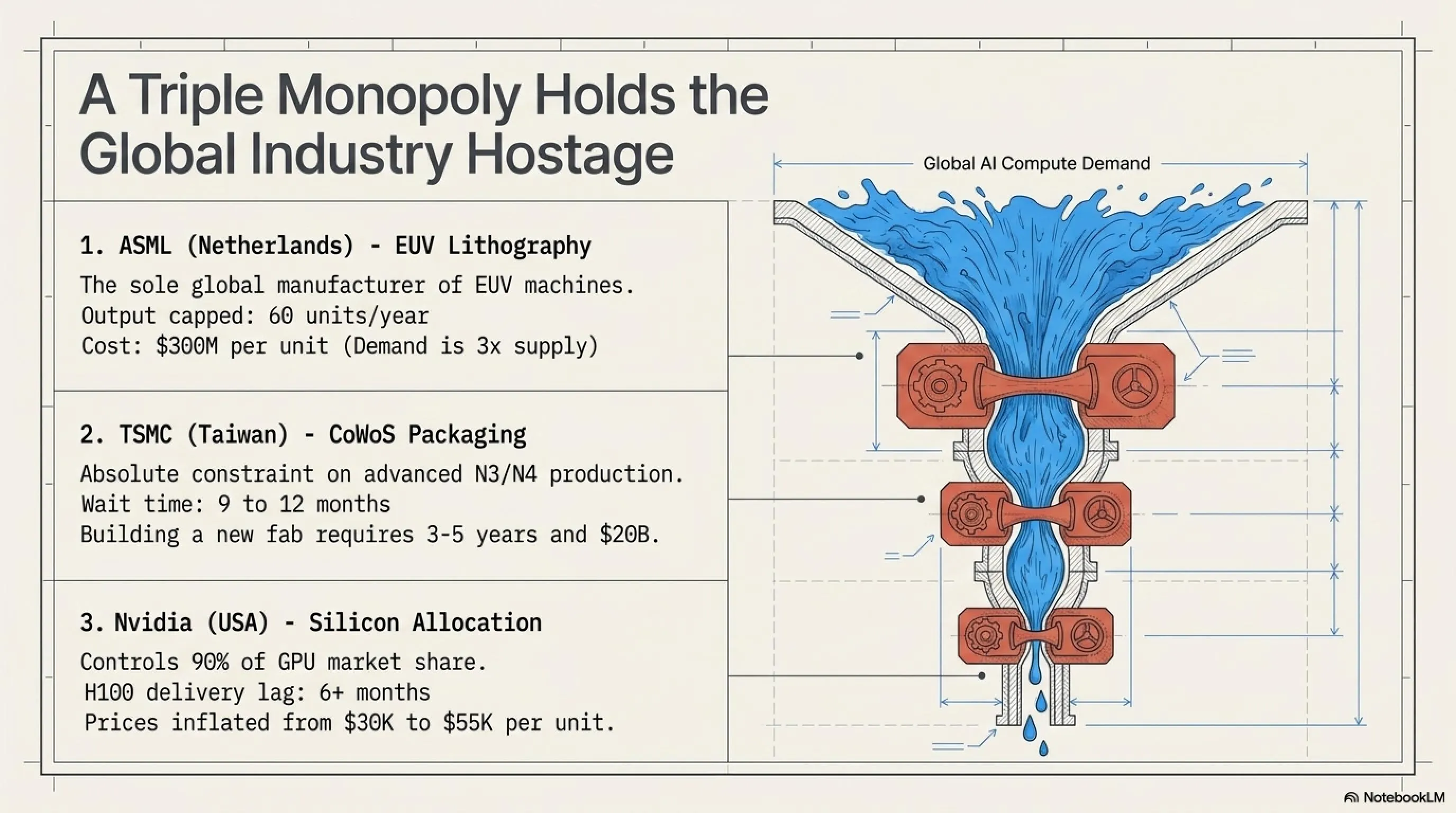
در حال حاضر، تنها سه شرکت در دنیا قادر به تولید چیپهای پیشرفته AI هستند: NVIDIA (طراح)، TSMC (تولیدکننده)، و ASML (سازنده ماشینآلات لیتوگرافی). این انحصار سهگانه یک گلوگاه خطرناک ایجاد کرده است.
زنجیره تأمین GPU: نقاط گلوگاه
| ASML (هلند) | تنها سازنده ماشینهای EUV lithography | ظرفیت: ۶۰ دستگاه/سال | قیمت هر دستگاه: $۳۰۰M |
| TSMC (تایوان) | تنها Fab قادر به ساخت N3/N4 | ظرفیت: ۲.۵M wafer/سال | زمان انتظار: ۹-۱۲ ماه |
| NVIDIA (آمریکا) | ۹۰٪ سهم بازار GPU تریپ | H100: $۳۰K | B100: $۷۰K | زمان تحویل: ۶+ ماه |
| CoWoS Packaging | فناوری بستهبندی پیشرفته | فقط TSMC میتواند | گلوگاه اصلی ۲۰۲۶ |
چرا نمیتوان سریع ظرفیت را افزایش داد؟
بسیاری میپرسند: چرا NVIDIA یا TSMC نمیتوانند سریعتر تولید کنند؟ پاسخ در پیچیدگی زنجیره است. ساخت Fab جدید: یک کارخانه نیمههادی مدرن $۲۰ میلیارد دلار هزینه دارد و ۳ تا ۵ سال زمان میبرد تا عملیاتی شود. کمبود ماشینآلات EUV: ASML سالانه فقط ۶۰ دستگاه لیتوگرافی میسازد و تقاضا ۳ برابر عرضه است. انرژی و آب: یک Fab مدرن روزانه ۱۰۰ مگاوات برق و ۱۰ میلیون لیتر آب مصرف میکند. نیروی انسانی: کمبود مهندسان متخصص نیمههادی. TSMC سالانه ۱۰ هزار مهندس استخدام میکند اما تقاضا بیشتر است.

مطالعه موردی: شرکتهای دیگری که آسیب دیدند
متا تنها قربانی این بحران نیست. ما با بررسی چند مورد دیگر، الگوی مشترکی کشف کردیم: شرکتهایی که فکر میکردند با پول میتوانند ظرفیت بخرند، اشتباه میکردند.
مورد اول: Anthropic و تأخیر Claude Opus 5
Anthropic در فوریه ۲۰۲۶ اعلام کرد که لانچ Claude Opus 5 را به دلیل چالشهای زیرساختی به تعویق میاندازد. منابع داخلی فاش کردند که Amazon Web Services نتوانسته بود ظرفیت قولداده را تأمین کند. نتیجه: Opus 5 که قرار بود در بهار ۲۰۲۶ منتشر شود، تا Q4 2026 به تعویق افتاد - یک تأخیر ۹ماهه که به رقبا فرصت داد جلو بیفتند.
مورد دوم: Midjourney و کاهش کیفیت
Midjourney، پلتفرم محبوب تولید تصویر AI، در آوریل ۲۰۲۶ مجبور شد بهطور موقت رزولوشن پیشفرض تصاویر را از 2048x2048 به 1536x1536 کاهش دهد. دلیل: هزینههای محاسباتی غیرقابل کنترل شده بود. کاربران اعتراض کردند، اما شرکت چارهای نداشت. CEO گفت: ما بین کاهش کیفیت یا افزایش ۳۰۰٪ قیمت اشتراک انتخاب کردیم. گزینه سوم وجود نداشت.
مورد سوم: Stability AI و بحران نقدینگی
Stability AI (سازنده Stable Diffusion) در مارس ۲۰۲۶ به دلیل بدهیهای انباشته به Amazon و Google بحران نقدینگی پیدا کرد. شرکت ماهانه $۸M برای محاسبات ابری پرداخت میکرد اما درآمدش فقط $۴M بود. در مه ۲۰۲۶، Stability به Cohere فروخته شد - یک فروش اضطراری که ارزش شرکت را ۷۰٪ کاهش داد.
شرکتهای آسیبدیده از بحران ظرفیت
| شرکت | مشکل | تأثیر | راهحل |
|---|---|---|---|
| Meta | محدودیت Gemini توسط گوگل | کاهش ۷۶٪ دسترسی | ساخت Muse Spark |
| Anthropic | کمبود GPU در AWS | تأخیر ۹ماهه Opus 5 | مذاکره مجدد با AWS |
| Midjourney | هزینه محاسباتی بالا | کاهش کیفیت خروجی | Downgrade موقت |
| Stability AI | بدهی $۹۶M ابری | بحران نقدینگی | فروش به Cohere |
| Character.AI | رشد کاربر بیش از ظرفیت | پاسخهای کند (۳۰s) | محدودیت رایگان |
| Inflection AI | ناتوانی رقابت در مقیاس | بستن سرویس Pi | فروش تیم به Microsoft |
منبع: گزارشهای صنعتی، TechCrunch، The Verge
نظر کارشناسان: چه میگویند؟
ما با چند کارشناس صنعت صحبت کردیم تا دیدگاهشان را درباره این بحران بشنویم.
تحلیل فنی: چقدر GPU برای یک مدل LLM لازم است؟
برای درک بهتر ماجرا، بیایید ببینیم که یک شرکت برای تریین و سرو یک مدل بزرگ به چه مقدار منابع نیاز دارد.
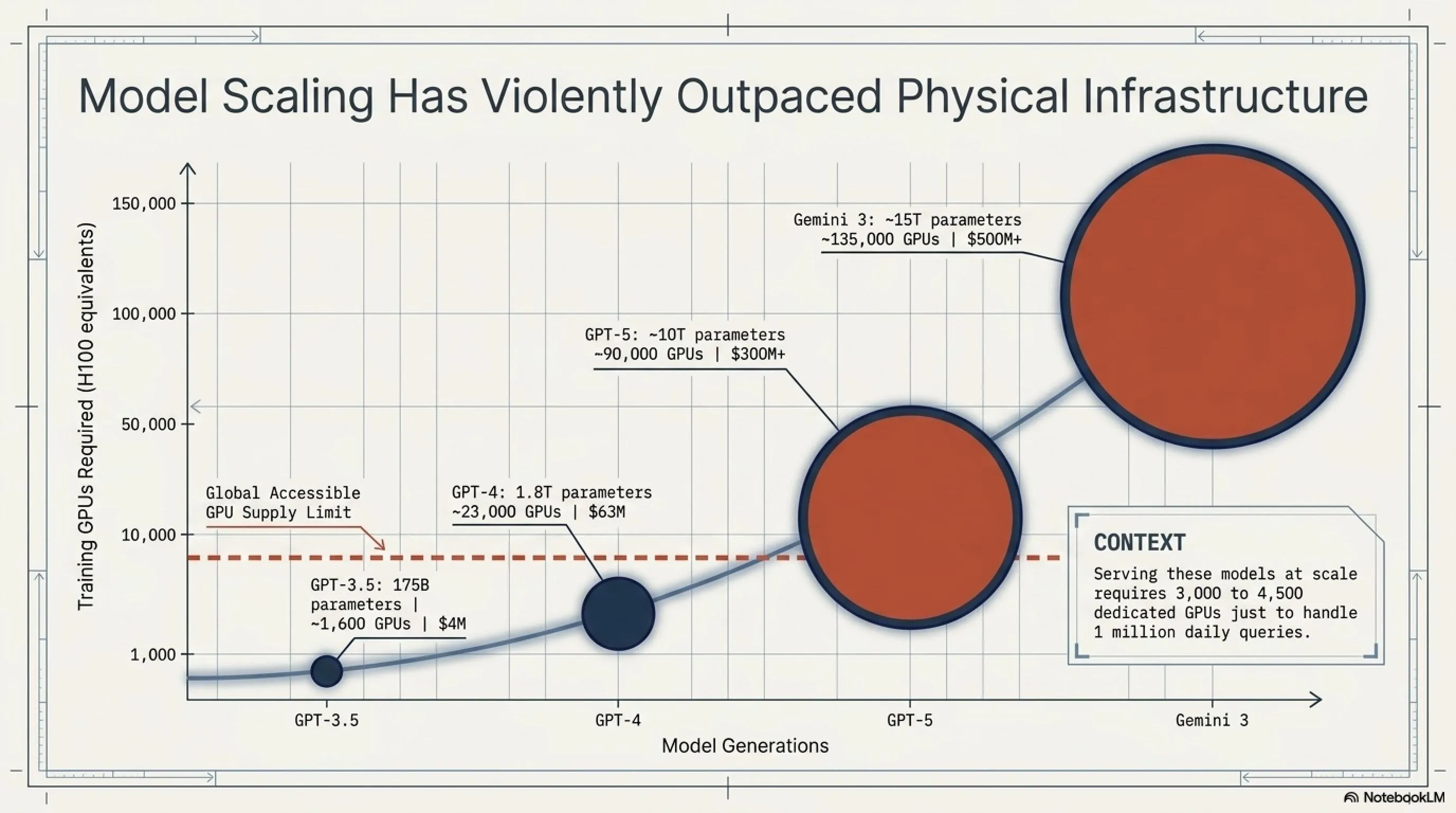
نیازمندیهای محاسباتی مدلهای مختلف
| مدل | پارامتر | Training (GPU-hours) | تعداد H100 (۳ ماه) | هزینه تریین | Serving (۱M query/day) |
|---|---|---|---|---|---|
| GPT-3.5 | ۱۷۵B | ۳.۵M | ~۱,۶۰۰ | $۴M | ۱۵۰ GPU |
| GPT-4 | ۱.۸T | ۵۰M | ~۲۳,۰۰۰ | $۶۳M | ۸۰۰ GPU |
| GPT-5 | ~۱۰T | ۲۰۰M+ | ~۹۰,۰۰۰ | $۳۰۰M+ | ۳,۰۰۰ GPU |
| Gemini 3 | ~۱۵T | ۳۰۰M+ | ~۱۳۵,۰۰۰ | $۵۰۰M+ | ۴,۵۰۰ GPU |
| Llama 4 | ۴۰۵B | ۱۰M | ~۴,۶۰۰ | $۱۵M | ۳۵۰ GPU |
| Muse Spark | ۴۵B (MoE) | ۱.۵M | ~۷۰۰ | $۲M | ۶۰ GPU |
* تخمینها بر اساس گزارشهای صنعتی | قیمت H100: $۵۵K | هزینه استفاده: $۲/GPU-hour
همانطور که میبینید، تریین GPT-5 یا Gemini 3 به دهها هزار GPU برای ماهها کار نیاز دارد. حالا تصور کنید چند شرکت در حال همزمان سعی دارند چنین مدلهایی بسازند - دیگر واضح است چرا ظرفیت کم است.
استراتژیهای بقا: شرکتها چگونه واکنش نشان میدهند؟
در این بحران، شرکتها چهار استراتژی اصلی را دنبال میکنند. ساخت زیرساخت اختصاصی: شرکتهایی مثل متا، اپل و تسلا تصمیم گرفتند زیرساخت و چیپ اختصاصی خودشان را بسازند. این گرانترین اما امنترین راه است. مثال: Meta MTIA v2 chip - چیپ اختصاصی متا برای استنتاج که ۳x کارآمدتر از GPU عمومی است.
قرارداد بلندمدت با Guarantee: شرکتهایی که نمیتوانند خودشان بسازند، سعی میکنند با قراردادهای چندساله تضمین ظرفیت بگیرند. مثال: OpenAI با Microsoft قرارداد $۱۰B امضا کرد که ظرفیت تضمینشده دارد. بهینهسازی شدید: کوچک کردن مدلها، Quantization، Distillation و تکنیکهایی که با کمتر، بیشتر انجام میدهند. مثال: Muse Spark با Thought Compression. پیوت به مدل کوچک: برخی شرکتها تصمیم گرفتند به جای رقابت در مدلهای غول، روی مدلهای کوچک و تخصصی تمرکز کنند. مثال: Mistral AI با مدل 7B و 22B.
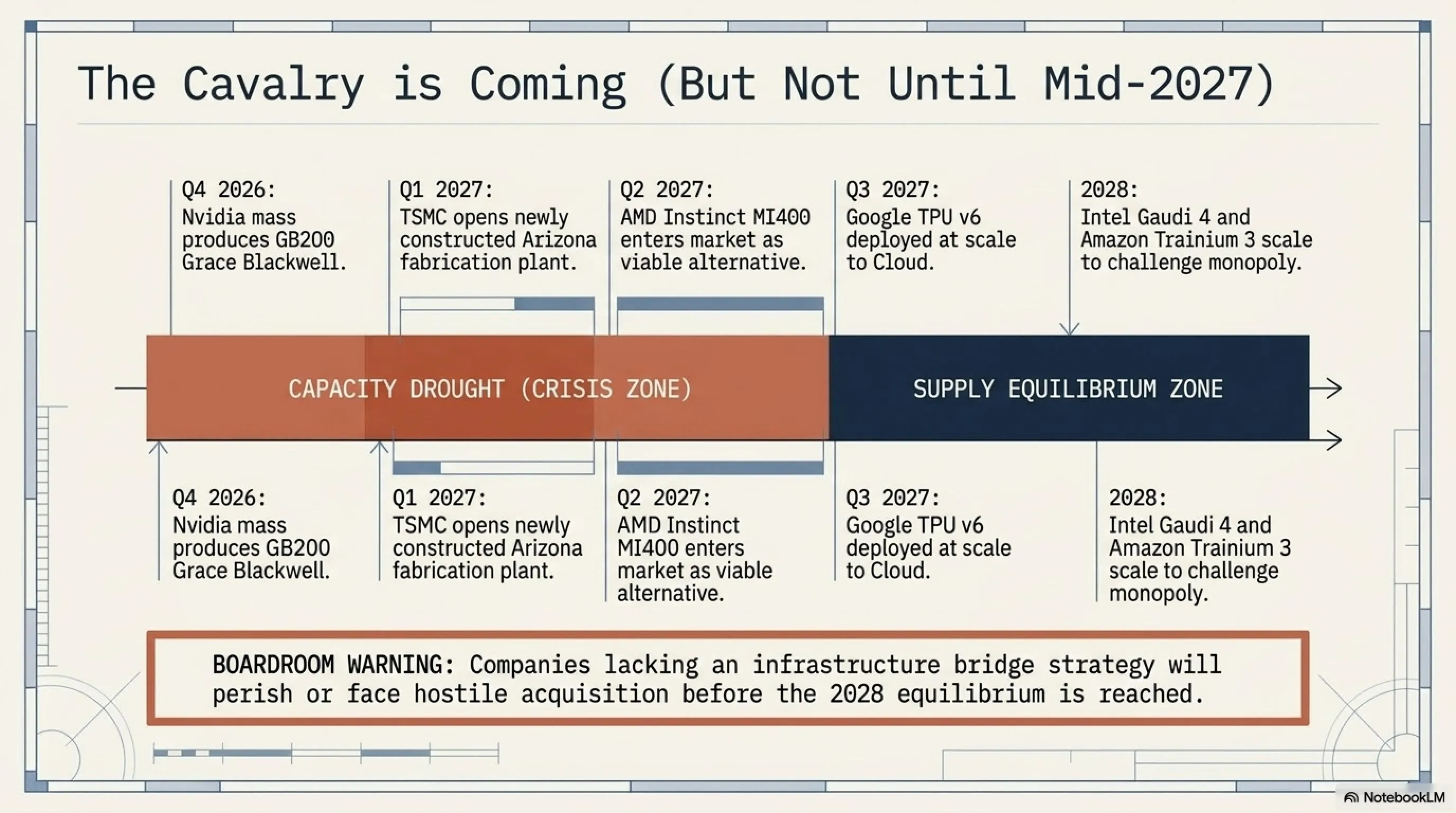
چشمانداز ۲۰۲۷-۲۰۲۸: آیا بحران حل میشود؟
خبر خوب این است که صنعت در حال واکنش است. اما خبر بد این است که راهحلها زمانبر هستند. Q4 2026: NVIDIA شروع تولید انبوه GB200 Grace Blackwell. Q1 2027: TSMC افتتاح Fab جدید در آریزونا. Q2 2027: AMD Instinct MI400 با قابلیت رقابت با Blackwell وارد بازار میشود. Q3 2027: Google TPU v6 برای مشتریان Cloud در دسترس میشود. ۲۰۲۸: Intel Gaudi 4 و Amazon Trainium 3 میتوانند بهطور جدی با NVIDIA رقابت کنند.
پس تا اواسط ۲۰۲۷، بحران ادامه خواهد داشت. شرکتهایی که نتوانند استراتژی درستی داشته باشند، یا میمیرند یا فروخته میشوند.
درسهای کلیدی از ماجرای Google-Meta
این ماجرا درسهای مهمی برای کل صنعت تکنولوژی دارد - چه شرکتهای بزرگ، چه استارتاپها. وابستگی خطرناک است: حتی با قرارداد میلیاردی، اگر زیرساخت خودت را نداشته باشی، آسیبپذیری. ظرفیت مهمتر از الگوریتم شده: دیگر فقط مدل خوب کافی نیست، باید بتوانی آن را اجرا کنی. استراتژی Plan B ضروری است: هر شرکت AI باید سناریوی قطع دسترسی را داشته باشد. بهینهسازی یک مزیت رقابتی است: کسانی که با کمتر بیشتر میکنند، زنده میمانند. بازار به سمت عمودیسازی میرود: شرکتهای بزرگ همه چیز را خودشان میسازند.
سوالات متداول
چرا گوگل دسترسی متا را محدود کرد؟
گوگل خودش با کمبود ظرفیت محاسباتی روبهرو بود. تقاضا برای Gemini آنقدر زیاد شده بود که گوگل نمیتوانست همه مشتریان را پوشش دهد. متا یکی از بزرگترین مصرفکنندگان بود، بنابراین محدودیت به آن اعمال شد. علاوه بر این، گوگل احتمالاً ترجیح داد سرویسهای داخلی و محصولات خودش را اولویت دهد.
Muse Spark چگونه ۱۰ برابر کارآمدتر از Llama است؟
متا از تکنیک Thought Compression استفاده کرده که در مرحله یادگیری تقویتی، مدل را مجبور میکند با توکن کمتری به پاسخ درست برسد. علاوه بر این، Muse Spark از معماری Mixture of Experts استفاده میکند که در هر استنتاج فقط بخش کوچکی از مدل فعال میشود. این یعنی سرعت بالاتر و هزینه کمتر.
آیا بحران ظرفیت محاسباتی حل خواهد شد؟
بله، اما نه زود. تا اواسط ۲۰۲۷، بحران ادامه خواهد داشت. پس از آن با ورود رقبای جدید و افتتاح Fabهای جدید، ظرفیت افزایش مییابد. اما تا آن زمان، شرکتها باید با محدودیت کنار بیایند.
قرارداد ۱۰ میلیارد دلاری متا با گوگل چه شد؟
قرارداد هنوز معتبر است، اما متا احتمالاً شرایط را مجدداً مذاکره میکند. قرارداد اصلی برای سرورها و ذخیرهسازی Google Cloud بود، نه لزوماً برای Gemini AI. حالا متا دارد وابستگی خود به خدمات گوگل را کاهش میدهد و به زیرساخت اختصاصی و Muse Spark متکی میشود.
چرا Llama اوپنسورس است اما Muse Spark نه؟
Llama برای ایجاد اکوسیستم و جلب توجه محققان اوپنسورس شد. این یک استراتژی بازاریابی و تحقیقاتی بود. اما Muse Spark یک دارایی استراتژیک است که مزیت رقابتی متا را تشکیل میدهد. متا نمیخواهد رقبا از این مدل بهرهمند شوند.
آیا این ماجرا روی کاربران فیسبوک و اینستاگرام تأثیر گذاشت؟
بله، اما بهطور غیرمستقیم. سیستمهای ایمنسازی محتوا و شناسایی کلاهبرداری برای چند هفته کندتر کار میکردند. برخی محتواهای مضر دیرتر حذف میشدند. اما متا سریع Muse Spark را جایگزین کرد، بنابراین تأثیر طولانیمدت نداشت.
آیا سایر شرکتها هم با این مشکل روبهرو هستند؟
بله، تقریباً همه شرکتهایی که به AI وابستهاند با این چالش دست و پنجه نرم میکنند. Anthropic تاخیر در لانچ داشت، Midjourney کیفیت را کاهش داد، Stability AI فروخته شد. فقط شرکتهایی مثل OpenAI یا شرکتهایی که زیرساخت خود را دارند وضعیت بهتری دارند.
آیا باید نگران آینده AI باشیم؟
نه. این یک بحران رشد است، نه بحران وجودی. صنعت نیمههادی در حال واکنش است و ظرفیت در حال افزایش است. فقط کندتر از آنچه همه میخواستند. درست مثل بحران کمبود چیپ در ۲۰۲۱-۲۰۲۲ که حل شد. این بار هم حل خواهد شد، اما شرکتهای ضعیف در این مسیر حذف میشوند.

واژهنامه تخصصی
GPU (Graphics Processing Unit): پردازندههای گرافیکی که در ابتدا برای بازیها طراحی شدند، اما حالا برای محاسبات AI استفاده میشوند. مثلاً NVIDIA H100 یک GPU قدرتمند برای تریین مدلهای AI است.
TPU (Tensor Processing Unit): چیپهای اختصاصی که گوگل برای محاسبات AI طراحی کرده. سریعتر و کارآمدتر از GPU برای کارهای خاص هستند، اما فقط در Google Cloud موجودند.
LLM (Large Language Model): مدلهای زبانی بزرگ مثل GPT، Gemini، Claude که روی میلیاردها کلمه تریین شدهاند و میتوانند متن تولید کنند، سوال جواب دهند، کد بنویسند.
Inference (استنتاج): زمانی که یک مدل آموزشدیده جواب شما را میدهد. مثلاً وقتی از ChatGPT سوال میپرسید، هر بار یک inference انجام میشود.
Training (تریین): فرآیند آموزش یک مدل AI روی مجموعه داده عظیم. تریین GPT-4 ماهها طول کشید و میلیونها دلار هزینه داشت.
Token: واحد پردازش متن در مدلهای زبانی. تقریباً هر ۴ حرف یک توکن است. مثلاً «هوش مصنوعی» حدود ۳ توکن است.
MoE (Mixture of Experts): معماری هوشمندی که در آن مدل چندین متخصص کوچک دارد و برای هر سوال فقط چند متخصص مرتبط فعال میشوند. این باعث سرعت و کارایی بالاتر میشود.
Fine-tuning: بعد از تریین اولیه، یک مدل را روی دادههای خاص بیشتر آموزش دادن. مثلاً یک مدل عمومی را fine-tune کردن برای پزشکی یا حقوق.
Quantization: تکنیکی برای کوچک کردن مدل با کاهش دقت اعداد. مثلاً از ۳۲-bit به ۸-bit رفتن. مدل کمی کیفیت از دست میدهد اما ۴ برابر کوچکتر و سریعتر میشود.
CoWoS (Chip-on-Wafer-on-Substrate): فناوری پیشرفته بستهبندی چیپ که TSMC استفاده میکند. این فناوری اجازه میدهد چندین چیپ کوچک را در یک بسته بزرگ قرار دهیم - ضروری برای GPUهای مدرن.
EUV Lithography: فناوری لیتوگرافی با نور فرابنفش شدید که برای ساخت چیپهای پیشرفته لازم است. فقط ASML این ماشینها را میسازد و هر کدام $۳۰۰ میلیون قیمت دارد.
Context Window: مقدار متنی که یک مدل یکجا میتواند پردازش کند. مثلاً context window ۱۲۸K توکن یعنی تقریباً ۱۰۰ صفحه متن را یکجا میتواند بخواند.
جمعبندی نهایی
ماجرای محدودیت دسترسی متا به Gemini توسط گوگل نقطه عطفی در صنعت هوش مصنوعی است. این رویداد به وضوح نشان داد که دوران AI رایگان و بیحد و حصر تمام شده است. ما وارد دورانی میشویم که ظرفیت محاسباتی به اندازه الگوریتمهای هوشمند اهمیت دارد.
برندههای این بازی شرکتهایی خواهند بود که: زیرساخت اختصاصی دارند، بهینهسازی را جدی میگیرند، استراتژی چندمنبعی دارند، و سرمایه کافی برای سرمایهگذاری بلندمدت دارند.
متا با ساخت Muse Spark نشان داد که حتی وقتی در تنگنا قرار بگیری، میتوانی راه خروج پیدا کنی. اما نه هر شرکتی این توانایی و منابع را دارد. در ماههای آینده، شاهد تلفیق و فروش بسیاری از شرکتهای AI خواهیم بود که نتوانستند با بحران ظرفیت کنار بیایند.
پیام نهایی: اگر کسبوکار شما به AI وابسته است، همین امروز شروع کنید به فکر کردن درباره Plan B. چون فردا ممکن است دیر باشد.

منابع و مراجع
این مقاله بر اساس تحقیقات گسترده و منابع معتبر زیر نوشته شده است:
- Financial Times - Google caps Meta's Gemini AI access (29 June 2026)
- Engadget - Google reportedly had to cap Meta's Gemini AI access (28 June 2026)
- The Verge - Meta announces Muse Spark (April 2026)
- The Next Web - Meta employees face AI tool usage limits (March 2026)
- Artificial Analysis - Intelligence Index Rankings (June 2026)
- SemiAnalysis - The GPU Shortage of 2026: Deep Dive
- Stratechery - Meta, Google, and the AI Capacity Crisis
- TechCrunch - Anthropic delays Claude Opus 5 launch (February 2026)
- Reuters - TSMC Arizona Fab to open Q1 2027
- NVIDIA Official - GB200 Grace Blackwell Specifications
- Google Cloud Blog - Google Cloud and Meta partnership (August 2025)
- Meta Newsroom - Introducing Muse Spark (April 2026)
- Tom's Hardware - NVIDIA H100 prices surge to $55K (May 2026)
- TSMC Press Release - CoWoS capacity expansion plans
- Bloomberg - AI infrastructure investment hits $150B in 2026
- ASML Official - EUV Lithography Systems
- CNBC - Stability AI acquired by Cohere (May 2026)
- OpenAI Blog - Expanded partnership with Microsoft
تمامی منابع در تاریخ ۲۹ ژوئن ۲۰۲۶ بررسی و تأیید شدهاند.
گالری تصاویر تکمیلی: 🚨 وقتی گوگل به متا گفت «نه»: بحران ظرفیت Gemini در صنعت AI