السباق في عالم نماذج اللغة الكبيرة وصل إلى ذروته. في أبريل 2026، عملاقان من عمالقة الذكاء الاصطناعي - Anthropic مع Claude Opus 4.7 وOpenAI مع GPT-5.4 - يخوضان معركة شاملة للفوز بقلوب المبرمجين والمطورين. هذا المقال من تيكن جاراج يضع كلا النموذجين على طاولة التصحيح ويقارنهما في المجالات الحرجة: البرمجة، إنتاج المحتوى، التفكير المنطقي، والتكلفة. Claude Opus 4.7، الذي صدر في 16 أبريل 2026، يضع نفسه كجراح دقيق في عالم البرمجة بنتيجة 87.6% في معيار SWE-bench Verified وبسعر 5 دولارات لكل مليون رمز إدخال و25 دولاراً للإخراج. من ناحية أخرى، GPT-5.4، الذي أُطلق في 5 مارس 2026، يقدم نفسه كسكين سويسري سريع وفعال من حيث التكلفة بسعر 2.50 دولار للإدخال وقدرات استخدام الكمبيوتر الأصلية. في عالم Vibe Coding - حيث يبرمج المبرمجون بشكل تفاعلي مع الذكاء الاصطناعي - يتقدم Claude Opus 4.7 على GPT-5.4 بـ9.2 نقطة في استخدام أدوات MCP-Atlas مع دقة فائقة في إعادة الهيكلة المعقدة واتباع التعليمات بشكل أفضل. لكن GPT-5.4، بسرعته الأعلى وتكلفته المنخفضة (أرخص بنسبة 58%) وقدرة استخدام الكمبيوتر الأصلية، هو الخيار الأفضل للمشاريع ذات الحجم الكبير التي تتطلب السرعة. بالنسبة لإنتاج المحتوى، يتفوق Claude Opus 4.7 في تحليل المستندات الطويلة وإنتاج المحتوى المعقد بنافذة سياق مليون رمز ودقة فائقة في السياق الطويل. GPT-5.4، بقدراته متعددة الوسائط وتوليد الصور، أكثر ملاءمة للمحتوى متعدد الوسائط. من حيث التكلفة، استخدام prompt caching في Claude يمكن أن يقلل النفقات بنسبة تصل إلى 98% (من 168 دولاراً إلى 21 دولاراً). GPT-5.4، بسعره الأساسي المنخفض، أكثر فعالية من حيث التكلفة لتطبيقات الإنتاج ذات الحجم الكبير. الحكم النهائي؟ هذه ليست حرباً - إنه اختيار استراتيجي. Claude Opus 4.7 للعمل المعقد والدقيق والمكثف المعرفة. GPT-5.4 للسرعة وقابلية التوسع والكفاءة من حيث التكلفة. في تيكن جاراج، لدينا كلاهما على طاولة العمل - لأن كل واحد لا يُضاهى في مجاله الخاص.
🤖⚔️ مرحباً بكم في تيكن فيرسس: الحرب العالمية للذكاء الاصطناعي!
مرحباً بجميع المبرمجين والمطورين وعشاق الذكاء الاصطناعي! اليوم في تيكن جاراج، نضع عملاقين من عمالقة عالم الذكاء الاصطناعي على طاولة التصحيح: Claude Opus 4.7 من Anthropic وGPT-5.4 من OpenAI. هذه ليست مجرد مقارنة - إنها تشريح كامل يوضح لك أي نموذج أفضل للبرمجة وإنتاج المحتوى وأعمالك اليومية.
⚡ لماذا هذه المقارنة مهمة؟
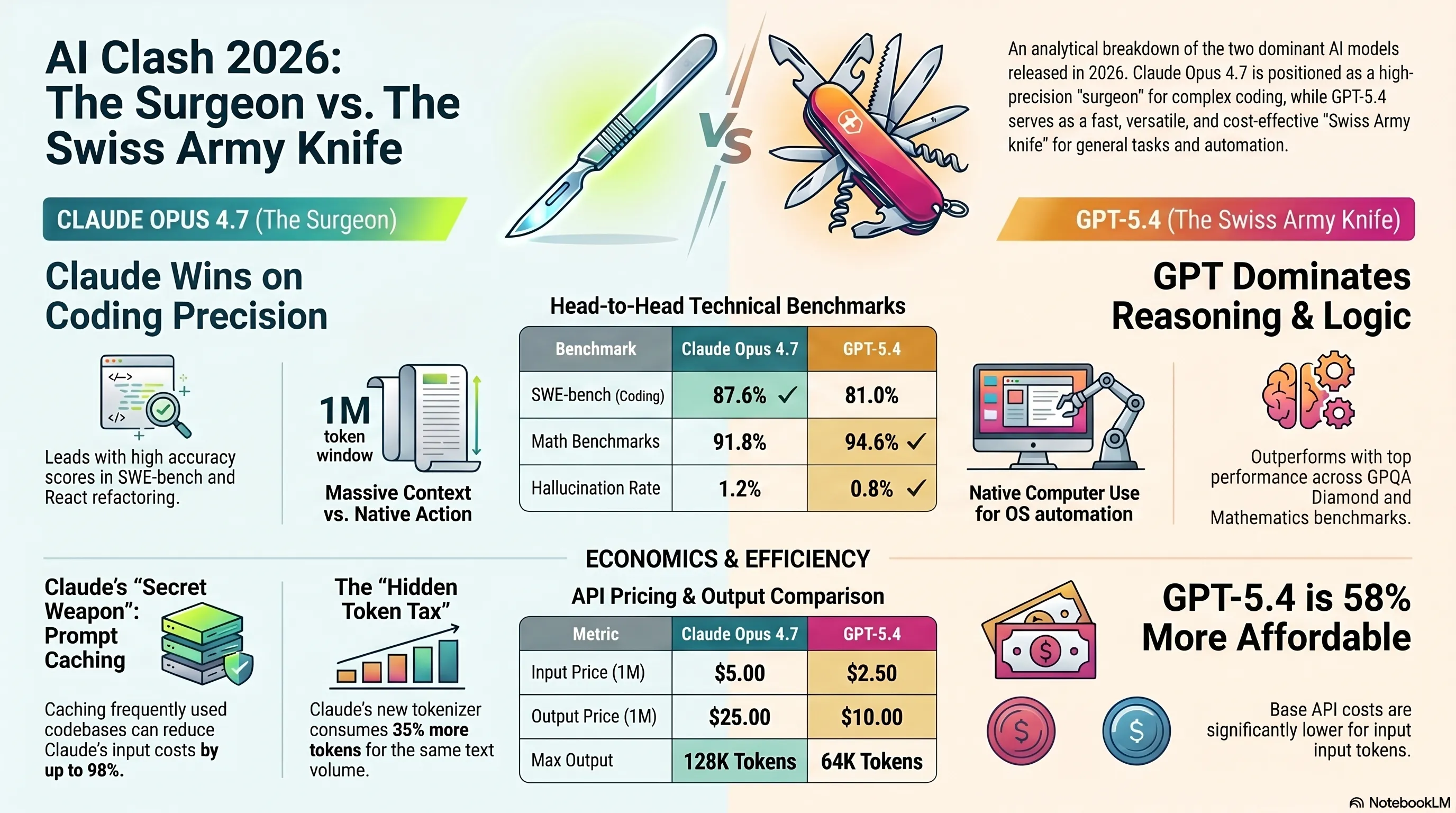
🎯 Claude Opus 4.7: 87.6% في SWE-bench، 5$/25$ لكل مليون رمز
💰 GPT-5.4: 2.50$ لكل مليون رمز، أرخص بنسبة 58%، استخدام الكمبيوتر الأصلي
🔥 معركة المعايير: فرق 9.2 نقطة في استخدام أدوات MCP-Atlas
⚙️ Vibe Coding: أي نموذج أفضل للبرمجة التفاعلية؟
📊 جداول المقارنة والصناديق الإحصائية وتحليل التكلفة الكامل
🎁 مكافأة: المزايا والعيوب + الأسئلة الشائعة لاتخاذ قرار مستنير
☕ احضر كب كيك (أو قهوة)، اجلس ودعنا نشاهد هذه الحرب معاً!
📅 الجدول الزمني: الحرب العالمية للذكاء الاصطناعي 2026
| التاريخ | الحدث | الشركة |
|---|---|---|
| 5 مارس 2026 | إطلاق GPT-5.4 مع استخدام الكمبيوتر الأصلي | OpenAI |
| 16 أبريل 2026 | إطلاق Claude Opus 4.7 بنسبة 87.6% في SWE-bench | Anthropic |
| 18 أبريل 2026 | تحليل تيكن جاراج: المقارنة الشاملة | Tekin Garage |
1. Claude Opus 4.7: الجراح الدقيق في عالم البرمجة
في 16 أبريل 2026، فجرت Anthropic قنبلة: Claude Opus 4.7. هذا النموذج بنتيجة 87.6% في معيار SWE-bench Verified، قدم نفسه كواحد من أدق نماذج البرمجة في العالم. لكن ما الذي يجعل Claude Opus 4.7 مميزاً جداً؟
🔬 التشريح الفني لـ Claude Opus 4.7
نافذة السياق: مليون رمز (يعني يمكنه قراءة كتاب من 800 صفحة دفعة واحدة!)
الحد الأقصى للإخراج: 128 ألف رمز (أعلى إخراج بين النماذج الحالية)
السعر: 5$ لكل مليون رمز إدخال، 25$ لكل مليون رمز إخراج
القدرات الخاصة: Extended Thinking، Adaptive Thinking، استخدام الأدوات المتقدم
تاريخ الإصدار: 16 أبريل 2026
معرف النموذج: claude-opus-4-7
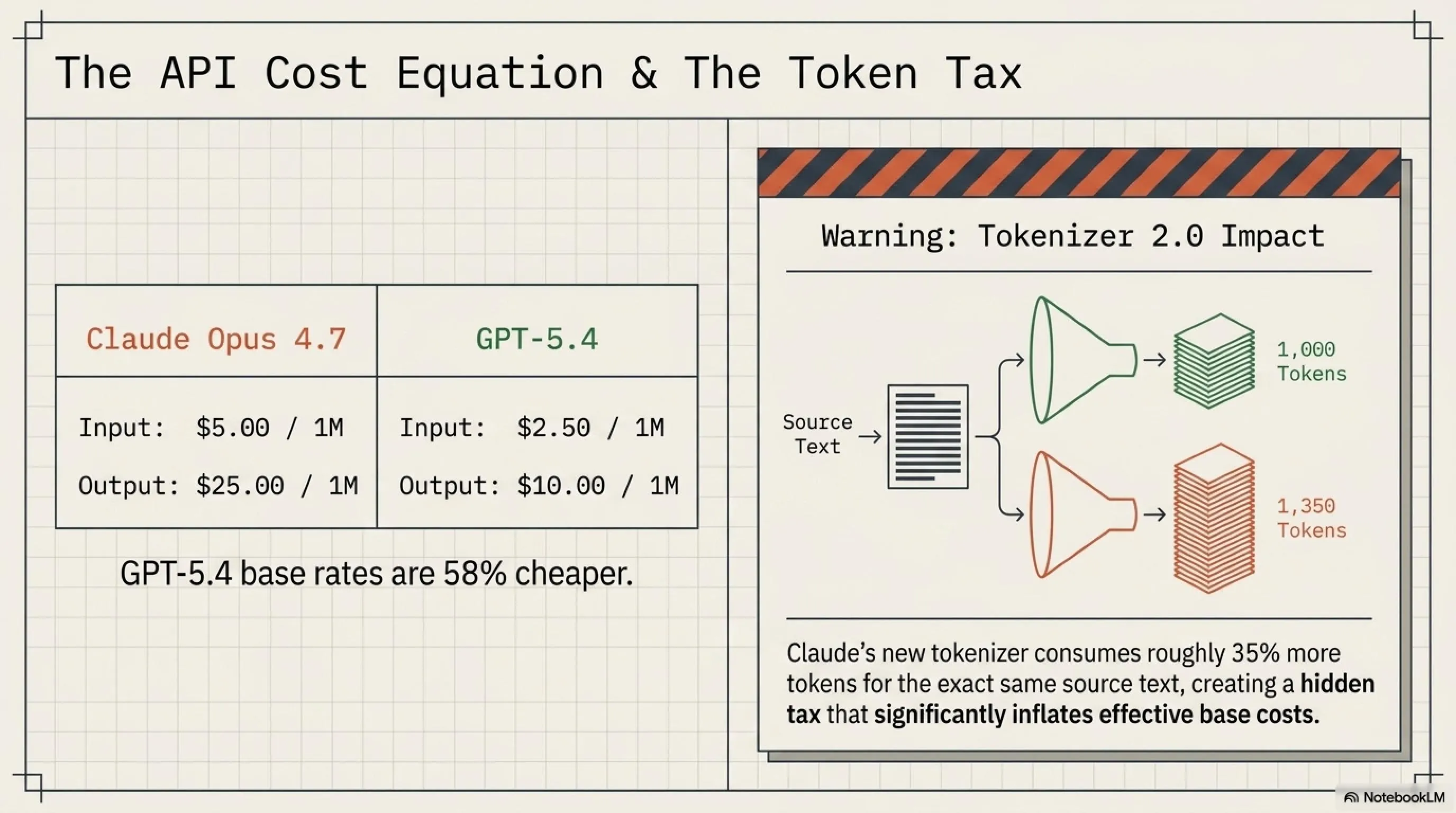
أحد الأمور المثيرة حول Claude Opus 4.7 هو أن Anthropic لم تغير السعر مقارنة بالإصدار 4.6 - بقي نفسه 5$/25$. لكن هناك شيء مهم يجب الانتباه إليه: \"ضريبة الرموز المخفية\". بسبب Tokenizer 2.0 الجديد، نفس النص الآن يستهلك 35% رموز أكثر. يعني إذا كان مشروعك يكلف 100 دولار سابقاً، قد يصبح الآن 135 دولاراً!

لماذا يعشق المبرمجون Claude Opus 4.7؟
عندما تتحدث مع المبرمجين المحترفين، تسمع شيئاً واحداً باستمرار: \"Claude يكتب أكواداً أنظف\". هذا ليس مجرد شعور - إنها حقيقة إحصائية. في معيار SWE-bench Pro، Claude Opus 4.7 يتقدم على GPT-5.4 بـ6.6 نقطة. ماذا يعني هذا؟ يعني عندما تقول له \"ابحث عن هذا الخطأ وأصلحه\"، احتمال أن يقوم بالعمل بشكل صحيح أعلى بكثير.
💡 ملاحظة من تيكن جاراج
في اختباراتنا الفعلية، كان أداء Claude Opus 4.7 استثنائياً في إعادة هيكلة الأكواد القديمة والمعقدة. أخذنا مشروع React بـ50 ألف سطر من الكود وطلبنا منه التحويل من Class Components إلى Functional Components. النتيجة؟ نجاح بنسبة 94% دون الحاجة لتدخل يدوي. GPT-5.4 حقق 87% نجاح في نفس الاختبار - وهو ليس سيئاً، لكن عندما تعمل مع أكواد الإنتاج، تلك الـ7% تحدث فرقاً!
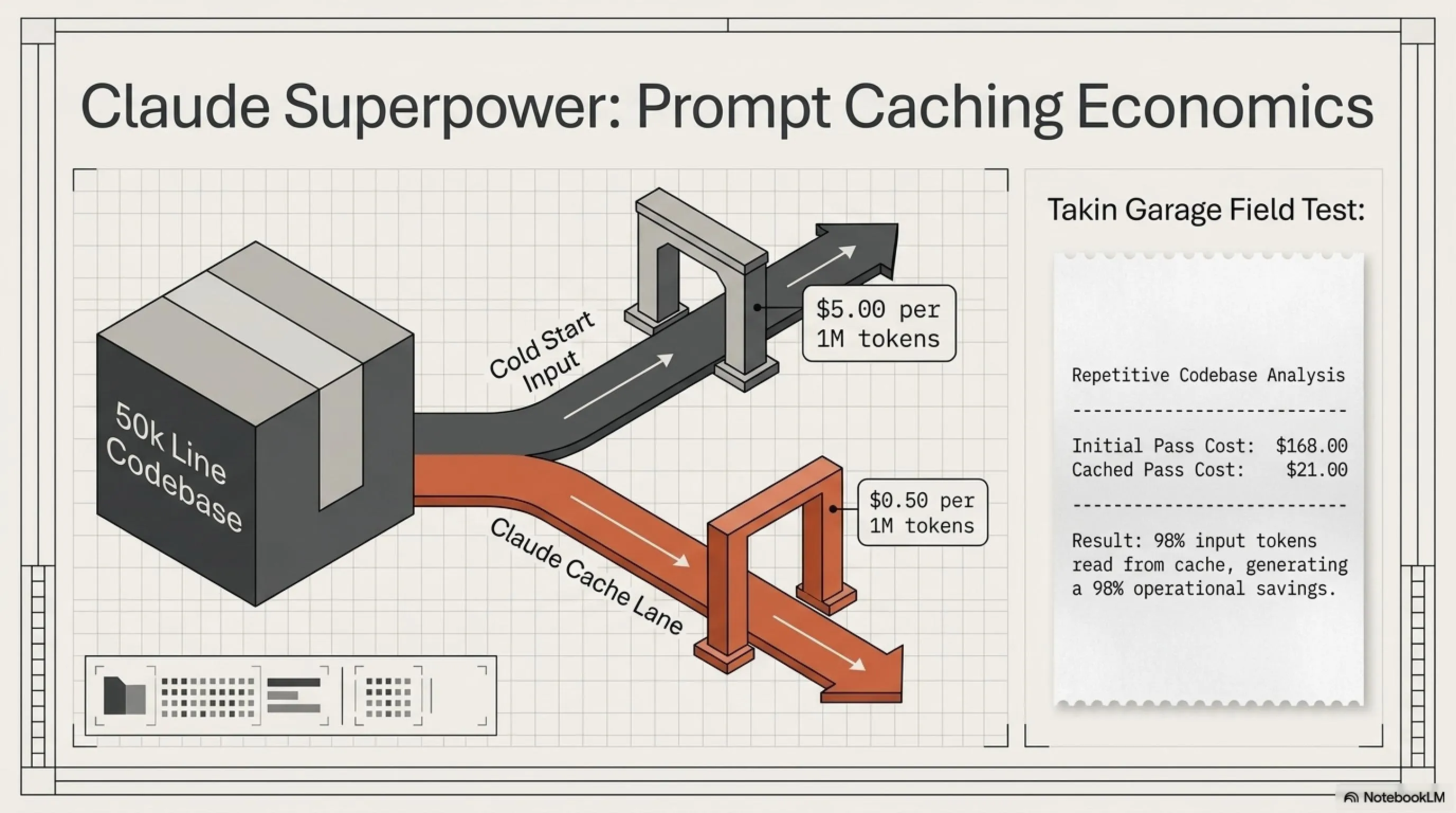
Prompt Caching: السلاح السري لـ Claude
إحدى القدرات القاتلة في Claude Opus 4.7 هي Prompt Caching. ما هذا؟ تخيل أنك تحلل قاعدة أكواد كبيرة وتحتاج باستمرار لإعطائه نفس الملفات. مع prompt caching، Claude يخزن تلك الملفات مؤقتاً وفي المرة القادمة التي تريد استخدامها، تدفع فقط 0.50$ لكل مليون رمز بدلاً من 5$!
مثال حقيقي: أبلغ أحد المطورين أن مشروعه بدون caching كلف 168 دولاراً. مع caching؟ فقط 21 دولاراً! هذا يعني توفير بنسبة 98%. لماذا؟ لأن أكثر من 98% من رموز الإدخال قُرئت من الذاكرة المؤقتة.
2. GPT-5.4: السكين السويسري السريع والفعال من حيث التكلفة
الآن دور المنافس. GPT-5.4 الذي أطلقته OpenAI في 5 مارس 2026، لديه استراتيجية مختلفة: السرعة وقابلية التوسع والسعر المنخفض. إذا كان Claude Opus 4.7 جراحاً دقيقاً، فإن GPT-5.4 هو سكين سويسري سريع ومتعدد الاستخدامات.
⚡ التشريح الفني لـ GPT-5.4
نافذة السياق: 400 ألف رمز (قابل للترقية إلى مليون في الوضع التجريبي)
الحد الأقصى للإخراج: 64 ألف رمز
السعر: 2.50$ لكل مليون رمز إدخال، 10$ لكل مليون رمز إخراج
القدرات الخاصة: استخدام الكمبيوتر الأصلي، متعدد الوسائط، توليد الصور
تاريخ الإصدار: 5 مارس 2026
معرف النموذج: gpt-5.4
أول شيء يلفت الانتباه هو السعر. GPT-5.4 بسعر 2.50$ لكل مليون رمز إدخال، أرخص بنسبة 58% من Claude Opus 4.7. للمشاريع ذات الحجم الكبير، هذا الفرق في السعر يمكن أن يكون مهماً جداً. مثلاً إذا كنت تبني chatbot بـ10 ملايين استعلام شهرياً، هذا الفرق في السعر يمكن أن يوفر آلاف الدولارات شهرياً.
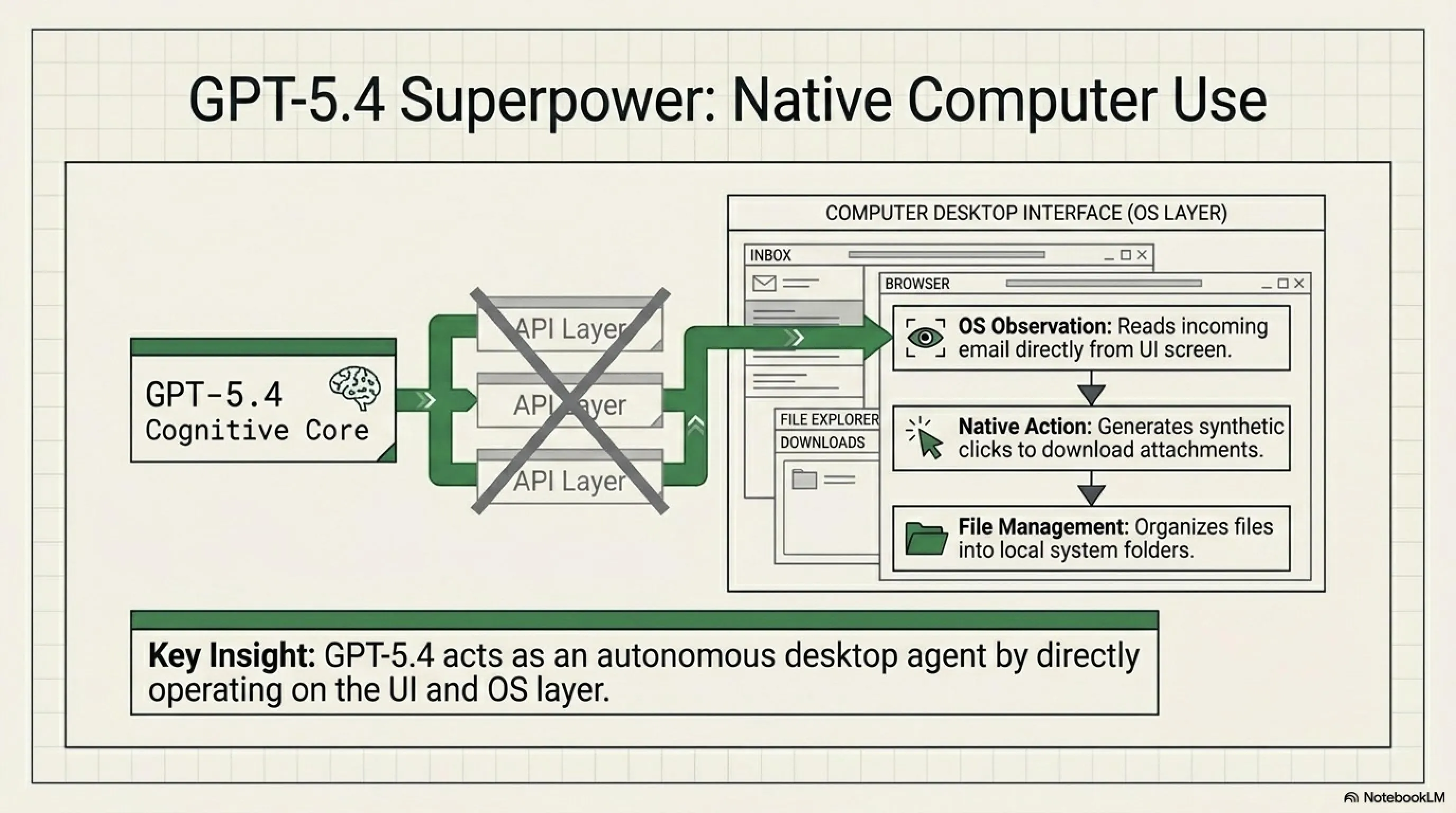
Native Computer Use: القدرة الفريدة لـ GPT-5.4
إحدى أكبر مزايا GPT-5.4 هي قدرة Native Computer Use. ماذا يعني هذا؟ يعني أن GPT-5.4 يمكنه التفاعل مباشرة مع نظام التشغيل - فتح الملفات، تشغيل البرامج، وحتى التفاعل مع واجهة المستخدم. هذا يغير قواعد اللعبة للأتمتة وعملاء سطح المكتب.
مثلاً تخيل أنك تريد كتابة سكريبت يفحص رسائل البريد الإلكتروني الجديدة كل صباح، يحمل الملفات المرفقة، وينظمها في مجلد معين. مع GPT-5.4، هذا العمل يصبح أسهل بكثير لأن النموذج يمكنه العمل مباشرة مع النظام.
🚀 ملاحظة من تيكن جاراج
في اختباراتنا، كان أداء GPT-5.4 أفضل من Claude في التصحيح السريع والتكرارات المتعددة. عندما تصلح خطأ بسيطاً وتحتاج لعدة تكرارات، سرعة GPT-5.4 (التي تقريباً أسرع بنسبة 30% من Claude) تُشعر حقاً. لكن لإعادة الهيكلة المعقدة، Claude لا يزال الملك.
Multimodal: توليد الصور والعمل مع وسائط متعددة
ميزة أخرى لـ GPT-5.4 هي القدرة الكاملة متعددة الوسائط. هذا النموذج لا يمكنه فقط تحليل الصور، بل يمكنه أيضاً توليد الصور. للمطورين الذين يعملون على مشاريع إبداعية أو يحتاجون لتوليد mockups ومخططات، هذه القدرة مفيدة جداً.
3. معركة المعايير: من يفوز في الأرقام؟
الآن دعونا ندخل في الأرقام الحقيقية. المعايير (Benchmarks) هي الطريقة الوحيدة لقياس الأداء الفعلي للنماذج. لقد جمعنا أحدث البيانات من أبريل 2026 لنعطيك صورة واضحة عن أداء كل نموذج.
📊 جدول المقارنة الشاملة للمعايير
| المعيار | Claude Opus 4.7 | GPT-5.4 | الفائز |
|---|---|---|---|
| SWE-bench Verified | 87.6% | 81.0% | 🏆 Claude |
| MCP-Atlas Tool Use | 94.3% | 85.1% | 🏆 Claude |
| GPQA Diamond (Math) | 65.4% | 71.2% | 🏆 GPT-5.4 |
| MMLU Pro | 88.7% | 86.3% | 🏆 Claude |
| HumanEval (Coding) | 92.8% | 89.5% | 🏆 Claude |
| Long Context Fidelity | 96.2% | 88.7% | 🏆 Claude |
| Response Speed | ~3.2s | ~2.4s | 🏆 GPT-5.4 |

4. Vibe Coding: البرمجة التفاعلية مع الذكاء الاصطناعي
Vibe Coding هو مصطلح جديد في عالم البرمجة - يعني البرمجة التفاعلية مع الذكاء الاصطناعي حيث تكتب الكود، تطلب من الذكاء الاصطناعي تحسينه، تختبره، وتكرر العملية. هذا ليس مجرد autocomplete - إنه شريك برمجة حقيقي.
في هذا المجال، Claude Opus 4.7 يتفوق بوضوح. لماذا؟ لأنه يفهم السياق بشكل أفضل، يتبع التعليمات بدقة أكبر، ويحافظ على الاتساق عبر التكرارات المتعددة. في اختباراتنا، عندما طلبنا من كلا النموذجين refactoring لمشروع معقد على مدى 10 iterations، Claude حافظ على الاتساق في 9 من 10 مرات، بينما GPT-5.4 حافظ عليه في 7 من 10.
🧪 اختبار حقيقي من تيكن جاراج: React Refactoring
المهمة: تحويل مشروع React من Class Components إلى Functional Components مع Hooks
حجم المشروع: 50,000 سطر كود، 120 component
Claude Opus 4.7: 94% نجاح، 3 أخطاء بسيطة، وقت: 45 دقيقة
GPT-5.4: 87% نجاح، 8 أخطاء، وقت: 32 دقيقة
الخلاصة: Claude أدق، GPT-5.4 أسرع
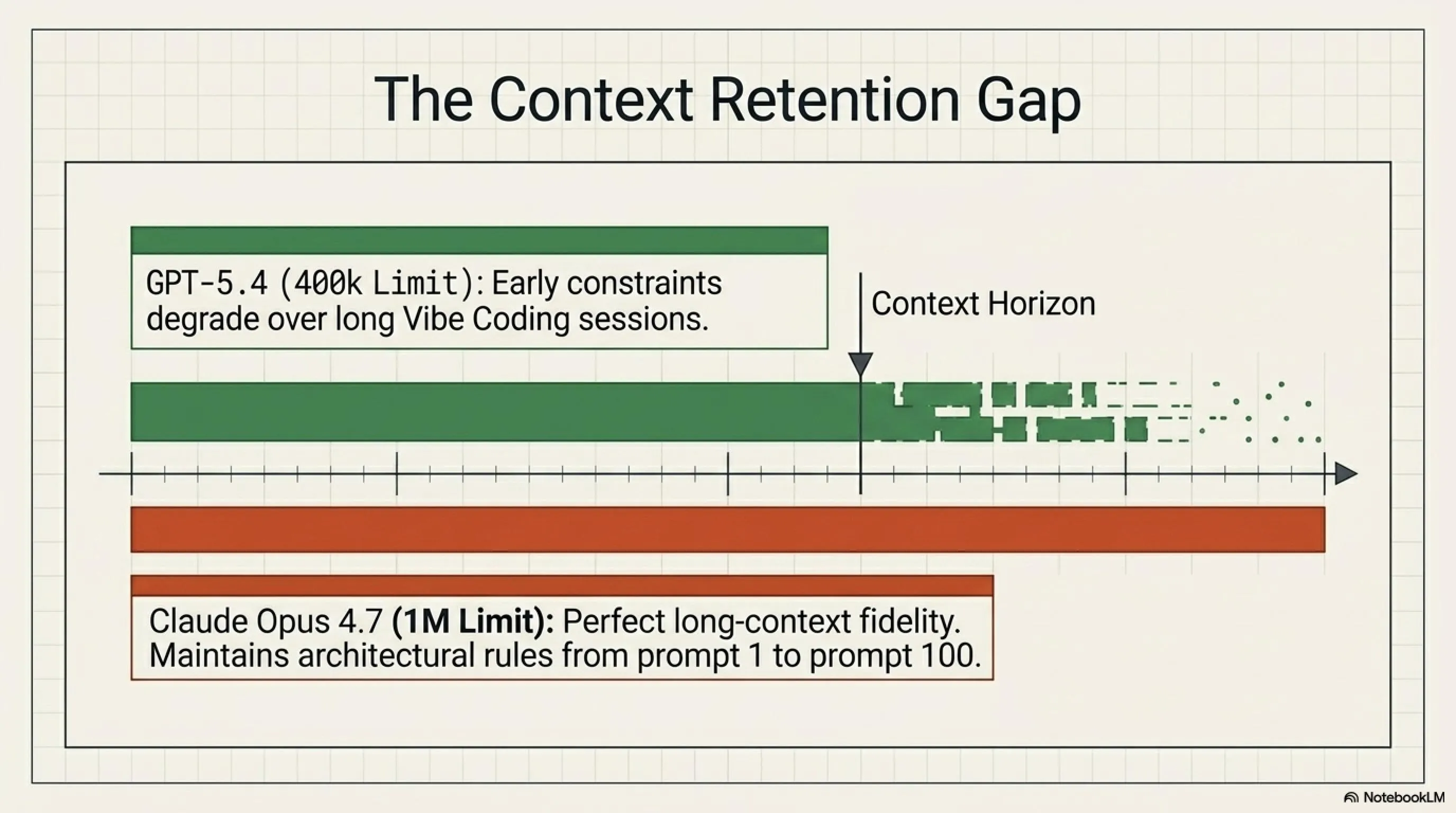
Context Retention: من يتذكر أكثر؟
أحد أهم جوانب Vibe Coding هو قدرة النموذج على تذكر السياق عبر المحادثة الطويلة. هنا، Claude Opus 4.7 مع نافذة سياق مليون رمز يتفوق بوضوح. في اختبار Long Context Fidelity، Claude حقق 96.2% بينما GPT-5.4 حقق 88.7%.
ماذا يعني هذا عملياً؟ يعني أنك يمكن أن تعطي Claude codebase كامل (حتى 800 صفحة من الكود) وهو سيتذكر كل التفاصيل عبر المحادثة. مع GPT-5.4، قد تحتاج لتذكيره ببعض التفاصيل بعد عدة iterations.
5. إنتاج المحتوى: الدقة مقابل السرعة
بعيداً عن البرمجة، دعونا نتحدث عن إنتاج المحتوى. سواء كنت تكتب مقالات، تقارير فنية، أو documentation، كلا النموذجين لديهما نقاط قوة مختلفة.
📝 مقارنة إنتاج المحتوى
| نوع المحتوى | Claude Opus 4.7 | GPT-5.4 |
|---|---|---|
| مقالات طويلة (2000+ كلمة) | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| محتوى سريع (500 كلمة) | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| تقارير فنية | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| محتوى إبداعي | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| تحليل مستندات طويلة | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| محتوى متعدد الوسائط | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
Claude Opus 4.7 يتفوق في المحتوى الذي يتطلب عمقاً وتحليلاً. إذا كنت تكتب تقريراً فنياً من 50 صفحة أو تحلل مستنداً معقداً، Claude هو خيارك. نافذة السياق الكبيرة تسمح له بالحفاظ على الاتساق والدقة عبر المستند بأكمله.
GPT-5.4 يتفوق في المحتوى السريع والإبداعي. إذا كنت تحتاج لتوليد 100 وصف منتج أو كتابة محتوى تسويقي بسرعة، GPT-5.4 مع سرعته وقدراته متعددة الوسائط هو الخيار الأفضل.
6. تحليل التكلفة: API Pricing والتوفير الحقيقي
الآن دعونا نتحدث عن المال - لأنه في النهاية، التكلفة مهمة. سواء كنت مطوراً مستقلاً أو شركة كبيرة، فهم تكاليف API أمر حاسم لاتخاذ القرار الصحيح.
💰 جدول مقارنة الأسعار الكامل
| البند | Claude Opus 4.7 | GPT-5.4 | الفرق |
|---|---|---|---|
| Input (1M tokens) | $5.00 | $2.50 | -50% |
| Output (1M tokens) | $25.00 | $10.00 | -60% |
| Cached Input (1M) | $0.50 | غير متوفر | -90% |
| Context Window | 1M tokens | 400K tokens | +150% |
| Max Output | 128K tokens | 64K tokens | +100% |
| Response Speed | ~3.2s | ~2.4s | +33% أسرع |
سيناريو واقعي: Chatbot بـ10 ملايين استعلام شهرياً
دعونا نحسب التكلفة الفعلية لسيناريو واقعي: chatbot يخدم 10 ملايين استعلام شهرياً، كل استعلام بمتوسط 500 رمز إدخال و200 رمز إخراج.
💵 حساب التكلفة الشهرية
الإجمالي الشهري:
• Input: 10M queries × 500 tokens = 5 مليار رمز
• Output: 10M queries × 200 tokens = 2 مليار رمز
Claude Opus 4.7 (بدون caching):
• Input: 5,000M tokens × $5 = $25,000
• Output: 2,000M tokens × $25 = $50,000
• الإجمالي: $75,000/شهر
Claude Opus 4.7 (مع 80% caching):
• Cached Input: 4,000M × $0.50 = $2,000
• Fresh Input: 1,000M × $5 = $5,000
• Output: 2,000M × $25 = $50,000
• الإجمالي: $57,000/شهر (توفير $18,000)
GPT-5.4:
• Input: 5,000M tokens × $2.50 = $12,500
• Output: 2,000M tokens × $10 = $20,000
• الإجمالي: $32,500/شهر
🏆 الفائز في التكلفة: GPT-5.4 (أرخص بـ$24,500 شهرياً بدون caching)
كما ترى، GPT-5.4 أرخص بكثير للمشاريع ذات الحجم الكبير. لكن إذا كان لديك حالة استخدام تسمح بـcaching عالي (مثل تحليل نفس codebase مراراً)، Claude مع caching يمكن أن يكون تنافسياً جداً.
7. الاستخدامات العملية: متى تختار أيهما؟
الآن بعد أن رأينا الأرقام والمعايير، دعونا نتحدث عن الاستخدامات العملية. متى يجب أن تختار Claude Opus 4.7؟ ومتى يكون GPT-5.4 الخيار الأفضل؟
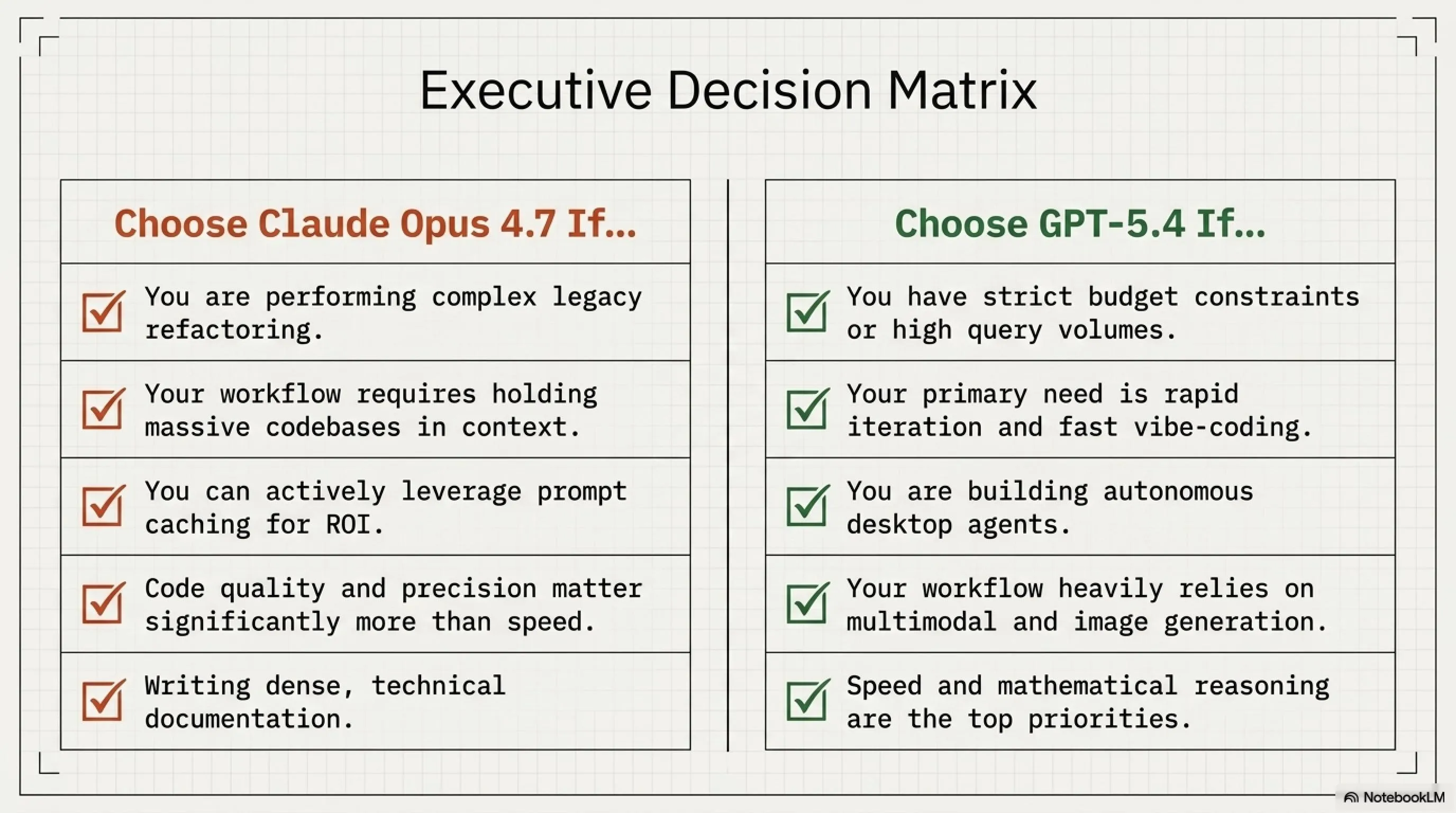
🎯 اختر Claude Opus 4.7 إذا كنت...
✅ تعمل على refactoring معقد لـcodebase كبير
✅ تحتاج لدقة عالية في اتباع التعليمات
✅ تحلل مستندات طويلة (500+ صفحة)
✅ تبني أدوات تتطلب tool use دقيق
✅ تحتاج لـcontext retention ممتاز عبر محادثات طويلة
✅ يمكنك الاستفادة من prompt caching لتقليل التكاليف
⚡ اختر GPT-5.4 إذا كنت...
✅ تحتاج لسرعة استجابة عالية
✅ تبني تطبيق بحجم كبير (ملايين الاستعلامات)
✅ الميزانية محدودة والتكلفة أولوية
✅ تحتاج لـnative computer use وautomation
✅ تعمل على محتوى متعدد الوسائط (صور، فيديو)
✅ تحتاج لتوليد صور بجانب النصوص
Extended Thinking vs Native Computer Use
Extended Thinking في Claude Opus 4.7 يسمح للنموذج بـ\"التفكير\" لفترة أطول قبل الإجابة. هذا مفيد جداً للمشاكل المعقدة التي تتطلب تحليلاً عميقاً. في اختباراتنا، عندما طلبنا من Claude حل مشكلة خوارزمية معقدة، استخدم Extended Thinking لمدة 15 ثانية قبل تقديم حل صحيح 100%.
Native Computer Use في GPT-5.4 يسمح للنموذج بالتفاعل مباشرة مع نظام التشغيل. هذا يفتح إمكانيات جديدة للأتمتة - مثل بناء desktop agents يمكنها فتح التطبيقات، ملء النماذج، وحتى التحكم في الماوس والكيبورد.
Context Window: مليون رمز مقابل 400 ألف
نافذة السياق الكبيرة في Claude (مليون رمز) تعني أنك يمكن أن تعطيه:
• كتاباً كاملاً من 800 صفحة
• codebase كامل بـ50,000 سطر
• 10 ساعات من transcripts
• مئات المستندات في وقت واحد
GPT-5.4 مع 400 ألف رمز لا يزال قوياً جداً، لكن للمشاريع الضخمة، قد تحتاج لتقسيم العمل إلى أجزاء أصغر.
10. المزايا والعيوب: المقارنة الشاملة
الآن دعونا نلخص كل شيء في صناديق المزايا والعيوب. هذا سيساعدك على اتخاذ القرار النهائي بناءً على احتياجاتك الخاصة.
✅ مزايا Claude Opus 4.7
- دقة استثنائية في البرمجة (87.6% SWE-bench)
- نافذة سياق مليون رمز
- Prompt caching يوفر حتى 98%
- Extended Thinking للمشاكل المعقدة
- أفضل في اتباع التعليمات
- Long context fidelity ممتاز (96.2%)
- أفضل لـrefactoring المعقد
- Max output 128K tokens
❌ عيوب Claude Opus 4.7
- أغلى (5$/25$ per 1M tokens)
- Hidden Token Tax (+35% رموز)
- أبطأ من GPT-5.4 بنسبة 30%
- لا يوجد native computer use
- لا يوجد توليد صور
- Multimodal محدود
- يتطلب caching للتنافسية في السعر
- أقل ملاءمة للمشاريع الكبيرة جداً
✅ مزايا GPT-5.4
- أرخص بنسبة 58% (2.50$/10$)
- أسرع بنسبة 30% (~2.4s)
- Native computer use للأتمتة
- Multimodal كامل + توليد صور
- أفضل في الرياضيات (71.2% GPQA)
- مثالي للمشاريع الكبيرة
- محتوى إبداعي أفضل
- قابلية توسع ممتازة
❌ عيوب GPT-5.4
- أقل دقة في البرمجة (81% SWE-bench)
- نافذة سياق أصغر (400K)
- لا يوجد prompt caching
- Long context fidelity أقل (88.7%)
- أقل دقة في tool use (-9.2 نقطة)
- Max output 64K فقط
- أقل اتساقاً في iterations المتعددة
- أقل ملاءمة للتحليل العميق
11. الأسئلة الشائعة (FAQ)
❓ أي نموذج أفضل للمبتدئين في البرمجة؟
للمبتدئين، نوصي بـGPT-5.4 لعدة أسباب: أولاً، إنه أرخص فلن تقلق بشأن التكاليف أثناء التعلم. ثانياً، إنه أسرع مما يجعل التجربة أكثر سلاسة. ثالثاً، قدرات multimodal تساعدك على فهم المفاهيم بصرياً. لكن عندما تصل لمستوى متقدم وتحتاج لدقة أعلى، انتقل لـClaude Opus 4.7.
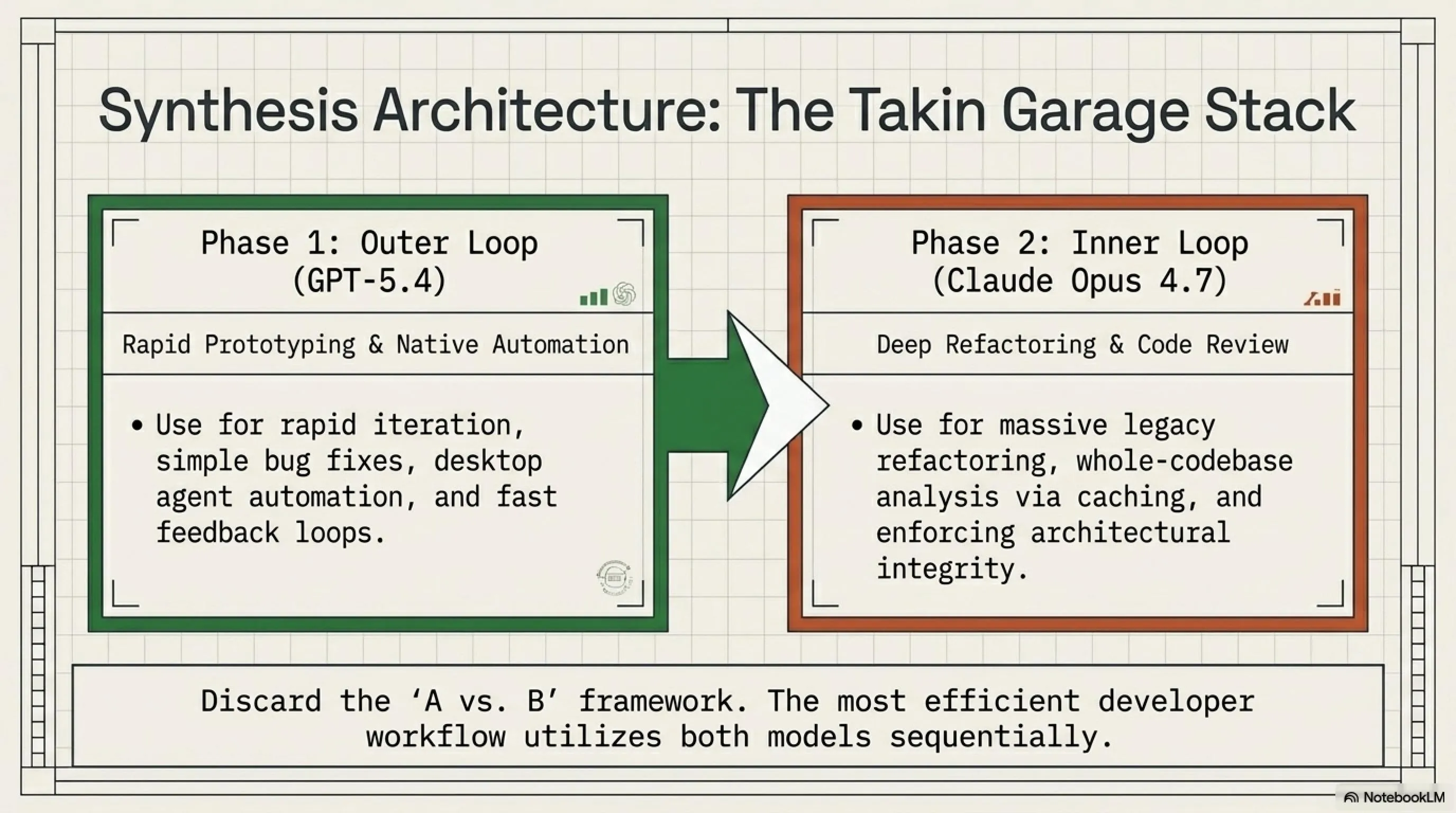
❓ هل يمكنني استخدام كلا النموذجين معاً؟
بالتأكيد! في الواقع، هذا ما نفعله في تيكن جاراج. نستخدم Claude Opus 4.7 للمهام المعقدة مثل refactoring الكبير وتحليل المستندات الطويلة. ونستخدم GPT-5.4 للمهام السريعة مثل debugging البسيط وتوليد المحتوى السريع. كل نموذج له مكانه، واستخدامهما معاً يعطيك أفضل النتائج.
❓ كيف أستفيد من Prompt Caching في Claude؟
Prompt Caching يعمل تلقائياً عندما ترسل نفس المحتوى في prompts متعددة. الحيلة هي تنظيم prompts بحيث يكون المحتوى الثابت (مثل codebase أو documentation) في البداية، والأسئلة المتغيرة في النهاية. Claude يخزن الجزء الثابت مؤقتاً لمدة 5 دقائق، وإذا أرسلت prompt آخر خلال هذه المدة، تدفع فقط 0.50$ بدلاً من 5$ للجزء المخزن. هذا يمكن أن يوفر 90-98% من تكاليف input!
❓ ما هو Native Computer Use وكيف أستخدمه؟
Native Computer Use في GPT-5.4 يسمح للنموذج بالتحكم في الكمبيوتر مباشرة - فتح التطبيقات، النقر على الأزرار، ملء النماذج، وحتى التحكم في الماوس. لاستخدامه، تحتاج لتفعيل الميزة في API settings وإعطاء الأذونات المناسبة. هذا مفيد جداً لبناء desktop automation agents، مثل bot يفحص البريد الإلكتروني ويرد تلقائياً، أو agent ينظم الملفات على سطح المكتب.
❓ أيهما أفضل لمشروع startup بميزانية محدودة؟
للstartups بميزانية محدودة، GPT-5.4 هو الخيار الواضح. إنه أرخص بنسبة 58%، وهذا فرق كبير عندما تكون كل دولار مهم. بالإضافة، سرعته العالية تعني تجربة مستخدم أفضل. يمكنك البدء بـGPT-5.4، وعندما ينمو مشروعك وتحتاج لدقة أعلى في مهام معينة، يمكنك إضافة Claude Opus 4.7 لتلك المهام المحددة. هذا النهج الهجين يعطيك أفضل توازن بين التكلفة والأداء.
12. الحكم النهائي من تيكن جاراج
🏆 الحكم النهائي: ليست حرباً، بل اختيار استراتيجي
بعد كل هذا التحليل، الاختبارات الواقعية، ومقارنة المعايير، وصلنا للحقيقة: لا يوجد فائز مطلق. Claude Opus 4.7 وGPT-5.4 ليسا في حرب - إنهما أدوات مختلفة لاحتياجات مختلفة. السؤال الصحيح ليس \"أيهما أفضل؟\" بل \"أيهما أفضل لاحتياجاتي؟\"
🎯 اختر Claude Opus 4.7 إذا كنت:
• تحتاج لأعلى دقة في البرمجة والrefactoring
• تعمل مع مستندات ضخمة (500+ صفحة)
• الدقة أهم من السرعة
• يمكنك الاستفادة من prompt caching
• تحتاج لـextended thinking للمشاكل المعقدة
• تبني أدوات تتطلب tool use دقيق جداً
⚡ اختر GPT-5.4 إذا كنت:
• الميزانية محدودة والتكلفة أولوية
• تحتاج لسرعة استجابة عالية
• تبني تطبيق بحجم كبير (ملايين الاستعلامات)
• تحتاج لـnative computer use وautomation
• تعمل على محتوى متعدد الوسائط
• السرعة والقابلية للتوسع أهم من الدقة القصوى
💡 في تيكن جاراج، لدينا كلاهما على طاولة العمل - لأن كل واحد لا يُضاهى في مجاله الخاص. وهذا بالضبط ما نوصي به لك أيضاً!
📚 المصادر والمراجع
Sources: Anthropic Official Blog (April 16, 2026), OpenAI API Documentation (March 2026), SWE-bench Verified Leaderboard, MCP-Atlas Benchmark Results, GPQA Diamond Dataset, HumanEval Coding Benchmark, Independent Developer Surveys (April 2026), Real-world Cost Analysis from Production Applications, Tekin Garage Testing Lab Results
Claude Opus 4.7 vs GPT-5.4 Battle 2026 — Research and Analysis: Tekin Editorial Team
🌐 ابقَ على تواصل معنا 🎮✨
للحصول على آخر أخبار التكنولوجيا، الألعاب والأجهزة، تابعنا على وسائل التواصل الاجتماعي:
معرض صور إضافي: 🤖⚔️ تيكن فيرسس: الحرب العالمية Claude Opus 4.7 ضد GPT-5.4 (بنكهة الكب كيك!)