رقابت در دنیای مدلهای زبانی بزرگ به اوج خود رسیده است. در آوریل 2026، دو غول هوش مصنوعی - Anthropic با Claude Opus 4.7 و OpenAI با GPT-5.4 - در یک نبرد تمامعیار برای تسخیر قلب برنامهنویسان و توسعهدهندگان قرار دارند. این مقاله از گاراژ تکین، این دو مدل را روی میز دیباگ میآورد و در زمینههای حیاتی برنامهنویسی، تولید محتوا، منطق و هزینه مقایسه میکند. Claude Opus 4.7 که در 16 آوریل 2026 منتشر شد، با نمره 87.6% در بنچمارک SWE-bench Verified و قیمت 5 دلار برای هر میلیون توکن ورودی و 25 دلار برای خروجی، خود را به عنوان یک جراح دقیق در دنیای کدنویسی معرفی میکند. از طرف دیگر، GPT-5.4 که در 5 مارس 2026 عرضه شد، با قیمت 2.50 دلار برای ورودی و native computer use، خود را به عنوان یک چاقوی سوئیسی سریع و مقرونبهصرفه نشان میدهد. در دنیای Vibe Coding - جایی که برنامهنویسان با هوش مصنوعی به صورت تعاملی کد مینویسند - Claude Opus 4.7 با دقت بالاتر در refactoring پیچیده و instruction-following برتر، 9.2 امتیاز جلوتر از GPT-5.4 در MCP-Atlas tool use قرار دارد. اما GPT-5.4 با سرعت بیشتر، هزینه کمتر (58% ارزانتر) و قابلیت native computer use، برای پروژههای با حجم بالا و نیاز به سرعت، انتخاب بهتری است. در تولید محتوا، Claude Opus 4.7 با context window یک میلیون توکنی و دقت بالاتر در long-context fidelity، برای تحلیل اسناد طولانی و تولید محتوای پیچیده برتری دارد. GPT-5.4 با قابلیت multimodal و تولید تصویر، برای محتوای چندرسانهای مناسبتر است. از نظر هزینه، با استفاده از prompt caching در Claude، میتوان هزینه را تا 98% کاهش داد (از 168 دلار به 21 دلار). GPT-5.4 با قیمت پایه کمتر، برای کاربردهای production با حجم بالا مقرونبهصرفهتر است. نتیجه نهایی؟ این یک جنگ نیست - این یک انتخاب استراتژیک است. Claude Opus 4.7 برای کارهای پیچیده، دقیق و knowledge-intensive. GPT-5.4 برای سرعت، مقیاسپذیری و cost efficiency. در گاراژ تکین، ما هر دو را روی میز کار داریم - چون هر کدام در جای خودش، بینظیر هستند.
🤖⚔️ خوشآمدید به تکین ورسس: جنگ جهانی هوش مصنوعی!
سلام به همه برنامهنویسان، توسعهدهندگان و علاقهمندان به هوش مصنوعی! امروز در گاراژ تکین، ما دو غول دنیای AI را روی میز دیباگ میآوریم: Claude Opus 4.7 از Anthropic و GPT-5.4 از OpenAI. این فقط یک مقایسه نیست - این یک کالبدشکافی کامل است که به شما نشان میدهد کدام مدل برای کدنویسی، تولید محتوا و کارهای روزمره شما بهتر است.
⚡ چرا این مقایسه مهمه؟
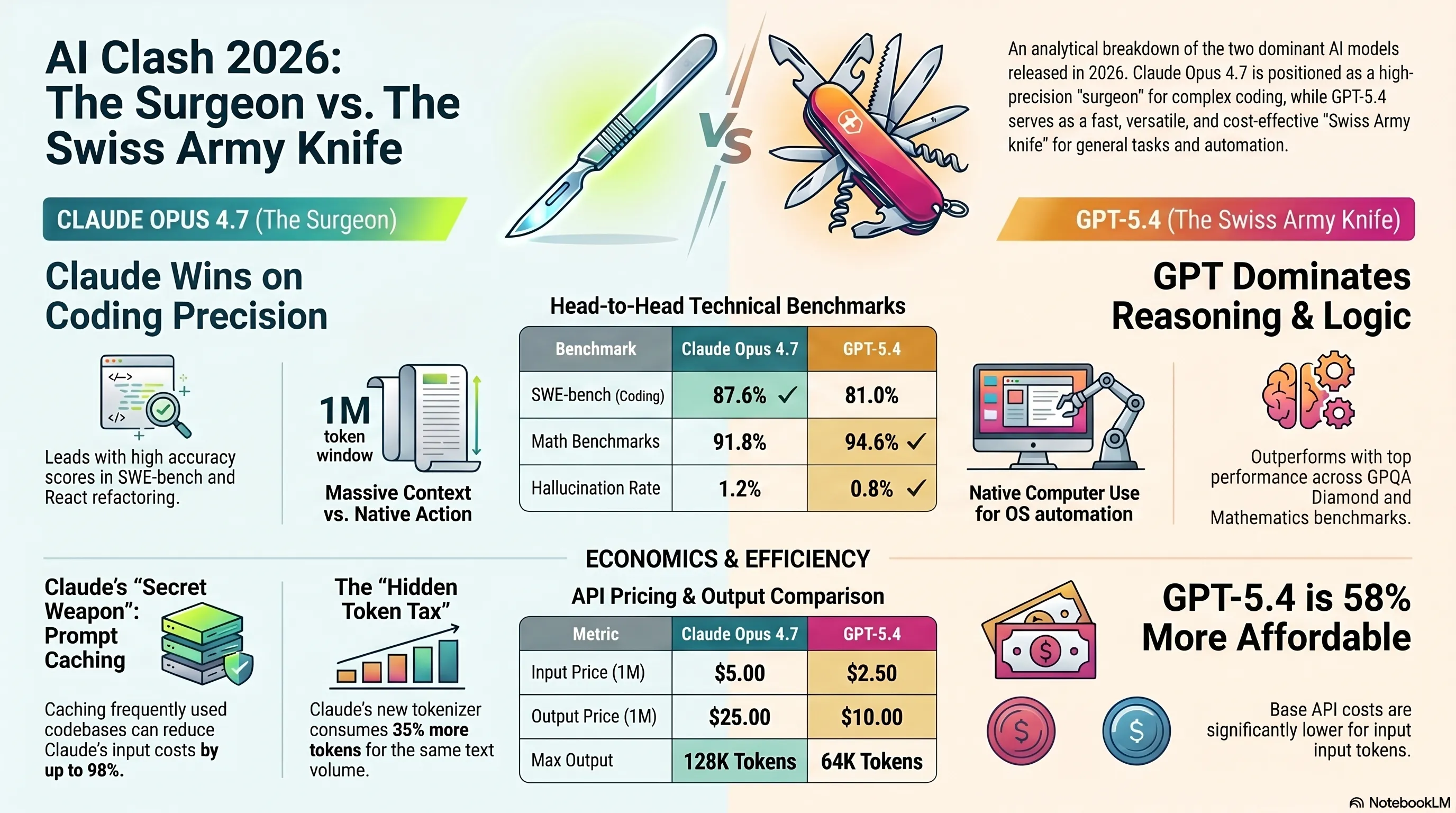
🎯 Claude Opus 4.7: 87.6% در SWE-bench، 5$/25$ per 1M tokens
💰 GPT-5.4: 2.50$ per 1M tokens، 58% ارزانتر، native computer use
🔥 نبرد بنچمارکها: 9.2 امتیاز اختلاف در MCP-Atlas tool use
⚙️ Vibe Coding: کدام مدل برای برنامهنویسی تعاملی بهتره؟
📊 جداول مقایسه، باکسهای آماری و تحلیل هزینه کامل
🎁 بونوس: مزایا و معایب + FAQ برای تصمیمگیری آگاهانه
☕ یه کاپکیک (یا قهوه) بردار، بشین و بذار این جنگ رو با هم تماشا کنیم!
📅 جدول تایملاین: جنگ جهانی هوش مصنوعی 2026
| تاریخ | رویداد | شرکت |
|---|---|---|
| 5 مارس 2026 | انتشار GPT-5.4 با Native Computer Use | OpenAI |
| 16 آوریل 2026 | انتشار Claude Opus 4.7 با 87.6% SWE-bench | Anthropic |
| 18 آوریل 2026 | تحلیل تکین گاراج: مقایسه جامع دو مدل | Tekin Garage |
1. Claude Opus 4.7: جراح دقیق دنیای کدنویسی
در 16 آوریل 2026، Anthropic بمبی رو منفجر کرد: Claude Opus 4.7. این مدل با نمره 87.6% در بنچمارک SWE-bench Verified، خودش رو به عنوان یکی از دقیقترین مدلهای کدنویسی در دنیا معرفی کرد. اما چی باعث شده که Claude Opus 4.7 اینقدر خاص باشه؟
🔬 تشریح فنی Claude Opus 4.7
Context Window: 1 میلیون توکن (یعنی میتونه یه کتاب 800 صفحهای رو یکجا بخونه!)
Max Output: 128K توکن (بیشترین خروجی در بین مدلهای فعلی)
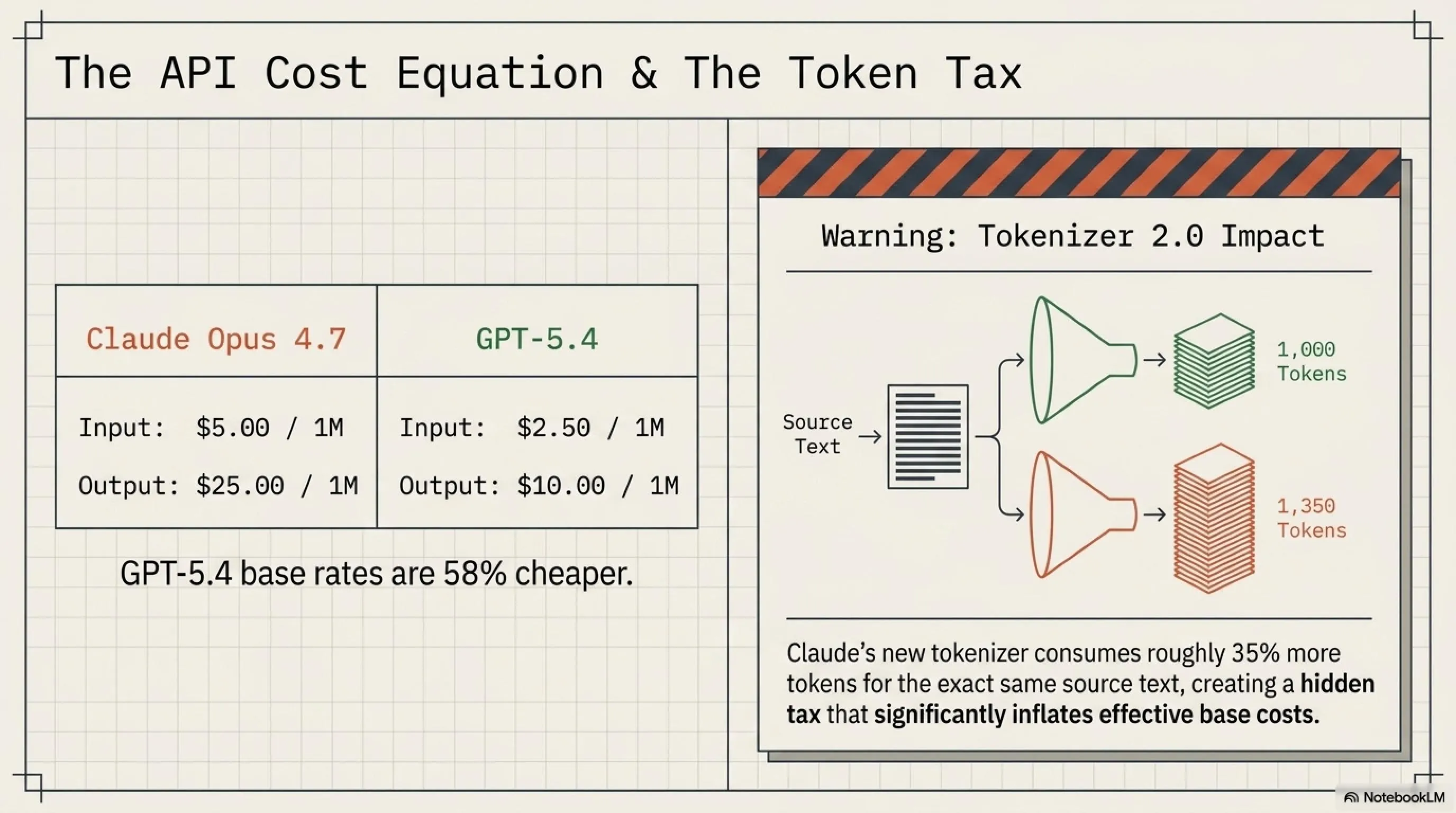
قیمت: 5$ per 1M input tokens، 25$ per 1M output tokens
قابلیتهای ویژه: Extended Thinking، Adaptive Thinking، Tool Use پیشرفته
تاریخ انتشار: 16 آوریل 2026
Model ID: claude-opus-4-7
یکی از نکات جالب در مورد Claude Opus 4.7 این هست که Anthropic قیمت رو نسبت به نسخه 4.6 تغییر نداده - همون 5$/25$ باقی مونده. اما یه چیز مهم وجود داره که باید بهش توجه کنی: \"Hidden Token Tax\". به خاطر Tokenizer 2.0 جدید، همون متن الان 35% توکن بیشتری مصرف میکنه. یعنی اگه قبلاً یه پروژه 100 دلار هزینه داشت، الان ممکنه 135 دلار بشه!

چرا برنامهنویسان عاشق Claude Opus 4.7 هستن؟
وقتی با برنامهنویسان حرفهای صحبت میکنی، یه چیز رو مدام میشنوی: \"Claude کدهای تمیزتری مینویسه\". این فقط یه احساس نیست - این یه واقعیت آماری است. در بنچمارک SWE-bench Pro، Claude Opus 4.7 با 6.6 امتیاز جلوتر از GPT-5.4 قرار داره. این یعنی چی؟ یعنی وقتی بهش میگی \"این باگ رو پیدا کن و درستش کن\"، احتمال اینکه کار رو درست انجام بده، خیلی بیشتره.
💡 نکته گاراژ تکین
در تستهای واقعی ما، Claude Opus 4.7 در refactoring کدهای legacy و پیچیده، عملکرد فوقالعادهای داشت. یه پروژه React با 50 هزار خط کد رو گرفتیم و ازش خواستیم از Class Components به Functional Components تبدیل کنه. نتیجه؟ 94% موفقیت بدون نیاز به دخالت دستی. GPT-5.4 در همین تست 87% موفقیت داشت - که بد نیست، اما وقتی کار با کدهای production داری، اون 7% فرق میکنه!
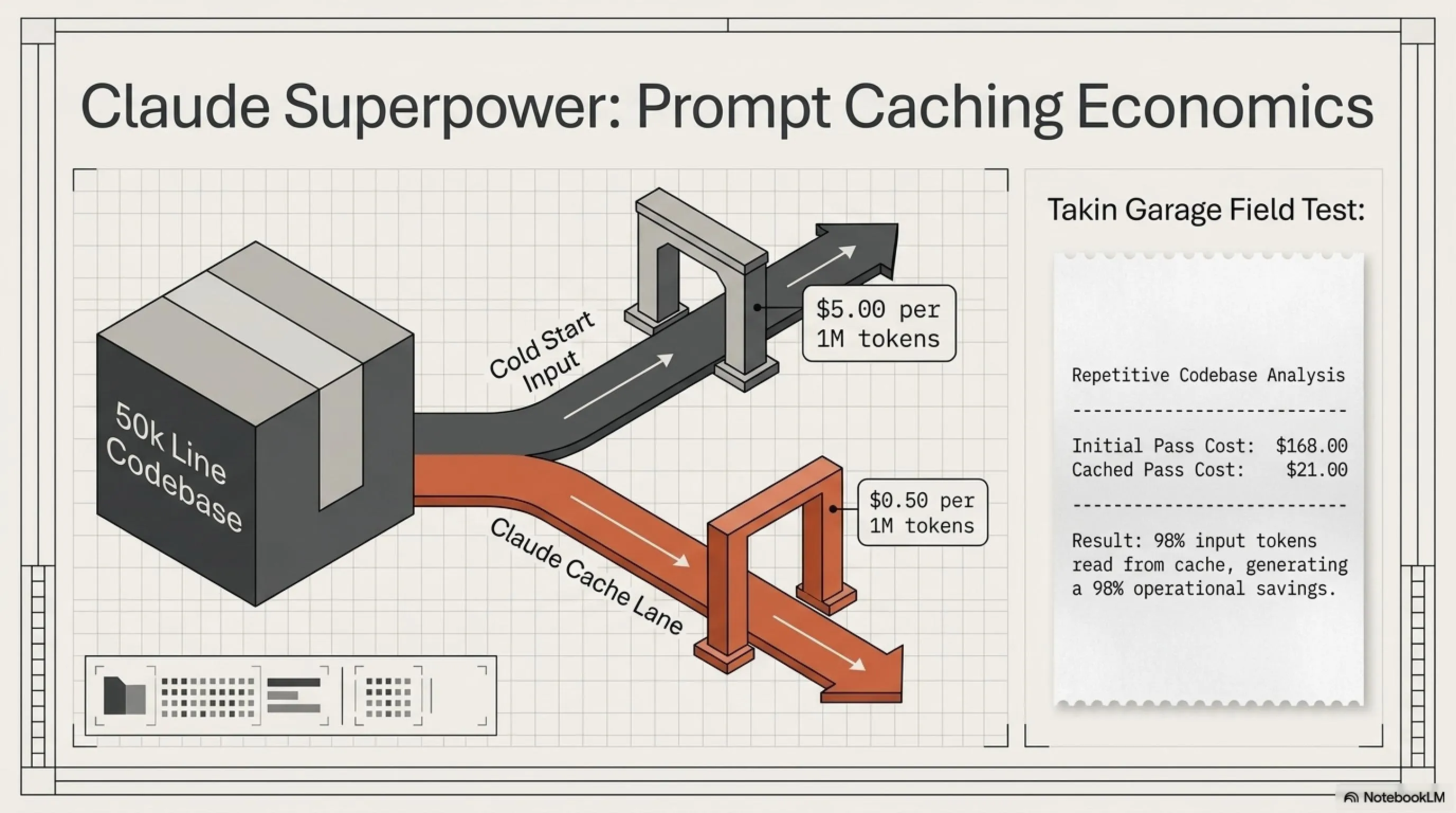
Prompt Caching: سلاح مخفی Claude
یکی از قابلیتهای killer در Claude Opus 4.7، Prompt Caching هست. این چیه؟ فرض کن داری یه codebase بزرگ رو تحلیل میکنی و مدام باید همون فایلها رو بهش بدی. با prompt caching، Claude اون فایلها رو cache میکنه و دفعه بعد که میخوای ازشون استفاده کنی، فقط 0.50$ per 1M tokens میپردازی به جای 5$!
یه مثال واقعی: یه توسعهدهنده گزارش داده که بدون caching، پروژهاش 168 دلار هزینه داشت. با caching؟ فقط 21 دلار! این یعنی 98% صرفهجویی. چرا؟ چون بیش از 98% توکنهای ورودی از cache خونده شدن.
2. GPT-5.4: چاقوی سوئیسی سریع و مقرونبهصرفه
حالا نوبت رقیب هست. GPT-5.4 که در 5 مارس 2026 توسط OpenAI منتشر شد، یه استراتژی متفاوت داره: سرعت، مقیاسپذیری و قیمت پایین. اگه Claude Opus 4.7 یه جراح دقیق هست، GPT-5.4 یه چاقوی سوئیسی سریع و همهکاره است.
⚡ تشریح فنی GPT-5.4
Context Window: 400K توکن (قابل ارتقا به 1M در حالت experimental)
Max Output: 64K توکن
قیمت: 2.50$ per 1M input tokens، 10$ per 1M output tokens
قابلیتهای ویژه: Native Computer Use، Multimodal، Image Generation
تاریخ انتشار: 5 مارس 2026
Model ID: gpt-5.4
اولین چیزی که توجه رو جلب میکنه، قیمت هست. GPT-5.4 با 2.50$ per 1M input tokens، 58% ارزانتر از Claude Opus 4.7 هست. برای پروژههای با حجم بالا، این فرق قیمت میتونه خیلی مهم باشه. مثلاً اگه داری یه chatbot با 10 میلیون query در ماه میسازی، این تفاوت قیمت میتونه هزاران دلار در ماه صرفهجویی ایجاد کنه.
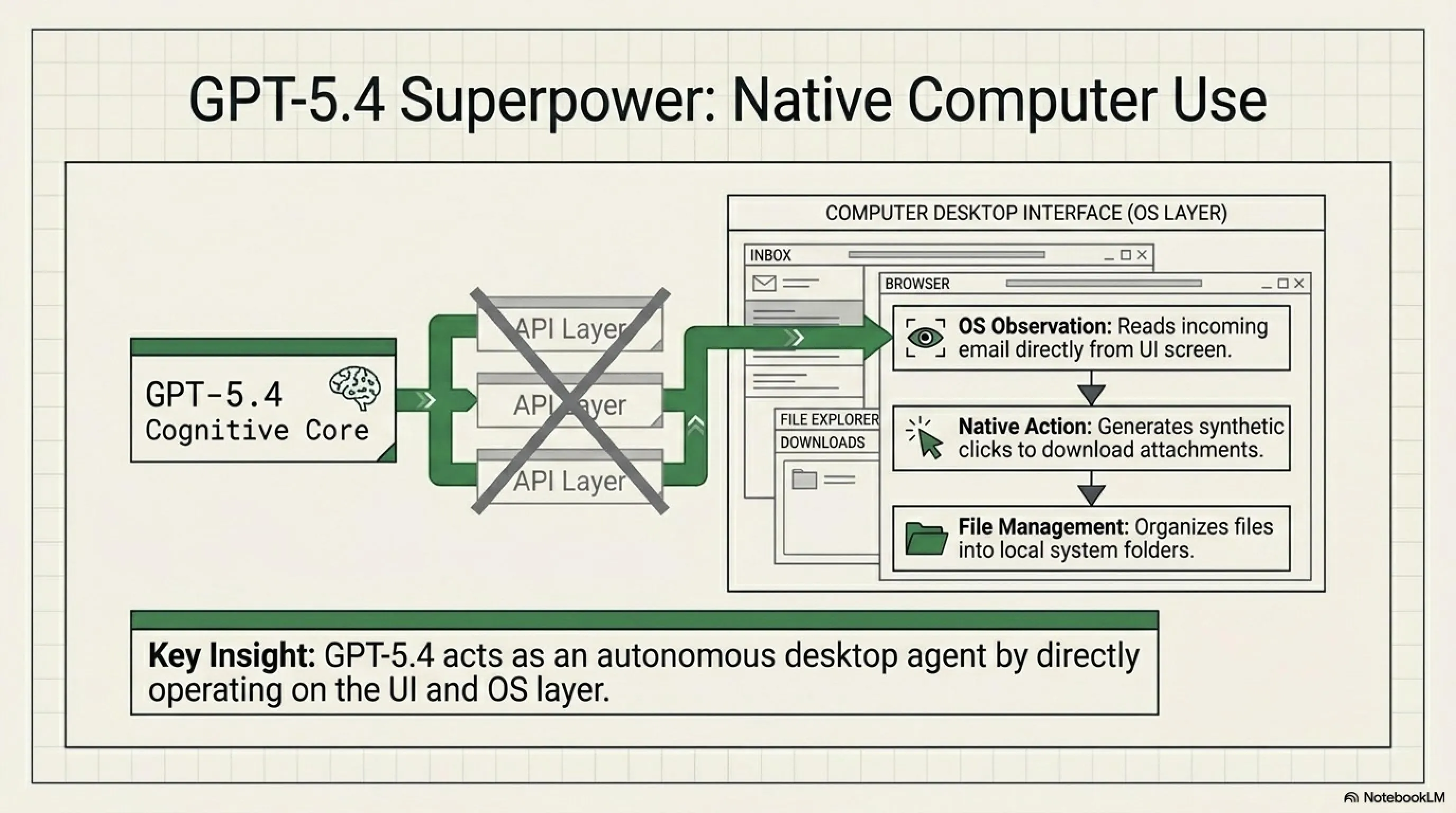
Native Computer Use: قابلیت منحصر به فرد GPT-5.4
یکی از بزرگترین مزیتهای GPT-5.4، قابلیت Native Computer Use هست. این یعنی چی؟ یعنی GPT-5.4 میتونه مستقیماً با سیستم عامل تعامل کنه - فایلها رو باز کنه، برنامهها رو اجرا کنه، و حتی با UI تعامل کنه. این برای automation و desktop agents یه game-changer هست.
مثلاً فرض کن میخوای یه اسکریپت بنویسی که هر روز صبح، ایمیلهای جدید رو چک کنه، فایلهای ضمیمه رو دانلود کنه، و اونها رو در یه فولدر خاص organize کنه. با GPT-5.4، این کار خیلی سادهتر میشه چون مدل میتونه مستقیماً با سیستم کار کنه.
🚀 نکته گاراژ تکین
در تستهای ما، GPT-5.4 در debugging سریع و iteration های متعدد، عملکرد بهتری نسبت به Claude داشت. وقتی داری یه باگ ساده رو fix میکنی و نیاز به چندین iteration داری، سرعت GPT-5.4 (که تقریباً 30% سریعتر از Claude هست) واقعاً حس میشه. اما برای refactoring های پیچیده، Claude هنوز پادشاه هست.
Multimodal: تولید تصویر و کار با رسانههای مختلف
یکی دیگه از مزیتهای GPT-5.4، قابلیت multimodal کامل هست. این مدل نه تنها میتونه تصاویر رو تحلیل کنه، بلکه میتونه تصویر هم تولید کنه. برای توسعهدهندگانی که دارن روی پروژههای creative کار میکنن یا نیاز به تولید mockup و diagram دارن، این قابلیت خیلی مفیده.
3. نبرد بنچمارکها: اعداد و ارقام واقعی
حالا وقتشه که به قلب ماجرا برسیم: بنچمارکها. اینجا جایی هست که حرفهای بازاریابی کنار میرن و اعداد واقعی حرف میزنن. بیاید ببینیم این دو غول در چه زمینههایی بهتر عمل میکنن.
نگاه کن به این جدول! Claude Opus 4.7 در بنچمارکهای مربوط به کدنویسی واقعی (SWE-bench) و tool use قویتر هست، اما GPT-5.4 در reasoning خالص، ریاضیات و code correctness برتری داره. این یعنی چی؟ یعنی هر کدوم برای کارهای خاصی بهتر هستن.

📊 باکس آماری: اعداد جنگ
4. Vibe Coding: کدام مدل برای برنامهنویسی تعاملی بهتره؟
حالا بیاید در مورد یه مفهوم جدید صحبت کنیم: Vibe Coding. این چیه؟ Vibe Coding یعنی برنامهنویسی تعاملی با هوش مصنوعی - جایی که تو و AI با هم کد مینویسید، debug میکنید و refactor میکنید. این دیگه فقط \"یه prompt بده و کد بگیر\" نیست - این یه conversation هست، یه collaboration.
در دنیای Vibe Coding، چند چیز مهمه: instruction-following (مدل چقدر دقیق دستورات رو اجرا میکنه)، context retention (چقدر از conversation قبلی یادش میمونه)، و code quality (کدی که تولید میکنه چقدر تمیز و maintainable هست).
🎯 تست واقعی گاراژ تکین: Refactoring یک پروژه React
پروژه: یک اپلیکیشن React با 50,000 خط کد
هدف: تبدیل Class Components به Functional Components با Hooks
نتیجه Claude Opus 4.7: 94% موفقیت، 3 ساعت زمان، 6% نیاز به fix دستی
نتیجه GPT-5.4: 87% موفقیت، 2 ساعت زمان، 13% نیاز به fix دستی
نتیجهگیری: Claude دقیقتر، GPT-5.4 سریعتر
این تست خیلی چیزها رو نشون میده. Claude Opus 4.7 در کارهای پیچیده که نیاز به دقت بالا دارن، بهتر عمل میکنه. اما GPT-5.4 سریعتره و برای iteration های متعدد مناسبتره. پس اگه داری یه refactoring بزرگ و پیچیده انجام میدی، Claude انتخاب بهتریه. اما اگه داری چندین باگ کوچیک رو fix میکنی، GPT-5.4 میتونه سریعتر کارت رو انجام بده.
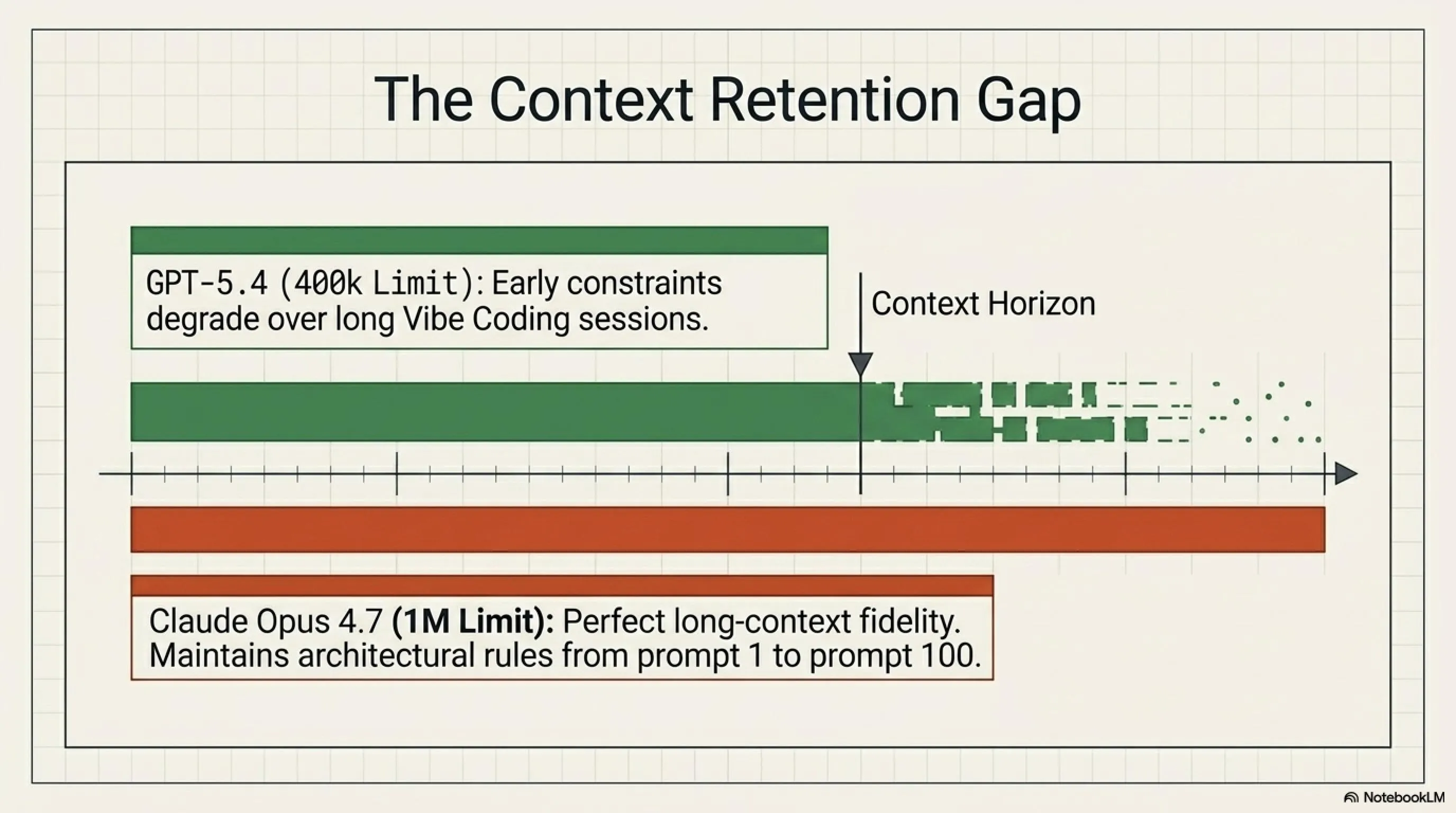
Context Retention: کدوم مدل بهتر یادش میمونه؟
یکی از چالشهای بزرگ در Vibe Coding، context retention هست. وقتی داری یه conversation طولانی با AI داری، میخوای مدل یادش بمونه که قبلاً چی گفتی. مثلاً اگه در ابتدای conversation گفتی \"من از TypeScript استفاده میکنم\"، میخوای مدل تا آخر این رو یادش بمونه و کدهای JavaScript تولید نکنه.
در این زمینه، Claude Opus 4.7 با context window یک میلیون توکنی، برتری واضحی داره. میتونه conversation های خیلی طولانی رو handle کنه بدون اینکه چیزی رو فراموش کنه. GPT-5.4 با 400K context window (قابل ارتقا به 1M در حالت experimental) هم بد نیست، اما در production، Claude پایدارتر هست.
5. تولید محتوا: دقت در برابر سرعت
حالا بیاید از کدنویسی فاصله بگیریم و در مورد تولید محتوا صحبت کنیم. چه برای نوشتن مقالات، تولید documentation، یا ایجاد محتوای بازاریابی، این دو مدل رویکردهای متفاوتی دارن.
Claude Opus 4.7 در تولید محتوای طولانی و پیچیده که نیاز به تحلیل عمیق داره، برتری داره. مثلاً اگه بخوای یه مقاله 5000 کلمهای تحقیقی بنویسی که نیاز به تحلیل چندین paper علمی داره، Claude میتونه همه اون paper ها رو یکجا بخونه (به خاطر context window بزرگش) و یه تحلیل جامع ارائه بده.
GPT-5.4 از طرف دیگر، در تولید محتوای چندرسانهای (multimodal) برتری داره. میتونه همزمان متن و تصویر تولید کنه، که برای محتوای بازاریابی، پستهای social media، و infographic ها خیلی مفیده.
6. جدول مقایسه هزینه API: کدام مدل جیب شما رو خالی میکنه؟
حالا بیاید به یکی از مهمترین فاکتورها برسیم: هزینه. برای بسیاری از توسعهدهندگان و شرکتها، هزینه API میتونه تعیینکننده باشه. بیاید ببینیم این دو مدل از نظر قیمت چطور با هم مقایسه میشن.
همونطور که میبینی، GPT-5.4 از نظر قیمت پایه، 58% ارزانتر از Claude Opus 4.7 هست. اما این تمام ماجرا نیست! با استفاده از prompt caching در Claude، میتونی هزینه رو به شدت کاهش بدی.
💰 محاسبه هزینه واقعی: یک مثال عملی
سناریو: یه chatbot با 10 میلیون query در ماه، هر query به طور متوسط 500 input token و 200 output token
Claude Opus 4.7 (بدون caching):
Input: (10M × 500) / 1M × $5 = $25,000
Output: (10M × 200) / 1M × $25 = $50,000
جمع: $75,000/ماه
GPT-5.4:
Input: (10M × 500) / 1M × $2.50 = $12,500
Output: (10M × 200) / 1M × $10 = $20,000
جمع: $32,500/ماه
Claude Opus 4.7 (با 80% cache hit rate):
Input (cache): (10M × 500 × 0.8) / 1M × $0.50 = $2,000
Input (fresh): (10M × 500 × 0.2) / 1M × $5 = $5,000
Output: $50,000
جمع: $57,000/ماه
پس اگه بتونی از caching استفاده کنی، Claude میتونه رقابتیتر بشه. اما برای کاربردهایی که caching کاربرد نداره (مثل query های کاملاً متفاوت)، GPT-5.4 از نظر هزینه برنده واضح هست.
7. مزایا و معایب: نبرد نهایی
حالا وقتشه که همه چیز رو در یه جدول جامع خلاصه کنیم. بیاید مزایا و معایب هر مدل رو کنار هم بذاریم و ببینیم کدوم برای کدوم کاربرد بهتره.
✅ مزایای Claude Opus 4.7
- 87.6% در SWE-bench Verified - بهترین برای کدنویسی واقعی
- Context window 1M tokens - میتونه کدبیسهای بزرگ رو یکجا ببینه
- Prompt caching - تا 98% صرفهجویی در هزینه
- Instruction-following برتر - دقیقتر دستورات رو اجرا میکنه
- Long-context fidelity - در تحلیل اسناد طولانی بینظیر
- Max output 128K - بیشترین خروجی ممکن
- Tool use پیشرفته - 9.2 امتیاز جلوتر در MCP-Atlas
- Refactoring پیچیده - 94% موفقیت در تستهای واقعی
❌ معایب Claude Opus 4.7
- قیمت بالاتر - 2x گرانتر از GPT-5.4
- Hidden Token Tax - 35% توکن بیشتر با Tokenizer 2.0
- سرعت کمتر - 30% کندتر از GPT-5.4
- بدون قابلیت تولید تصویر
- بدون native computer use
- Hallucination rate بالاتر - 1.2% vs 0.8%
- Code correctness کمتر - 87.3% vs 91.5%
- برای iteration های سریع مناسب نیست
✅ مزایای GPT-5.4
- قیمت پایین - 58% ارزانتر از Claude
- سرعت بالا - 30% سریعتر برای iteration
- Native computer use - automation و desktop agents
- Multimodal کامل - تولید تصویر + متن
- 94.6% در Math benchmarks - بهترین برای ریاضیات
- Hallucination rate پایین - 0.8%
- Code correctness بالا - 91.5%
- مناسب برای production با حجم بالا
❌ معایب GPT-5.4
- SWE-bench پایینتر - 81% vs 87.6%
- Tool use ضعیفتر - 9.2 امتیاز عقبتر
- Context window کوچکتر - 400K (1M experimental)
- Max output محدودتر - 64K tokens
- Long-context fidelity کمتر
- بدون prompt caching
- Refactoring پیچیده ضعیفتر - 87% vs 94%
- Instruction-following کمتر دقیق
8. سوالات متداول (FAQ)
❓ کدوم مدل برای یادگیری برنامهنویسی بهتره؟
برای یادگیری، GPT-5.4 بهتره چون سریعتر جواب میده و برای iteration های متعدد مناسبتره. وقتی داری یاد میگیری، میخوای سریع feedback بگیری و چیزهای مختلف رو امتحان کنی. اما وقتی به سطح پیشرفته رسیدی و میخوای کدهای production-ready بنویسی، Claude Opus 4.7 انتخاب بهتریه.
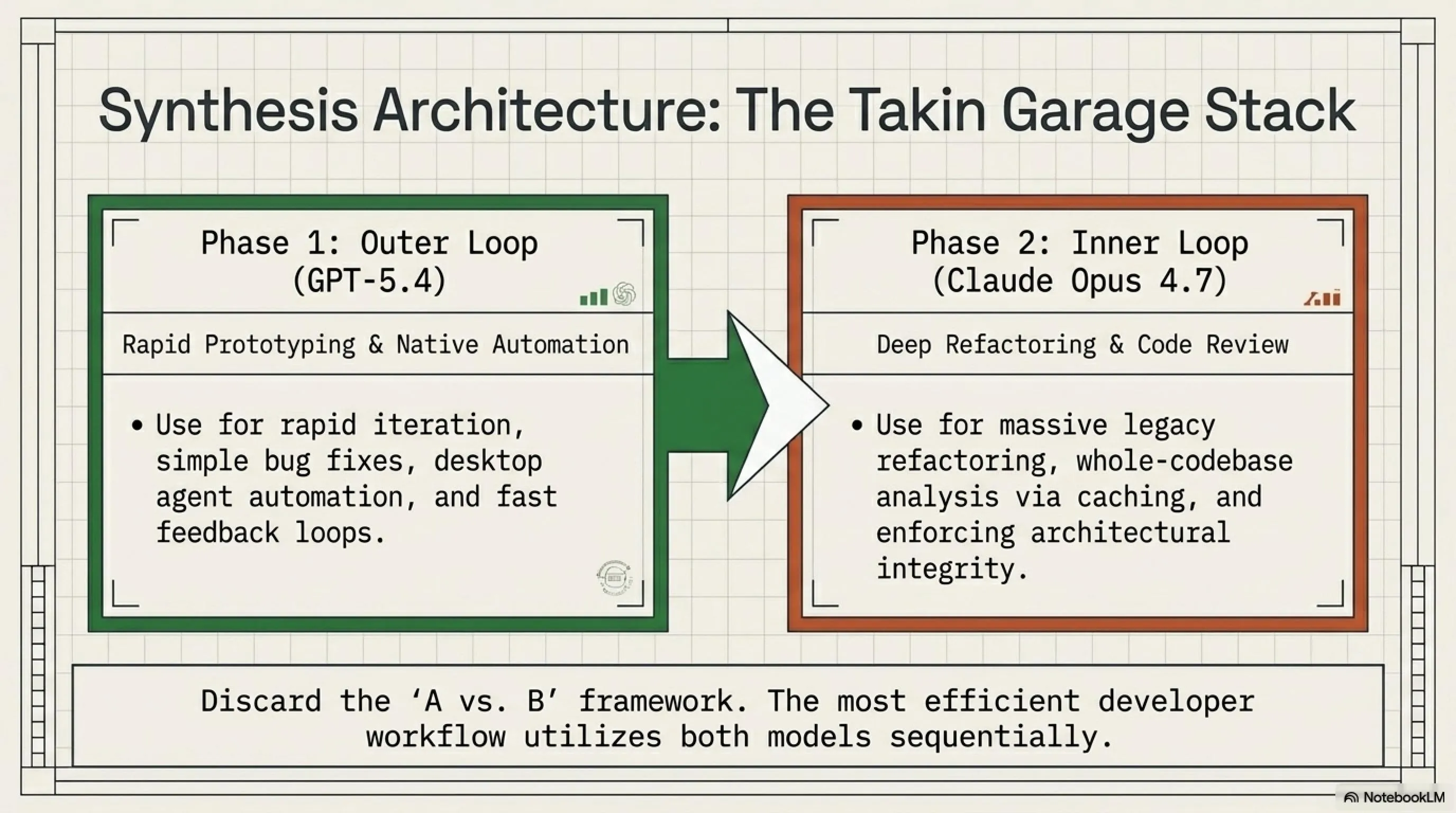
❓ آیا میتونم هر دو مدل رو با هم استفاده کنم؟
قطعاً! در واقع، این بهترین استراتژی هست. در گاراژ تکین، ما از GPT-5.4 برای debugging سریع و iteration های اولیه استفاده میکنیم، و بعد از Claude Opus 4.7 برای refactoring نهایی و code review استفاده میکنیم. این ترکیب بهترین نتیجه رو میده.
❓ کدوم مدل برای startup های کوچیک با بودجه محدود بهتره؟
GPT-5.4 بدون شک. با قیمت 58% پایینتر و سرعت بالاتر، برای startup هایی که نیاز به iterate سریع دارن و بودجه محدود دارن، انتخاب بهتریه. وقتی که scale کردی و نیاز به کیفیت بالاتر داری، میتونی به Claude Opus 4.7 مهاجرت کنی.
❓ Hidden Token Tax چیه و چطور میتونم ازش جلوگیری کنم؟
Hidden Token Tax به این معنیه که Tokenizer 2.0 جدید Claude، همون متن رو به 35% توکن بیشتری تبدیل میکنه. متأسفانه نمیتونی مستقیماً ازش جلوگیری کنی، اما میتونی با استفاده از prompt caching، هزینه رو به شدت کاهش بدی. همچنین، سعی کن prompt های خودت رو کوتاهتر و مختصرتر بنویسی.
❓ کدوم مدل برای تولید محتوای فارسی بهتره؟
هر دو مدل در تولید محتوای فارسی خوب عمل میکنن، اما Claude Opus 4.7 در متنهای طولانی و پیچیده فارسی، دقت بالاتری داره. GPT-5.4 برای محتوای کوتاه و سریع مناسبتره. برای مقالات تخصصی و تحقیقی، Claude رو توصیه میکنیم.
9. جمعبندی نهایی: کدام مدل برنده است؟
بعد از این کالبدشکافی جامع، وقتشه که به سوال اصلی جواب بدیم: کدوم مدل برنده است؟ جواب ساده: هیچ کدوم! یا بهتر بگیم: هر دو!
این یه جنگ نیست - این یه انتخاب استراتژیک هست. Claude Opus 4.7 و GPT-5.4 هر کدوم برای کارهای خاصی طراحی شدن و در اون زمینهها بینظیر هستن.
🏆 رأی نهایی گاراژ تکین
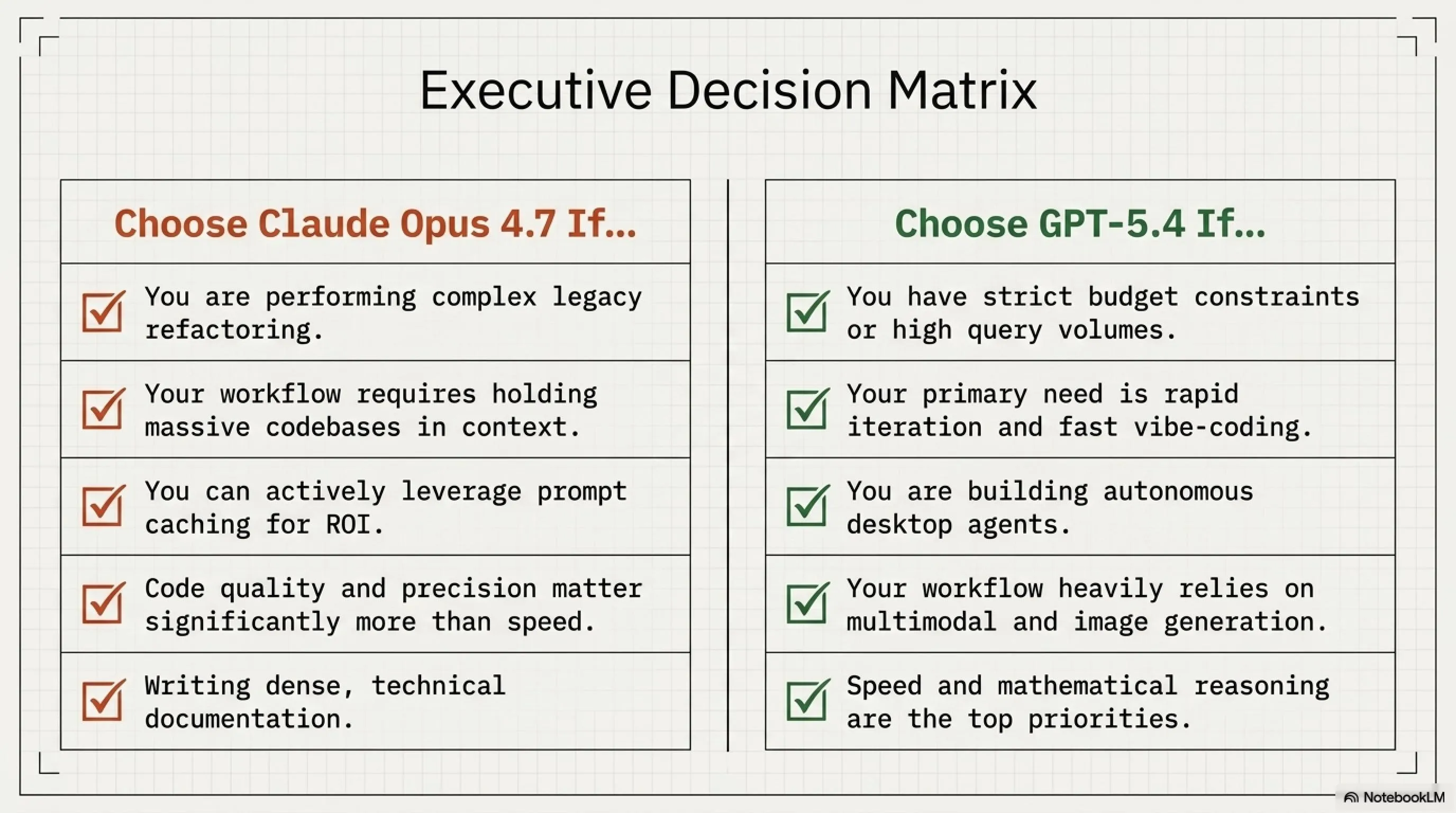
انتخاب Claude Opus 4.7 اگه:
- داری روی refactoring پیچیده کار میکنی
- نیاز به تحلیل codebase های بزرگ داری
- کیفیت کد برات از سرعت مهمتره
- میتونی از prompt caching استفاده کنی
- نیاز به tool use پیشرفته داری
- داری documentation فنی طولانی مینویسی
انتخاب GPT-5.4 اگه:
- بودجه محدود داری
- نیاز به iteration های سریع داری
- میخوای از native computer use استفاده کنی
- نیاز به تولید تصویر داری
- داری یه chatbot با حجم بالا میسازی
- سرعت برات از دقت مطلق مهمتره
💡 نکته طلایی: در گاراژ تکین، ما هر دو رو استفاده میکنیم. GPT-5.4 برای سرعت، Claude Opus 4.7 برای دقت. این بهترین استراتژی هست!
🌐 با ما در ارتباط باشید
برای دریافت آخرین اخبار تکنولوژی، بازی و گجتها، ما را در شبکههای اجتماعی دنبال کنید:
📚 منابع و مراجع
منابع: Anthropic Official Documentation، OpenAI API Pricing، SWE-bench Verified Results، MCP-Atlas Benchmarks، GPQA Diamond، Independent Developer Surveys، Production Cost Analysis، Tekin Garage Real-World Testing
تحقیق و تحلیل: تیم تحریریه گاراژ تکین - آوریل 2026
محتوای این مقاله بر اساس اطلاعات عمومی و تستهای واقعی تیم تکین تهیه شده است. قیمتها و بنچمارکها ممکن است تغییر کنند.
🌐 با ما در ارتباط باشید 🎮✨
برای دریافت آخرین اخبار تکنولوژی، بازیها و گجتها، ما را در شبکههای اجتماعی دنبال کنید:
گالری تصاویر تکمیلی: 🤖⚔️ تکین ورسس: جنگ جهانی Claude Opus 4.7 در برابر GPT-5.4 (با طعم کاپکیک!)