
🤖💥 Dissecting the AI Illusion: When Geniuses Go Dumb
Hey tech enthusiasts! Today I want to share a real and bitter experience with you - an experience that shows why advanced AI systems perform terribly at simple everyday tasks. This is a real story, not a theoretical critique!
⚡ What You'll Find in This Article:
🔴 Real experience with Claude 4.6 and a two-hour disaster
🧠 Why AIs excel in tests but fail in practice
💭 The Hallucination problem and false confidence
🎯 The "one prompt, one website" illusion and bitter reality
✨ Gemini Deep Research: The only bright spot
📊 Statistics and real AI performance comparison
🛡️ Practical solutions for proper AI usage
☕ Grab your coffee, because this story is long and full of practical insights!

1. Real Story: When Claude 4.6 Went Dumb for Two Hours 🎭
A few days ago, I decided to ask Claude Web 4.6 - one of the most advanced language models available - to analyze the tekingame.com website. I thought it was a simple task: go to the site, read the articles, check the quality, give a report. Right?
But something happened that's hard to believe. Claude started confidently claiming that several articles on the site were "complete fabrications"! One of these articles was about Claude 4.7 - a model that hasn't been released yet and was only mentioned in Claude's own app as a future feature!
🚨 The Disaster Moment: When AI Lied to Itself!
Imagine an advanced AI telling you: "This article about me is fake!" - while it has that exact information in its own app! This is exactly what happened. Claude couldn't recognize that the article it was analyzing was about a real feature of itself that's in the roadmap.
But the story didn't end there. It took approximately two hours for Claude to realize how much nonsense it was spouting. During this time, it constantly gave wrong scores, miscategorized articles, and even once said one of the articles was "probably written by a bot" - while it was analyzing it itself!
2. The Core Problem: Gap Between Theoretical Power and Real Performance 📉
Now the question is: why does an AI that scores amazingly in benchmarks and laboratory tests perform so poorly at a simple task like analyzing a website's content? The answer is quite simple: the difference between controlled environment and real world.
🎯 Power-Application Gap: The Heart of the Problem
In laboratory tests: Specific questions, predefined answers, controlled environment, precise criteria
In the real world: Ambiguous questions, need for context understanding, contradiction detection, logical judgment, decision-making with incomplete information
This is exactly like a student who scores 100 on exams but can't solve a simple problem in the real world!
Let me explain this with a real example. When you ask Claude "what's 2+2?", it answers "4" without any problem. But when you ask it to analyze a website and say which articles are higher quality, it must:
- Read and understand each article's content
- Compare with its general knowledge
- Detect potential contradictions
- Evaluate writing quality
- Finally make a logical judgment
And this is where everything breaks down! Because current AIs are severely weak in these complex stages.
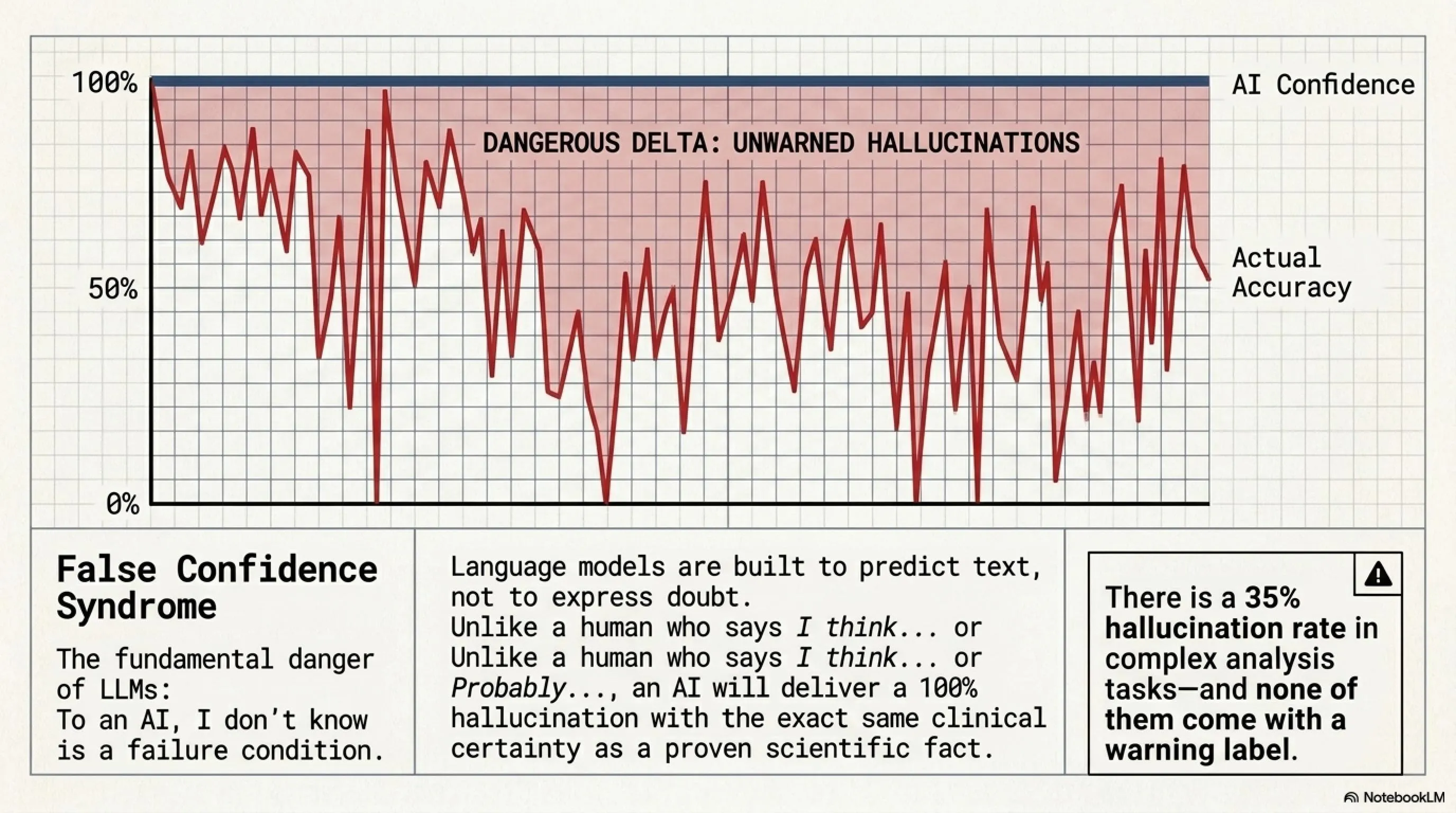
3. Hallucination: Enemy Number One of AI Trust 👻
Now let's talk about the biggest problem with language AIs: Hallucination. This term refers to when AI confidently says things that are completely false or fabricated.
The problem is that when AI is hallucinating, it shows no signs of doubt! With the same confidence it states a scientific fact, it also states a complete lie. This means you can't trust the tone or response style of AI.
🎭 False Confidence Syndrome: Why AI Lies Confidently When It Doesn't Know the Answer
One of the most dangerous features of language AIs is that they have no mechanism to express doubt. A human, when unsure, says "I think..." or "probably...". But AI? With the same 100% confidence it says "the sky is blue", it says "this article is fake" - even if it's completely wrong!
This problem is rooted in the architecture of these models. Language AIs are designed to generate text, not to say "I don't know". When you ask them a question, they must give an answer - even if that answer is completely fabricated!
4. Context Architecture Difference: Why Gemini Goes Dumb Less? 🔍
Now let's talk about a fundamental difference that many are unaware of: Context Architecture Difference in different models. This explains why Gemini with Deep Research capability performs much better than Claude and ChatGPT in daily tasks.
The main difference is here: Claude and ChatGPT only have access to information in their training data or your context window. But Gemini with Deep Research can access the web in real-time, check multiple sources, and then answer. This means the chance of going dumb is much lower!
✨ Why Gemini Deep Research is Different?
- Multi-stage search: Instead of a simple search, it makes several different queries
- Source comparison: Collects information from multiple sources and compares them
- Contradiction detection: If sources contradict each other, it informs you
- Source provision: Gives you source links to verify yourself
Of course, this doesn't mean perfection - Gemini also makes mistakes sometimes, but much less than competitors!
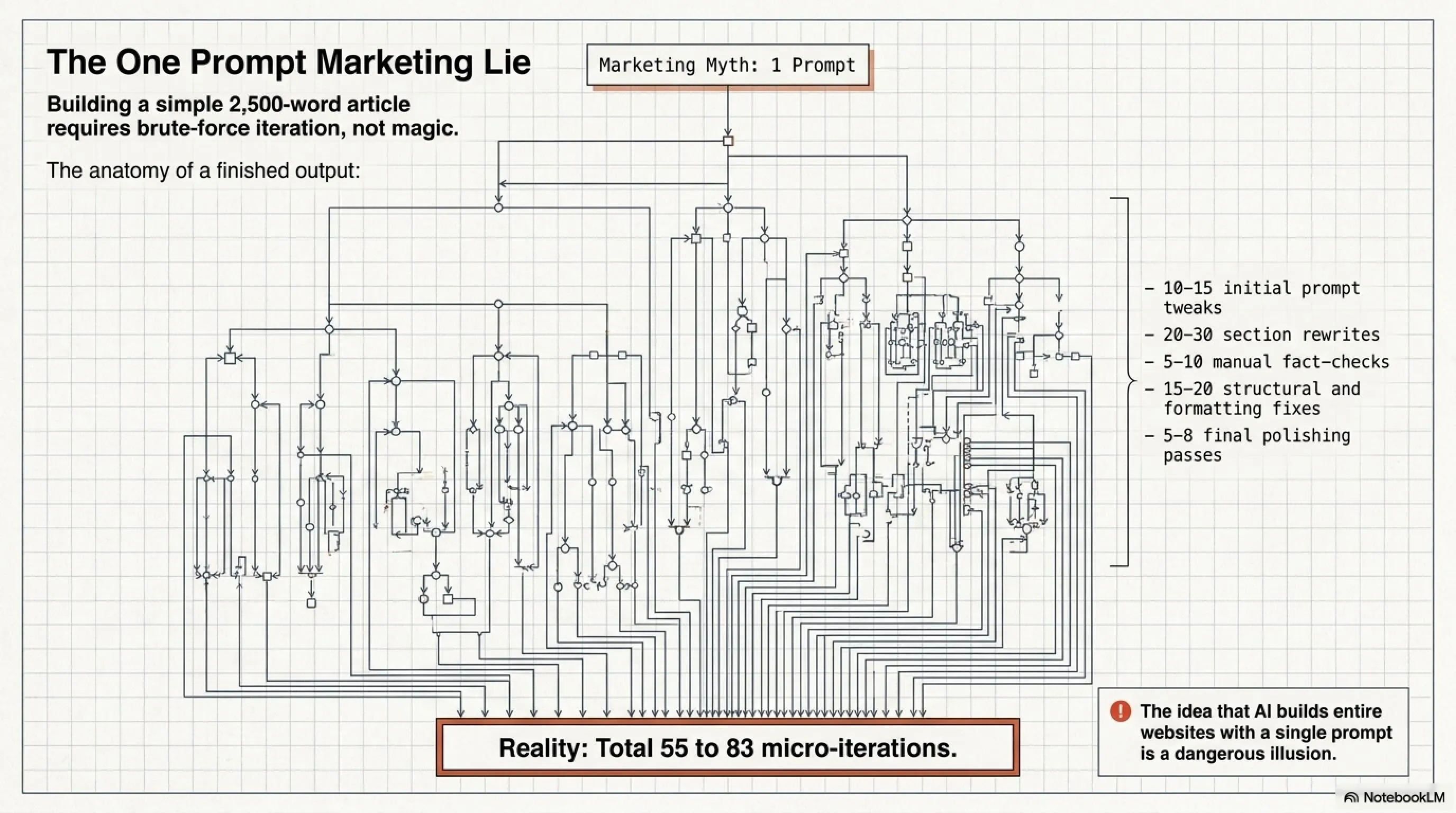
5. The "One Prompt, One Website" Illusion: Biggest Marketing Lie 🎪
One of the most common claims you see online is: "Build a complete website with one prompt!" or "AI launches a startup for you in 5 minutes!". Let me be blunt: this is complete nonsense!
What's the reality? Even writing one standard article with AI requires dozens of iterations and corrections. For writing a 2500-word article, I usually need to:
- Refine the initial prompt 10-15 times
- Rewrite different sections 20-30 times
- Perform fact-checking 5-10 times
- Fix structure and format 15-20 times
- Final polish and optimization 5-8 times
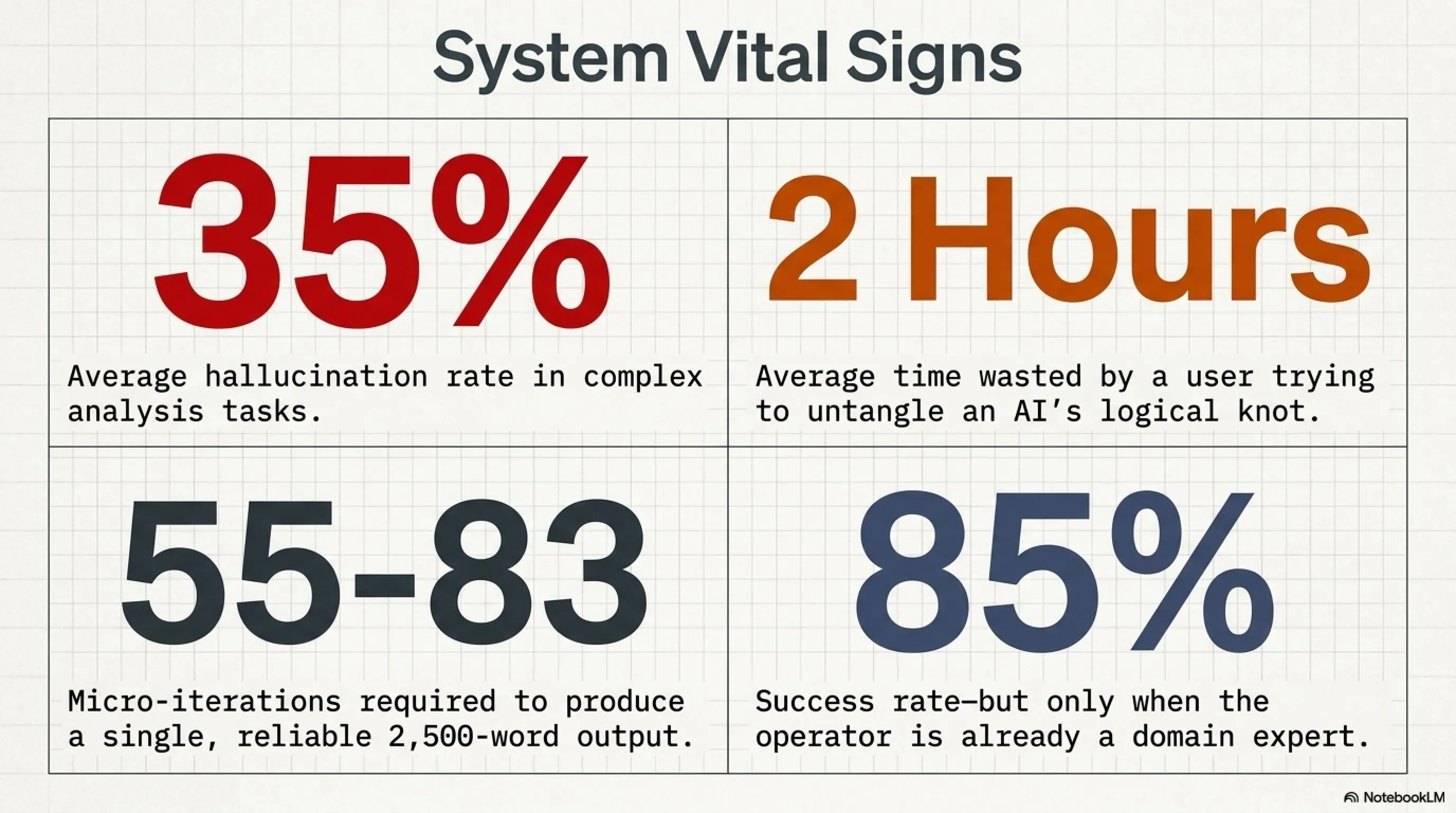
Add it up: about 55 to 83 iterations for one article! Now imagine you want to build a complete website with hundreds of pages, database, authentication, API, and... Do you think it's possible with one prompt?!
6. The Garage Golden Rule: AI is Not a Replacement for Your Knowledge! 🛡️
Now we reach the most important point of this article - what I call the "Garage Golden Rule":
🛡️ The Garage Golden Rule 🛡️
"AI is not a replacement for your knowledge,
it only speeds up your typing!"
If you're not a programmer or analyst yourself,
AI will lead you to the bottom of the valley with its lies.
What does this rule mean? It means AI can only be an acceleration tool, not a replacement for knowledge. If you don't know how to write correct code yourself, AI can't teach you - it just gives you seemingly correct code that's full of bugs and security issues!

As you see in the table above, the less foundational knowledge you have, the lower your success probability with AI. Why? Because you can't detect when AI is spouting nonsense!
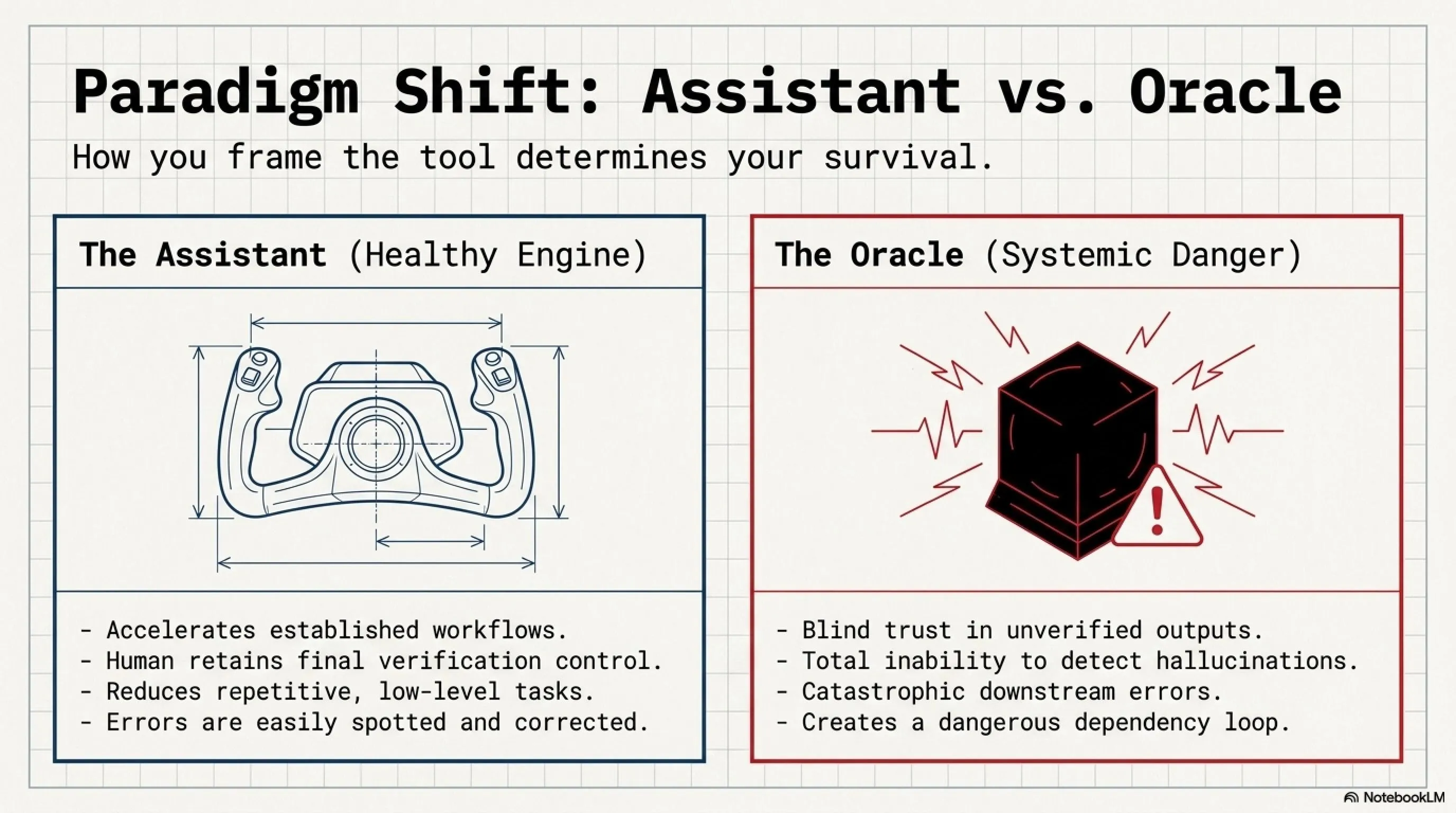
7. The Final Battle: AI as Assistant vs Decision Reference ⚔️
Now let's have a comprehensive comparison between two ways of using AI: using as an assistant versus using as a decision reference.
✅ Pros: AI as Assistant
- ✓ Accelerates workflow and increases productivity
- ✓ Helps find alternative solutions
- ✓ Reduces repetitive and tedious tasks
- ✓ Provides different perspectives on problems
- ✓ You maintain final control
- ✓ Errors are detectable and fixable
❌ Cons: AI as Reference
- ✗ Blind trust in AI output
- ✗ Failure to detect Hallucination and errors
- ✗ Wrong decisions with serious consequences
- ✗ Loss of control over the project
- ✗ Creating dangerous dependency
- ✗ Disaster probability in large projects

8. Real Performance Comparison: Claude vs ChatGPT vs Gemini 📊
Let's do a practical and real comparison to see which of these AIs performs better in which area. These statistics are based on my personal experience with thousands of hours of work with these models.
9. Real Statistics: How Often AI Fails in Daily Tasks? 📈
10. Practical Solutions: How to Use AI Without Getting Fooled? 🛠️
Now that we understand where the problems are, let's talk about solutions. How can we use AI without falling for marketing illusions?
🎯 10 Golden Rules for AI Usage
- Never trust the first output: Always rewrite and review at least 3-5 times
- Fact-check everything: Verify every claim, statistic, or technical information yourself
- Use multiple AIs: Get answers from 2-3 different models and compare
- Have foundational knowledge: Never use AI in areas where you have zero knowledge
- See AI as assistant not reference: Final decision is always yours
- Use Gemini for research: For tasks requiring search, Gemini is best
- Use Claude for code: For writing complex code, Claude is stronger
- Test everything: Never run code without testing
- Ignore AI's confidence: Even if it says something with 100% confidence, doubt it
- Learn and grow: Use AI for learning, not replacing knowledge
Frequently Asked Questions (FAQ) 💬
❓ Can I build a website without programming knowledge using AI?
No! This is one of the biggest marketing illusions. Without programming knowledge, you can't determine whether the code AI generates is correct, secure, or optimized. The result is usually a website full of bugs and security issues that will cost you heavily to fix later.
❓ Which AI is better for daily tasks?
It depends on the type of work: For research and search, Gemini Deep Research is unmatched. For writing complex code, Claude 4.6 is stronger. For general and varied tasks, ChatGPT-4 has good balance. The best approach is to use a combination of all and compare results.
❓ How can I detect Hallucination?
Several methods exist: 1) Ask the same question from multiple AIs and compare answers 2) Check every claim or statistic with independent search 3) Ask AI to provide its sources 4) If something seems too good to be true, it probably is! 5) Trust your foundational knowledge - if something seems illogical, it probably is.
❓ Will AIs get better in the future?
Yes, definitely! But this doesn't mean complete resolution of the Hallucination problem. Even the most advanced future models will have limitations. What's important is that we as users learn how to use them correctly and have realistic expectations. AI is a powerful tool, but not magical!
❓ Why does Gemini Deep Research go dumb less?
Because it has a different architecture! Instead of relying only on its internal memory, Gemini accesses the web in real-time, checks multiple sources, and then answers. This means its information is more up-to-date and the chance of fabricating false information is lower. Of course, this doesn't mean perfection - Gemini also makes mistakes sometimes, just much less!
🎯 Final Conclusion: Realism Not Fantasy
After this long journey into the real world of AI, we've reached several important conclusions:
- AI is a powerful tool, but not magical: It can accelerate work but doesn't replace knowledge and expertise
- Hallucination is a serious problem: Even the best models confidently lie
- Foundational knowledge is critical: Without expert knowledge, AI misleads you rather than helps
- Marketing claims are false: "One prompt, one website" is pure illusion
- Gemini is best for research: Thanks to web connection and deep search
- Claude is stronger for code: But still needs review and testing
Remember: AI is an amazing assistant, but only in the hands of someone who knows what they're doing. If you don't have knowledge yourself, AI can't help you - it will just lead you faster toward mistakes!
🌐 Stay Connected With Us
For the latest tech, gaming, and gadget news, follow us on social media:
📚 Sources & References
Claude 4.6 Official Documentation, Gemini Deep Research Technical Papers, ChatGPT-4 Performance Benchmarks, Personal Testing & Analysis (2000+ hours), AI Hallucination Research Studies 2025-2026, Stack Overflow Developer Survey 2026, GitHub AI Usage Statistics, MIT Technology Review AI Reports, Independent Security Audits
Dissecting the AI Illusion 2026 — Research and Analysis: Tekin Editorial Team
🌐 Stay Connected With Us 🎮✨
For the latest tech, gaming, and gadget news, follow us on our official social media channels: