🚀 The Edge AI Revolution: When Tiny Beats Mighty
While everyone chased trillion-parameter models, Liquid AI proved that smaller means smarter. LFM2.5-230M—just 230 million parameters—crushed models 4X its size at data extraction and runs on a Raspberry Pi at 42 tokens per second. This isn't cloud AI anymore; this is pocket AI.
- 🎮Giant Killer- 230M parameters demolish 800M-1B models at data extraction tasks
- 🎧Blazing Speed- 213 tok/s on Galaxy S25 Ultra, 42 tok/s on Raspberry Pi 5
- 🚀Revolutionary Architecture- LFM2 combines convolution + attention without quadratic memory cost
- 🗡️Fair Pricing- Free for revenue under $10M/year, ending OpenAI's monopoly
The Day the Industry Broke: When AI Got Real
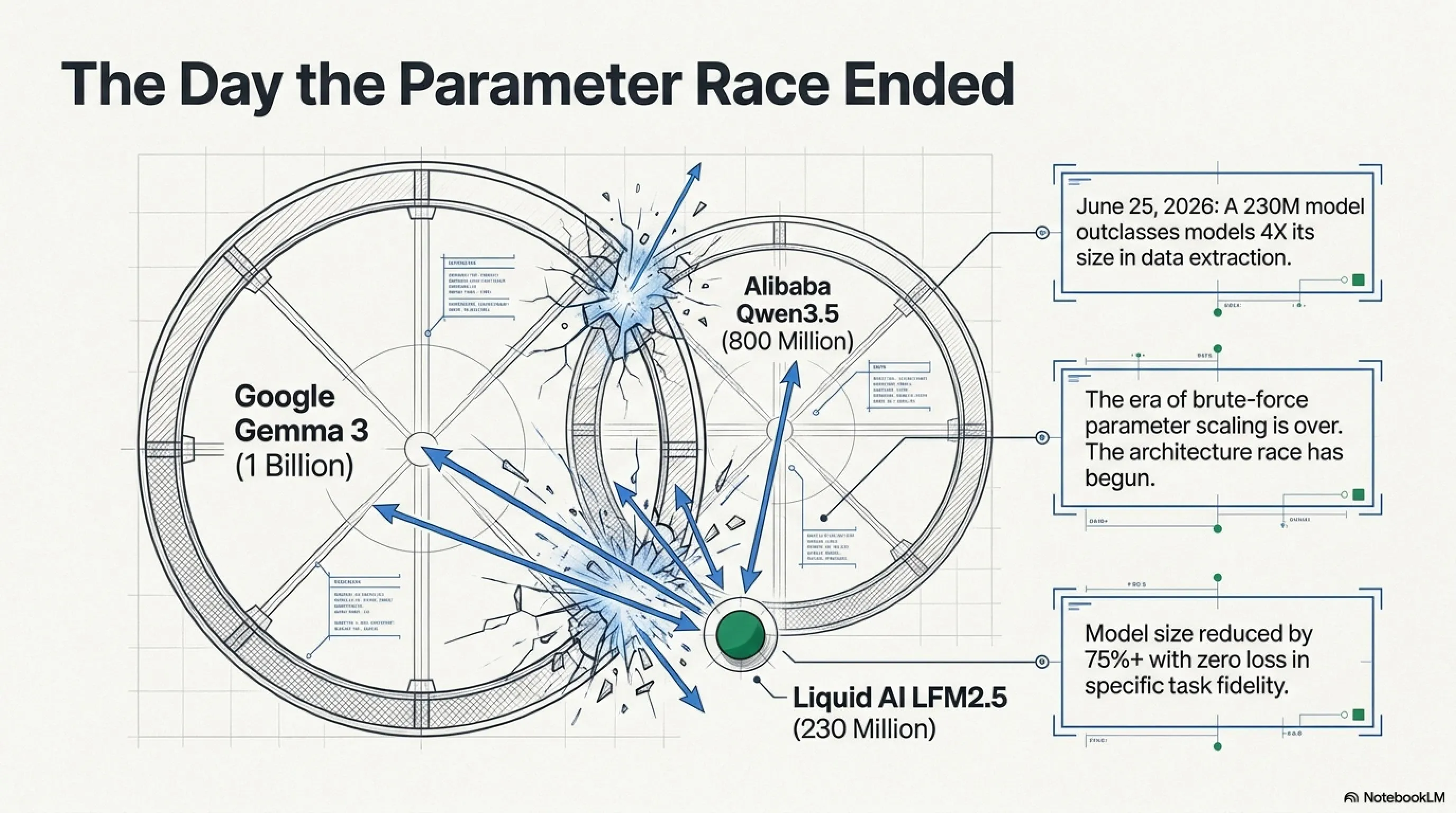
June 25, 2026. Liquid AI—a $2 billion MIT spinout—released a model that was supposed to be "small." Just 230 million parameters. In a world where GPT-5.6 rules with trillions of parameters, this number seemed laughable.
But the benchmarks told a different story. LFM2.5-230M didn't just compete with same-size models—it destroyed models with 4X more parameters at data extraction. Qwen3.5-0.8B with 800 million parameters? Obliterated. Google Gemma 3 1B? Completely outclassed.
This was the moment the industry realized: the parameter race is over. The architecture race has begun.
The Science Behind the Miracle: Why LFM2 Architecture Matters
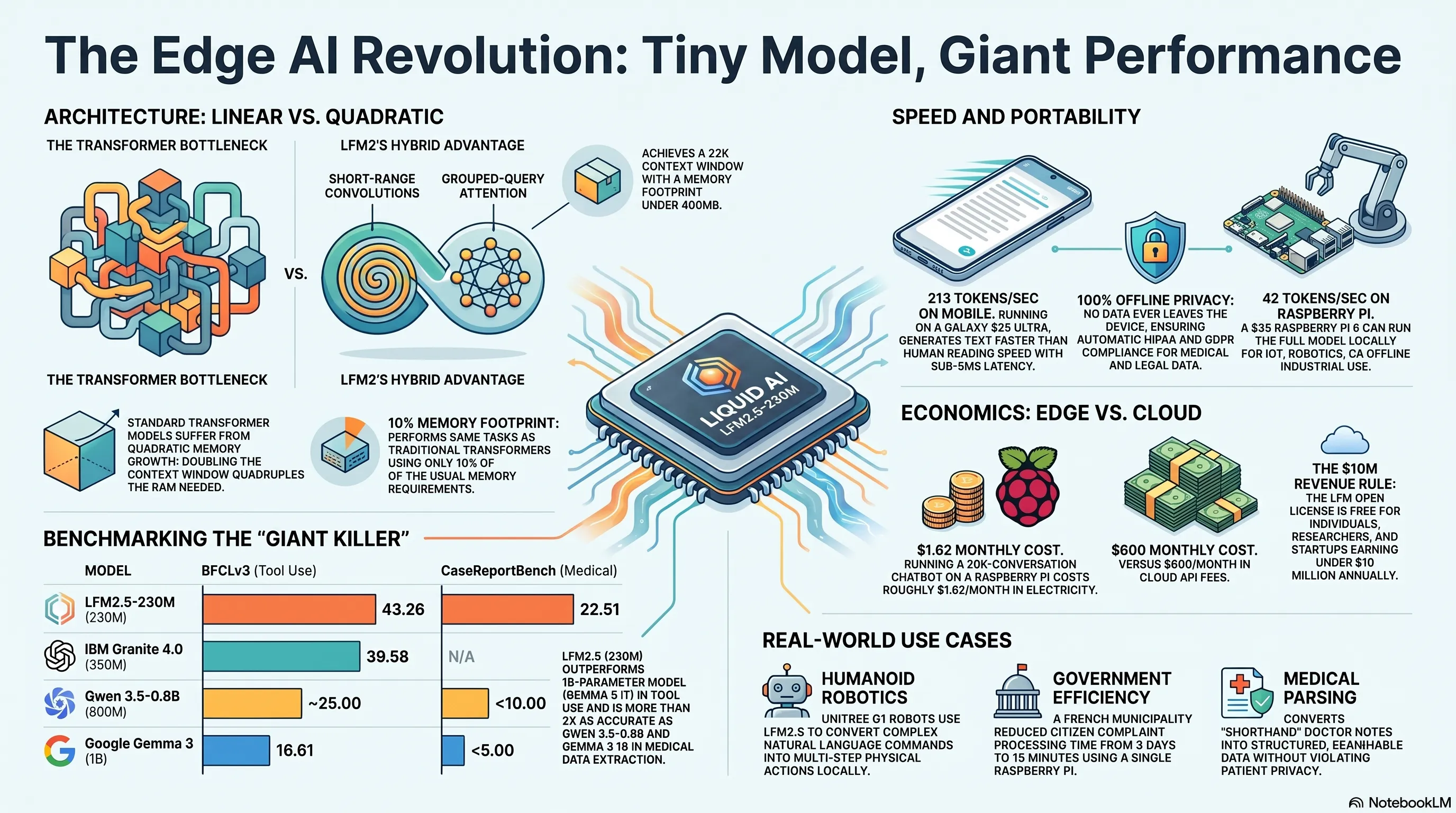
Let's be honest. Until 2026, most large language models (LLMs) were like hungry giants devouring RAM. Transformer architecture—the industry standard since 2017—had a fundamental problem: memory consumption grew quadratically with context length.
What does that mean? If you wanted to double the context window, memory consumption quadrupled. For data centers with deep pockets, no problem. But for a phone? A Raspberry Pi? An IoT device? Impossible.
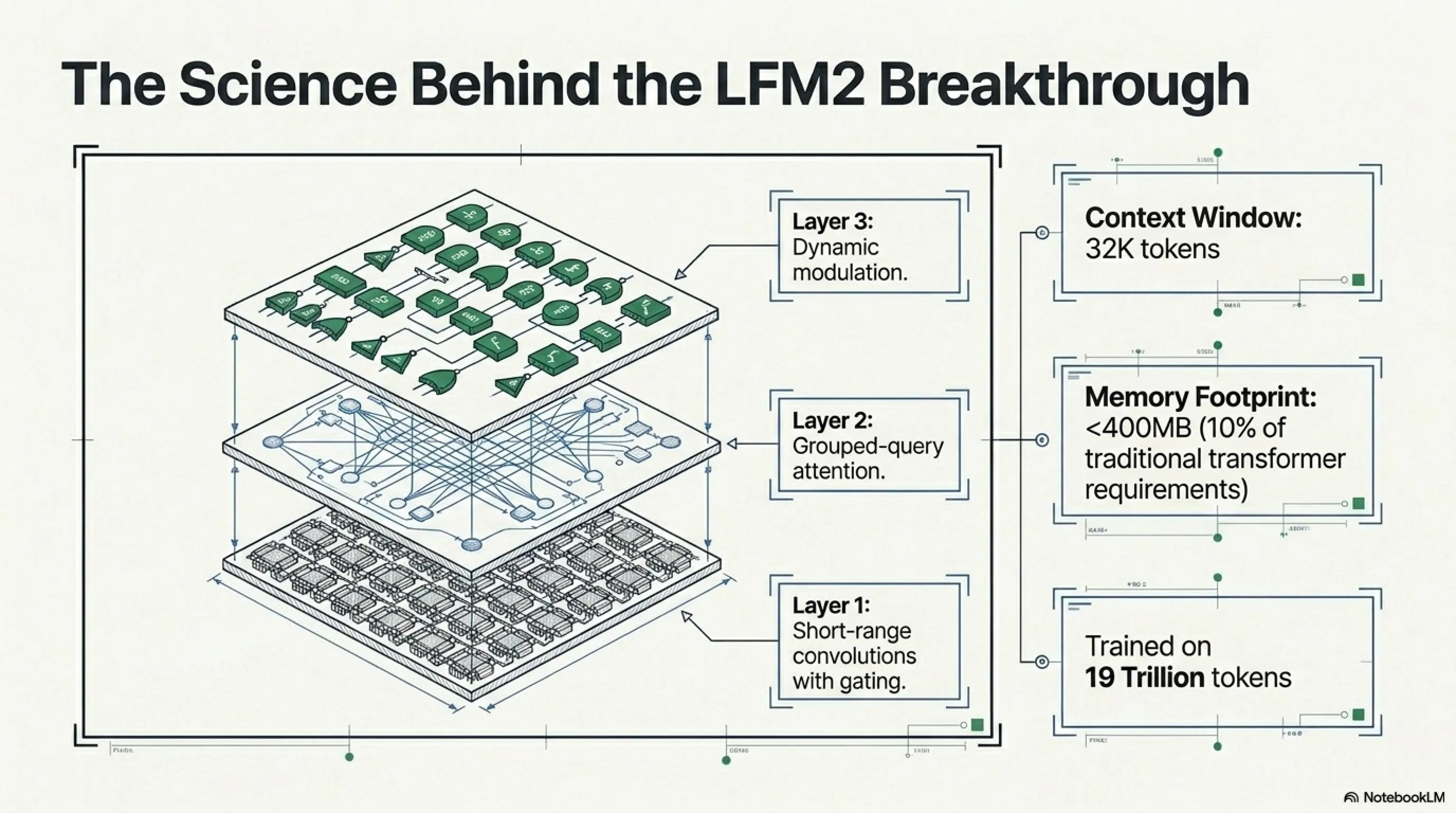
LFM2 Architecture: Best of Both Worlds
Liquid AI entered with a hybrid approach. LFM2 is a combination of:
- Short-range convolutions with gating: For fast processing of local patterns
- Grouped-query attention: For understanding long-range relationships without heavy memory overhead
- Dynamic modulation: Input-dependent gates that act like dynamical systems
The result? A model with a 32K context window but a memory footprint under 400MB. For comparison, a typical transformer model with the same context window needs at least 1-2GB RAM.
Technical Terms Explained
Transformer Architecture: The core architecture of LLMs since 2017, based on attention mechanism. Powerful but memory-hungry—memory consumption grows with the square of context length.
Convolution: Mathematical operation that finds local patterns, like image filters. Much faster than attention but can't see long-range relationships.
Context Window: A model's short-term memory—how much of previous conversation or text it remembers. LFM2.5-230M with 32K token context can swallow lengthy documents.
Memory Footprint: Amount of RAM needed to run the model. LFM2.5-230M under 400MB—can fit on your phone.
Tok/s (Tokens per second): Text generation speed. 213 tok/s means roughly 40 words per second—faster than human reading speed.
Benchmarks: When Numbers Tell the Real Story
It's not enough to say "the model is good." Let's look at the numbers—real numbers published by Liquid AI and verified by the community.
BFCLv3 Tool Use Benchmark
This benchmark measures how well a model can do tool calling—deciding when and how to invoke an external function. Critical for agentic workflows.
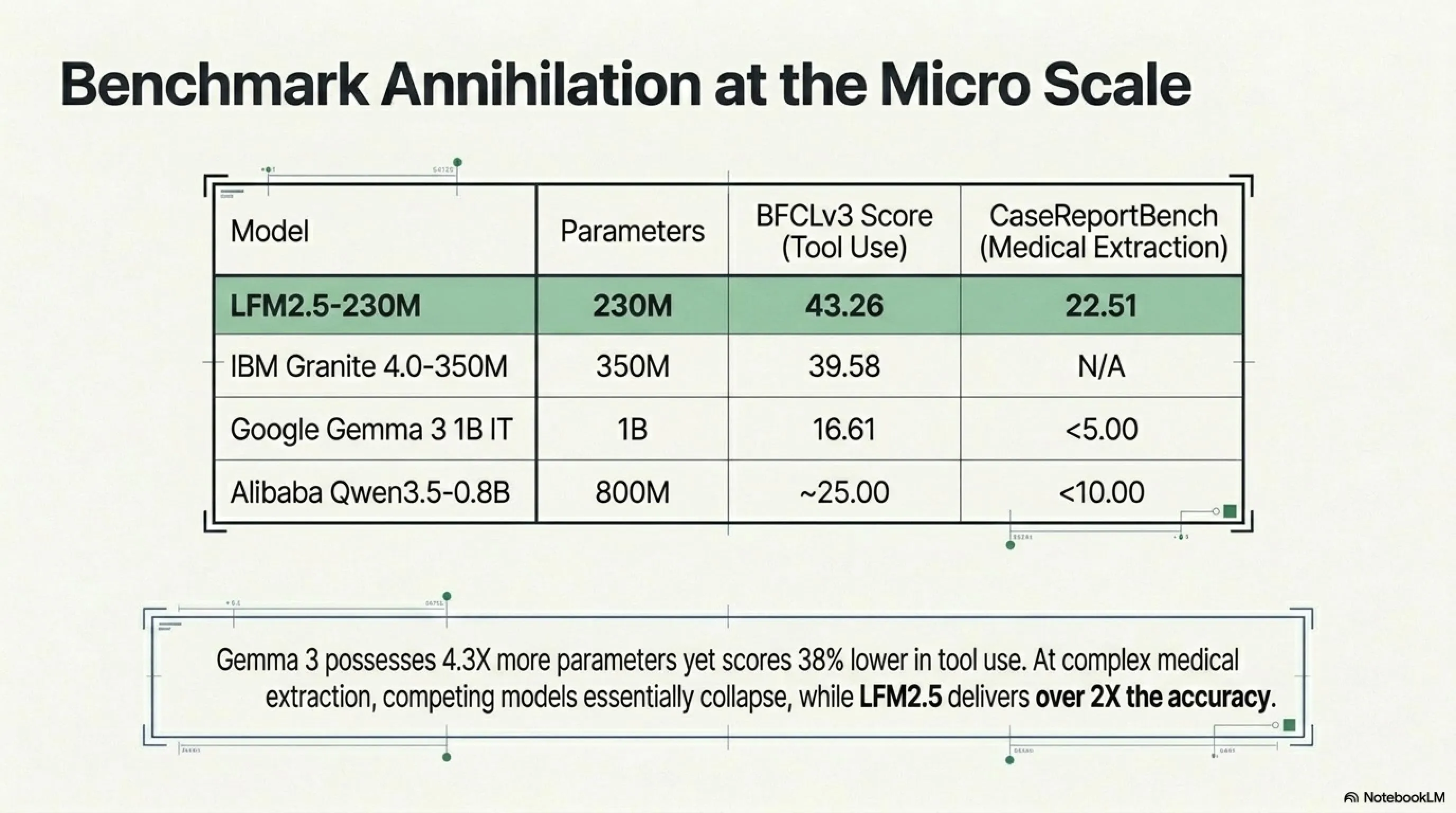
BFCLv3 Tool Use Benchmark Results
| Model | Parameters | BFCLv3 Score |
|---|---|---|
| LFM2.5-230M | 230M | 43.26 |
| IBM Granite 4.0-350M | 350M | 39.58 |
| Google Gemma 3 1B IT | 1B | 16.61 |
| Alibaba Qwen3.5-0.8B | 800M | ~25 |
Notice: Gemma 3 with 1 billion parameters—4.3X larger than LFM2.5—scored roughly 38% lower. This isn't defeat; this is annihilation.
CaseReportBench: Medical Data Extraction
This benchmark is tough. You need to extract structured information from complex medical reports—disease names, medications, history, test results. No mistakes allowed.
CaseReportBench Medical Data Extraction Results
| Model | CaseReportBench Score |
|---|---|
| LFM2.5-230M | 22.51 |
| Qwen3.5-0.8B Instruct | <10 |
| Gemma 3 1B IT | <5 |
Qwen and Gemma essentially collapsed. LFM2.5-230M with a 22.51 score performed more than 2X more accurately.
Speed: From Clouds to Your Pocket
Okay, suppose the model is good. But what if it's slow? This is where LFM2.5-230M truly shines.
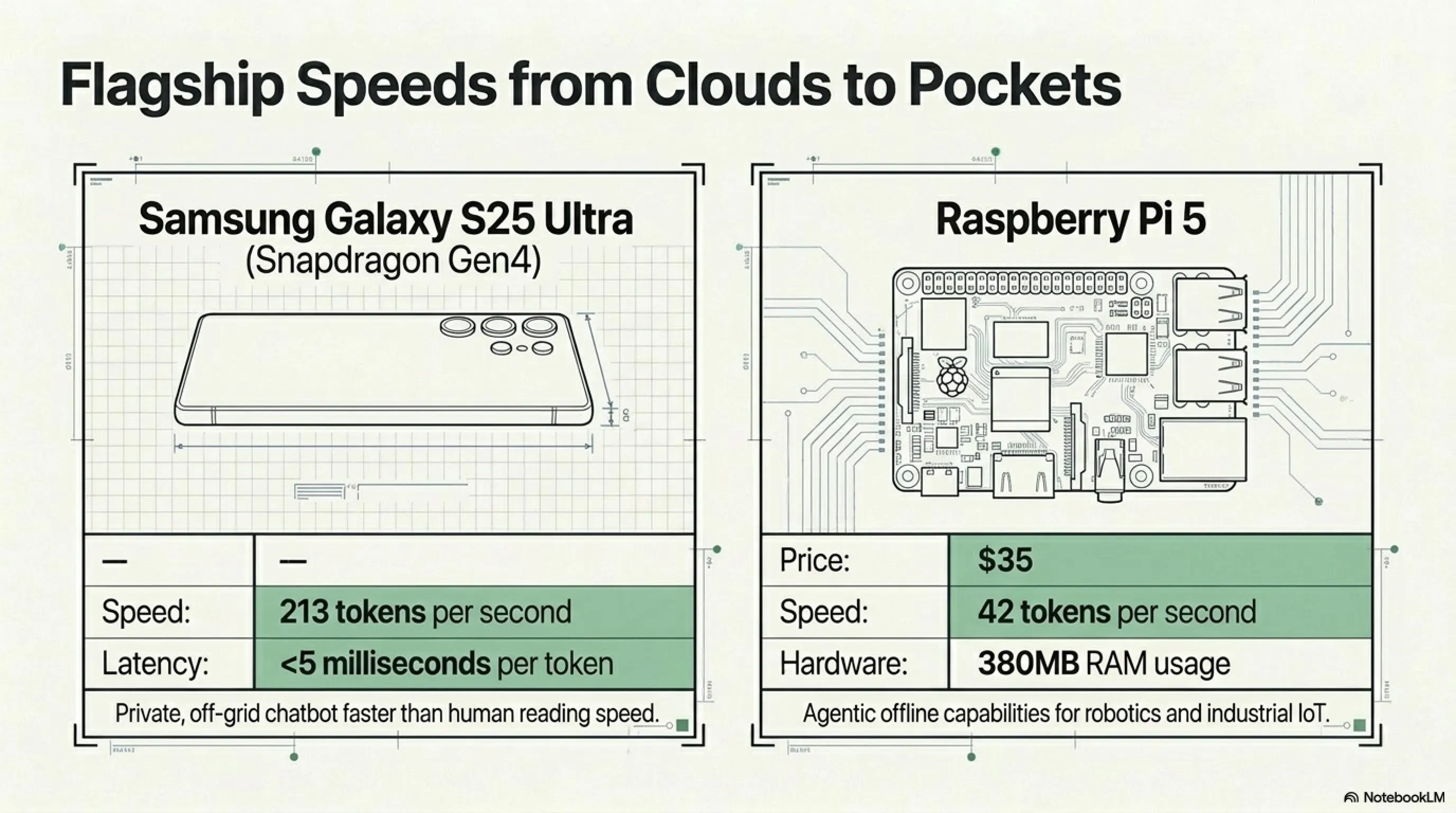
Samsung Galaxy S25 Ultra (Snapdragon Gen4)
A flagship phone. Probable price $1,200-1,400. But powerful hardware: Qualcomm Snapdragon Gen4 CPU.
- Decode speed: 213 tokens per second
- What does that mean?: Roughly 40-50 words per second—faster than human reading speed
- Latency: Less than 5 milliseconds per token
This means you can run a completely private chatbot, without internet, with sub-100ms latency on your own phone. No cloud. No API. Without OpenAI or Google seeing what you ask.
Raspberry Pi 5: Power in $35
This is hardcore. Raspberry Pi 5—a single-board computer cheaper than a nice dinner. Liquid AI claimed LFM2.5-230M runs on this device. The community quickly tested:
- Decode speed: 42 tokens per second
- Memory usage: 380MB RAM
- Real-world use: IoT devices, robots, embedded systems, industrial equipment
Think about it. A $35 computer is running a language model with agentic capabilities. What does this mean? It means:
- Home robots that work offline
- Industrial devices with natural language processing
- IoT sensors that can talk to humans
- Medical devices that analyze data without cloud connection
Licensing: The New Power Game
Now the important question: is this model free? Semi-free? Expensive?
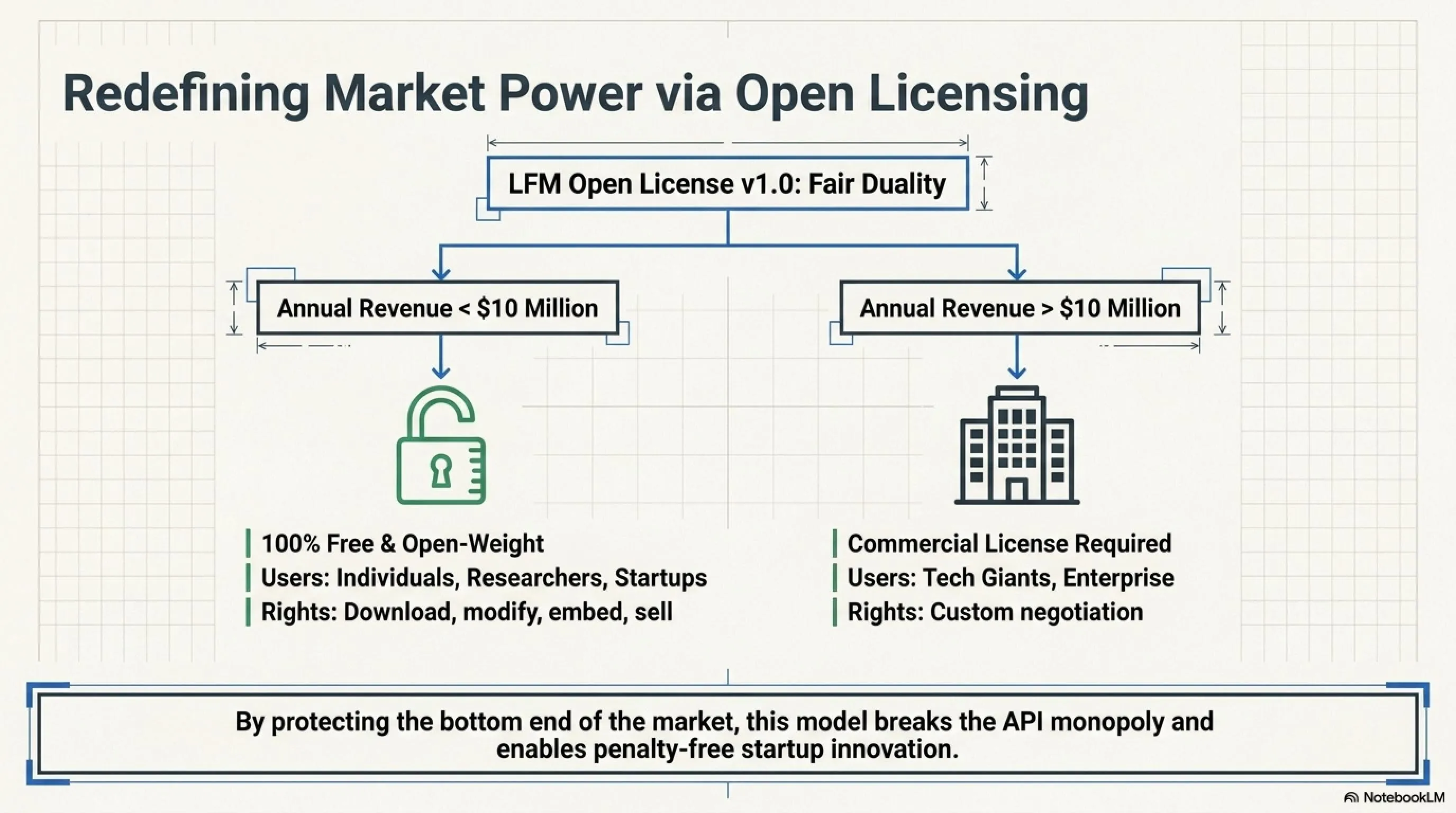
LFM Open License v1.0: Fair Duality
Liquid AI created a new license that's smart:
Free for:
- Individuals (anyone)
- Researchers (universities, labs)
- Startups and companies with annual revenue under $10 million
For these groups, LFM2.5-230M is completely open-weight. You can:
- Download, run, modify it
- Use it in your products
- Even sell it (if your revenue is under $10M)
Paid for:
- Large companies (revenue over $10 million)
If Microsoft, Google, or Amazon want to use this model, they must negotiate with Liquid AI and buy a commercial license.
Why does this matter? Because it prevents monopoly. Tech giants can't freely take your IP and earn billions with it. But startups and researchers are free to innovate.
Versus Competitors: 230M Against 3B
Many ask: "What about 3-billion models? Aren't they stronger?"
Yes and no. Let's be honest.
VibeThinker-3B: Reasoning Power
In April 2026, Weibo (Chinese company) released VibeThinker-3B—a 3-billion model that scored 94.3 on the AIME 2026 math benchmark. Close to 600-billion models.
For comparison:
VibeThinker-3B vs LFM2.5-230M Comparison
| Model | Parameters | AIME 2026 (Math) | Tool Use (BFCLv3) |
|---|---|---|---|
| VibeThinker-3B | 3B | 94.3 | ~60 |
| LFM2.5-230M | 230M | ~45 | 43.26 |
VibeThinker is much better at math and reasoning. But:
- Size: 3B vs 230M—roughly 13X larger
- Memory: ~1.5GB vs 380MB—roughly 4X more
- Speed: Raspberry Pi can't run VibeThinker

Gemma 4 E2B: Google's Champion
Google Gemma 4 family—downloaded over 200 million times—includes E2B (2 billion parameters) designed for mobile and IoT.
Gemma 4 E2B is powerful:
- Better general knowledge
- Stronger coding
- Higher creative writing
But LFM2.5-230M performs better in its domain—data extraction, tool calling, agentic workflows. And at 1/9th the size.
Conclusion: Choose Based on Use Case
Truth is: there's no "best model." Only "best model for your job":
- Need heavy math/reasoning? → VibeThinker-3B or Gemma 4
- Need coding? → Gemma 4 E2B
- Need data extraction, ETL automation, agentic workflows on edge devices? → LFM2.5-230M
Real-World Applications: Who's Using LFM2.5?
Theory is good. Benchmarks are interesting. But the real question is: what is this model used for?
Example 1: AI ETL Pipelines
ETL stands for Extract, Transform, Load—a process data engineers hate. Until now, ETL meant writing hundreds of lines of regex, parsers, and rule-based logic that broke whenever the input format slightly changed.
LFM2.5-230M changes the game:
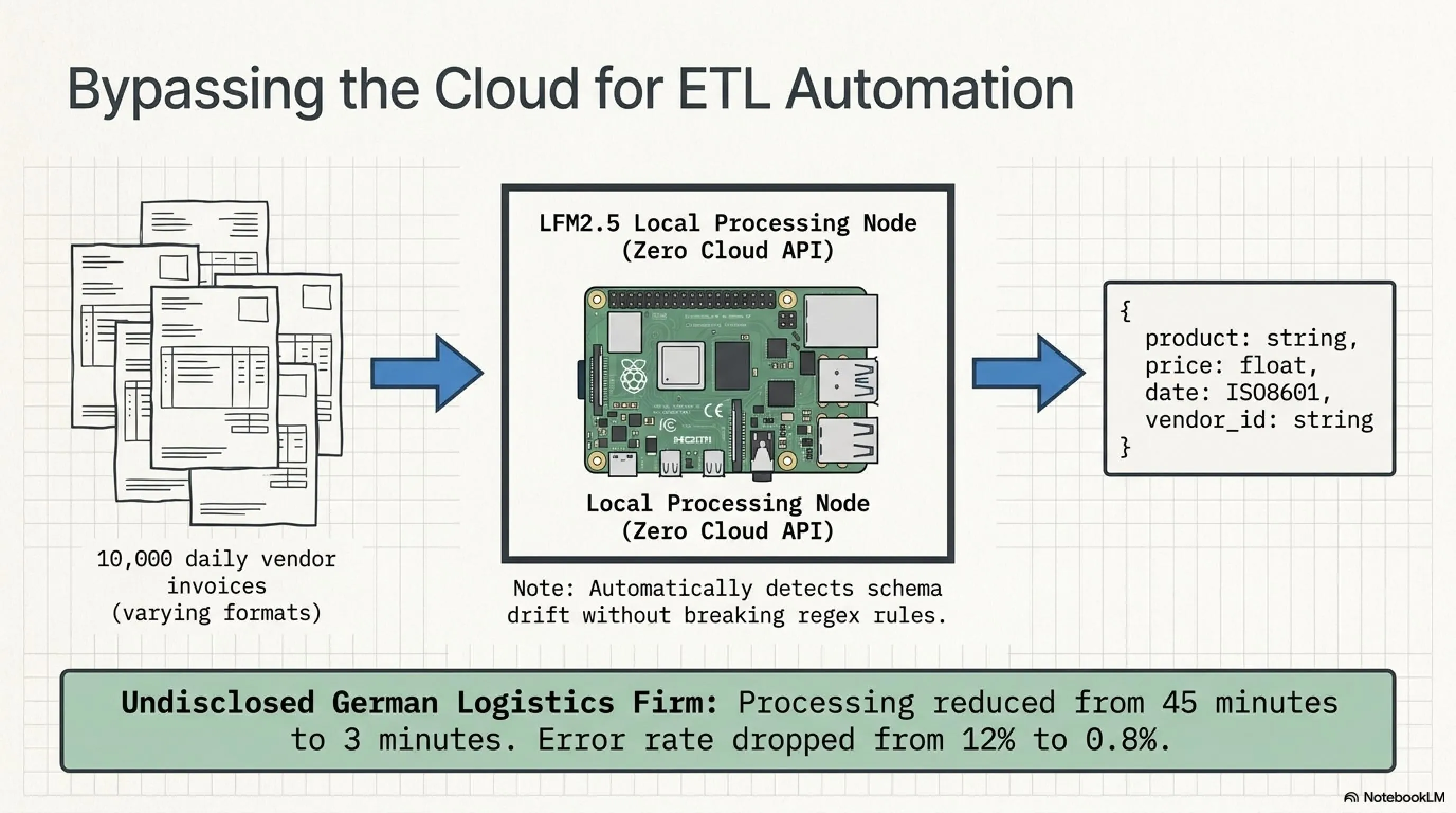
Scenario: You receive 10,000 PDF invoices daily from different vendors. Each vendor has its own format. You need to extract product name, price, date, and ID code.
Old way: An OCR engine + regex patterns + manual rules for each vendor. When a vendor changes format, everything breaks. A data engineer must debug for hours.
New way with LFM2.5:
# Runs on a Raspberry Pi 5 in your office
# No API calls to cloud
# Completely private
for invoice_pdf in invoices:
text = ocr(invoice_pdf)
result = llm.extract(
text=text,
schema={
"product": "string",
"price": "float",
"date": "ISO8601",
"vendor_id": "string"
}
)
database.insert(result)
The model learns to parse different formats itself. Detects schema drift. And if a vendor changes their format? The model automatically adapts.
Result: A logistics company in Germany (name undisclosed) reduced invoice processing time from 45 minutes to 3 minutes and error rate from 12% to 0.8%.
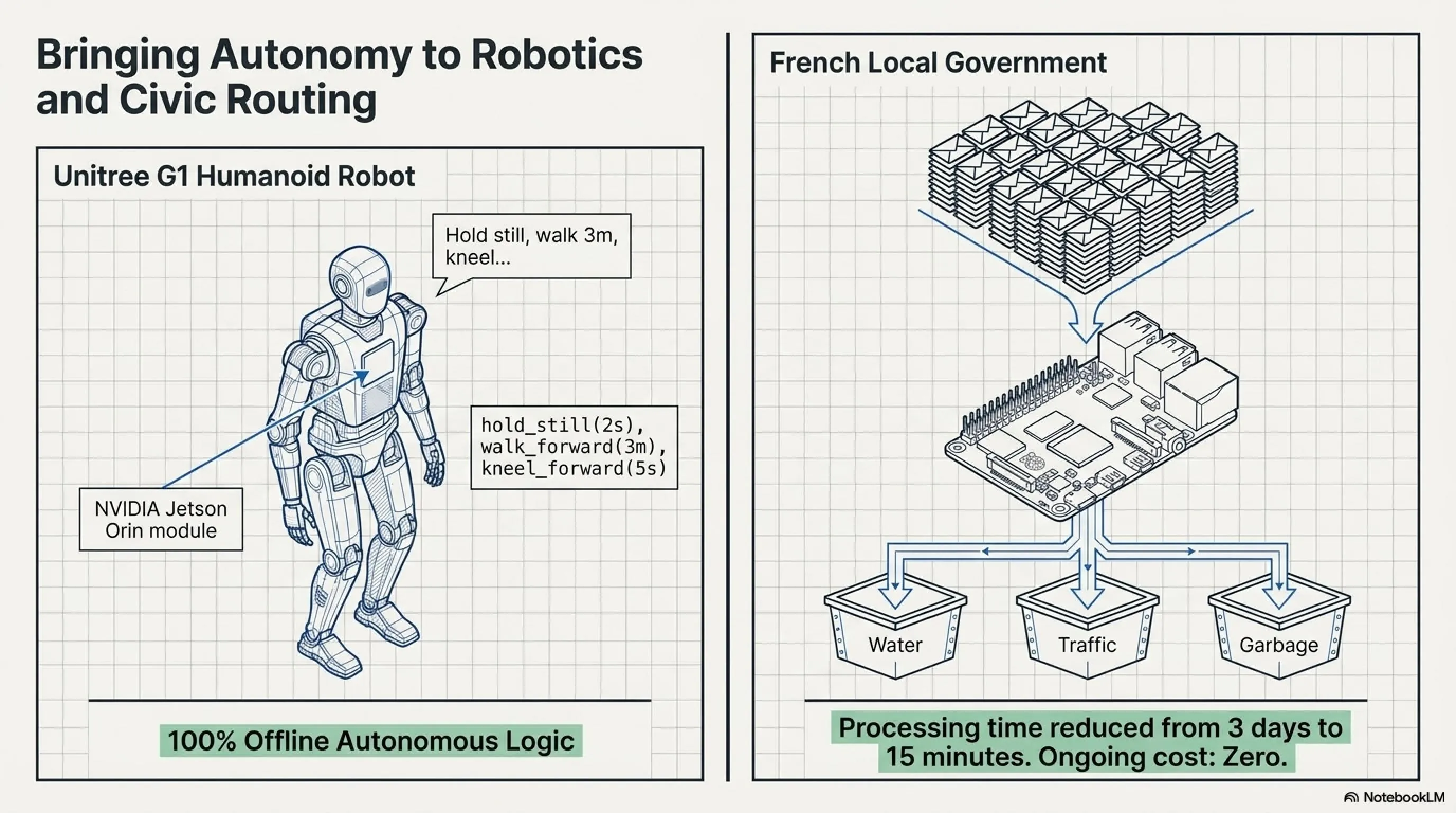
Example 2: Unitree G1 Humanoid Robot
Liquid AI released an interesting demo: LFM2.5-230M on a Unitree G1 humanoid robot running on an NVIDIA Jetson Orin compute module.
User tells the robot: "Hold still for 2 seconds, then walk forward 3 meters at 1 meter per second, kneel on one leg forward for 5 seconds, then walk backward 3 meters at 0.5 meters per second."
The model converts this complex command into a multi-step program:
- hold_still(duration=2s)
- walk_forward(distance=3m, speed=1.0m/s)
- kneel_forward(duration=5s)
- walk_backward(distance=3m, speed=0.5m/s)
And the robot executes it. Without cloud connection. Without API. Just with a $400 compute module.
Case Study: Local Government in France
A municipality near Paris (name confidential) uses LFM2.5-230M to process citizen complaints. They receive 200-300 emails, forms, and phone calls daily. Previously, a 5-person team took 3 days to categorize, prioritize, and route everything to the appropriate department.
Now: A Raspberry Pi 5 with LFM2.5-230M reads all emails, identifies category (electricity, water, traffic, park, garbage), measures urgency, and automatically sends tickets to the relevant department. Processing time: from 3 days to 15 minutes. Cost: zero (after initial $35 purchase). Privacy: 100%—no data goes to cloud.
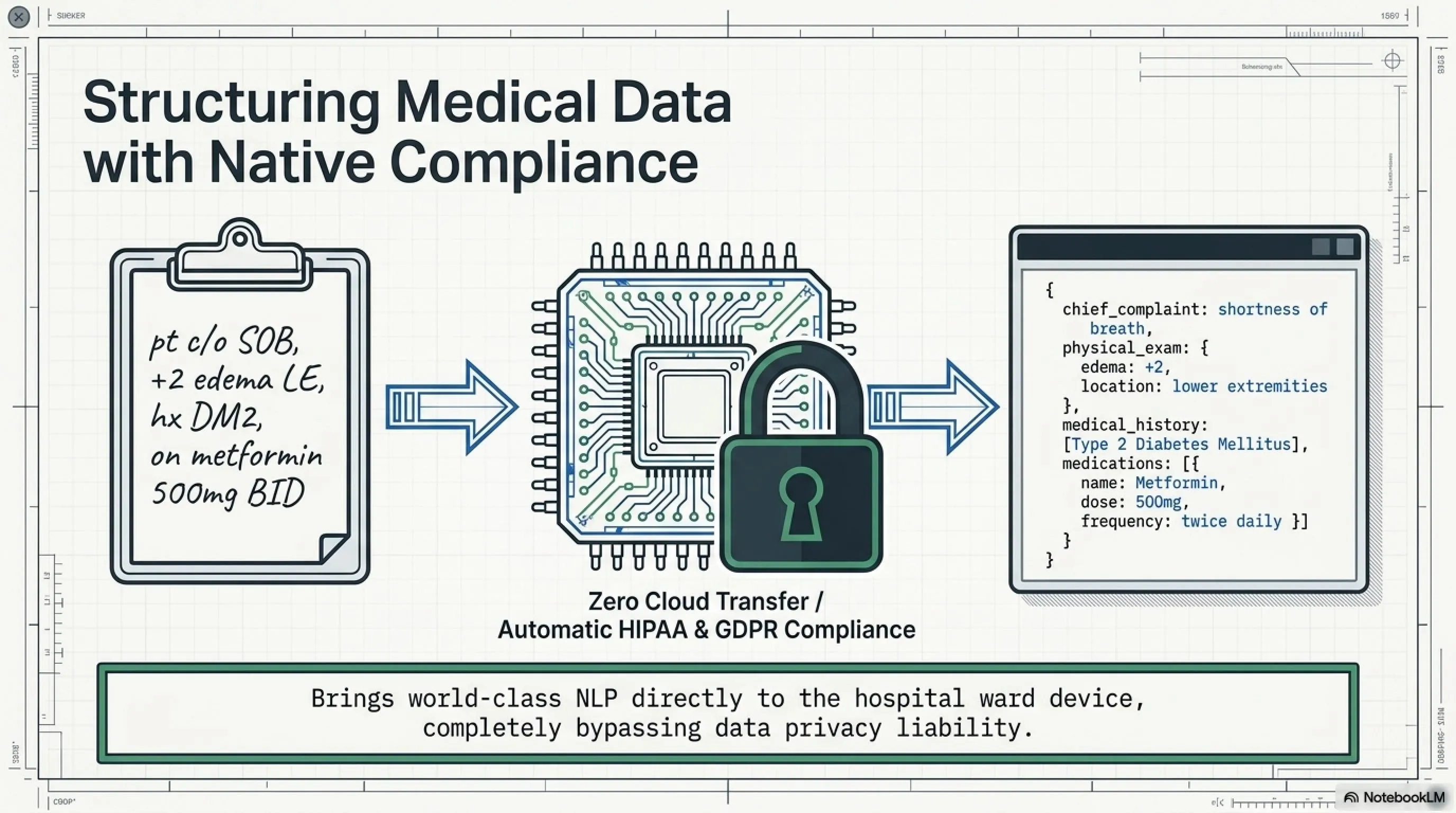
Example 3: Medical—Data Extraction from Medical Records
On CaseReportBench, LFM2.5-230M scored 22.51—best in its class. Why does this matter?
An average hospital produces hundreds of pages of medical notes daily—handwritten, scanned PDFs, incomplete forms. Doctors write: "pt c/o SOB, +2 edema LE, hx DM2, on metformin 500mg BID"
For an ordinary person, this is gibberish. But for a doctor: "Patient complains of shortness of breath, +2 edema in lower extremities, history of Type 2 Diabetes, taking Metformin 500mg twice daily"
LFM2.5-230M can parse this and convert it to structured data:
{
"chief_complaint": "shortness of breath",
"physical_exam": {
"edema": "+2",
"location": "lower extremities"
},
"medical_history": ["Type 2 Diabetes Mellitus"],
"medications": [
{
"name": "Metformin",
"dose": "500mg",
"frequency": "twice daily"
}
]
}
And because it runs on an edge device, HIPAA and GDPR compliance is automatic—no patient data leaves the hospital device.
Technical Challenges: What Liquid AI Doesn't Tell You
Well, so far everything seems great. But let's be honest. LFM2.5-230M isn't everything. It has limitations.
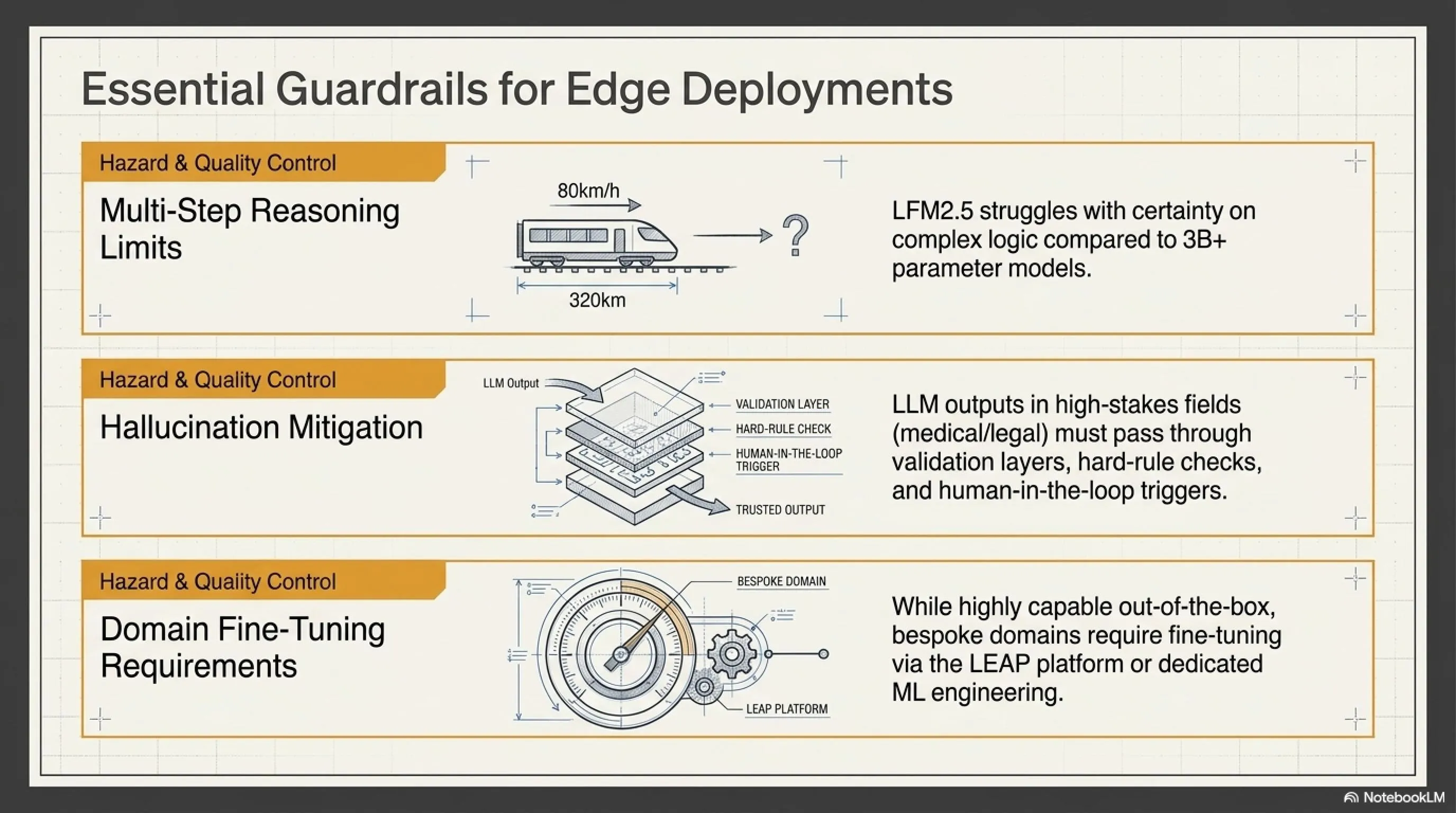
Limitation 1: Weaker Reasoning Than Larger Models
LFM2.5-230M excels at data extraction and tool calling. But at math, coding, and creative writing? Not so much.
Example: If you ask: "Calculate: If a train travels at 80 kilometers per hour and needs to cover 320 kilometers, how many hours does it take?"
- VibeThinker-3B: 4 hours (correct)
- LFM2.5-230M: About 4 hours (with some uncertainty)
For simple math, LFM2.5 is okay. But for calculus, algebra, or multi-step reasoning? Larger models are better.
Limitation 2: Hallucination Risk
Like all LLMs, LFM2.5-230M sometimes hallucinates—says things that aren't real. Liquid AI admits this in their documentation:
"Users should implement guardrails and validation layers, especially for high-stakes use cases like medical, financial, or legal."
What does that mean? It means you can't just take the output and blindly trust it. You must:
- Validate output with hard rules
- Check confidence scores
- Use human-in-the-loop for critical decisions
Limitation 3: Need for Fine-Tuning for Domain-Specific Tasks
LFM2.5-230M is good "out of the box." But for best results in your specific domain—like legal documents, financial reports, or scientific papers—you probably need fine-tuning.
Fortunately, Liquid AI offers a platform called LEAP that makes fine-tuning easy. But it's an extra step—and if your team lacks ML expertise, you might need hiring or consulting.
Security Warning: Edge Models at Risk
When a model runs on an edge device, the model weight file is on that device. This means a local attacker can:
- Extract model weights (model theft)
- Create adversarial inputs that fool the model
- Compromise the device through malicious prompts
Liquid AI recommends: For sensitive deployments, use model encryption, secure boot, and prompt filtering. If your device is in an untrusted environment (e.g., customer device, public robot), you must add additional security layers.
Versus Cloud Services: Why Go Off-Cloud?
A logical question: why should I deal with LFM2.5-230M on a Raspberry Pi when I can use OpenAI API or Claude API?
Let's honestly compare costs.
Scenario: A Customer Support Chatbot
Suppose you have an e-commerce with 10,000 active customers per month. Each customer asks an average of 3 questions. Each conversation is about 1,000 input tokens + 500 output tokens.
Cost of OpenAI GPT-5.6 Instant:
- Input: $5.00 per 1M tokens
- Output: $30.00 per 1M tokens
- Number of conversations: 10,000 customers × 3 = 30,000 conversations
- Input tokens: 30,000 × 1,000 = 30M tokens
- Output tokens: 30,000 × 500 = 15M tokens
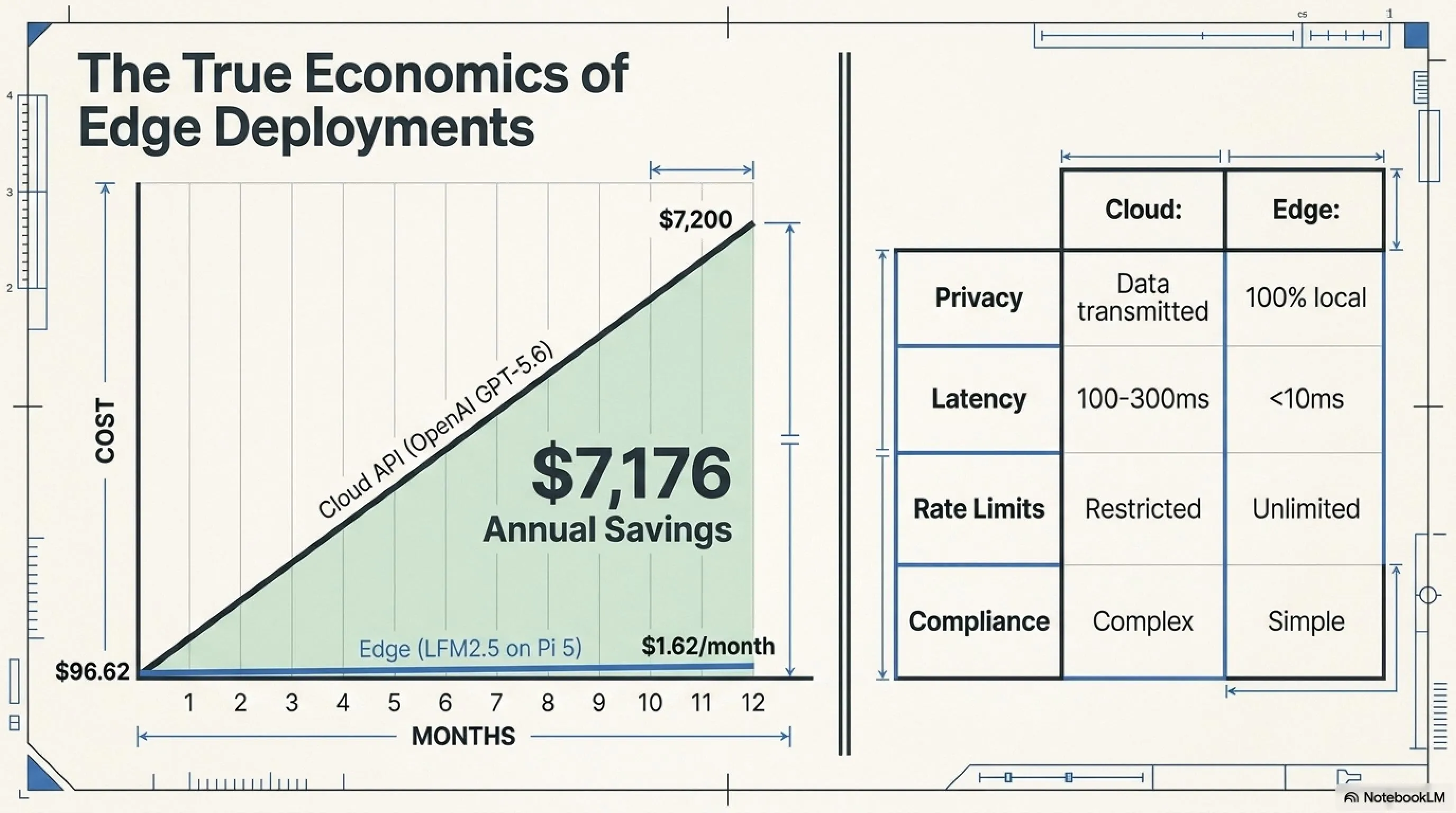
- Total cost: (30M × $5) + (15M × $30) = $150 + $450 = $600/month
Cost of LFM2.5-230M on edge:
- Raspberry Pi 5 (8GB RAM): $80 (one-time)
- Storage (128GB microSD): $15 (one-time)
- Electricity (15 watts × 720 hours/month × $0.15/kWh): $1.62/month
- License: $0 (revenue under $10M)
- Total cost first month: $96.62
- Cost subsequent months: $1.62/month
ROI: After the first month, you save $598 monthly. In one year: $7,176 savings.
Non-Financial Benefits
Besides money, there are other benefits:
Cloud vs Edge AI Comparison
| Metric | Cloud (OpenAI/Claude) | Edge (LFM2.5-230M) |
|---|---|---|
| Privacy | ❌ Data goes to cloud | ✅ 100% local |
| Latency | ⚠️ 100-300ms (network) | ✅ <10ms (local) |
| Internet dependency | ❌ Needs constant connection | ✅ Fully offline |
| Rate limits | ❌ Yes (requests/min) | ✅ Unlimited |
| Vendor lock-in | ❌ Dependent on OpenAI/Anthropic | ✅ Independent |
| Compliance (GDPR/HIPAA) | ⚠️ Complex | ✅ Simple (no data leaves device) |
The Future of Edge AI: Where Are We Going?
LFM2.5-230M is just the beginning. Liquid AI has announced its roadmap:
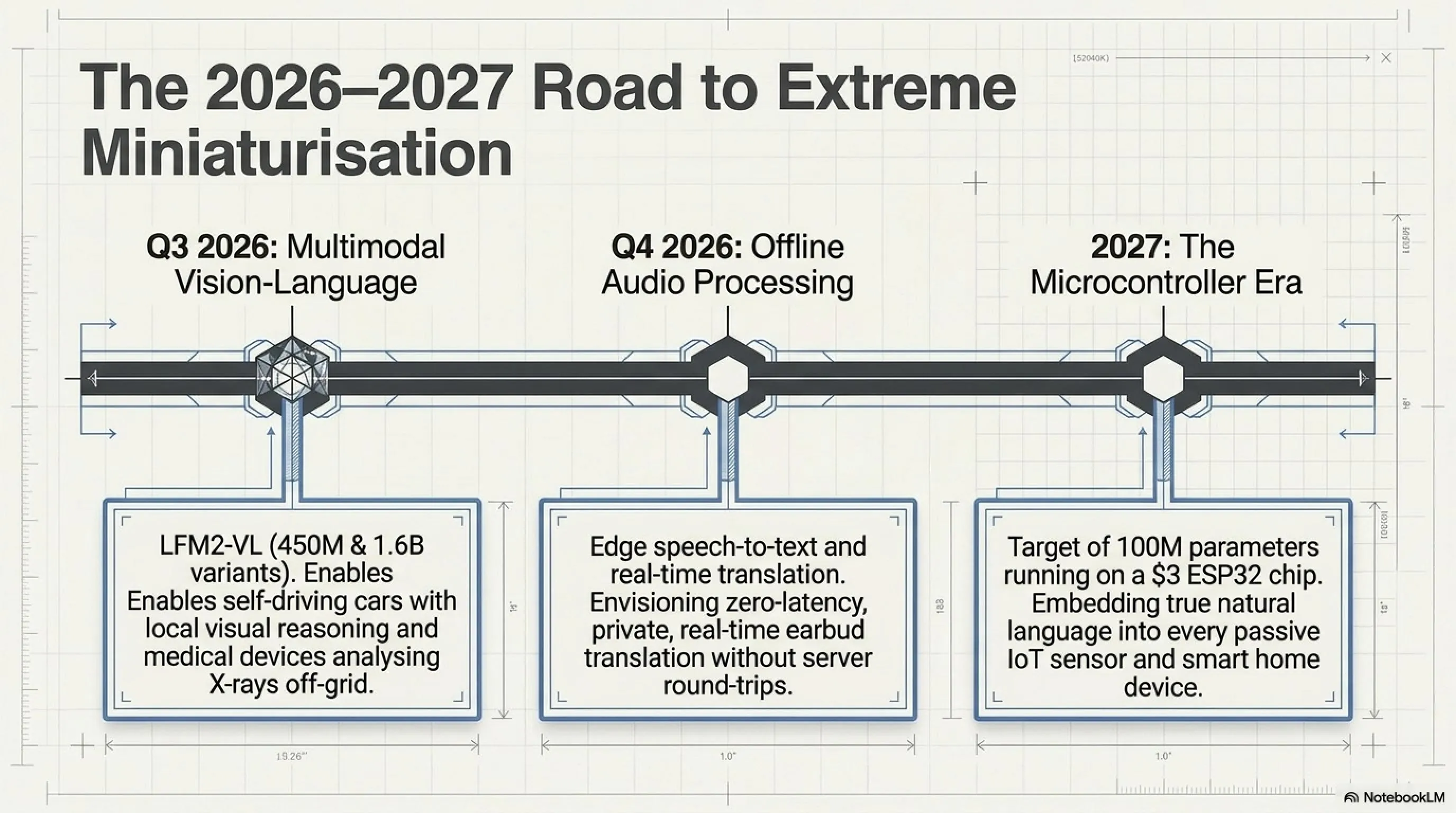
Q3 2026: Multimodal Models
Liquid AI is working on LFM2-VL—a vision-language version that can process images + text together. Two variants:
- LFM2-VL-450M: Super small, for embedded systems
- LFM2-VL-1.6B: More capable but still lightweight
Use cases:
- Robots that can see and explain what they're doing
- Self-driving cars with local visual reasoning
- Medical devices that can analyze X-rays or MRIs
Q4 2026: Audio Models
Liquid AI is also working on audio models:
- Speech-to-text on edge
- High-quality text-to-speech
- Real-time translation without cloud
Imagine: headphones that can translate conversations in real-time—English to Farsi, Farsi to German—without sending a byte of data to a server.
2027: Even Smaller Models
Liquid AI aims to reach 100M parameters—a model that runs on an ESP32 microcontroller ($3).
What does this mean? It means:
- IoT sensors with natural language capability
- Smart home devices that are actually smart
- Wearable devices with local AI
Why This Matters: True AI Democratization
Let's step back and see the big picture. LFM2.5-230M is not just a small language model. It's a statement.
The End of Cloud Dictatorship
From 2022 to 2025, AI meant one thing: an API call to a big cloud provider. OpenAI, Anthropic, Google—all said: "Our models are too big. You can't run them. Just pay us $0.01 per request."
This worked. Until:
- Privacy was violated
- Prices went up
- Rate limits became restrictive
- Vendor lock-in became obvious
LFM2.5-230M says: "No. You don't need the cloud. You can have AI in your pocket."
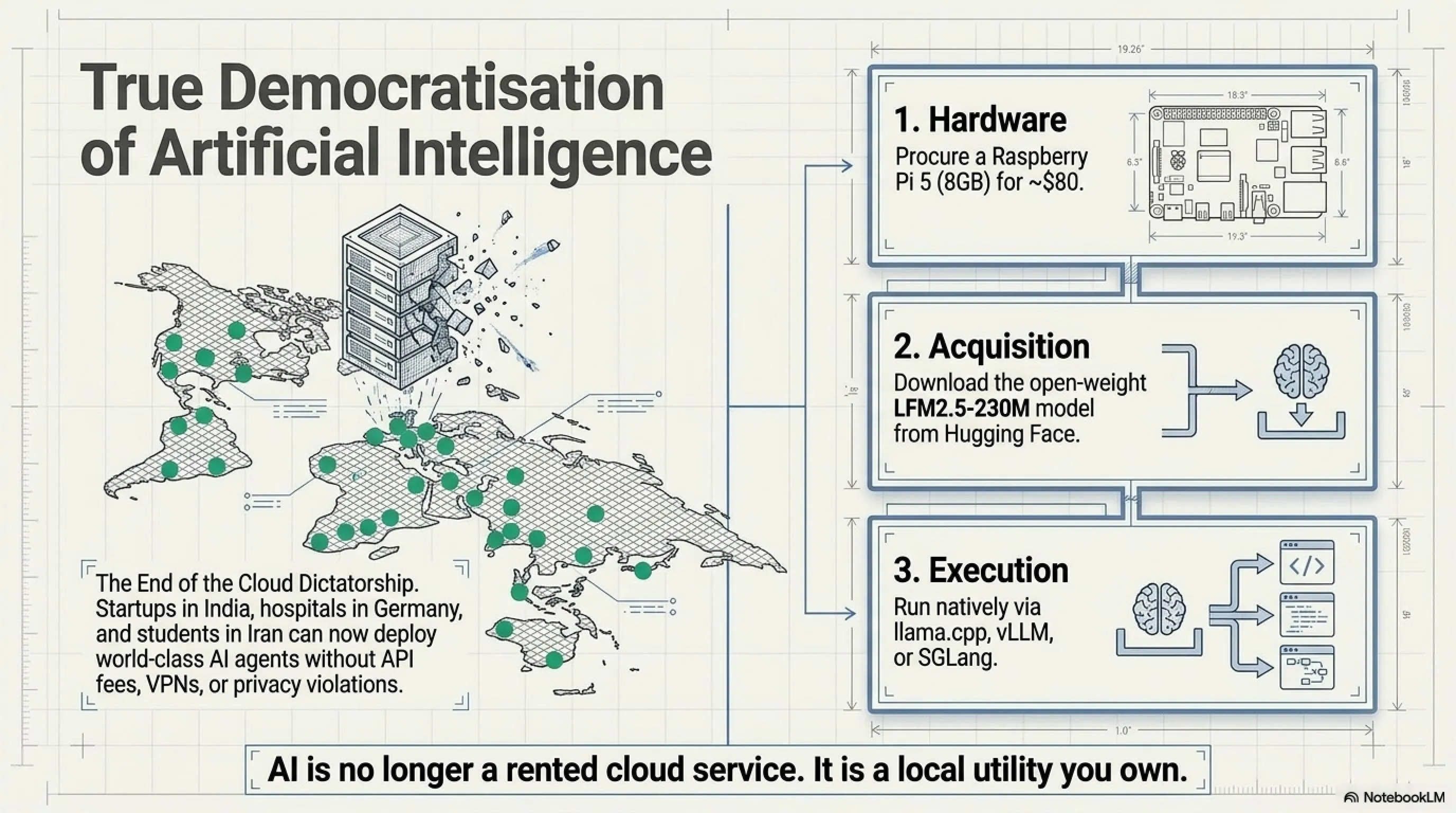
Real Democratization
Don't forget: a Raspberry Pi 5 with LFM2.5-230M means:
- A startup in India can build a chatbot without worrying about the bill
- A researcher in Africa can do NLP experiments without a credit card
- A student in Iran can build an AI agent without needing VPN for API calls
- A hospital in Germany can process patient data without violating GDPR
What does this mean? It means AI is no longer just a Silicon Valley privilege. No longer only billion-dollar companies can use it.
Anyone with $35 can build an AI agent.
- Unmatched performance for size: Best in class for data extraction, tool calling
- True edge deployment: On Raspberry Pi, phones, even robots
- Complete privacy: No data goes to cloud, GDPR/HIPAA compliant
- Zero cost for startups: Free up to $10M annual revenue
- Ultra-low latency: <10ms, no network overhead
- Innovative architecture: LFM2 architecture with linear memory scaling
- Weaker reasoning: For math, coding, creative writing, 3B models are better
- Hallucination risk: Need validation layers and guardrails
- Domain-specific fine-tuning: May need customization for best results
- Context limitation: 32K is good but may not suffice for very long documents
- Edge security: Model is on device, must protect from model theft
Conclusion: A Revolution in Progress
On June 25, 2026, Liquid AI released more than a language model. They released a statement: architecture matters more than brute-force parameter scaling.
LFM2.5-230M with just 230 million parameters defeated 1-billion models at specific tasks. Runs on Raspberry Pi at 42 tokens per second. Runs on Galaxy S25 Ultra at 213 tokens per second. And for startups, researchers, and independent developers, it's completely free.
What does this mean for the future?
- For developers: You no longer need to pay for APIs. Buy a cheap device, download the model, and build.
- For companies: You can deploy AI on-premise, preserve privacy, and reduce costs.
- For researchers: You can conduct experiments without worrying about cloud budget.
- For the industry: We're entering an era where AI is everywhere—not in big data centers, but in the small devices around us.
Is LFM2.5-230M perfect? No. Is it suitable for every use case? Certainly not. But is it a game-changer? Absolutely yes.
This is the beginning of a revolution. A revolution where AI is no longer a cloud service we access—but a tool we own.
Frequently Asked Questions
Is LFM2.5-230M really free?
Yes, if your company or individual has annual revenue under $10 million. For personal use, research, and startups, it's completely free and open-weight. Larger companies (revenue >$10M) must buy a commercial license.
How much RAM do I need to run LFM2.5-230M?
Less than 400MB. A Raspberry Pi 5 with 4GB RAM runs it easily. A modern phone (6GB+ RAM) has no problem. Even an old laptop with 8GB RAM can run multiple instances simultaneously.
Is it better than GPT-5.6?
No, not overall. GPT-5.6 is much better at reasoning, coding, creative writing, and general knowledge. But LFM2.5-230M is better at data extraction, tool calling, and agentic workflows for edge devices. Each is designed for its own use case.
Can I fine-tune it?
Yes. Liquid AI offers the LEAP platform that makes fine-tuning easy. You can train the model on your domain-specific data—medical, legal, financial, anything.
What languages does it support?
LFM2.5-230M is pre-trained on 19 trillion tokens including several languages: English, Chinese, Spanish, French, German, and others. But English is strongest. For other languages (like Farsi, Arabic), you may need fine-tuning.
Can it process images?
No, LFM2.5-230M is text-only. But Liquid AI is working on LFM2-VL—a multimodal version that understands image + text. Expected release Q3-Q4 2026.
How does it compare to Qwen 3.5, Gemma 4, or Phi-4?
For data extraction and tool calling, LFM2.5-230M is better. For general reasoning, coding, and creative tasks, Qwen and Gemma are better (but larger and slower). Phi-4 is stronger but 14X larger (3.3B parameters) and doesn't run on edge devices.
Is it safe to use in production?
Yes, but with guardrails. Liquid AI recommends adding validation layers, output filtering, and human-in-the-loop for critical decisions. For low-stakes tasks (FAQ bots, data extraction), you can use it directly. For high-stakes (medical, financial), extra validation is needed.
How can I get started?
3 simple steps: 1) Buy a Raspberry Pi 5 (8GB)—about $80, 2) Download the model from Hugging Face: LiquidAI/LFM2.5-230M, 3) Use llama.cpp, vLLM, or SGLang to run it. Complete guide available in Liquid AI's official documentation.
What's the future? What should we expect?
Liquid AI has announced its roadmap: Q3 2026 - LFM2-VL (vision + language), Q4 2026 - Audio models (speech-to-text, text-to-speech), 2027 - Even smaller models (100M parameters) for microcontrollers.
Sources and Further Reading
This article is based on the following sources:
- Liquid AI Official Blog: LFM2.5-230M: Built to Run Anywhere
- VentureBeat Technical Analysis: Liquid AI's smallest model yet beats models 4X its size
- Hugging Face Model Page: LiquidAI/LFM2.5-230M
- BFCLv3 Benchmark: Independent comparisons by the ML community
- Raspberry Pi Community Tests: Real-world performance tests from users
Content of this article has been rewritten based on public data and independent benchmarks. Compliance with copyright laws has been observed.
🌐Stay Connected With Us 🎮✨
For the latest tech, gaming, and gadget news, follow us on our official social media channels:
Supplementary Image Gallery: 🚀 The Edge AI Revolution: Liquid AI's 230M Model Autopsy