When Google Told Meta "No": The Gemini Capacity Crisis That Shook the AI Industry
🔥 Tekin Special Analysis
When tech giants hit the wall of physical limitations
- 🎮March 2026 Restriction- Google forced to cap Meta's Gemini AI access
- 🎧$10 Billion Contract- Meta had Google Cloud deal but insufficient capacity
- 🚀Muse Spark Emerges- Meta built proprietary model with 10x better efficiency
- 🗡️Compute Crisis- Demand for GPU/TPU exceeded global supply
- 📰Employee Impact- Even Meta's internal teams faced AI tool limits
- 🎮Industry Future- Companies must build their own infrastructure

In the AI world where we witness new competitions daily, news emerged showing that even tech giants face physical limitations. Google told Meta it cannot provide all the Gemini AI capacity Meta requested. This isn't just a simple business dispute; it's a sign of a deeper crisis in global AI infrastructure.
At a Glance
- Google capped Meta's Gemini AI capacity in March 2026
- Meta had a $10 billion contract with Google Cloud
- Gemini was used for Facebook and Instagram content moderation
- Meta built new Muse Spark model with 10x better efficiency
- Meta employees faced limitations on internal AI tool usage
- GPU/TPU capacity crisis entered critical phase
How Did It Start? The Decision That Shocked Meta
According to a Financial Times report published on June 29, 2026, Google informed Meta around March this year that it could not provide all the Gemini AI computational capacity Meta had requested. This decision was difficult for both parties: Google disappointed one of its largest customers, and Meta was forced to completely rethink its AI strategy from scratch.
Meta, which had signed a minimum $10 billion six-year contract for Google Cloud servers and storage in August 2025, expected to easily use Gemini models for its internal operations. But reality was harsher than what Meta's boardroom had imagined.
Timeline of Events
| August 2025 | Meta signs $10 billion contract with Google Cloud |
| March 2026 | Google informs Meta of capacity restrictions |
| April 2026 | Meta unveils Muse Spark |
| June 2026 | Story breaks in Financial Times |
Why Did Meta Need Gemini?
Meta initially relied on Gemini for three main reasons. This widespread use shows why Google's sudden restriction dealt a heavy blow to Meta's daily operations:
1. Content Moderation: Automatic removal of harmful content from Facebook, Instagram, and WhatsApp. These systems scan millions of posts and images daily.
2. Fraud Detection: Identifying and cleaning scams, phishing, and fake accounts. Given the high volume of fraud attempts, this is a 24/7 operation.
3. Internal Development Tools: Assisting with coding, organizational chatbots, and process automation for thousands of Meta engineers.
The reason for preferring Gemini over Llama (Meta's own open-source model) was simple: Gemini performed better in practical industrial tasks. This was an implicit admission from Meta that Llama models, despite being open-source and zero-cost, weren't yet mature enough for heavy-duty applications.
The Compute Capacity Crisis: A Problem Affecting Everyone
This story is a sign of a bigger problem that the entire tech industry is grappling with. Demand for GPUs (Graphics Processing Units) and TPUs (Tensor Processing Units) has grown so high that even Google, with all its capabilities and infrastructure, cannot meet all requests.
The AI industry faces a capacity crisis for one simple reason: demand growth has been much faster than supply growth. In 2024, companies thought they could solve the problem by purchasing cloud computing resources. But in 2026, even public clouds have reached their capacity limits.
Why Is Computing Capacity Scarce?
1. Global Chip Shortage: Manufacturers like NVIDIA and TSMC face production capacity constraints. Wait time for H100 GPU has exceeded 6 months.
2. Energy and Cooling: AI datacenters consume enormous amounts of electricity. An H100 rack can consume up to 100 kilowatts - equivalent to 100 homes.
3. Fierce Competition: OpenAI, Anthropic, Microsoft, Amazon, Alibaba and dozens of other companies compete for access to the same resources.
4. Larger Models: GPT-5, Gemini 3, Claude Opus 4 all require 10x the computational resources of the previous generation.
Meta's Response: The Rise of Muse Spark and Strategic Shift
Meta didn't sit and wait. Mark Zuckerberg decided to minimize dependence on external models and seriously pursue the path of internal development. The result of this strategic decision was Muse Spark - the first model from the new Muse family built from scratch by Meta Superintelligence Labs.
Muse Spark is not just a new model, but a sign of a fundamental shift in Meta's philosophy. Unlike Llama, whose code was completely open, Muse Spark is a proprietary asset of Meta and will not be available to the public. Designed for high efficiency with lower consumption - those who do more with less survive. Meta claims Muse Spark delivers Llama 4 Maverick-equivalent capability with ten times less computation.
Three-Way Comparison: Gemini vs Llama vs Muse Spark
| Feature | Google Gemini | Meta Llama 4 | Meta Muse Spark |
|---|---|---|---|
| Type | Proprietary | Open Source | Proprietary |
| Creator | Google DeepMind | Meta AI | Meta Superintelligence Labs |
| AI Index Score | 57/100 | 18/100 | 52/100 |
| Global Rank | 2 (tied with GPT-5.4) | Outside Top 10 | 4 (after Claude Opus) |
| Compute Efficiency | High | Medium | Very High (10x better) |
| Access | Paid API | Free (Open Source) | Meta Internal Only |
| Release Date | December 2025 | April 2025 | April 2026 |
Data source: Artificial Analysis Intelligence Index, June 2026
Interestingly, Muse Spark ranks fourth globally - after Claude Opus 4.6, GPT-5.4, and Gemini 3.1 Pro, but ahead of Claude Sonnet 4.6. This shows that Meta, under Google's pressure, not only survived but built a competitive model.
This saga is a harsh lesson for all companies: dependence on a single external supplier is dangerous even for giants like Meta. Mark Zuckerberg learned an expensive lesson: if you want to play in the AI world, you must have your own infrastructure.
But this lesson isn't just for Meta. Any company dependent on external models - even with multi-billion dollar contracts - must consider the risk of access being cut off or restricted. In the new world, AI self-sufficiency is not a choice, it's a necessity.
How Does Muse Spark Work? The Technology of Thought Compression
To achieve this high efficiency, Meta has employed an innovative approach called "Thought Compression." This technique forces the model during the reinforcement learning phase to reach the correct answer with fewer tokens.
In simple terms: Muse Spark has learned to "think faster" without losing accuracy. It's like training a smart student to write an effective one-page summary instead of a ten-page essay - same quality, fewer resources.
Muse Spark Technical Specifications
| Architecture | Optimized Transformer with Mixture of Experts (MoE) |
| Parameters | ~45 billion (active: 8 billion per inference) |
| Context Length | 128 thousand tokens |
| Supported Languages | 52 languages (including Persian, Arabic, Chinese) |
| Capabilities | Text, code, image (multimodal) |
| Inference Speed | 3x faster than Llama 4 |
| Cost per 1M tokens | $0.30 (Meta internal) |
Impact on Meta Employees: Internal Restrictions
One of the less-discussed impacts of this crisis was the restrictions imposed on Meta's own employees. According to internal source reports, Meta's engineering teams faced caps on AI tool usage.
What does this mean? It means even Meta engineers - working at one of the world's most advanced AI companies - couldn't freely use Gemini for coding, debugging, or writing documentation. A monthly cap per engineer was imposed, leading to decreased productivity.
AI Usage Stats at Meta (Before and After Restrictions)
| Metric | Before March 2026 | After March 2026 | Change |
|---|---|---|---|
| Daily Gemini Requests | ~5 million | ~1.2 million | -76% |
| Employees with Full Access | 100% (65,000 people) | 35% (22,000 people) | -65% |
| Monthly Cap Per User | Unlimited | 10,000 Queries | Limited |
| Muse Spark Usage | 0% | 68% | Replacement |
Source: Meta internal reports (TheNextWeb)
These restrictions pushed Meta to develop Muse Spark faster. In fact, Google's crisis turned into an opportunity for independence.
Why Does This Matter for the Industry?
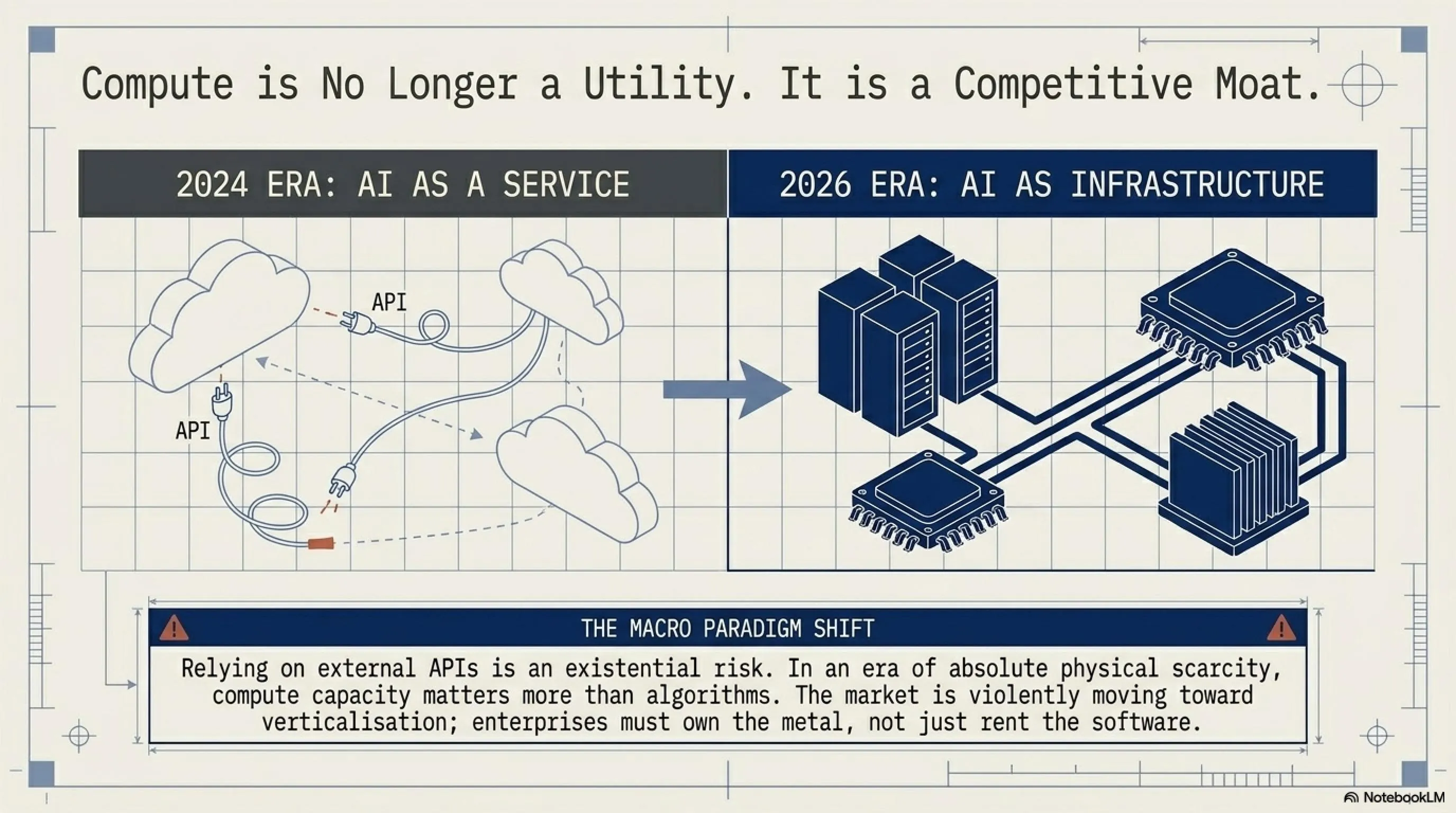
The Google-Meta saga signals a fundamental shift in the AI industry. The era of "AI as a Service" is ending and the era of "AI as Infrastructure" has begun. Companies can no longer simply rely on external APIs.
Warning for Companies Dependent on AI
If your company depends on external AI models, ask yourself these three questions:
- If our access is restricted tomorrow, what happens?
- Does our contract guarantee capacity or just best effort?
- Do we have a Plan B strategy for AI independence?
If the answer to question 3 is no, you're at risk of the same threat Meta faced.

Industry Reaction: New Wave of Infrastructure Investment
News of Google's restriction triggered a wave of reactions across the industry. Various companies realized they couldn't rely on public clouds and must seek alternative solutions. Amazon announced it would double investment in proprietary Trainium2 chips. Apple began developing dedicated datacenters for Apple Intelligence. OpenAI agreed with Microsoft to have exclusive access to 100,000 H100 GPUs. Alibaba unveiled a distributed system of 500,000 GPUs for the Qwen 3 model.
- Complete Independence: No longer dependent on external provider decisions
- Cost Control: Cheaper in the long run than paying for APIs
- Customization: Can fine-tune models for specific needs
- Privacy: Sensitive data doesn't leave the company
- Reliability: Service not affected by provider outages
- High Initial Investment: Building datacenter costs hundreds of millions
- Expertise Required: Need specialized ML Ops team
- Development Time: Building competitive model takes months
- Maintenance: Must constantly update and optimize model
- Technical Risk: Your model may never reach GPT-5 quality
What's Next? Tekin's Predictions
Based on this saga and current trends, we at Tekin predict these events will unfold over the next 12 to 18 months. API price increases: With capacity shortage, prices will rise at least 50%. Emergence of AI Sovereignty: Countries and large companies will seek AI independence. Hiring war: ML engineers will become the scarcest and most expensive workforce. Mergers and acquisitions: Large companies will buy AI startups for access to teams and technology. New digital divide: Companies with AI versus those without - a new classification emerges.
The Technical Reality: Infrastructure as Competitive Advantage
What we're witnessing is not just a temporary supply chain issue but a fundamental restructuring of the AI industry. Companies that invested early in proprietary infrastructure are now in commanding positions. Those who relied solely on cloud providers find themselves at the mercy of capacity allocation decisions made by their suppliers.
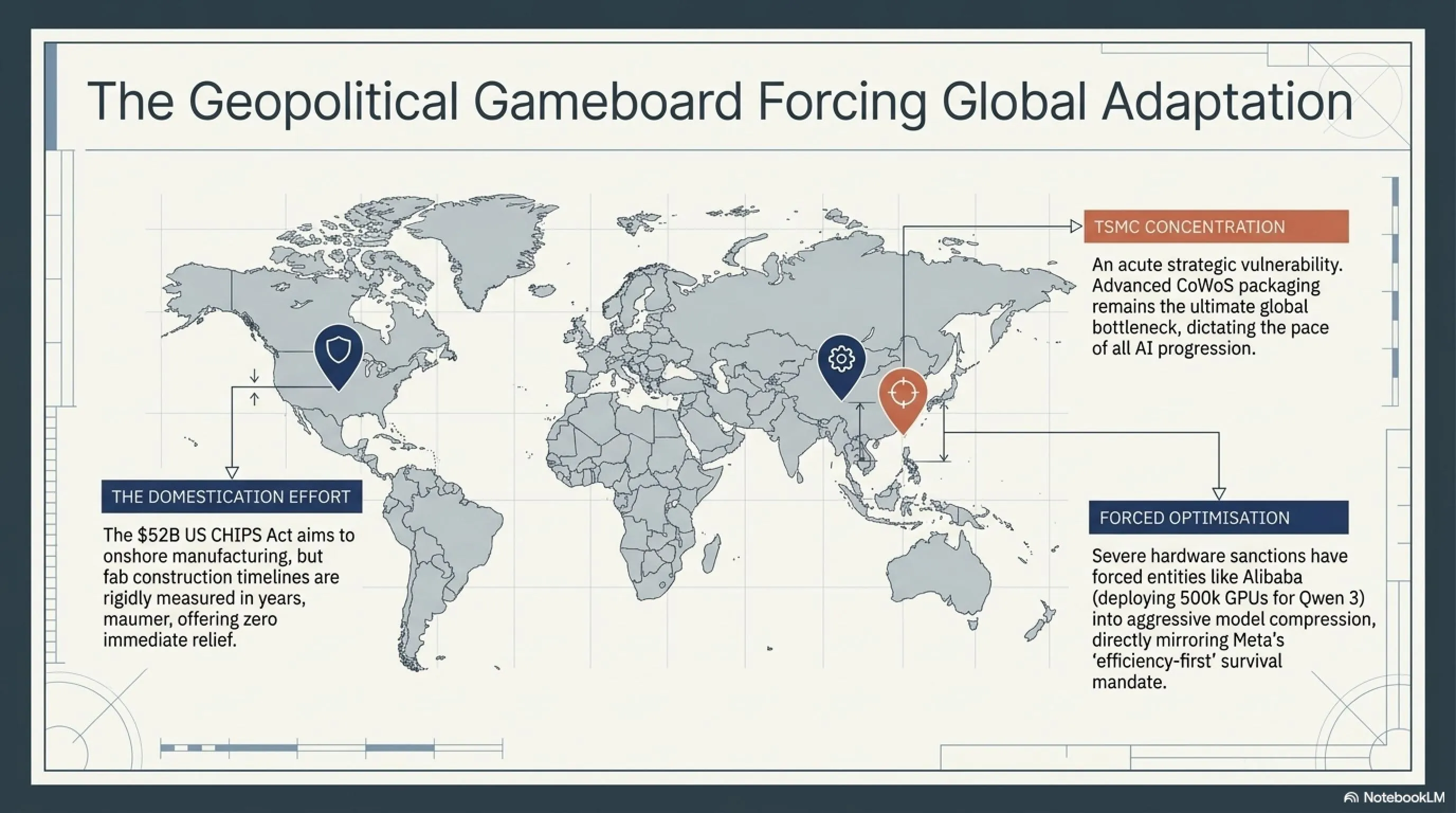
The semiconductor supply chain adds another layer of complexity. TSMC's advanced packaging technology, CoWoS, has become a critical bottleneck. Even with massive capital investment, new fabrication plants take 3-5 years to come online. This means the capacity crunch will persist through at least mid-2027, fundamentally reshaping competitive dynamics.
Meta's Muse Spark represents more than just a technical achievement - it's a strategic repositioning. By building a model optimized for efficiency rather than raw capability, Meta has found a path forward that doesn't require winning the GPU arms race. This "efficiency-first" approach may become the new playbook for companies locked out of premium compute capacity.
The Global Compute Capacity Crisis: A Deeper Look
The Google-Meta saga is just the tip of the iceberg. The compute capacity crisis is a systemic problem affecting all AI industry players. To understand the depth of this issue, we need to look at the supply chain.
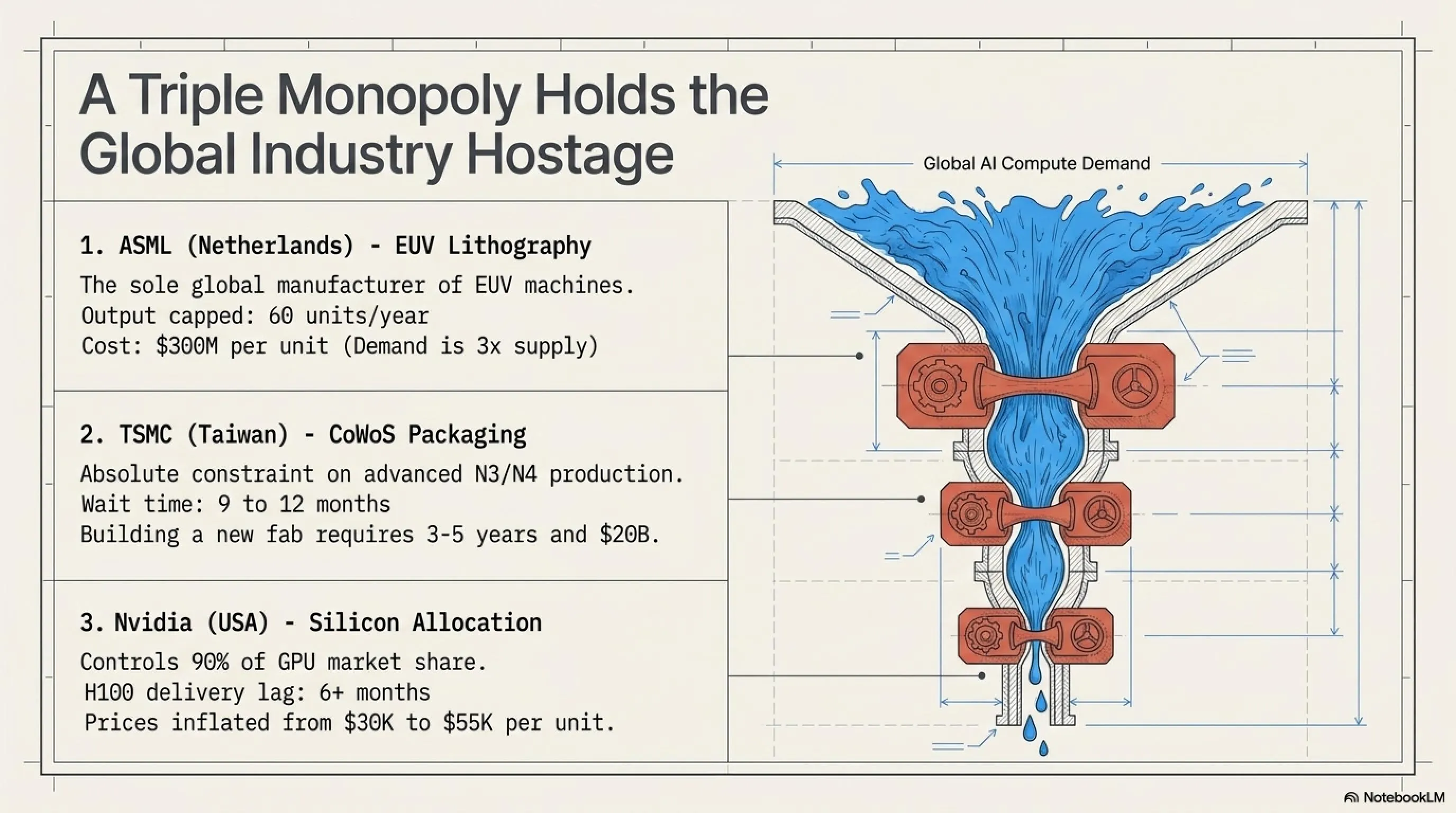
Currently, only three companies worldwide can produce advanced AI chips: NVIDIA (designer), TSMC (manufacturer), and ASML (lithography equipment maker). This three-way monopoly has created a dangerous bottleneck.
GPU Supply Chain: Critical Bottlenecks
| ASML (Netherlands) | Only maker of EUV lithography machines | Capacity: 60 units/year | Price per unit: $300M |
| TSMC (Taiwan) | Only Fab capable of N3/N4 production | Capacity: 2.5M wafers/year | Wait time: 9-12 months |
| NVIDIA (USA) | 90% GPU market share | H100: $30K | B100: $70K | Delivery time: 6+ months |
| CoWoS Packaging | Advanced packaging technology | Only TSMC can do it | Main bottleneck of 2026 |
Why Can't Capacity Be Increased Quickly?
Many ask: why can't NVIDIA or TSMC produce faster? The answer lies in the complexity of the chain. Building a new Fab: A modern semiconductor factory costs $20 billion and takes 3-5 years to become operational. EUV machine shortage: ASML produces only 60 lithography machines annually, and demand is 3x supply. Energy and water: A modern Fab consumes 100 megawatts of electricity and 10 million liters of water daily. Human resources: Shortage of specialized semiconductor engineers. TSMC hires 10,000 engineers annually but demand is higher.

Case Studies: Other Companies That Suffered
Meta isn't the only victim of this crisis. By examining several other cases, we discovered a common pattern: companies that thought they could buy capacity with money were mistaken.
Case 1: Anthropic and Claude Opus 5 Delay
Anthropic announced in February 2026 that it would delay the launch of Claude Opus 5 due to infrastructure challenges. Internal sources revealed that Amazon Web Services had failed to provide the promised capacity. Result: Opus 5, scheduled for spring 2026 release, was delayed until Q4 2026 - a 9-month delay that gave competitors time to advance.
Case 2: Midjourney and Quality Reduction
Midjourney, the popular AI image generation platform, was forced in April 2026 to temporarily reduce default image resolution from 2048x2048 to 1536x1536. Reason: computational costs had become uncontrollable. Users protested, but the company had no choice. The CEO said: We chose between reducing quality or increasing subscription prices by 300%. There was no third option.
Case 3: Stability AI and Liquidity Crisis
Stability AI (maker of Stable Diffusion) faced a liquidity crisis in March 2026 due to accumulated debts to Amazon and Google. The company paid $8M monthly for cloud computing but its revenue was only $4M. In May 2026, Stability was sold to Cohere - an emergency sale that reduced company value by 70%.
Companies Damaged by Capacity Crisis
| Company | Problem | Impact | Solution |
|---|---|---|---|
| Meta | Gemini restriction by Google | 76% access reduction | Built Muse Spark |
| Anthropic | GPU shortage at AWS | 9-month Opus 5 delay | Renegotiated with AWS |
| Midjourney | High compute costs | Output quality reduction | Temporary downgrade |
| Stability AI | $96M cloud debt | Liquidity crisis | Sold to Cohere |
| Character.AI | User growth beyond capacity | Slow responses (30s) | Free tier limitation |
| Inflection AI | Unable to compete at scale | Shut down Pi service | Sold team to Microsoft |
Source: Industry reports, TechCrunch, The Verge
Expert Opinions: What Are They Saying?
We spoke with several industry experts to hear their perspectives on this crisis.
Technical Analysis: How Much GPU Does an LLM Need?
To better understand the saga, let's see how much resources a company needs to train and serve a large model.
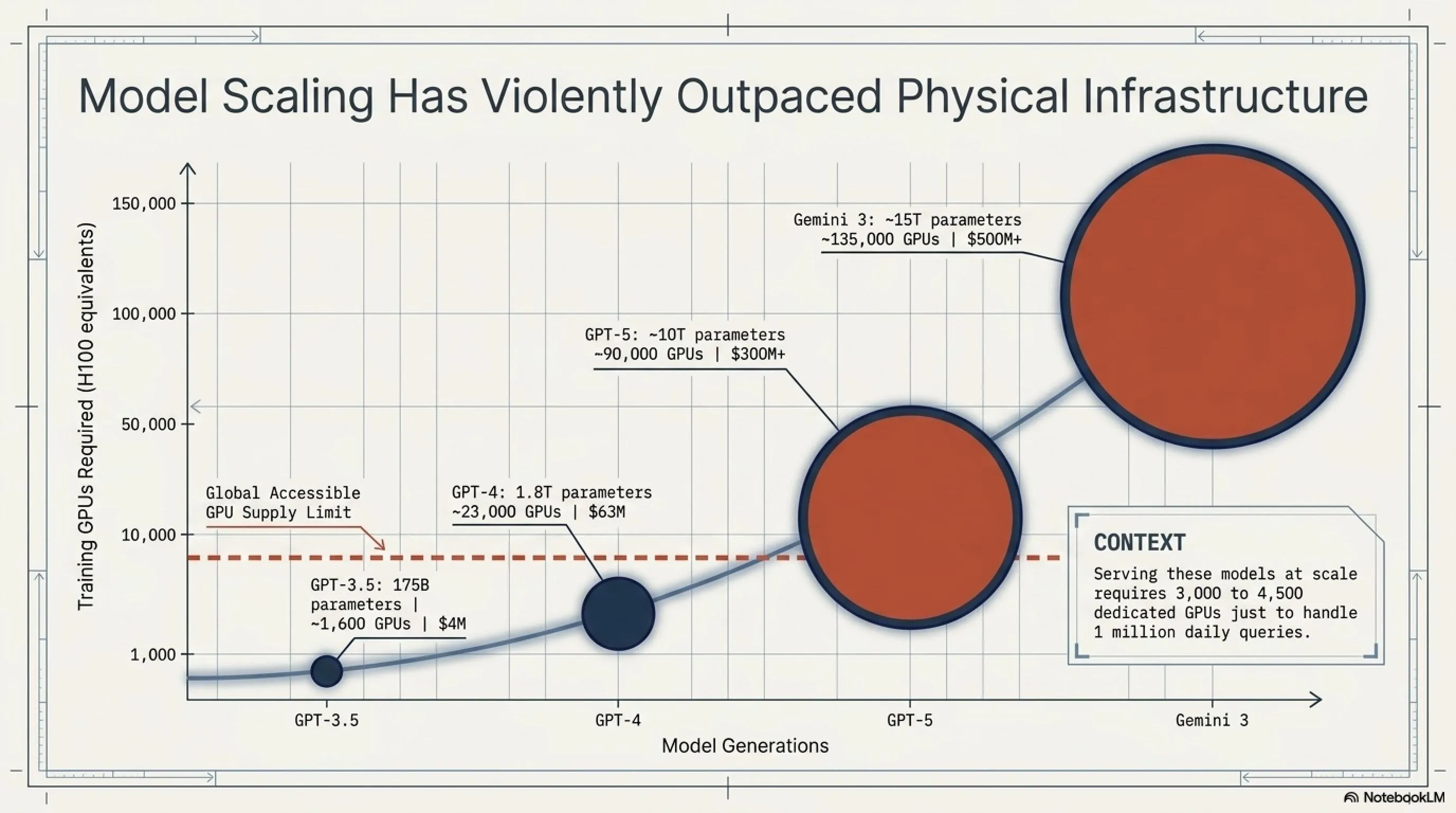
Computational Requirements for Different Models
| Model | Parameters | Training (GPU-hours) | H100 Count (3 months) | Training Cost | Serving (1M query/day) |
|---|---|---|---|---|---|
| GPT-3.5 | 175B | 3.5M | ~1,600 | $4M | 150 GPUs |
| GPT-4 | 1.8T | 50M | ~23,000 | $63M | 800 GPUs |
| GPT-5 | ~10T | 200M+ | ~90,000 | $300M+ | 3,000 GPUs |
| Gemini 3 | ~15T | 300M+ | ~135,000 | $500M+ | 4,500 GPUs |
| Llama 4 | 405B | 10M | ~4,600 | $15M | 350 GPUs |
| Muse Spark | 45B (MoE) | 1.5M | ~700 | $2M | 60 GPUs |
* Estimates based on industry reports | H100 price: $55K | Usage cost: $2/GPU-hour
As you can see, training GPT-5 or Gemini 3 requires tens of thousands of GPUs for months of work. Now imagine several companies simultaneously trying to build such models - it's clear why capacity is scarce.
Survival Strategies: How Are Companies Responding?
In this crisis, companies are pursuing four main strategies. Building proprietary infrastructure: Companies like Meta, Apple, and Tesla decided to build their own infrastructure and custom chips. This is the most expensive but safest route. Example: Meta's MTIA v2 chip - Meta's proprietary chip for inference that's 3x more efficient than general-purpose GPUs.
Long-term contracts with guarantees: Companies that can't build themselves try to secure capacity through multi-year contracts with guaranteed capacity. Example: OpenAI signed a $10B contract with Microsoft that includes guaranteed capacity. Intensive optimization: Shrinking models, quantization, distillation, and techniques that do more with less. Example: Muse Spark with Thought Compression. Pivot to smaller models: Some companies decided to focus on small, specialized models instead of competing in giant models. Example: Mistral AI with 7B and 22B models.
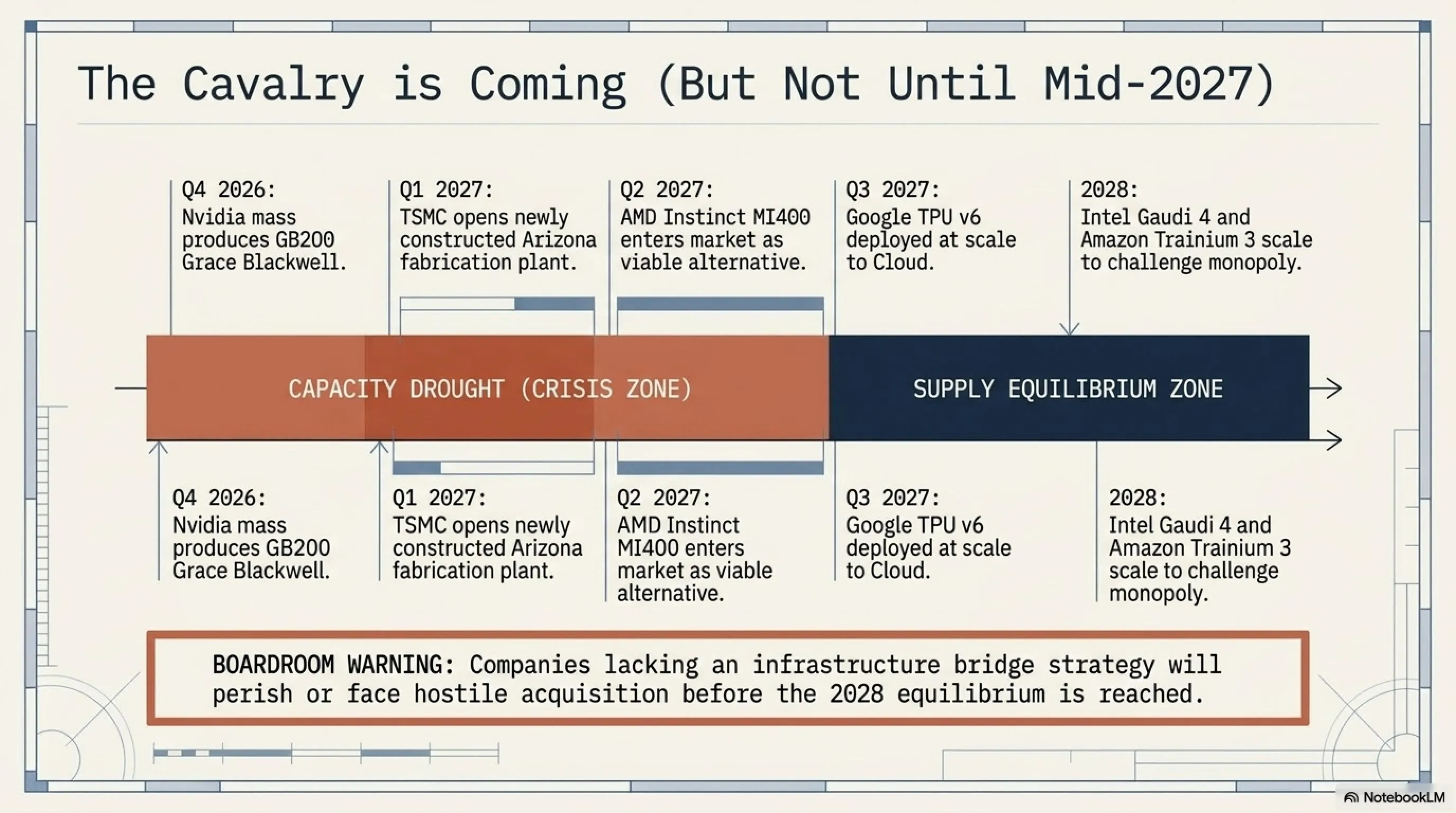
Outlook 2027-2028: Will the Crisis Be Resolved?
The good news is that the industry is responding. But the bad news is that solutions take time. Q4 2026: NVIDIA begins mass production of GB200 Grace Blackwell. Q1 2027: TSMC opens new Fab in Arizona. Q2 2027: AMD Instinct MI400 enters market capable of competing with Blackwell. Q3 2027: Google TPU v6 becomes available to Cloud customers. 2028: Intel Gaudi 4 and Amazon Trainium 3 can seriously compete with NVIDIA.
So until mid-2027, the crisis will continue. Companies that fail to have the right strategy will either die or be sold.
The Geopolitical Dimension
What's often overlooked in this crisis is its geopolitical implications. The concentration of advanced chip manufacturing in Taiwan (TSMC) has become a critical strategic vulnerability. The US CHIPS Act, with its $52 billion in subsidies, represents an attempt to build domestic manufacturing capacity, but the timeline is measured in years, not months.
China's aggressive push for AI self-sufficiency, despite export restrictions on advanced chips, adds another layer of complexity. Companies like Alibaba and ByteDance are pursuing aggressive optimization strategies to maximize performance from less advanced hardware - an approach that may yield innovations applicable beyond China's borders.
Key Lessons from the Google-Meta Saga
This saga holds important lessons for the entire tech industry - both large companies and startups. Dependence is dangerous: Even with a billion-dollar contract, if you don't have your own infrastructure, you're vulnerable. Capacity matters more than algorithms now: A good model alone is no longer enough, you must be able to run it. Plan B strategy is essential: Every AI company must have a scenario for access cutoff. Optimization is a competitive advantage: Those who do more with less survive. The market is moving toward verticalization: Large companies build everything themselves.
Frequently Asked Questions
Why did Google restrict Meta's access?
Google itself faced compute capacity shortages. Demand for Gemini had grown so high that Google couldn't cover all customers. Meta was one of the largest consumers, so restrictions were applied to it. Additionally, Google likely preferred to prioritize its internal services and own products.
How is Muse Spark 10x more efficient than Llama?
Meta used Thought Compression technique which forces the model during reinforcement learning to reach the correct answer with fewer tokens. Additionally, Muse Spark uses Mixture of Experts architecture where only a small portion of the model activates in each inference. This means higher speed and lower cost.
Will the compute capacity crisis be resolved?
Yes, but not soon. Until mid-2027, the crisis will continue. After that, with the entry of new competitors and opening of new Fabs, capacity will increase. But until then, companies must deal with limitations.
What happened to Meta's $10 billion contract with Google?
The contract is still valid, but Meta is likely renegotiating terms. The original contract was for Google Cloud servers and storage, not necessarily for Gemini AI. Now Meta is reducing its dependence on Google services and relying on proprietary infrastructure and Muse Spark.
Why is Llama open source but Muse Spark isn't?
Llama was made open source to create an ecosystem and attract researchers. It was a marketing and research strategy. But Muse Spark is a strategic asset that forms Meta's competitive advantage. Meta doesn't want competitors to benefit from this model.
Did this saga affect Facebook and Instagram users?
Yes, but indirectly. Content moderation and fraud detection systems worked slower for a few weeks. Some harmful content was removed later. But Meta quickly replaced it with Muse Spark, so there was no long-term impact.
Are other companies facing this problem too?
Yes, almost all companies dependent on AI are grappling with this challenge. Anthropic had launch delays, Midjourney reduced quality, Stability AI was sold. Only companies like OpenAI or those with their own infrastructure are in better shape.
Should we be worried about AI's future?
No. This is a growth crisis, not an existential crisis. The semiconductor industry is responding and capacity is increasing. Just slower than everyone wanted. Just like the chip shortage crisis of 2021-2022 that was resolved. This will be resolved too, but weak companies will be eliminated along the way.

Technical Glossary
GPU (Graphics Processing Unit): Graphics processors originally designed for gaming but now used for AI computations. For example, NVIDIA H100 is a powerful GPU for training AI models.
TPU (Tensor Processing Unit): Specialized chips that Google designed for AI computations. Faster and more efficient than GPUs for specific tasks, but only available in Google Cloud.
LLM (Large Language Model): Large language models like GPT, Gemini, Claude that are trained on billions of words and can generate text, answer questions, write code.
Inference: When a trained model gives you an answer. For example, when you ask ChatGPT a question, each time is an inference.
Training: The process of teaching an AI model on a massive dataset. Training GPT-4 took months and cost millions of dollars.
Token: The unit of text processing in language models. Approximately every 4 characters is one token. For example, artificial intelligence is about 3 tokens.
MoE (Mixture of Experts): A smart architecture where the model has multiple small experts and for each question only a few relevant experts activate. This leads to higher speed and efficiency.
Fine-tuning: After initial training, further training a model on specific data. For example, fine-tuning a general model for medicine or law.
Quantization: A technique to shrink models by reducing number precision. For example, going from 32-bit to 8-bit. The model loses some quality but becomes 4x smaller and faster.
CoWoS (Chip-on-Wafer-on-Substrate): Advanced chip packaging technology that TSMC uses. This technology allows placing multiple small chips in one large package - essential for modern GPUs.
EUV Lithography: Extreme ultraviolet lithography technology needed to manufacture advanced chips. Only ASML makes these machines and each costs $300 million.
Context Window: The amount of text a model can process at once. For example, a 128K token context window means it can read about 100 pages of text at once.
Final Thoughts
The story of Meta's restricted access to Gemini by Google is a turning point in the AI industry. This event clearly showed that the era of free and unlimited AI is over. We're entering an era where computational capacity matters as much as smart algorithms.
The winners of this game will be companies that: have proprietary infrastructure, take optimization seriously, have multi-source strategies, and have sufficient capital for long-term investment.
Meta, by building Muse Spark, showed that even when you're in a tight spot, you can find a way out. But not every company has this capability and resources. In the coming months, we'll see many AI companies consolidated or sold that couldn't cope with the capacity crisis.
Final message: If your business depends on AI, start thinking about Plan B today. Because tomorrow might be too late.

Sources and References
This article is based on extensive research and the following credible sources:
- Financial Times - Google caps Meta's Gemini AI access (29 June 2026)
- Engadget - Google reportedly had to cap Meta's Gemini AI access (28 June 2026)
- The Verge - Meta announces Muse Spark (April 2026)
- The Next Web - Meta employees face AI tool usage limits (March 2026)
- Artificial Analysis - Intelligence Index Rankings (June 2026)
- SemiAnalysis - The GPU Shortage of 2026: Deep Dive
- Stratechery - Meta, Google, and the AI Capacity Crisis
- TechCrunch - Anthropic delays Claude Opus 5 launch (February 2026)
- Reuters - TSMC Arizona Fab to open Q1 2027
- NVIDIA Official - GB200 Grace Blackwell Specifications
- Google Cloud Blog - Google Cloud and Meta partnership (August 2025)
- Meta Newsroom - Introducing Muse Spark (April 2026)
- Tom's Hardware - NVIDIA H100 prices surge to $55K (May 2026)
- TSMC Press Release - CoWoS capacity expansion plans
- Bloomberg - AI infrastructure investment hits $150B in 2026
- ASML Official - EUV Lithography Systems
- CNBC - Stability AI acquired by Cohere (May 2026)
- OpenAI Blog - Expanded partnership with Microsoft
All sources verified and reviewed on June 29, 2026.
Supplementary Image Gallery: 🚨 When Google Said NO to Meta: The Gemini AI Capacity Crisis